NoSQL

relational database
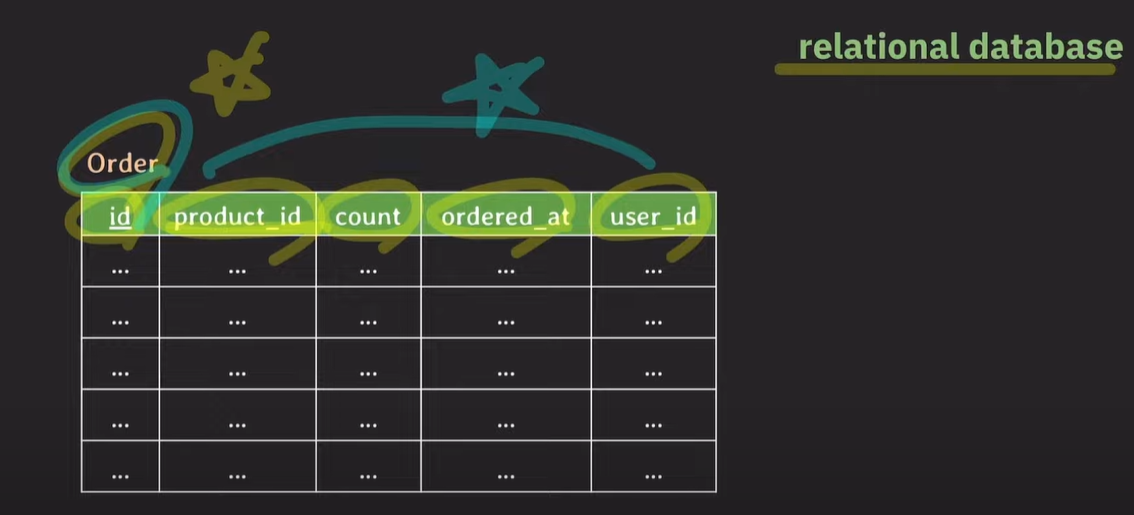

Order 테이블에 주문번호, 상품번호 등등이 존재하는 상태에서 새롭게 로켓배송을 서비스를 시작하고, 테이블에 로켓배송 여부 column을 추가하고 스키마가 변경된다.
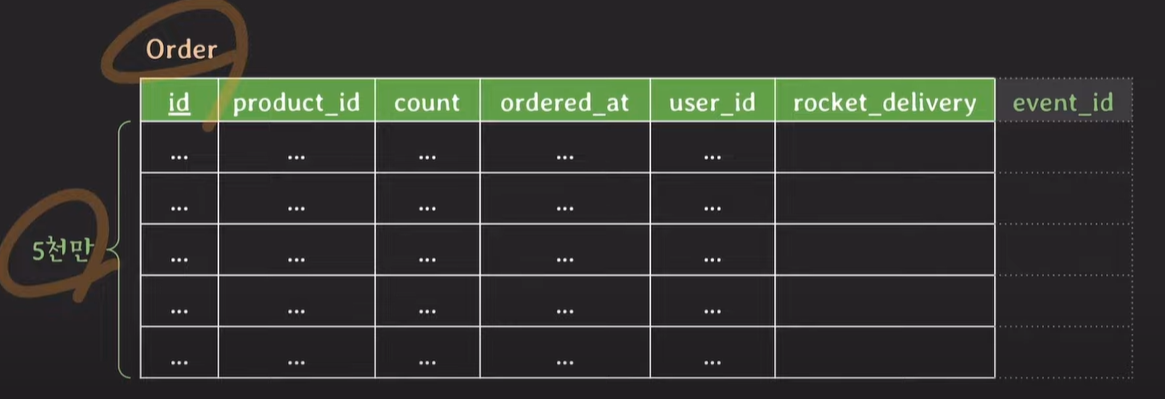
만약 추가적으로 세일 이벤트를 진행할 경우 어떻게 해야할까 ? column을 추가하여 다시 schema를 변경해야한다.
