Order by, Aggregate function, Group by
Order by

조회결과를 특정 attributes(column)을 기준으로 정렬, ASC 오름차순 DESC 내림차순 (기준이 되는 컬럼을 1개이상 가능하다)
ORDER BY salary DESC (급여 내림차순)
ORDER BY dept_id ASC, salary DESC (부서번호를 먼저 오름차순 후 급여에 대해 내림차순으로 정렬)
aggregate function

여러 tuple들의 정보를 요약해서 하나의 값으로 추출하는 함수(하나의 요약값)
대표적으로 count, sum, max, min, avg 함수가 있다.
null값들은 제외하고 요약 값을 추출한다.
임직원의 수를 알고 싶다 : select count(*) from employee;
== select count(id) from employee; (null이 없는 경우)
count 함수는 tuple의 갯수를 센다. 중복에대한 값이 존재해도 중복값을 포함한다. (null인 경우 포함X)
null이 존재할 수 있는경우 *를 이용하여 모든 tuple의 수를 세는것이 좋다.
예제

SELECT count(*), max(salary), min(salary), avg(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
WHERE W.proj_id = 2002;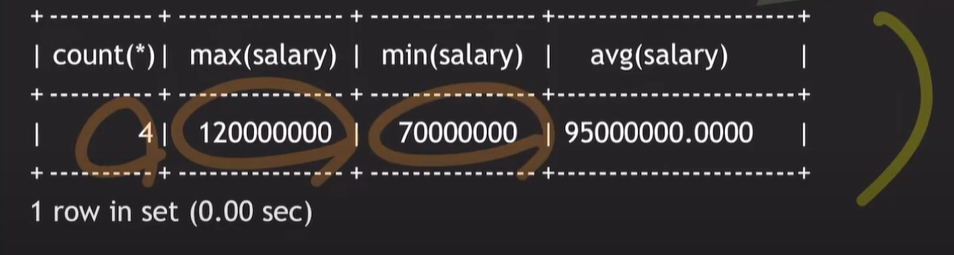
Group by

프로젝트 2002에 참여한 임직원이 아닌, 프로젝트 별로 데이터를 알고 싶은 경우
SELECT W.proj_id, count(*), max(salary), min(salary), avg(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
GROUP BY W.proj_id;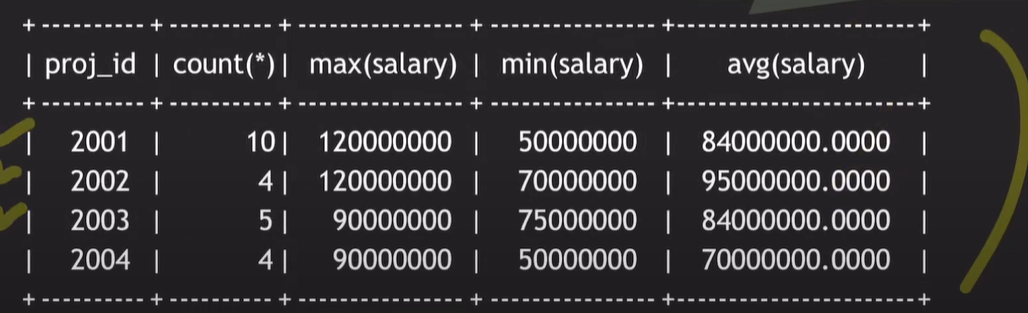
works_on 테이블의 proj_id 별로 그룹(통합)되어 데이터가 출력된다.
기준이 되는 attribute를 반드시 select 해야 된다.
HAVING

GROUP BY와 같이 사용되고, 결과값을 바탕으로 그룹을 필터링하고 싶을때 사용한다.

GROUP BY에 대한 데이터들(결과)에 대해서 조건을 작성한다.
SELECT W.proj_id, count(*), max(salary), min(salary), avg(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
GROUP BY W.proj_id
HAVING count(*) >= 7;
예제

GROUP BY의 기준이 되는 attribute의 값이 NULL인 경우 NULL값을 가지고 있는 데이터끼리 그룹이 된다.
NULL을 가지고 있는 tuple끼리 그룹을하고 count한것.

부서별, 성별로 그룹되어 각각 count한다.
GROUP BY dept_id, sex

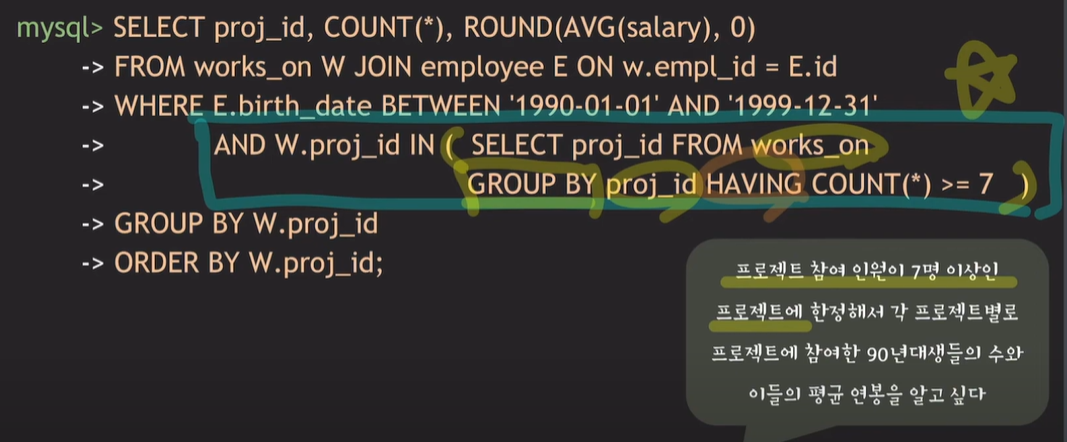
Having에 count(*) >= 7을 작성할 경우 참여인원의 수를 조건으로 작성한것이 아니라 90년대생의 수를 조건으로 사용하기 때문에 Where의 조건으로 서브쿼리를 작성해야한다.


