Stored Procedure

예제
예제1


CREATE PROCEDURE 프로시저명(IN 변수1 자료형, IN 변수2 자료형, OUT 변수3 자료형)
인풋 파라미터와 아웃풋 파라미터를 작성한다.
BEGIN
프로시저 정의;
END
call 프로시저명(파라미터, 파라미터, @사용자 정의 변수);
select @사용자 정의 변수;데이터 베이스내에서 사용자 정의 변수를 사용하기 위해선 @를 접두사로 사용한다.
결과를 아웃풋 파라미터로 작성해야한다! Function의 경우 RETURN 키워드로 값을 바로 반환받는게 가능하지만 프로시저의 경우 불가능하다.
예제2

a와 b는 값을 전달 받는것과 동시에 값을 반환할 수도 있다. (INOUT)
IN : 값을 전달 받을 수 있지만 반환 불가
OUT : 값을 전달 받을 수 없지만 반환이 가능
INOUT : 둘다 가능하다.

SET @a = 5, @b = 7;
사용자 정의 변수를 설정하여 값을 대입한다.
call swap(@a, @b);
프로시저를 호출하여 정의된 내부 구현이 동작한다.
select @a, @b;
프로시저의 동작 결과를 확인예제3

select get_dept_avg_salary()
-- select를 작성할 시 결과를 반환할 수 있다.예제4
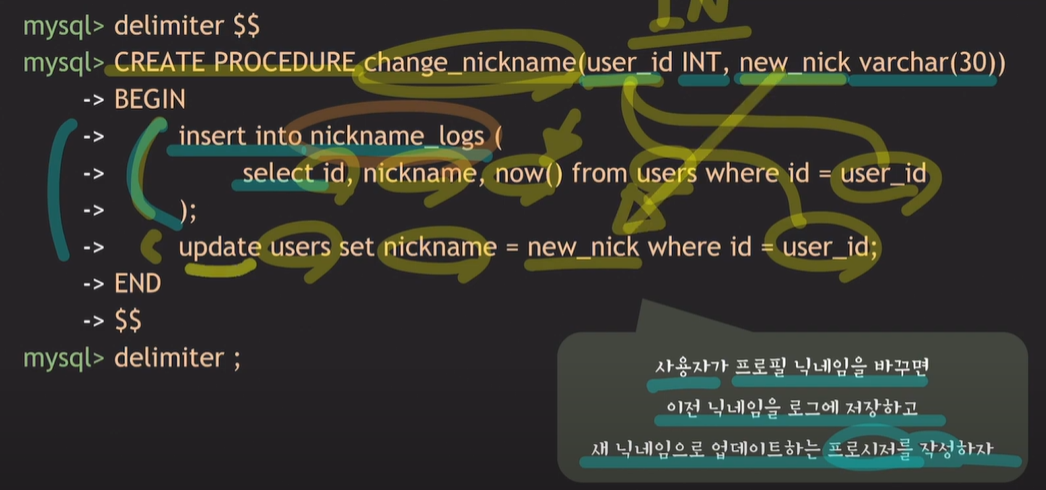
인풋 파라미터 예약어인 IN은 작성하지 않아도 default로 동작한다.
닉네임이 변경될 시 로그를 남기는 테이블에 id, 닉네임, 현재시간을 users 테이블에서 가져온 후 insert 하며, 새로운 닉네임은 users 테이블의 닉네임으로 업데이트 한다.
반환값이 없다.

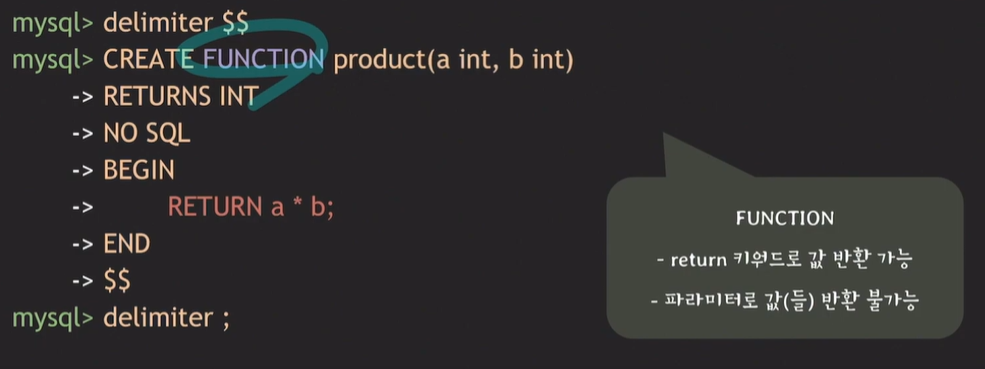
Procedure vs Function


프로시저의 경우 return 키워드로 값을 반환하는것이 불가능하기 때문에 값을 반환하려면 반드시 파라미터를 활용해야한다.