이미 데이터가 5천만개 있는 테이블에 새로운 column을 추가하게 될 경우 기존에 존재하던 5천만건의 데이터의 event_id는 데이터는 null이다. 때문에, 데이터 베이스의 스키마를 변경하는 작업은 매우 복잡하고, 위험요소가 있는 작업이다.
단점
1. 경직된 스키마
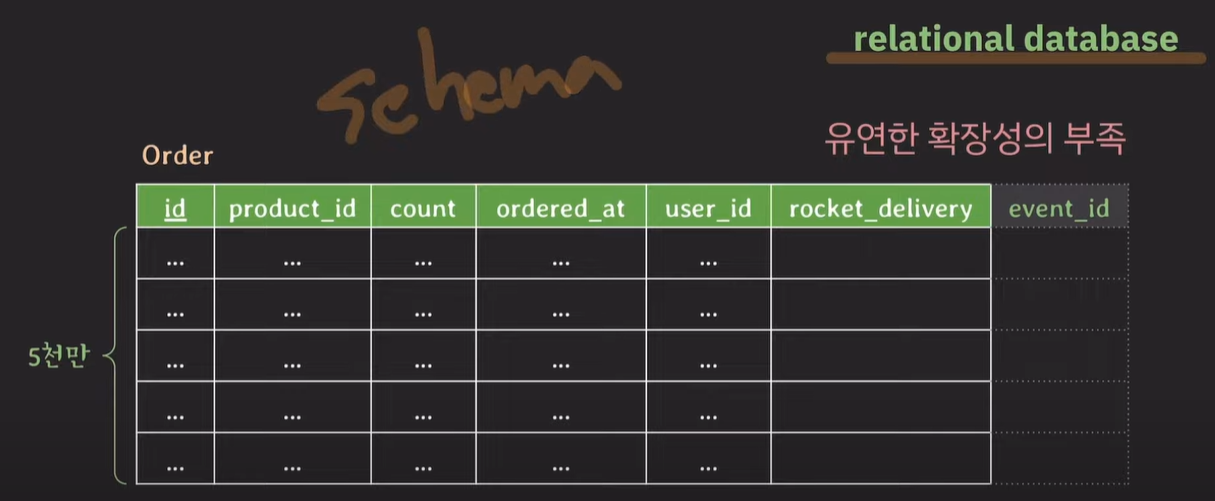
relational database는 경직된 스키마를 가지며, 유연한 확장성이 부족하다.
2. 성능 하락
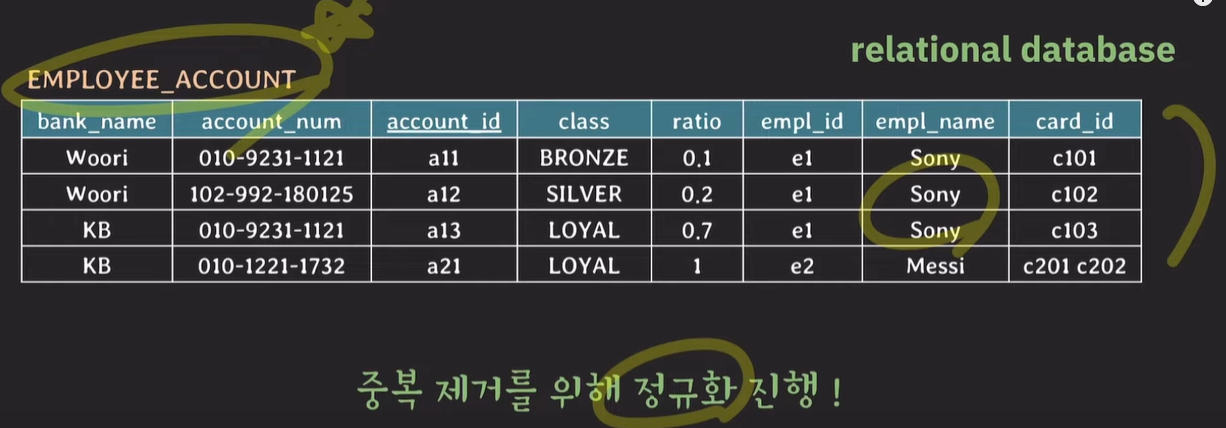
relational database는 데이터 중복을 피하기위해 정규화를 진행한다.
