
Notify의 핵심 기능은 학교의 공지사항을 한 곳에서 볼 수 있다는 점이다.
일반 공지사항 학교 홈페이지에서 봐야하고, 학과 별 공지사항은 학과 홈페이지를 들어가서 보아야하는 불편함이 있다. 이를 위해 학교 공지사항을 한군데 모으는 크롤러를 개발해보려한다.
크롤링을 해오려면 3가지 단계를 거쳐야한다.
- 새 글이 올라왔는지 확인
- 새 글을 크롤링 해오기
- DB에 저장
Spring Batch vs 단순 @Scheduled 어노테이션
고민이 많이 된 부분이다. Spring Batch는 대량의 데이터 처리나 복잡한 데이터 변환 작업이 필요한 경우에 적합하다. 하지만 나는 @Scheduled 어노테이션만을 사용하기로 마음먹었다. 이유는 아래와 같다.
리소스 사용
Spring 배치는 배치 작업을 위한 별도의 프로세스를 실행한다. 이러한 프로세스는 배치 작업을 위한 전용 환경을 설정하고, 배치 작업이 실행되는 동안에도 메모리를 유지해야 한다. 이에 비해 @Scheduled 어노테이션은 스프링 애플리케이션의 메인 스레드에서 실행되므로 추가적인 프로세스 실행이 필요하지 않다. 심지어 우리 프로젝트는 AWS 프리티어를 사용하여 서버의 성능이 낮기 때문에 Spring 배치를 사용하기에 무리가 있다.
데이터의 양
한번에 크롤링할 데이터양이 많으면 배치를 사용하는 것이 유리하다. 하지만 내가 개발하는 기능은 1시간마다 공지사항을 크롤링하는 것이고 공지사항 종류도 공통 공지사항과 4개의 학과 공지사항이 전부다. 따라서 데이터의 양이 작은 프로젝트이므로 비교적 간단하게 구현할 수 있고 가벼운 @Scheduled 어노테이션만 사용하였다.
따라서 @Scheduled 어노테이션만 사용하여 구현하기로 생각했다.
기능 1: 새 글 확인 기능
새 글이 올라왔는지 확인하는 기능을 먼저 개발해야한다. 그 전에 공지사항의 특징을 생각해보자.
- 오타가 없다면 글이 수정되지 않는다.
- 글이 삭제되지 않는다.
이러한 공지사항의 특징을 고려하여 내가 생각한 방법은 아래와 같다.
1. DB에서 가장 최신의 글 2개의 제목과 날짜를 가져온다.
2개를 가져오는 이유는 1개만 가져올 경우 혹시나 글이 수정되거나 삭제될 경우에 정상적으로 작동하지 않을 수 있기 때문이다.
2. 공지사항 1 페이지의 글의 제일 최신 글 2개가 DB에서 가져온 2개의 제목이과 날짜랑 일치하는지 확인한다.
3. 만약 일치하면 새 글이 없다고 판단하고 만약 일치하지 않으면 새글이 있다고 판단한다.
3-1. 둘 다 일치하는 경우 -> 새글 X
3-2. 둘 중 하나(DB에서 가져온 글 중 더 최신의 글)만 일치하는 경우 -> 새글 O
3-3. 둘 다 일치하지 않는 경우 -> 새글 O
4. 어디서부터 새글인지 확인한다.
DB에서 가져온 글이 1페이지에 있으면 몇번째인지 계산하여 새글을 몇개 가져와야하는지 계산하고, 1페이지에 없으면 페이지를 넘겨가며 DB에서 가져온 글과 비교하여 새글을 몇개 가져와야하는지 계산한다.
그런데 학과 공지사항과 달리 공통 공지사항은 성균관대 학생만 접속할 수 있었다. 따라서 공통 공지사항을 크롤링하기 위해서는 먼저 자동 로그인을 한 뒤 게시판을 클릭하여 공통 공지사항 페이지에 들어가는 기능을 개발해야했다.
기능 2: 새 글 크롤링 해오기
새 글이 몇개 올라왔는지 확인을 하면 이제 새 글들을 크롤링 해올 차례이다. 이 때 크롤링 한 게시물들을 날짜를 기준으로 정렬해야한다.
아래와 같이 크롤링하였다.
/**
* 해당 페이지 번호에서 공통 공지사항들을 가져온다.