프로시저의 경우 반환값이 없어도 되지만, 함수의 경우 반환값이 필수이다.

프로시저의 경우 SQL상태에서 호출이 불가능하지만, 함수의 경우는 가능하다.
★ 프로시저는 트랜잭션사용이 가능하지만, 함수는 대부분 불가능하다.
★ 프로시저는 주로 비즈니스 로직에서 사용한다.
★ 함수는 주로 복잡한 계산을 처리하는 용도로 사용한다.

RDBMS마다 차이가 존재.
예시
procedure

function
실무에서 사용하기 조심스러운 이유

three tier architecture
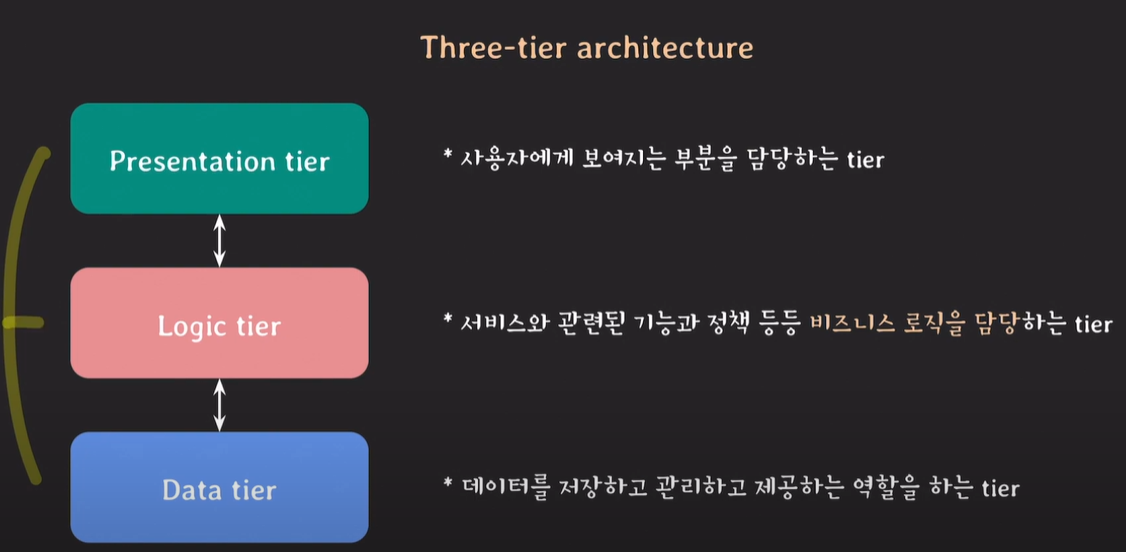
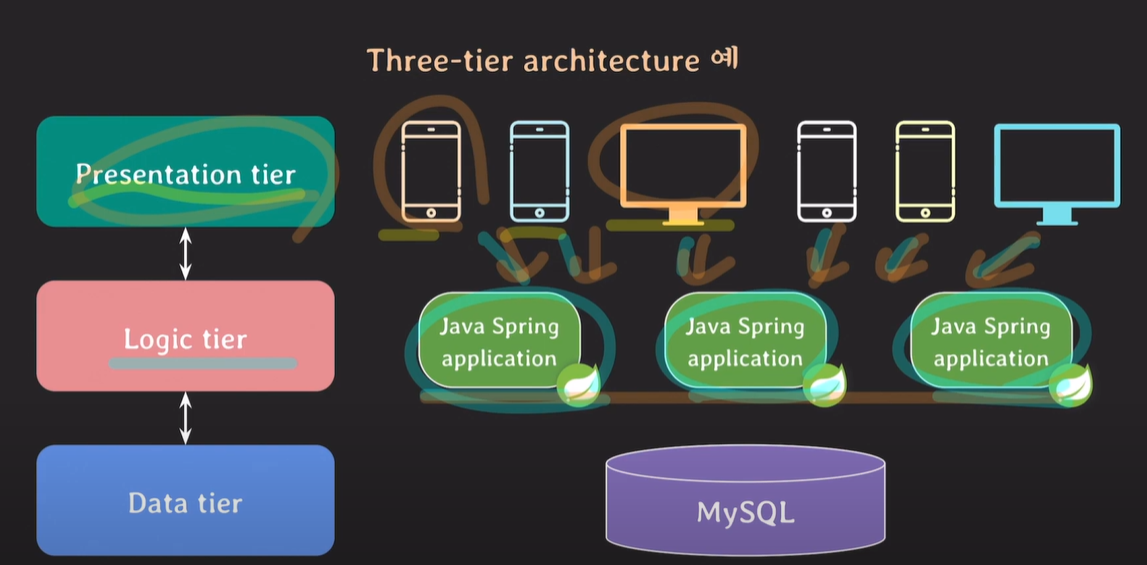

프로시저의 장,단점
프로시저가 주로 비즈니스 로직을 처리하기 위해 생성하는데, Data tier에서 비즈니스 로직이 존재하는게 맞을까?
