관계형 데이터베이스, 기본키, 외래키, constraints
관계형 데이터베이스
수학에서 relation
set
서로 다른 elements를 가지는 collection
하나의 set에서 element 중복이 없으며 elements의 순서는 중요하지 않다.
e.g.{1,3,11,4,7}
relation

set A와 set B의 pair 생성
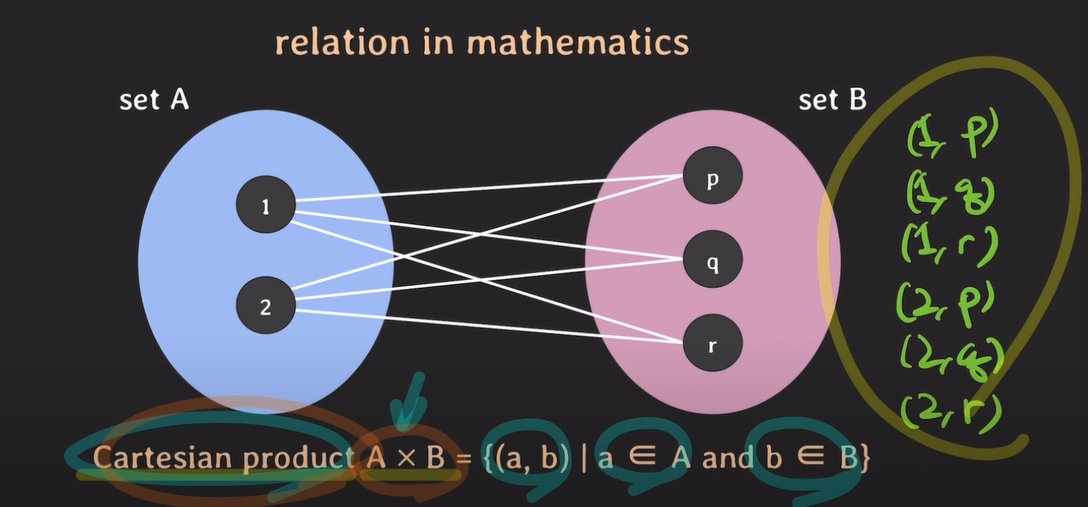
Cartesian product의 부분집합 -> set이 2개 Binary relation
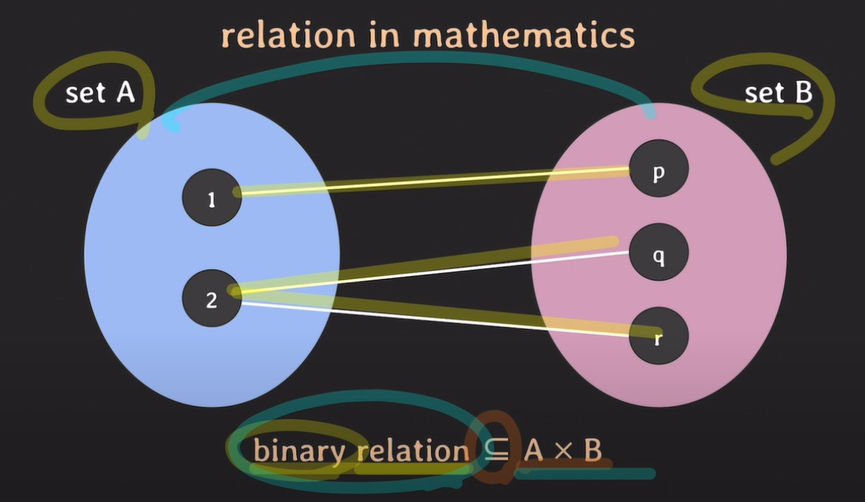
n개의 set이 존재하는 경우 -> n-ary relation