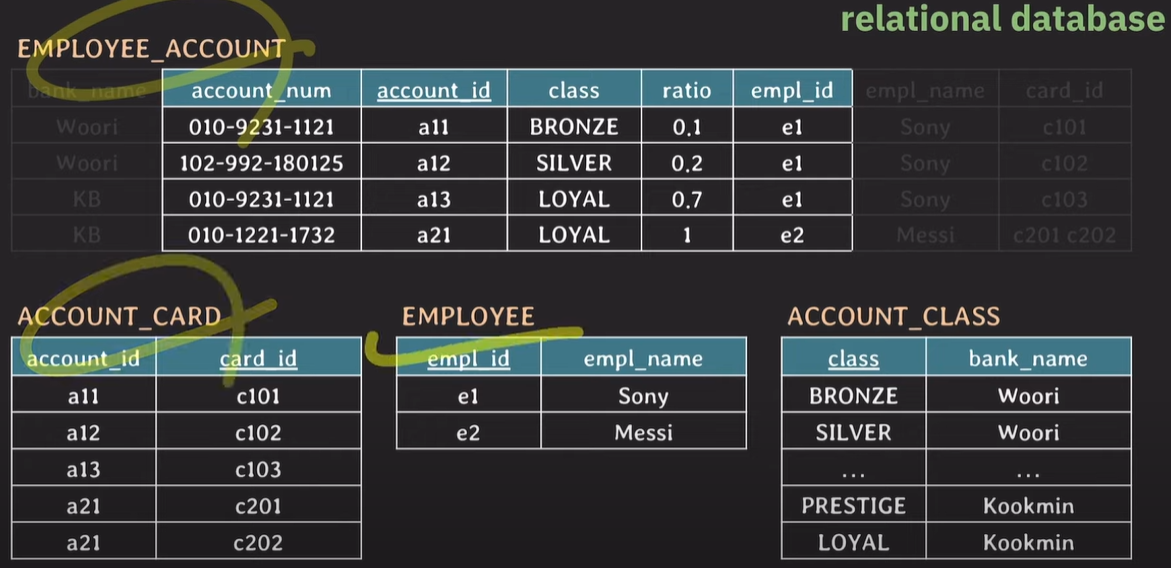
정규화된 테이블에서 데이터를 가져올게 될 경우 join을 사용해야 하고, 복잡한 join은 cpu 사용량이 증가하여 성능이 하락된다.
3. scale-out을 하기 힘들다


RDB는 기본적으로 한대의 컴퓨터에 저장하고 사용한다. 만약 DB서버에 많은 요청이 오게 되어 처리시간이 오래 걸릴 경우 scale up을 통한 database 성능을 향상시켜야한다.
scale up : 더 좋은 성능을 가진 컴퓨터로 교체 (CPU, Memory, HDD, SDD등 교체. DB 서버의 성능 향상)
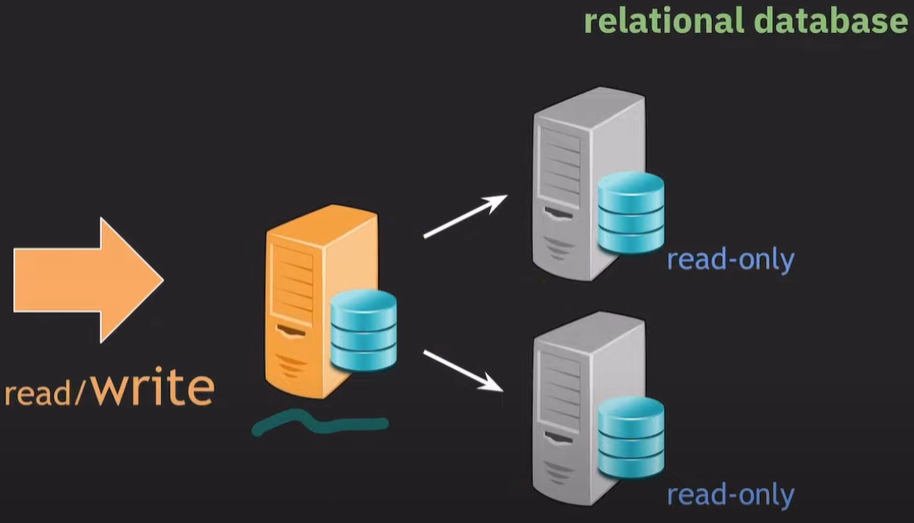
scale out : 데이터 베이스 서버를 추가하여 성능을 향상시킨다.