장점
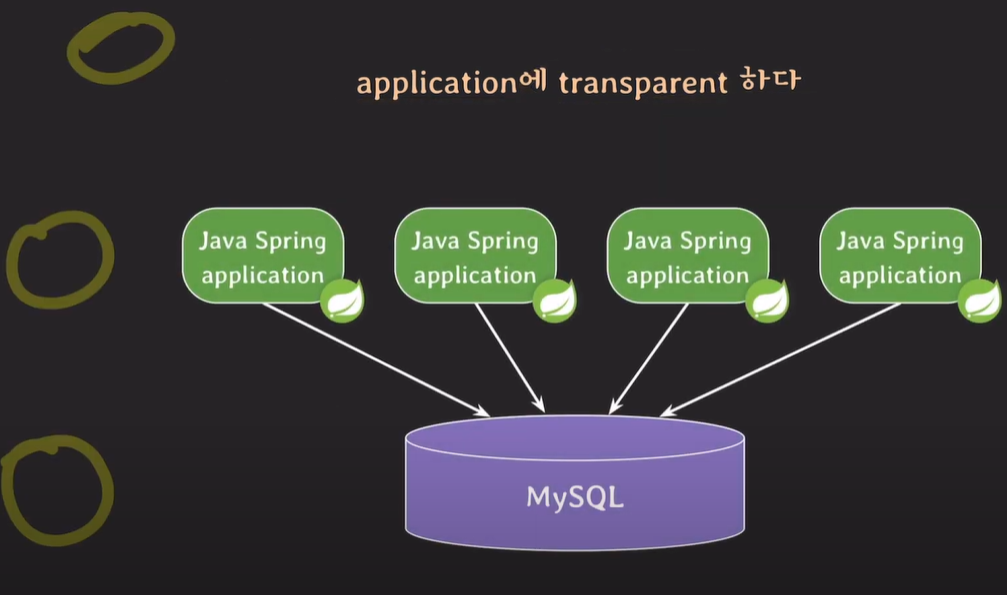
로직티어의 애플리케이션들을 교체하거나, 수정할 때 데이터 티어에 존재하기 때문에 프로시저는 분리되어있다.
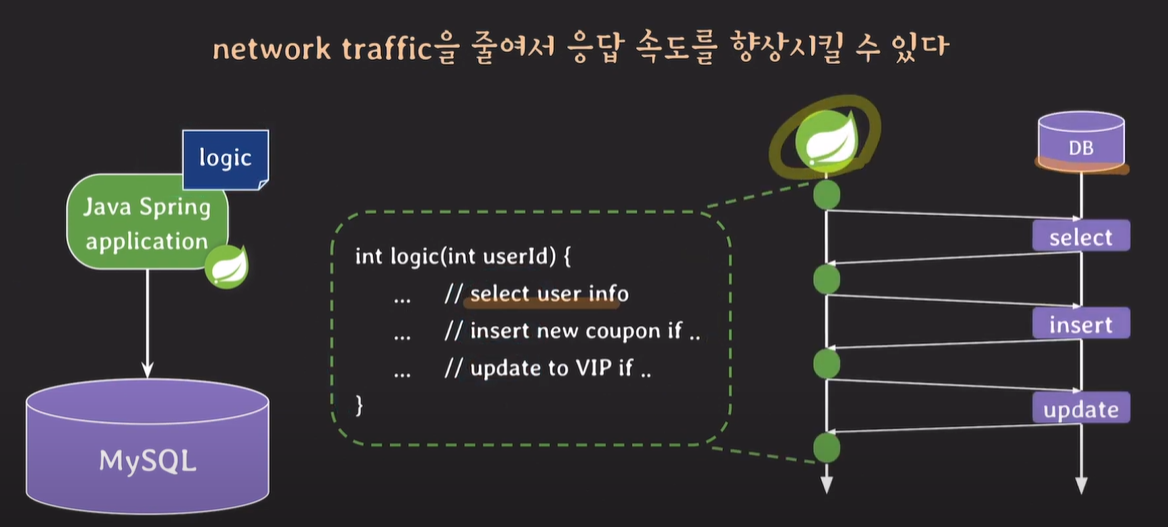
select -> insert -> update를 해야하는 비즈니스 로직인 경우 데이터 베이스와 로직 서버가 다수 통신해야하기 때문에 속도가 느릴 수 있다.
