[redis] string
redis string
redis에서 string은 어떻게 저장될까?
레디스에서의 string은 byte 배열로 이루어져있다
*sds 구조도 마찬가지
즉 json, 이진수와 같은 다양한 데이터 타입에 대해 직렬화가 가능한 것이다
redis의 모든 키는 string으로 이루어진다
물론 value도 string이 될 수 있다
redis를 통해 문자열을 저장 시의 특징
redis는 c 언어를 기반으로 하고 있지만 특성이 조금 다르다
null byte라는 것을 문자열의 끝을 표현하기 위해 사용하는 것은 동일하다
c의 경우 이러한 \0이 중간에 들어가게 되면 문자열 자체로 저장할 수 없다
따라서 이미지 파일, 압축파일의 경우 별도의 방식으로 관리가 필요하다
그러나 redis는 문자열의 길이를 따로 저장하고 있음에 따라 \0이 중간에 들어가는 문자열에 대해서도 지원이 가능하다
c의 경우 이 맥락에서 문자열의 길이를 알기 위해 전체 문자열을 탐색해야한다는 단점 또한 가지고 있다
최대로 저장할 수 있는 문자열의 크기는 512MB이다
즉, 키로 저장할 수 있는 문자열의 최대 크기가 이와 같은 것이다
그러나 실제로는 작게 쪼개주는 것이 적합하다
한꺼번에 큰 데이터의 크기를 지정해주더라도 한번에 네트워크 상으로 전송되는 것이 아니라 chunk를 나눠 전송하게 되기 때문이다
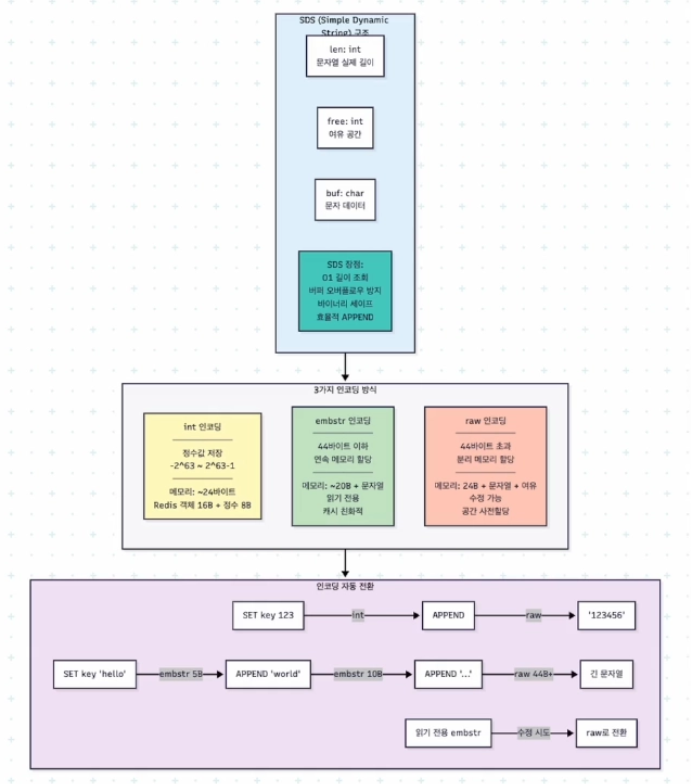
sds 란?
redis는 string을 저장할 때 sds라는 구조를 활용한다
이는 simple dynamic string의 약자이다
sds에는 3개의 구성요소가 있다
- len : 문자열의 실제 길이
- free : 문자열에 대한 추가 여유 공간
- buf : 실제 문자 데이터
이와 같은 형태를 지님에 따라 다음과 같은 장점을 지닌다
-
문자열 길이 저장 -> 따로 길이를 위해 문자열을 전체 조회할 필요 없음, 또한 \0을 중간에 삽입해도 문자열로 구분하고 저장해줄 수 있음
-
여유공간 -> 문자열의 수정, 공간 추가 확보에 용이 (이미 공간이 있기 때문에 시간 단축 가능)
객체 헤더를 함께 주는 이유
문자열 값 자체만 저장하지 않고 객체 헤더를 같이 두는 이유는
관리 가능한 객체로 다루기 위함
- 어떤 자료형인지
- 어떤 저장 방식을 지녔는지
수명 관리, 성능 최적화 등을 위해 운영 정보를 붙이기 위함
sds는 저장되는 구조의 한 형태이지 그것만으로 인코딩 방식을 바로 파악할 수 없음(추론 비용 없는 분기를 위함)
encoding 방식
이와 관련해 제공하는 인코딩 방식은 크게 3가지이다
*인코딩은 문자를 컴퓨터가 저장할 수 있는 숫자로 대응시키는 것을 의미한다
- int encoding
- embstr encoding
- raw encoding
int encoding
정수에 대한 저장 시 따로 문자열의 구조를 활용하지 않는다