tuple : 엘리먼트들로 이루어진 리스트, 각각의 리스트
n-tuple : n개의 엘리먼트들로 이루어진 리스트.
정리
수학에서의 relation
- Cartesian product의 부분 집합
- 튜플들의 set(집합)
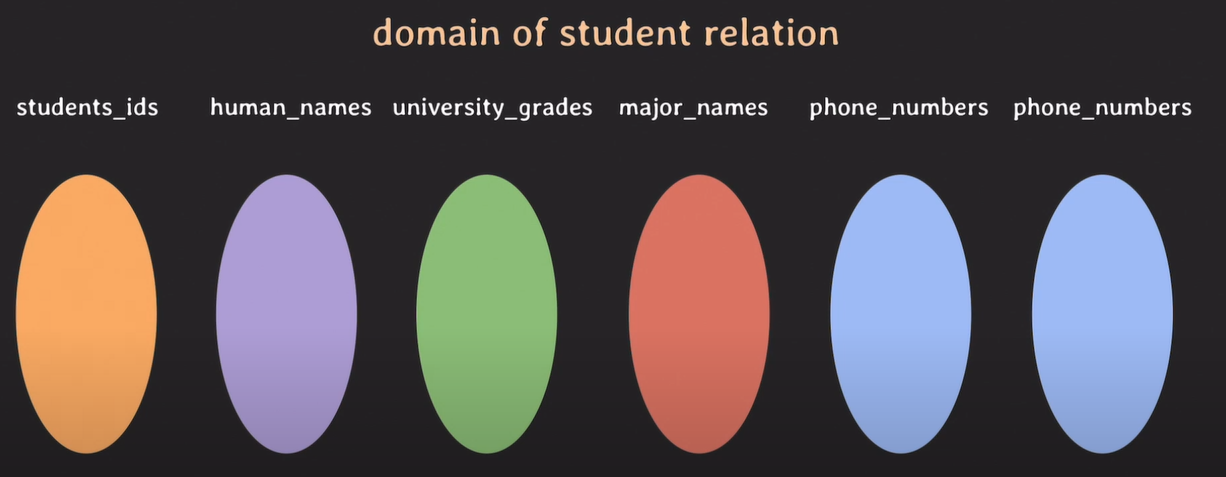
relation data model

