2과목 - SQL 기본 및 활용
관계형 데이터베이스 개요
DBMS
1) DBMS: 데이터베이스를 관리 및 접근하기 위한 환경을 제공하는 시스템
2) RDBMS(관계형 DBMS)
- 데이터를 테이블 형태로 저장하고 테이블간 관계를 활용하여 관리하는 데이터베이스
- 1970년 IBM의 에드가 F.커드가 처음 제안한 모델
- 대표적인 RDBMS: Oracle, SQL Server, MySQL, PostgreSQL 등
SQL
- RDMS에서 데이터를 생성, 조회, 수정, 삭제 하기 위한 표준 언어
1) 데이터 정의어(DDL): 테이블 생성, 변경, 삭제
CREATE, ALTER,DROP, RENAME, TRUNCATE
2) 데이터 조작어(DML): 데이터를 조회, 삽입, 수정, 삭제
SELECT, INSERT, UPDATE, DELETE
SELECT를 데이터 조회어(DQL)로 구분하기도 함
3) 데이터 제어어(DCL): 권한관리
GRAND, REVOKE
4) 트랜잭션 제어어(TCL): 트랜잭션을 제어
COMMIT, ROLLBACK, SAVEPOINT
SELECT문
-
SELECT문의 구조
데이터베이스에서 데이터를 조회할때 사용하는 가장 기본적인 명령어
해석하는 순서: FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY (FWGHSO) -
SELECT DISTINCT 사용시 중복 제거하고 유일 값 선택
-
AS는 생략가능하며 FROM절의 TABLE에도 별칭 설정 가능
-
WHERE 절은 SELECT 문보다 먼저 수행되므로 SELECT문에 정의된 별칭은 사용 불가
-