프로시저를 사용할 경우
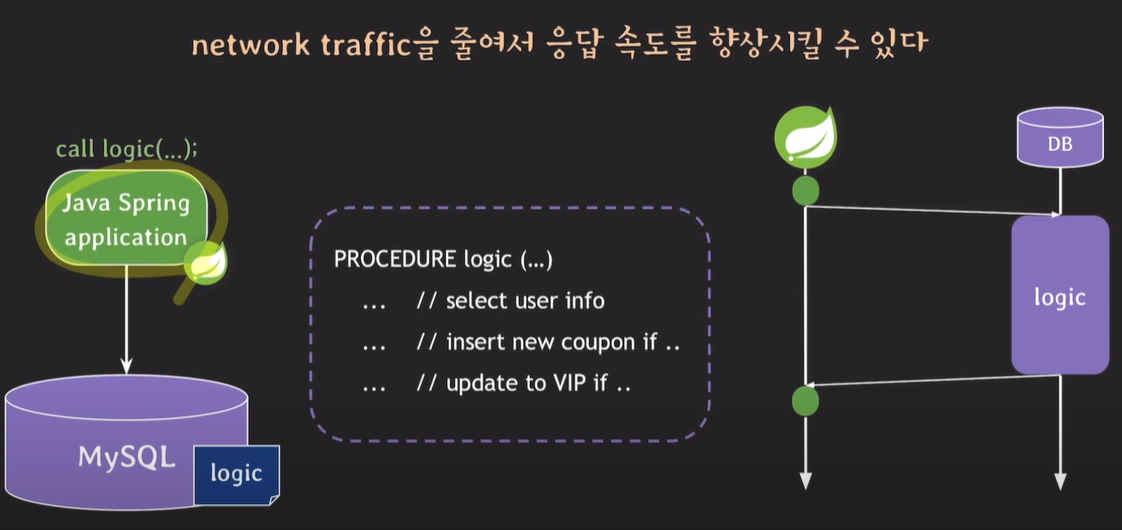
한번의 네트워크 통신으로 로직처리가 가능하다.
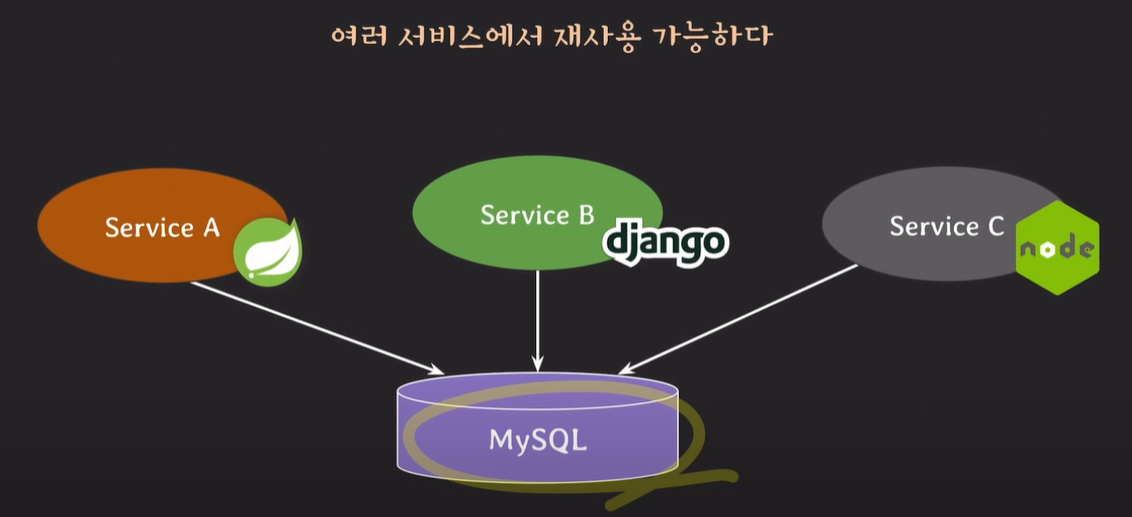
요즘은 서비스 별 언어 및 개발 프로젝트가 다르다. 각각 정의하여 사용하는게 아닌, 공통적인 데이터 베이스를 사용할 경우 데이터 베이스에서 한번에 관리가 가능하다.