학생 전화번호에 비상연락망을 추가하여 저장하고 싶다. phone_numbers가 2개 존재한다.
도메인마다 각각의 목적, 역할에 맡게 attribute가 존재한다.
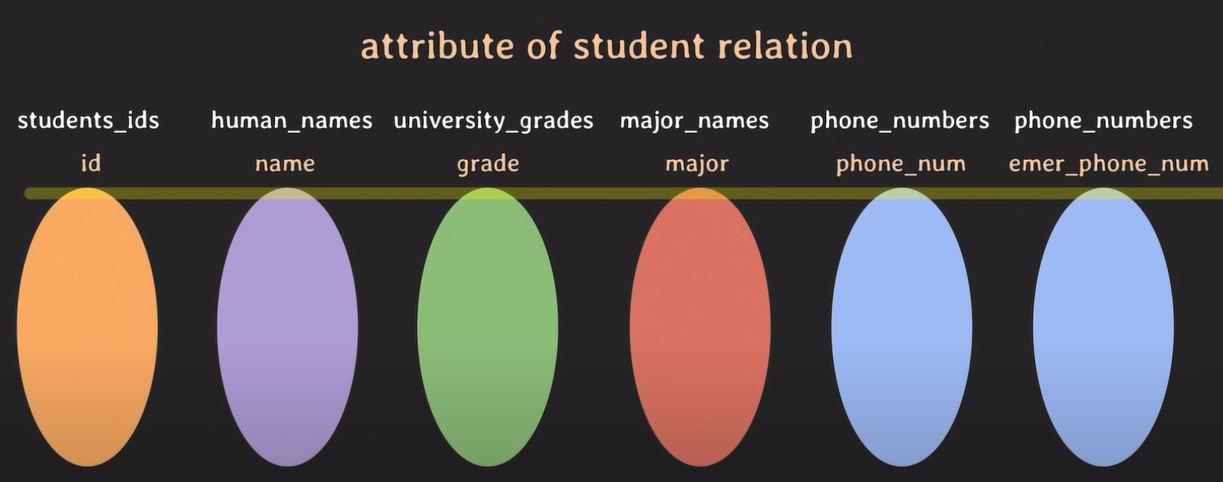
각 도메인마다 데이터가 존재하고, 데이터들 끼리 연결되어 튜플을 형성한다.
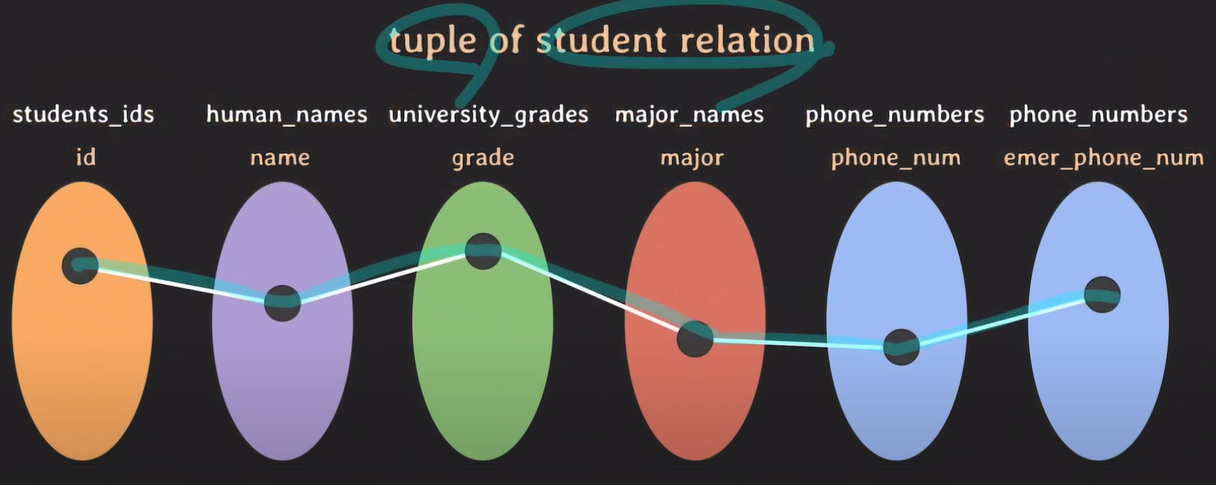
relation을 표현하기에 테이블이 적합하다.
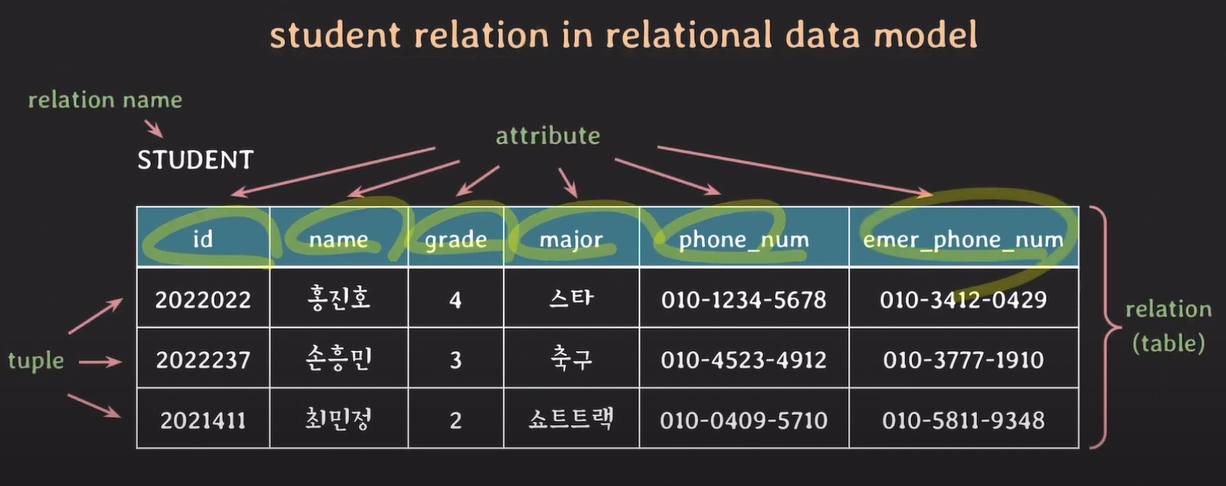