Oracle에서의 CONCAT은 ||, SQL Server에서의 CONCAT은 +
함수
입력에 대한 특정 연산을 수행 후, 결과를 반환하는 약속된 코드 블록
단일행 함수: Input 1 > Output 1 / 다중행 함수: Input N > Output 1
-
문자함수
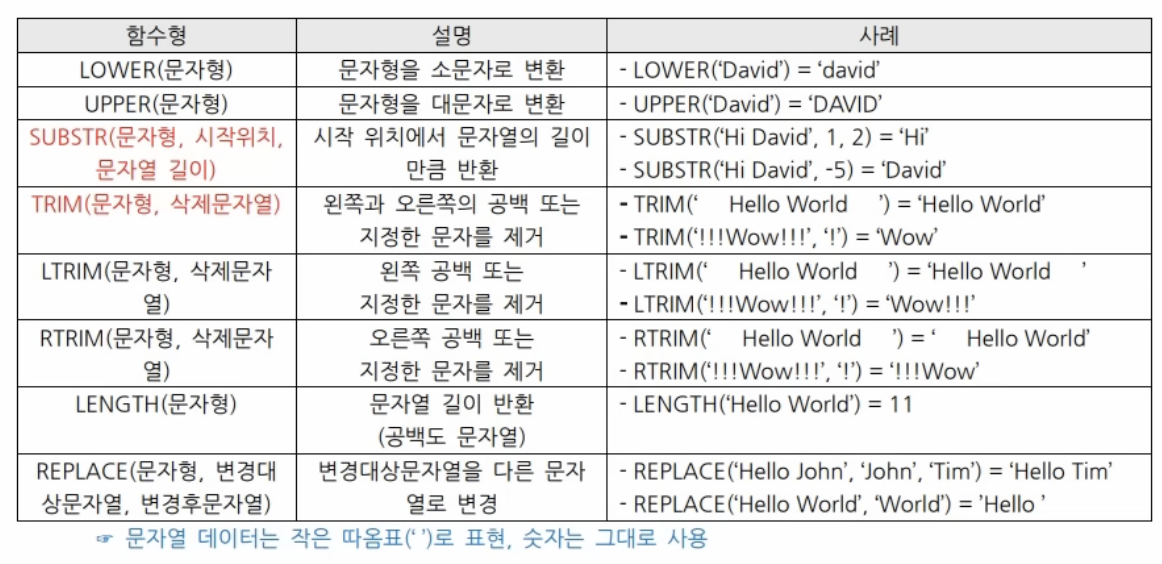
-
숫자함수
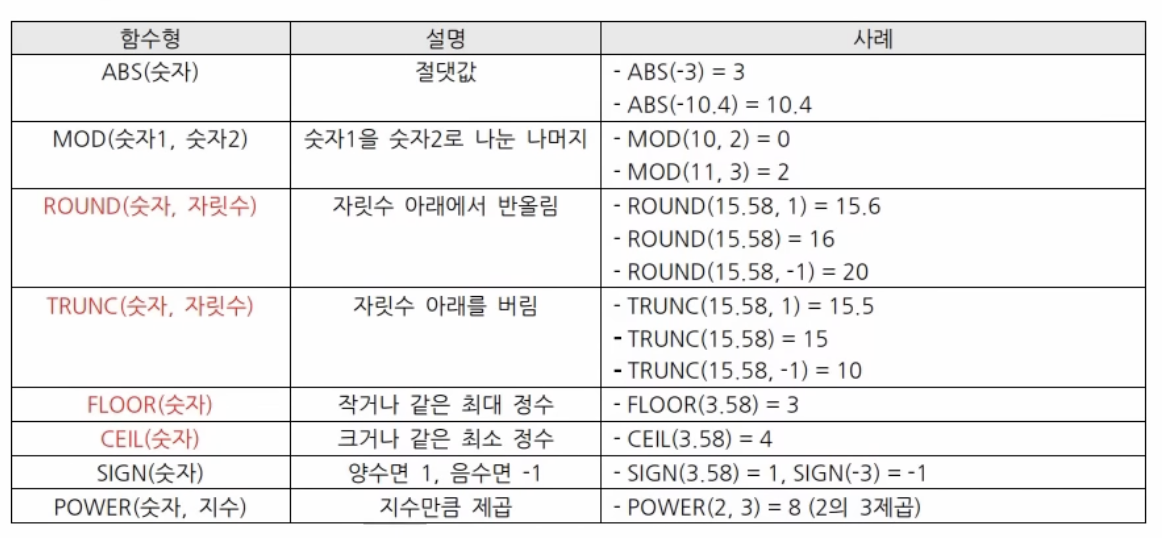
-
날짜함수

-
변환함수
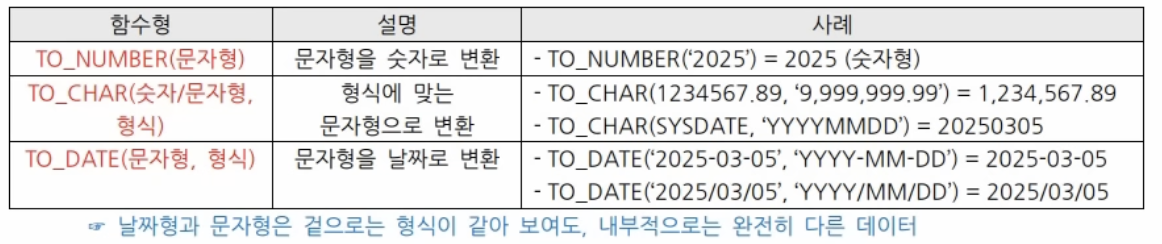
-
집계함수
COUNT, SUM, AVG, MIN, MAX 등
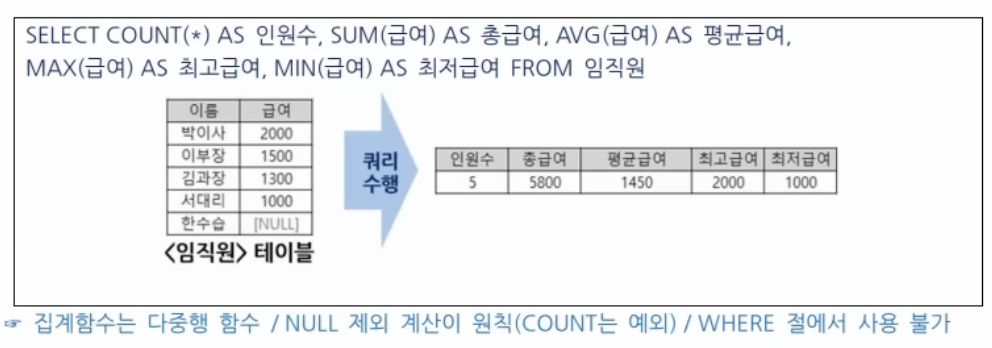
-
NULL 관련 함수