Replication 후 secondary server는 read-only로만 구성했는데, write 트래픽이 증가하는 경우 primary server에서 모든 write 트래픽을 감당해야한다.
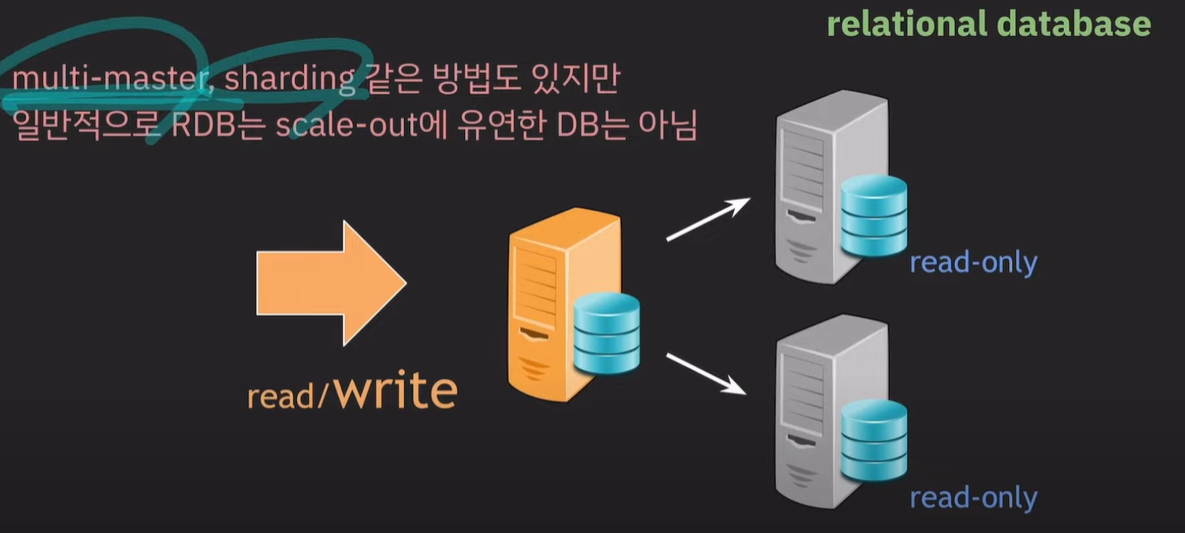
일반적으로 RDB는 scale-out에 유연하지 않다. 서버를 추가하게 되는 경우 데이터를 모두 옮겨주고 복사해야한다.
4. ACID가 성능에 영향

트랜잭션의 ACID는 좋은 기능이지만, 성능에 영향을 미친다.

ACID를 보장하기 위해 성능 측면에 영향을 미친다.
NoSQL의 등장


인터넷의 보급이 활발해 지고 인터넷 사용자가 크게 증가하여, 트래픽이 증가함에 따라 RDBMS만으로 해결하기 어려운 성능 문제가 발생한다.