redis 객체 헤더 + 정수값 으로 구성되는 것이다
ex) set count 123 의 경우 내부적으로 "123"과 같은 문자열이 아니라 123 정수를 저장하는 것
embstr encoding
짧은 문자열에 한해 쓰는 인코딩 방식이다
redis 객체 + sds의 구조를 메모리상에 연속으로 배치한다
즉, 레디스 객체가 문자열을 저장 시에는 두번의 메모리 할당이 필요하다
- 레디스 객체 헤더
- 실제 문자열 데이터
이와 같은 것인데 함께 저장을 해줌으로서 속도가 빠르고 메모리 단편화를 감소시킬 수 있다
따라서 이와 같은 인코딩 방식을 활용할 경우 캐싱 상의 이점을 볼 수 있다
인접한 주소에 문자열의 내용이 있기 때문에 다른 주소로 교체될 필요없이 해당 문자열에 대해서는 계속 히트가 가능한 것이다
raw encoding
문자열이 44byte 초과 시에 활용한다
이 크기부터는 분리된 메모리로 할당하는 것이며 redis 객체 헤더, sds 구조가 분리되어 저장된다
이때 레디스 객체의 ptr이 sds를 가리키기 때문에 실제 문자열에 대한 반환이 가능하다
이때 embstr은 읽기 전용, embstr의 문자열에 대해 수정이 발생하면 그때부터는 raw encoding 을 활용한다
따라서 embstr은 변경되지 않고 크기가 적은 읽기 전용의 데이터에 대해 적합하다
redis 명령어
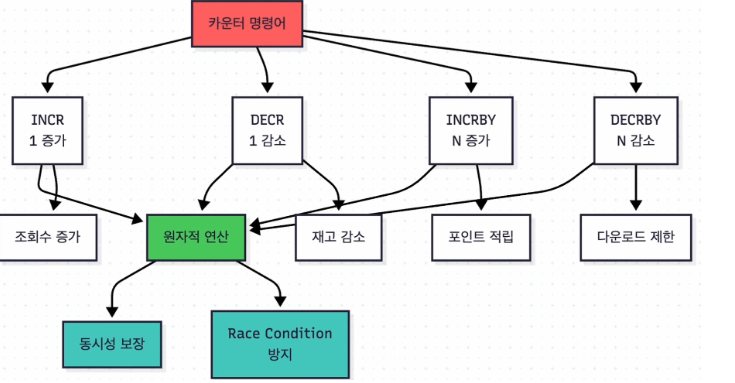
레디스의 명령어들은 원자성을 지닌다
단일 스레드 기반으로 요청에 대한 응답을 제공하는 방식이기 때문이다
- set
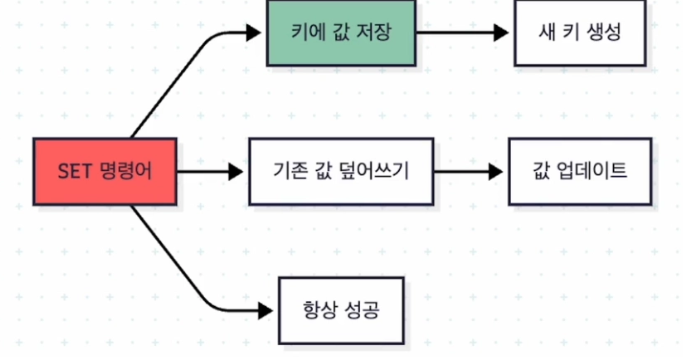
- get

없을 시 nil 반환
incr, decr
mset
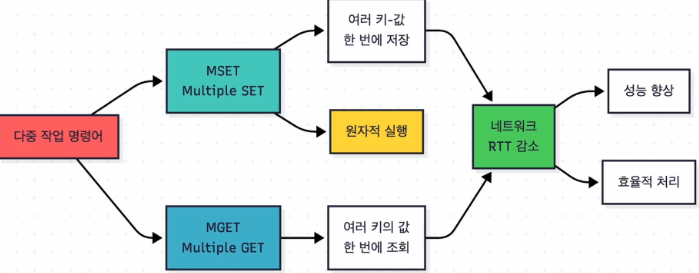
multiset으로 여러 키와 값의 쌍을 한꺼번에 저장할 때 사용한다
이와 같은 연산이 필요한 이유는 네트워크 상으로 데이터를 전송할 때 rtt, round trip time이라는 것이 발생하기 때문이다
이는 redis에서 연산 속도를 얼마나 빨리하는지와는 관계없이 네트워크 전송 상에서 걸리는 시간을 의미한다
따라서 이에 대한 단축을 위해 모아 데이터를 보내는 것이라 보면 된다
pipelining이라는 개념이 multiset과 여러 명령어를 한꺼번에 처리하는 점에서 유사하다
그러나 pipeline의 경우 여러 명령어를 순차적으로 실행하는 점에서 race condition이 발생 가능하다
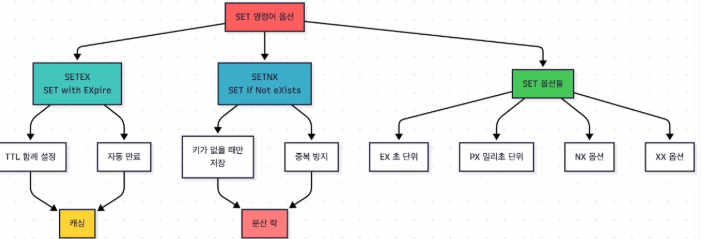
ttl의 경우 setnx, setex를 활용할 수 있다
둘의 차이는 setnx가 key가 없는 경우에만 값을 set해주는 것이다
setex는 key의 값을 덮어버리기 때문에 이를 방지하고자 하는 경우 사용할 수 있다