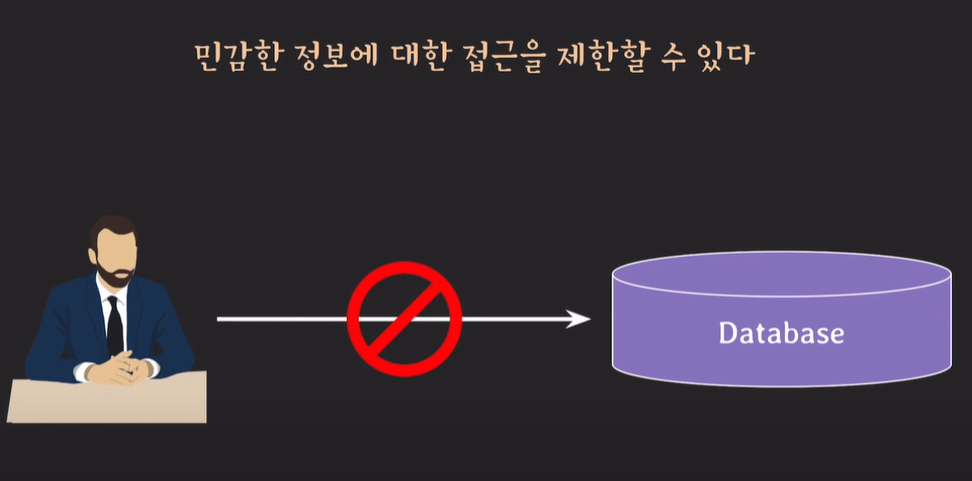
민감한 정보에대해 로직을 통해 접근하는것을 막고, 프로시저를 통한 접근만 허용하게 할 수 있다.
단점

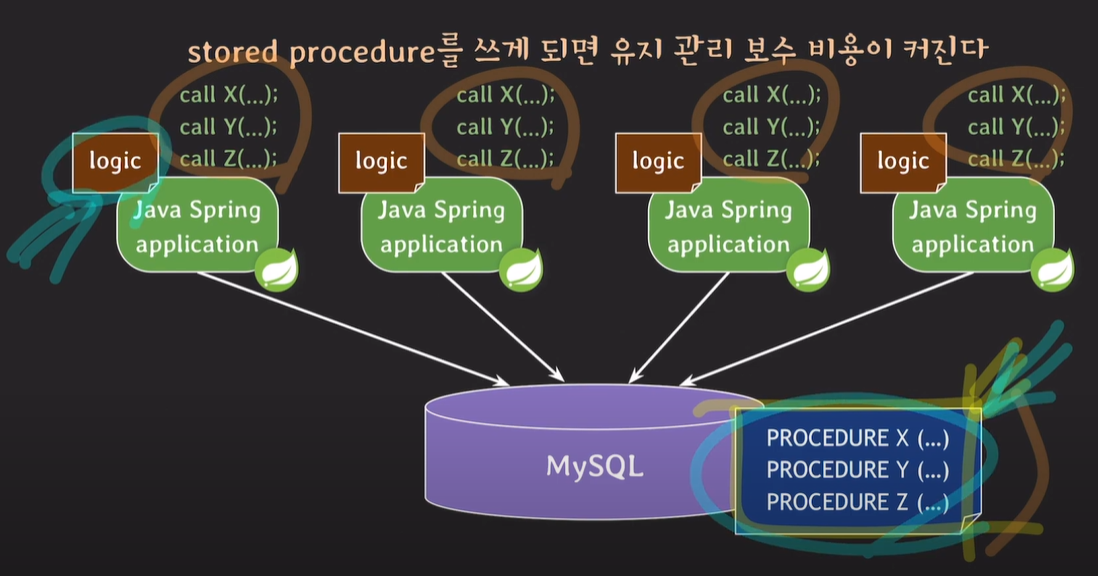
비즈니스 로직이 애플리케이션 서버와 분리되어있기 때문에 유지 관리가 힘들다. 신규 기능 개발시 애플리케이션 서버에서도 개발해야하고 Data tier에서도 프로시저를 그에 맞게 개발해야한다.