때문에 high-throughput(높은 응답률), low-latency(짧은 응답시간)이 요구되며, 비정형 데이터의 증가(Schema가 정해지지 않은 데이터)
일반적인 NoSQL의 특징
1. 유연한 스키마
Collection 생성
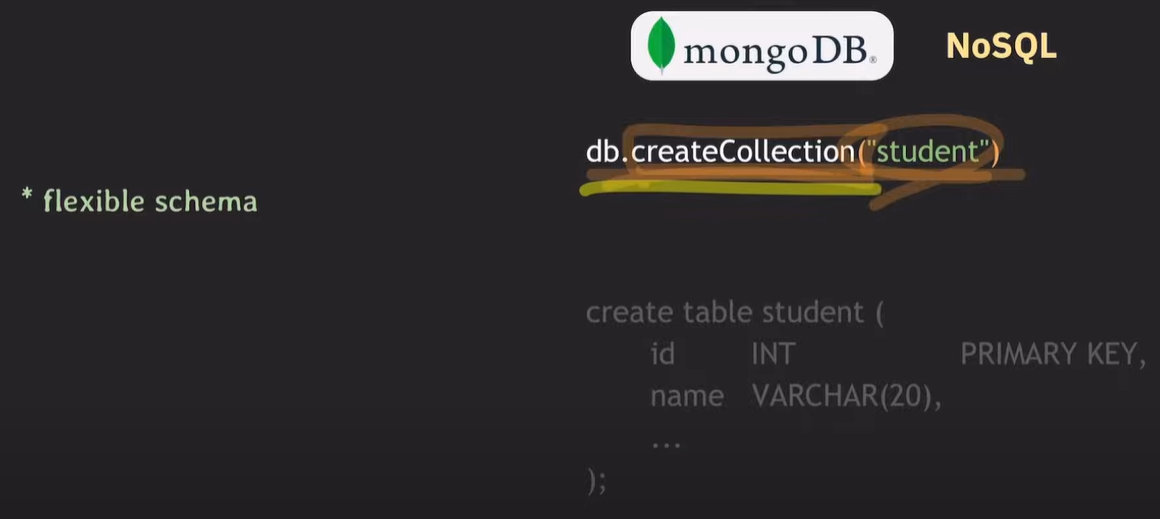
NoSQL의 Collection은 RDB의 테이블에 대응되는 개념
RDB는 스키마를 구성하고 테이블을 생성하는 반면, NoSQL은 Collection을 스키마 구성없이 생성할 수 있다.
db.createCollection("컬렉션명")
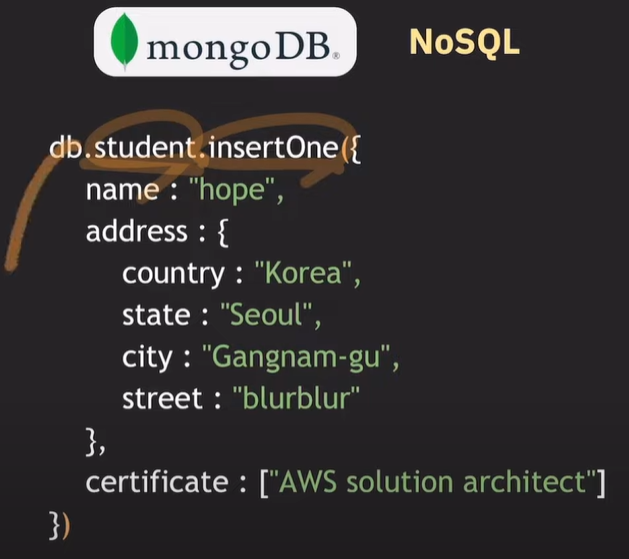
데이터 추가

db.컬렉션명.insertOne({프로퍼티 : 벨류})
스키마가 정의되어 있지 않기 때문에, 원하는 형태로 데이터를 넣고 뺄 수 있다.
몽고DB는 JSON 형태로 값을 받는다.
데이터를 읽고 싶은 경우
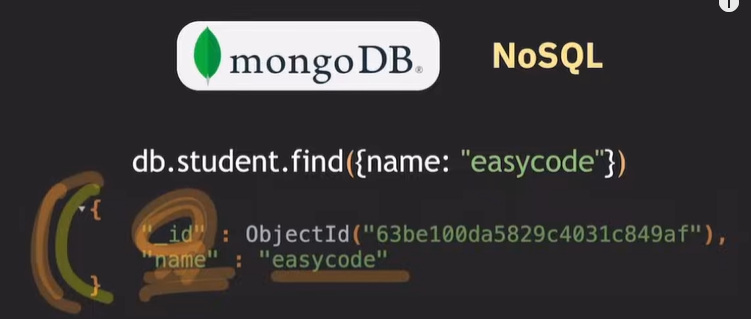
db.컬렉션명.find({프로퍼티 : 벨류})
조건문도 JSON 형태로 작성한다.