relation : 하나의 테이블
attribute : 목적에 맡는 속성
tuple : elements들로 이루어진 리스트
주요 개념 정리
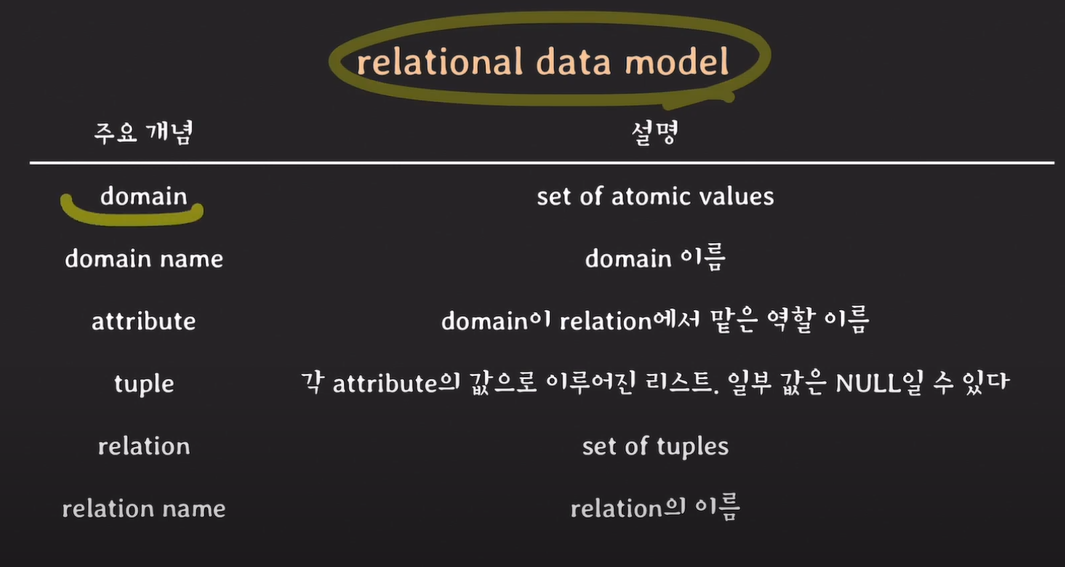
domain : 더이상 나누어 질 수 없는 값의 집합
attribute : domain이 relation에서 맡은 역할 이름
tuple : 각 attribute의 값으로 이루어진 리스트. 일부 값은 NULL일 수 있다.
relation schema