1) NVL(컬럼, 대체값): 컬럼이 NULL이면 대체값, NULL이 아니면 원래값
2) NULLIF(컬럼1, 컬럼2): 두 컬럼값이 같으면 NULL, 다르면 첫 번째 값
3) COALESCE(컬럼1, 컬럼2, 컬럼3...): 가장 먼저 NULL이 아닌 값 -
CASE문/ DECODE함수
조건에 따라 값을 분기 처리
1) CASE 문
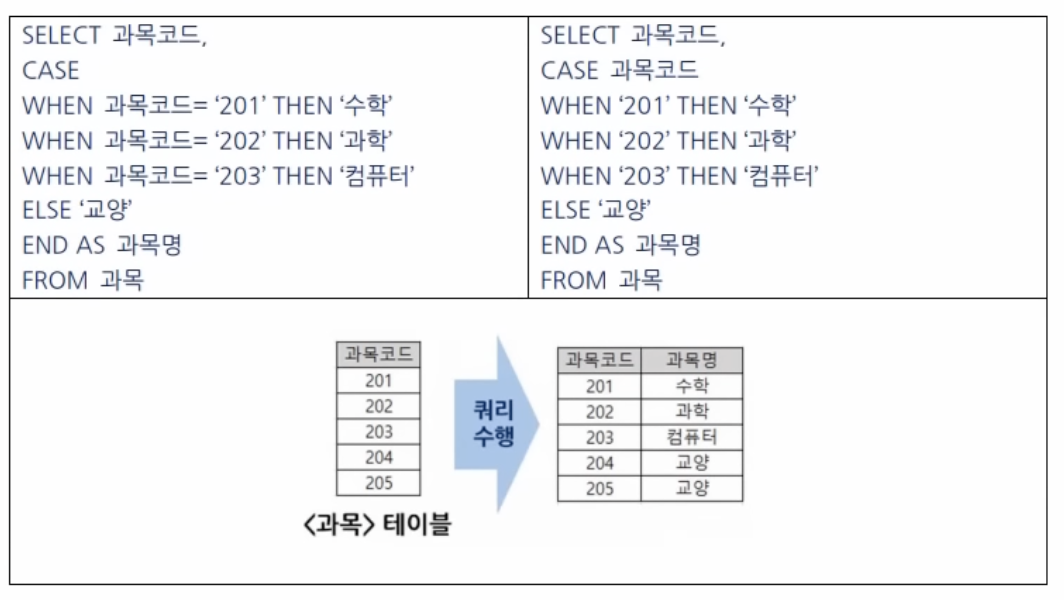
2) DECODE(컬럼, 값1, 반환1, 값2, 반환2, ..., 반환N)

-
WHERE절
특정 조건에 부합하는 튜플(행) 데이터들을 조회할 때 사용
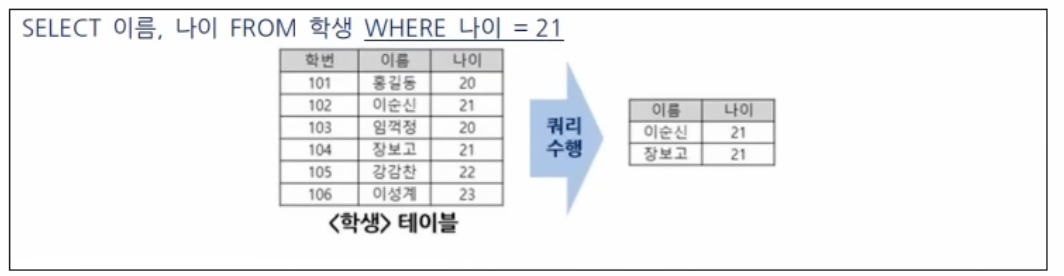
-
기본 비교 연산자
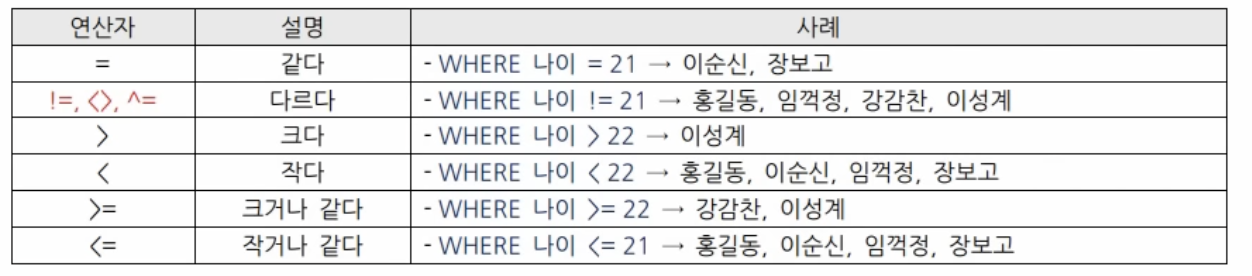
-
조건 표현 연산자