RDB에서는 검색된 결과를 Tuple, row라고 부르지만 NoSQL에서는 Document라 부른다.

db.컬렉션.find({})
해당 컬렉션에 존재하는 모든 데이터를 찾는다.
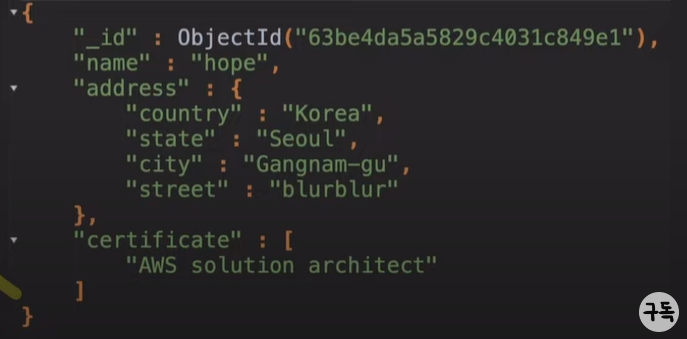
단, RDBMS의 경우 schema 관리를 데이터베이스에서 하지만, NoSQL의 경우 application level에서 schema를 관리해야한다.
2. 중복 허용

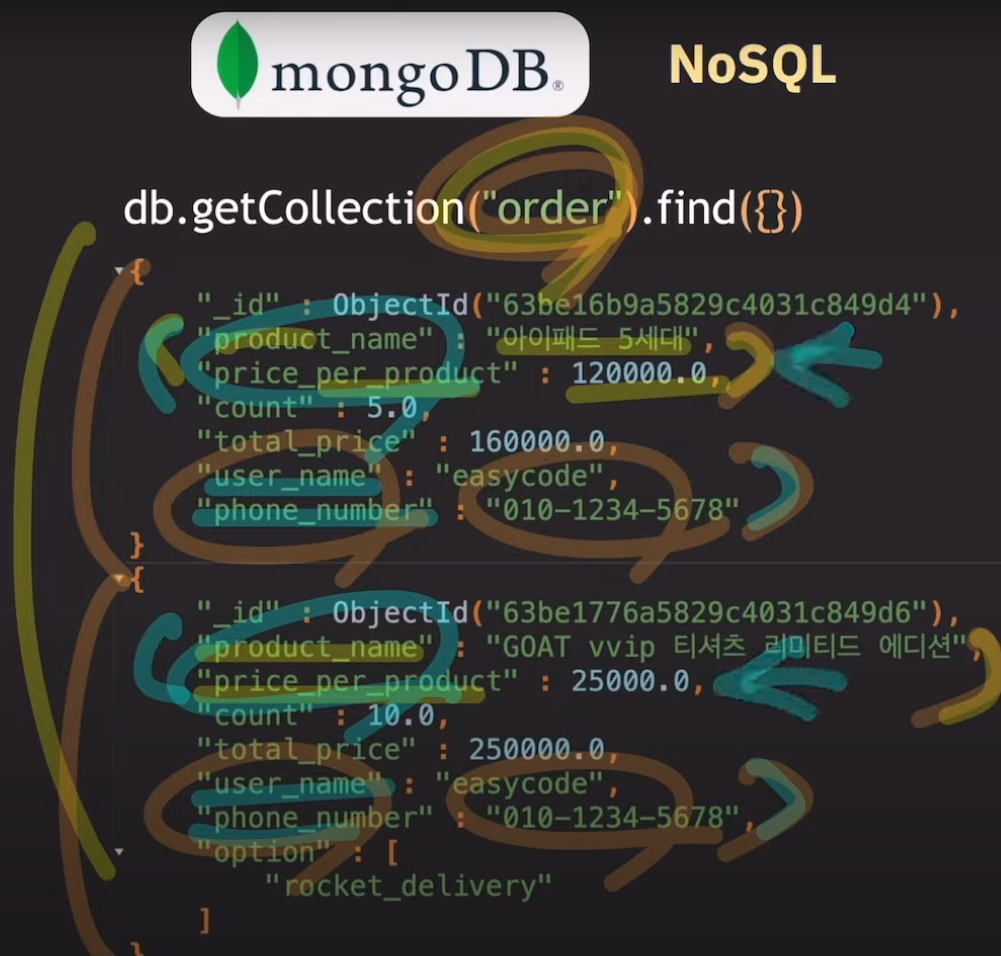
user_name, phone_number등 데이터의 중복이 발생한다. RDB의 경우 중복을 회피하기 위해 정규화를 진행하고 각각의 정보를 서로 다른 table에 저장한다.