STUDENT : relation 이름
(id,name,grade... emer_phone_num) : attributes 리스트
degree of a relation

relation의 차수(정도), relation schema에서 attributes의 수
relation database

relation database는 여러 개의 relations로 구성된다.
relation database schema

relation schema들의 집합 + integrity constraint들의 집합
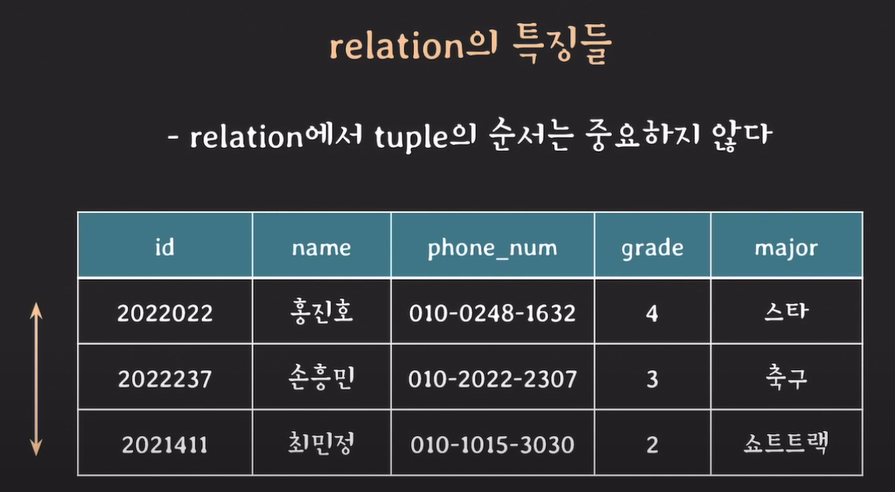
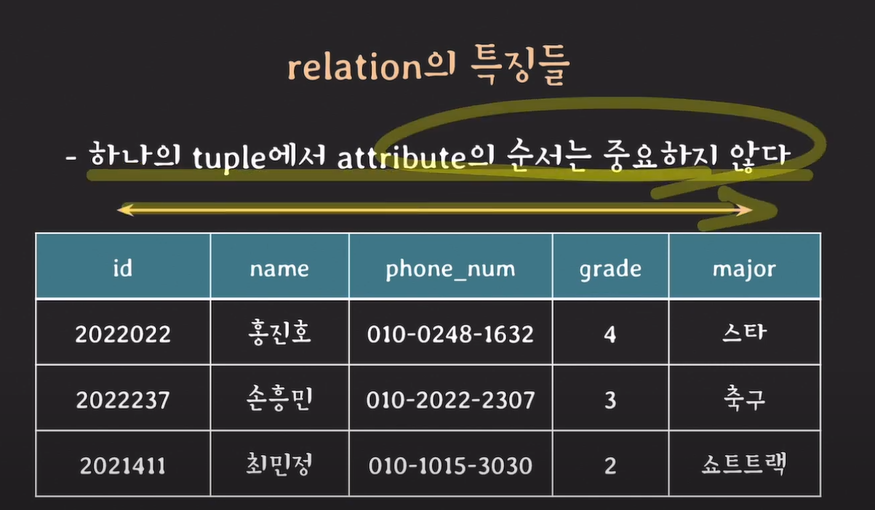
relation의 특징
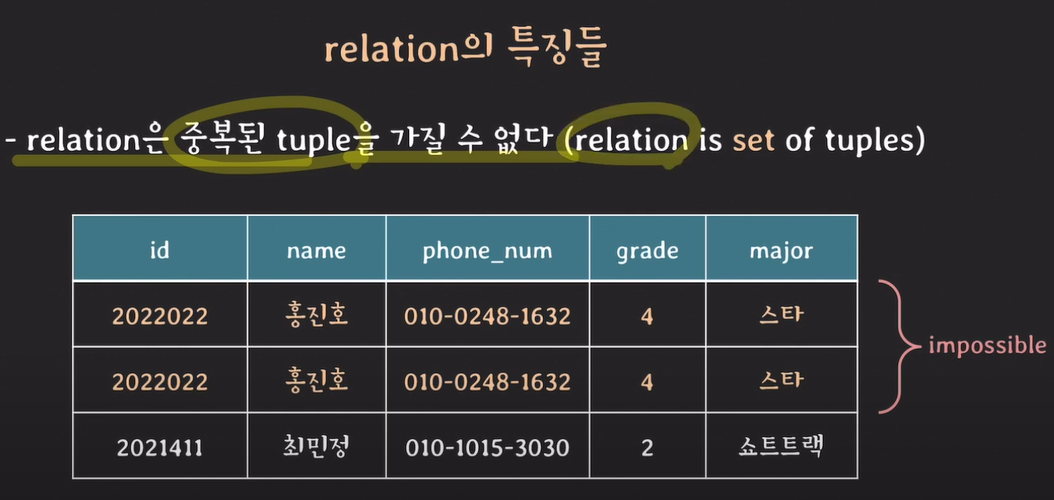
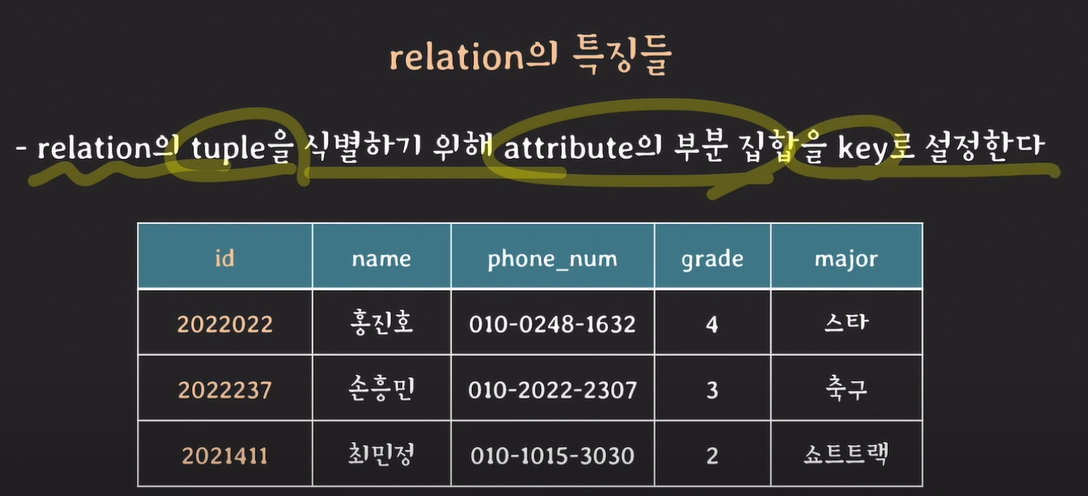
id를 통해 학생들을 고유값으로 식별한다.