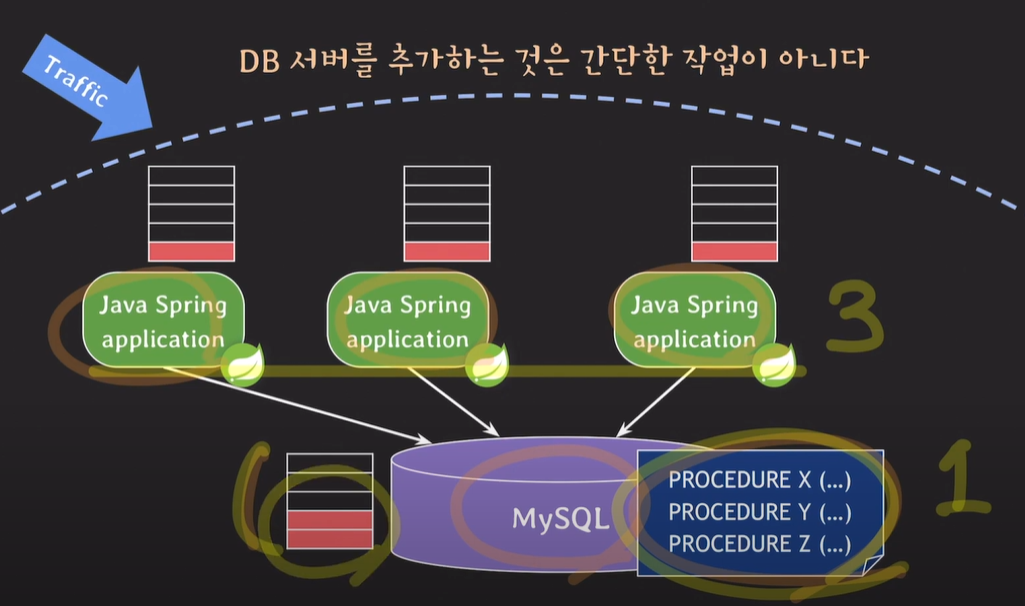
애플리케이션 서버 3대에서 사용자의 요청을 받고 데이터베이스 서버로 클라이언트의 요청에 맞게 데이터를 요청한다. 데이터베이스 서버는 현재 1대이기 때문에 부하가 많이 올 수밖에 없다.
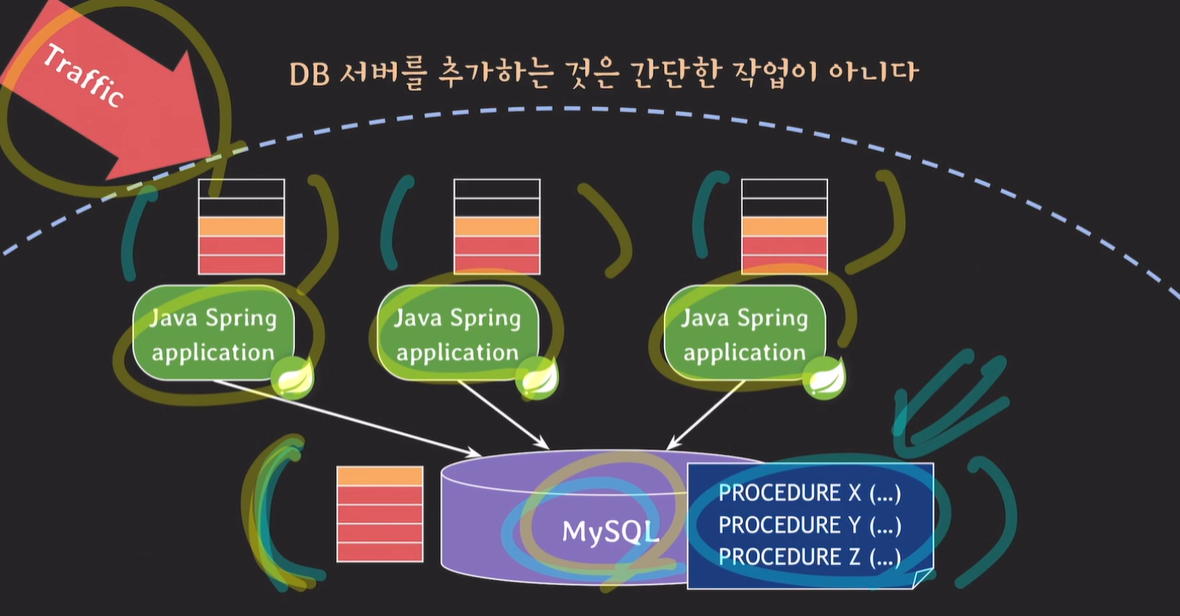
트래픽이 더 많이 생길경우 애플리케이션 서버는 버틸 수 있지만, 데이터베이스 서버는 과부하가 올 가능성이 있다. 데이터베이스 서버를 증설해야하지만, 데이터베이스 서버를 추가하는일은 상당히 어려운 일이다. 데이터 베이스 서버를 증설하려면 모든 데이터도 복제해주어야하기 때문이며, 애플리케이션 서버는 기본적으로 상태가 없기 때문에 빠르게 추가가 가능하다.