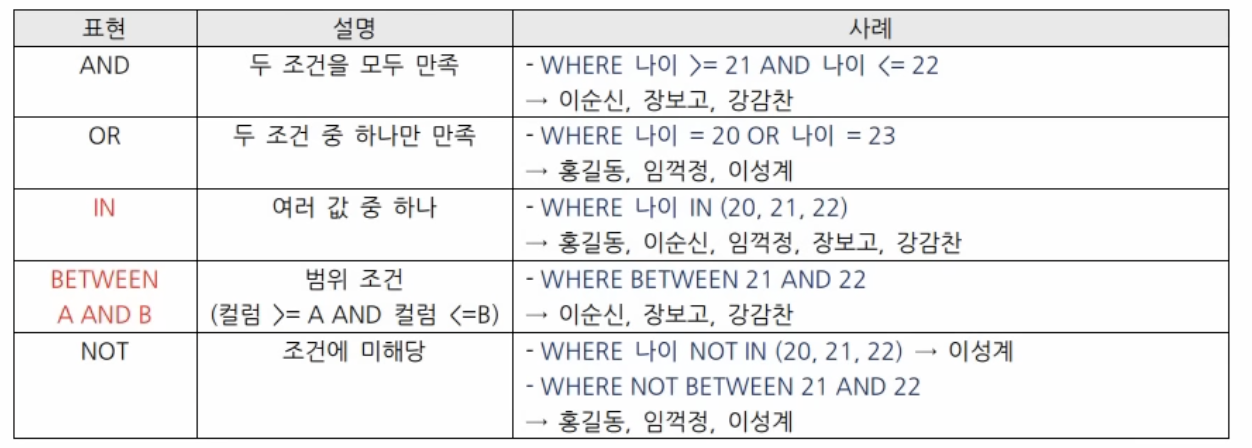
-
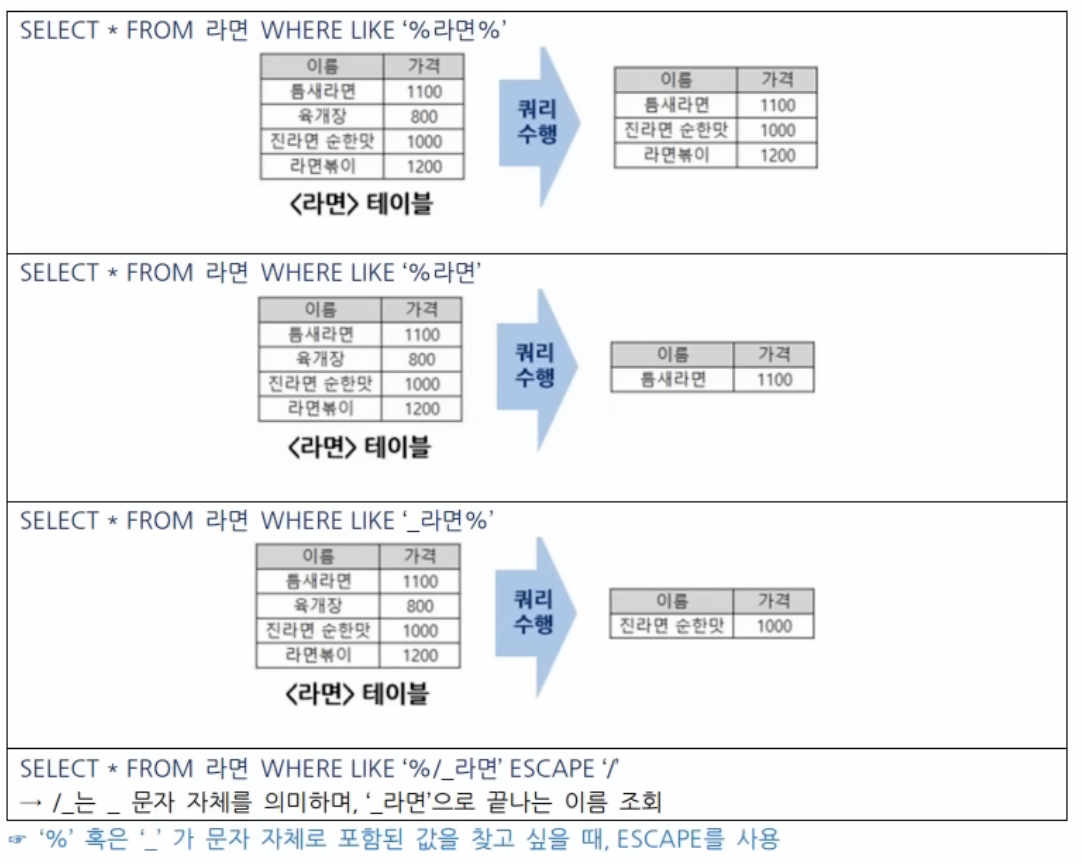
LIKE 연산자
1) 와일드카드 문자

2) LIKE의 활용
-
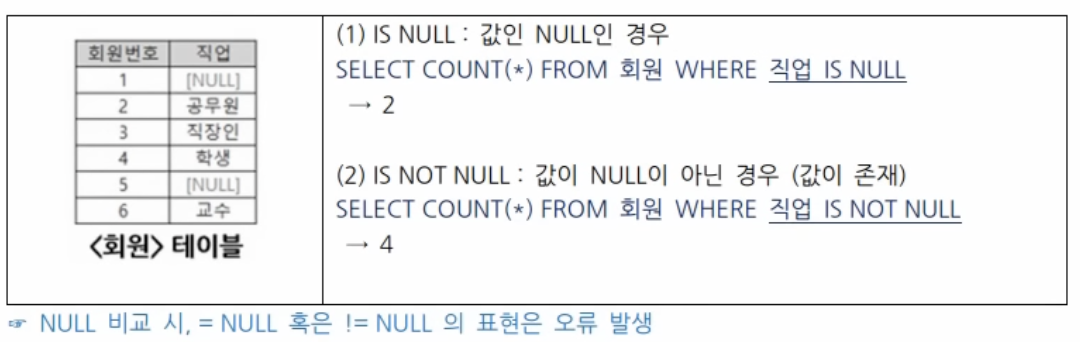
NULL 비교 연산자
-
연산자 우선순위
괄호() > 곱셈(*), 나눗셈(/), 나머지연산(%) > 비교연산자(=, !=, <>, <, >, <=, >=)
IS NULL, LIKE, BETWEEN, IN > NOT > OR
GROUP BY, HAVING절
-
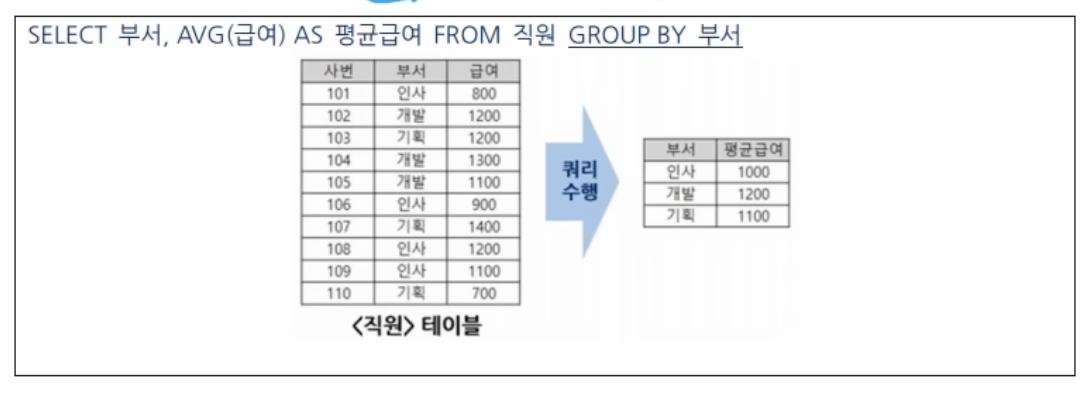
GROUP BY 절
특정 컬럼을 기준으로 행들을 그룹화하여 집계함수 결과를 산출
-