address는 서울특별시/ 강남구/ 청담동으로 나뉘어질 수 있다.(=composite)
major는 나뉘어질 수 있다.(여러가지 값 존재 = multivalued)
NULL의 의미

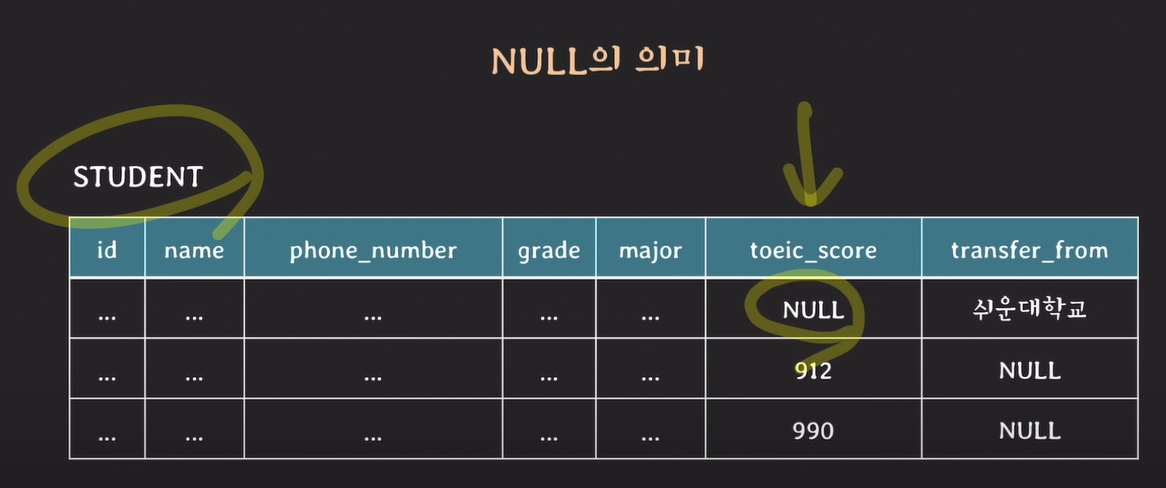
토익점수 또는 편입학생인지에 대한 데이터
keys
superkey

relation에서 tuples를 unique하게 식별할 수 있는 attributes set
cadidate key

어느 한 attribute라도 제거하면 unique하게 tuples를 식별할 수 없는 super key
primary key

relation에서 tuples를 unique하게 식별하기 위해 선택된 candidate key
unique key

primary key가 아닌 candidate keys
foreign key
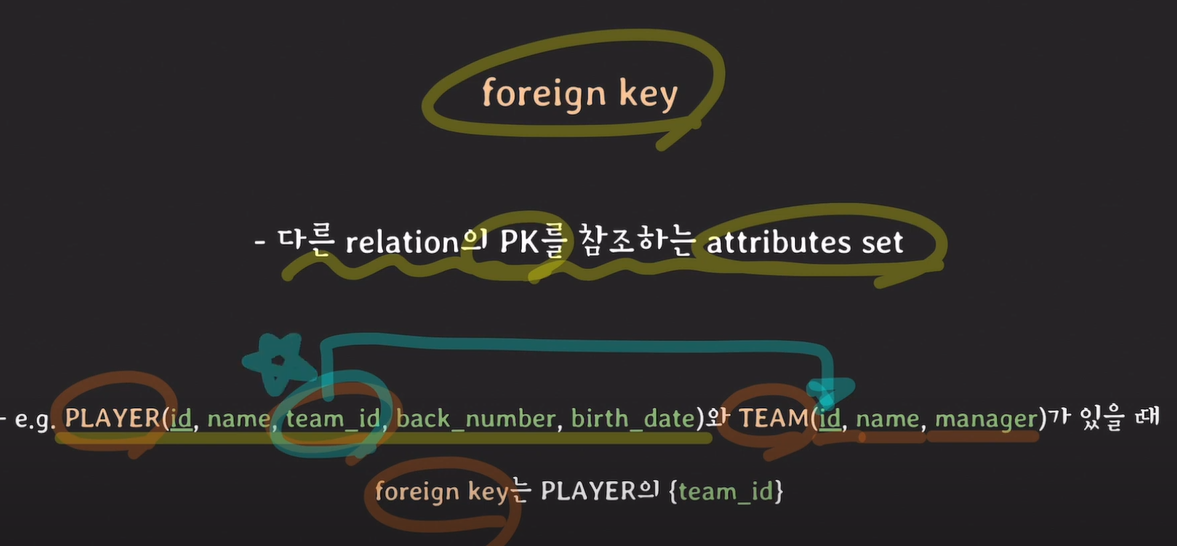
다른 relation의 PK를 참조하는 attributes set
PLAYER의 team_id는 TEAM의 id를 참조하는 외래키이다.
constraints