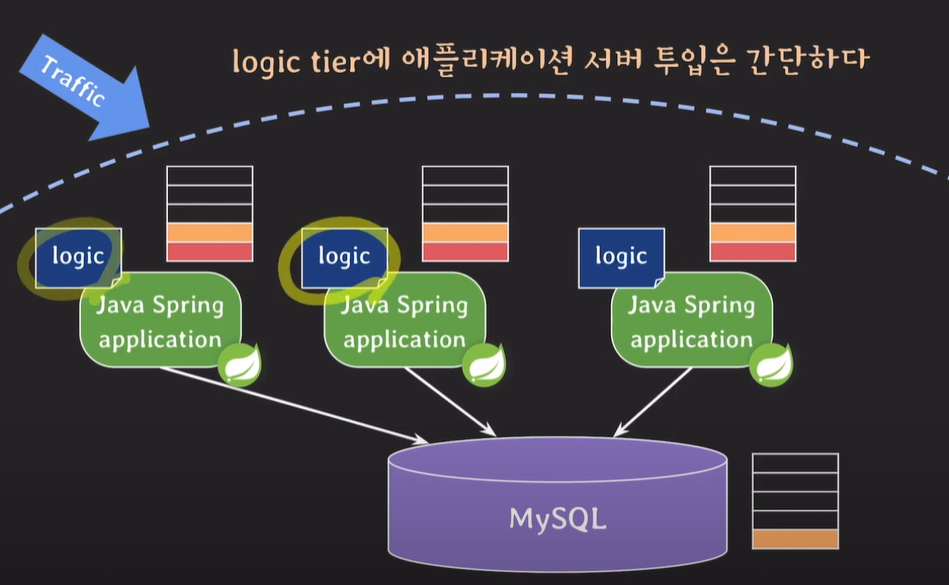
프로시저가 없고 모든 비즈니스 로직이 애플리케이션 서버에 있을 경우 애플리케이션 서버에 부하가오지만, 애플리케이션 서버를 증설하는 일은 비교적 쉽다. (클라우드 서비스, 오토 스케일링)
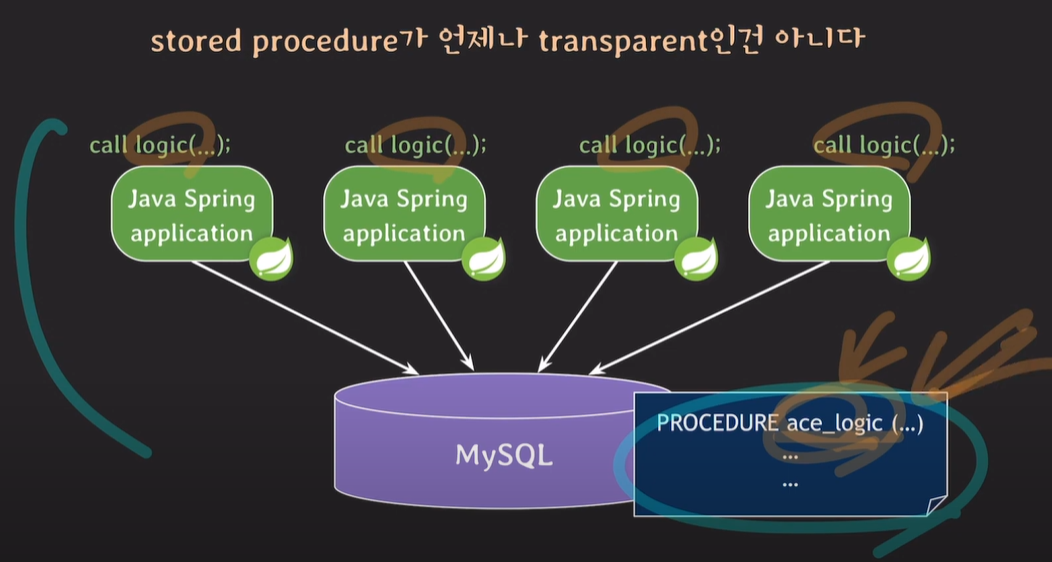
프로시저의 변경이 일어날 경우 애플리케이션 서버를 변경하고, 모든 서버를 재가동해야한다. 소스 코드에 로직이 있는 경우보다 오히려 손이 더 많이 갈 수 있다.
call logic() >> call ace_logic()
데이터베이스 프로시저 변경이 있을 경우 애플리케이션 로직도 변경되어야하면 재기동이 필요하다.