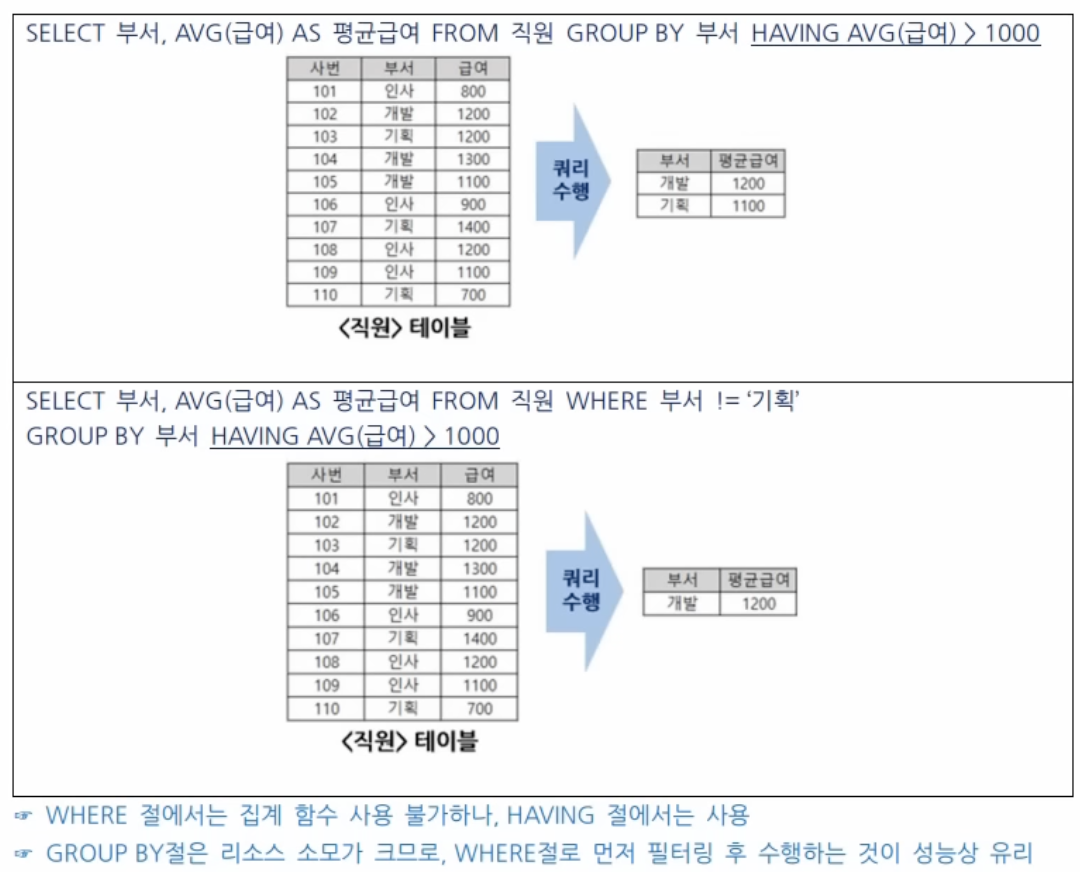
HAVING 절
그룹화된 결과에 대한 조건(WHERE은 튜플(행)단위, HAVING은 그룹단위)
보통은 GROUP BY절과 같이 사용되지만, 단독으로도 사용가능(집계함수의 활용)
ORDER BY 절
결과를 정렬할 때 사용
1) 정렬 키워드
ASC: 오름차순(기본값)
DESC: 내림차순
2) 특징
SELECT절보다 나중에 수행되므로 SELECT절에서 선언된 별칭 사용 가능
GROUP BY 절보다 나중에 수행되므로 집계함수 사용 가능
3) 데이터 형에 따른 정렬 순서(오름차순 기준)
숫자형: 작은수 -> 큰수
문자형: 사전 순
날짜형: 과거 -> 미래
NULL 정렬: Oracle은 NULL을 최댓값으로 SQL Server는 NULL을 최솟값으로 처리