join을 할 필요성이 사라지기 때문에 조회속도가 빠르다.
중복된 데이터들이 많기 때문에 application 레벨에서 최신 데이터를 유지할 수 있도록 관리가 필요하다.
3. scale-out이 편리하다.
RBDMS에 비해 scale-out이 편리하여 서버를 증설하기 쉽다.

서버 여러 대로 하나의 클러스터(cluster)를 구성하여 사용 (ex. redis-cluster)
일반적으로 각각의 서버는 데이터들을 나눠서 저장하기 때문에 scale-out을 한다 해서 RDB처럼 데이터를 복사할 필요가 없다. 또한 데이터 중복을 허용하기 때문에 특정 Collection 조회 시 담당 cluster에서 document를 read한다.
4. 높은 처리량

ACID의 일부를 포기하고, high-throughput(높은 응답률), low-latency(빠른 응답)를 추구한다.
금융 시스템처럼 consistency(일관성)이 중요한 환경에서는 사용하기가 어렵다.
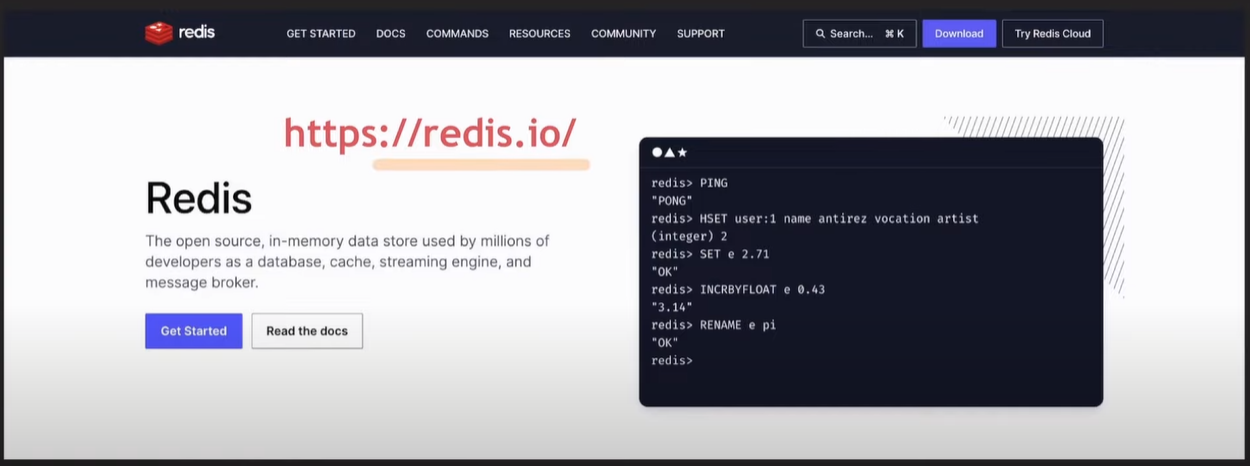
Redis
특징

HDD를 사용하지 않고 메모리를 사용하여 키, 벨류 형태로 (데이터, 캐시)를 저장한다.
redis > SET name easycode
-- SET key value
redis > GET name //easycode
-- GET key
저장 가능한 여러 타입의 데이터를 가질 수 있다.

해시 기반 샤딩 클러스터를 구성할 수 있다.