* @param username 로그인 ID
* @param password 로그인 PW
* @param pageNum 가져올 페이지 번호
* @param oldDriver 크롬 드라이버
* @return 해당 페이지 번호의 공지사항들 리스트
* @throws InterruptedException
* @throws ParseException
*/
@Override
public List<Notice> getNewComNoticesByPageNum(String username, String password, int pageNum, WebDriver oldDriver) throws InterruptedException, ParseException {
oldDriver.quit();
ChromeOptions options = new ChromeOptions().addArguments("--disable-popup-blocking", "--headless");
WebDriver driver = new ChromeDriver(options);
// 공지사항들을 저장할 리스트
List<Notice> notices = new ArrayList<>();
//로그인 하기
if(!isLoggedIn(driver)) {
driver = loginAndGoToComNoticePage(driver, username, password);
}
// 공지 페이지로 이동
driver.get(CrawlerConstants.COM_NOTICE_BOARD_PAGE);
// 두번째 iframe 요소 가져오기
WebElement secondIframe = driver.findElement(By.xpath("(//iframe)[2]"));
// 두 번째 iframe으로 전환
driver.switchTo().frame(secondIframe);
// 해당 페이지로 이동
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(10)); // 최대 10초간 대기
WebElement nextButton = wait.until(ExpectedConditions.visibilityOfElementLocated(By.cssSelector("div.dhx_page:nth-of-type(" + pageNum + ")")));
nextButton.click();
//페이지의 이동을 위해 0.5초 대기
Thread.sleep(500);
// 클래스 이름이 .ev_dhx_terrace 인 모든 요소 가져오기
List<WebElement> elements = wait.until(ExpectedConditions.visibilityOfAllElementsLocatedBy(By.cssSelector(".ev_dhx_terrace")));
String currentHandle = driver.getWindowHandle();
// 각 공지사항을 클릭
for (WebElement element : elements) {
element.click();
}
// 클릭이 제대로 진행될 때까지 1초 대기
Thread.sleep(1000);
// 새로 열린 창의 핸들을 가져오기
Set<String> windowHandles = driver.getWindowHandles();
// 모든 창에서 공지사항 정보 가져오기
for (String windowHandle : windowHandles) {
if(!windowHandle.equals(currentHandle)) {
String newHandle = windowHandle;
driver.switchTo().window(newHandle);
// 새로 열린 창이 완전히 로드될 때까지 대기
wait.until(webDriver -> ((JavascriptExecutor) webDriver).executeScript("return document.readyState").equals("complete"));
// 페이지에서 URL을 찾아 문자열로 저장
String noticeUrl = driver.getCurrentUrl();
// 페이지에서 공지 제목을 찾아 문자열로 변환
WebElement title = driver.findElement(By.cssSelector(".searom_tit"));
String noticeTitle = title.getText();
// 페이지에서 공지 날짜를 찾아 날짜 객체로 변환
WebElement date = driver.findElement(By.id("reg_info"));
String dateText = date.getText();
Date noticeDate = parseComNoticeDateAndFormatting(dateText);
// noticeDate를 가져올 때까지 기다리기
Thread.sleep(100);
// 공지 객체로 만들기
Notice notice = Notice.builder()
.noticeTitle(noticeTitle)
.noticeDate(noticeDate)
.noticeUrl(noticeUrl)
.noticeType(NoticeType.COM)
.build();
notices.add(notice);
// 창 닫기
driver.close();
}
}
// 현재 창으로 전환
driver.switchTo().window(currentHandle);
// 창 닫기
driver.close();
// noticeDate 오래된 순으로 정렬(나중에 DB에 넣을 때 오래된 것을 먼저 삽입해야하므로)
Collections.sort(notices, new DateComparator());
return notices;
}중간 중간 Thread.sleep(100);을 통해 대기하도록 만들었다. 이런 대기코드가 없으면 페이지가 완전히 로딩되지 않았는데 크롤링을 시도하다가 오류가 발생했기 때문이다.
또한 마지막에 Collections.sort(notices, new DateComparator());를 통해 날짜 순으로 정렬하도록 했다.
기능 3: 크롤링한 데이터 DB에 저장
DB에 저장하는 부분은 어렵지는 않았다. 공지사항 객체로 만들어서 JPA를 통해 DB에 저장하였다.
/**
* 새 공통 공지사항들을 DB에 저장한다.
* @param newNotices 새 공통 공지사항들 리스트
*/
@Transactional
public void saveNewComNotices(List<Notice> newNotices) {
for (Notice notice : newNotices) {
// 공지사항 객체화
Notice build = Notice.builder()
.noticeTitle(notice.getNoticeTitle())
.noticeDate(notice.getNoticeDate())
.noticeUrl(notice.getNoticeUrl())
.noticeType(notice.getNoticeType())
.build();
// 공지사항 테이블에 저장
noticeRepository.save(build);
//공통 공지사항 객체화
ComNotice comNotice = new ComNotice();
// 공지사항 테이블의 아이디를 가져오기
comNotice.setNoticeId(build.getNoticeId());
//공통 공지사항 테이블에 저장
comNoticeRepository.save(comNotice);
}
}이 코드에서 중요한 것은 @Transactional 어노테이션이다. 자세히 보면 공지사항을 저장할 때 noticeRepository.save(build);를 통해 공지사항 테이블에도 저장하고, comNoticeRepository.save(comNotice);를 통해 공통 공지사항 테이블에도 저장하고 있다. 우리 팀의 ERD에서는 공지사항 테이블과 공통 공지사항 테이블이 따로 있었기 때문에 각각에 한번씩 총 두번 저장해야하는 것이다. 이 때 공통 공지사항 테이블에만 저장되고 공지사항 테이블에는 저장되지 않거나 공지사항 테이블에만 저장되고 공통 공지사항 테이블에는 저장되지 않는 경우 심각한 문제가 생긴다. 따라서 @Transactional를 추가하여 하나의 트랜잭션으로 관리하도록 코드를 작성하였다.
이 코드들을 완성하고 직접 실행해보았다.
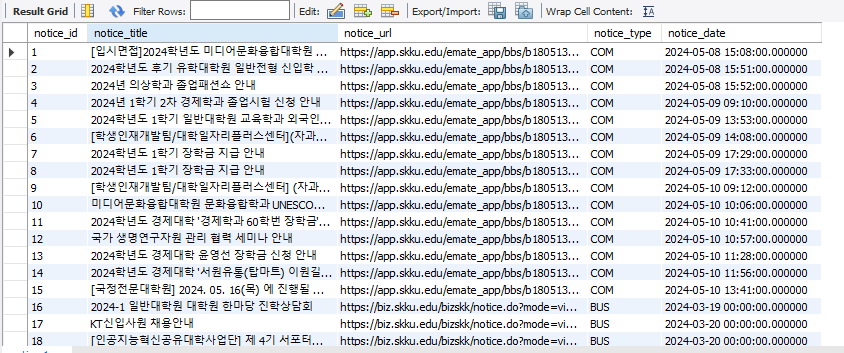
크롤링이 잘 진행되어 DB에 정상적으로 저장됨을 볼 수 있다. 😀