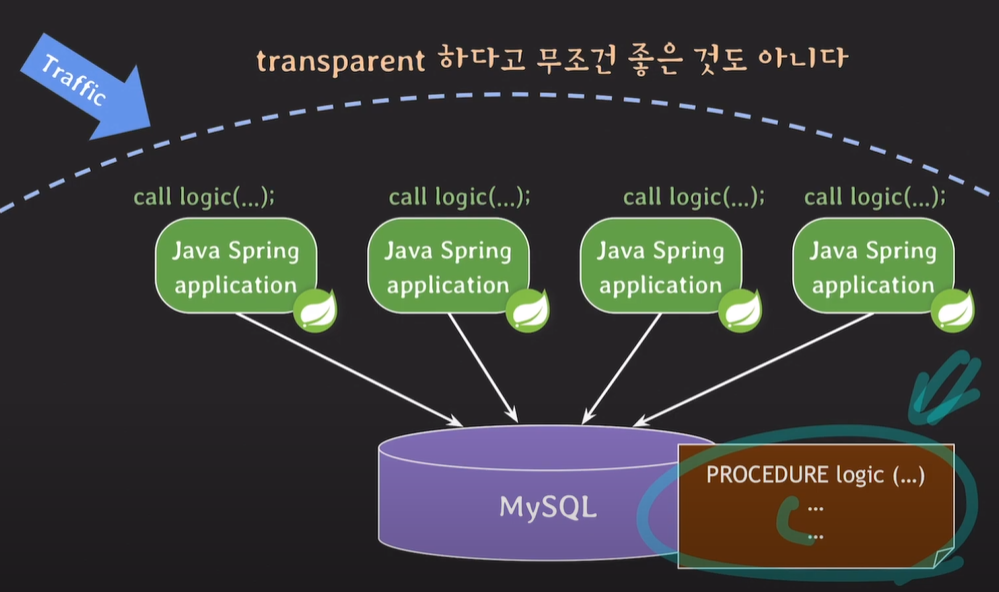
프로시저를 사용하지 않고 응답속도를 빠르게 하는방법
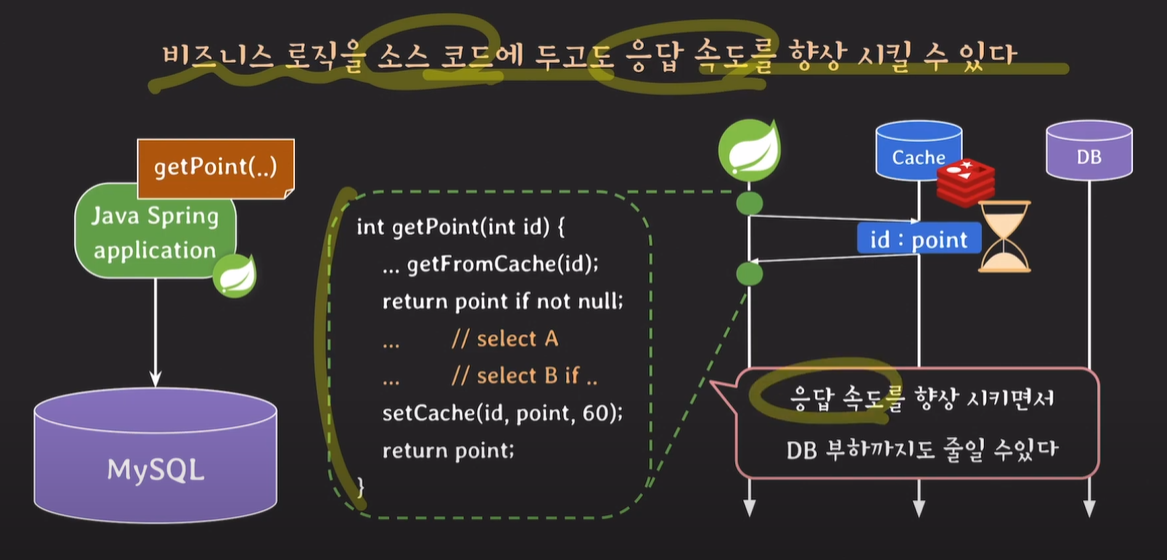
한번 조회한 데이터는 캐시에 놓고, 캐시에서 조회한다. 캐시에 존재할 경우 데이터베이스 서버와 통신하지 않아도 된다.