: 데이터 추가, 검색, 삭제 속도가 매우 빠르다.
고 가용성을 보장한다.
예제
Redis는 Memory를 사용하기 때문에 SSD보다 빠른 처리속도를 가진다.

RDB
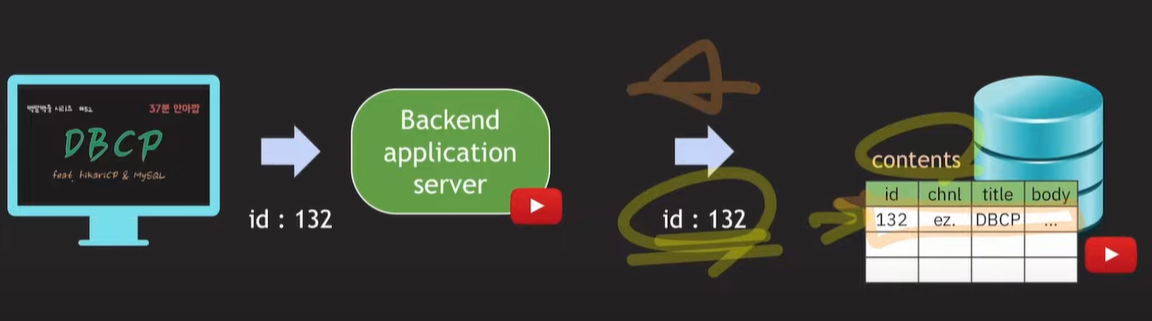
사용자의 요청이 들어오면 백엔드 서버는 값을 처리하고 데이터베이스 서버로 부터 데이터를 read한다.
Redis cache
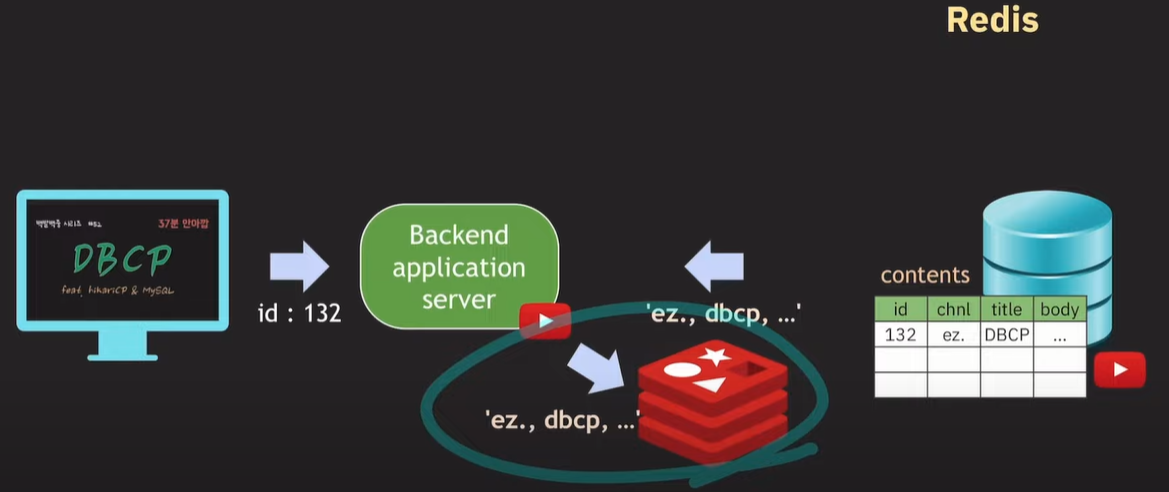
Redis에 데이터(캐시)가 존재하지 않으면, 첫 read는 데이터베이스에서 가져오고 그 이후에 백엔드 서버는 redis에 해당 데이터를 저장하여 캐시로 사용한다.
(키:벨류) 형태로 저장하며 타임아웃을 설정할 수 있다.(몇초간 유지, 생명주기)
백엔드 서버에서는 우선 레디스를 확인하고, 캐시되어있으면 캐시값을 응답해주고, 캐시가 없는 경우 데이터베이스를 read하고 캐시로 저장한다.