implicit constraints

relational data model 자체가 가지는 constraints
schema-based constraints

주로 DDL을 통해 schema에 직접 명시할 수 있는 constraints
explicit constraints
domain constraints

grade(학년)은 1~4만 가능하다.
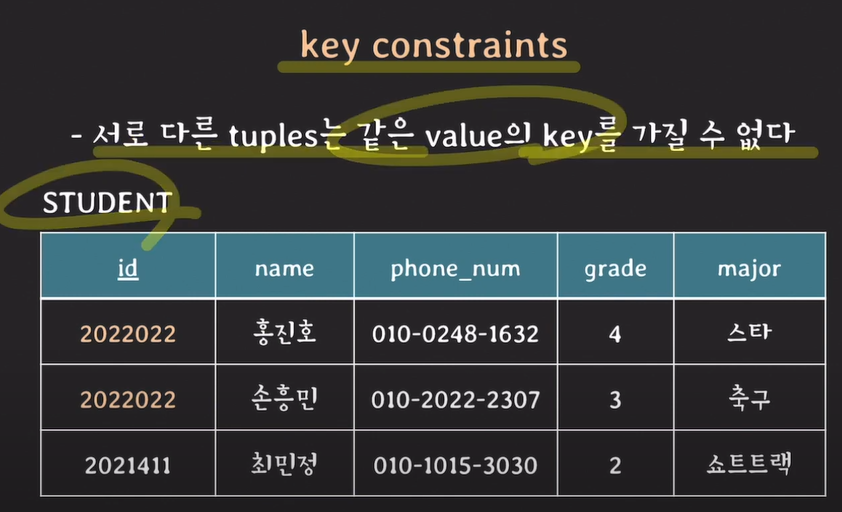
key constraints
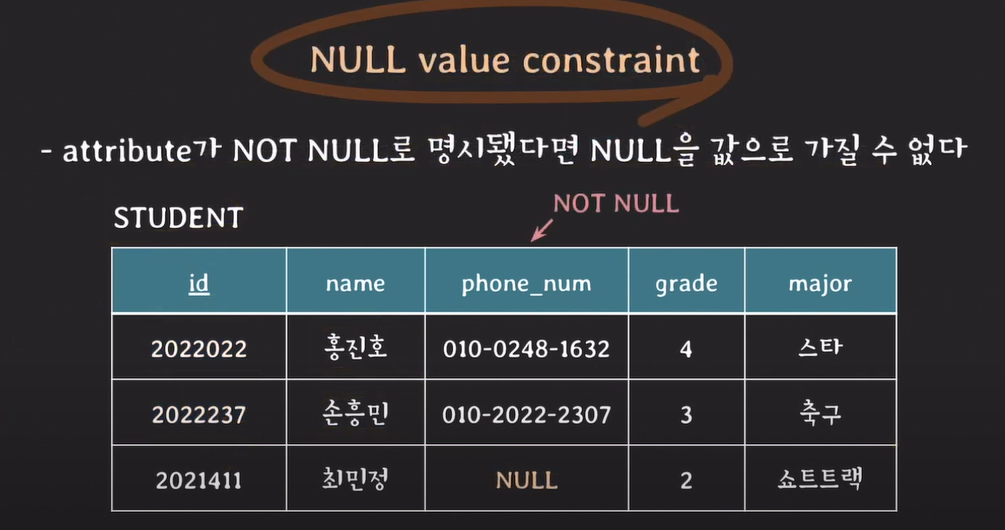
Null value constraints
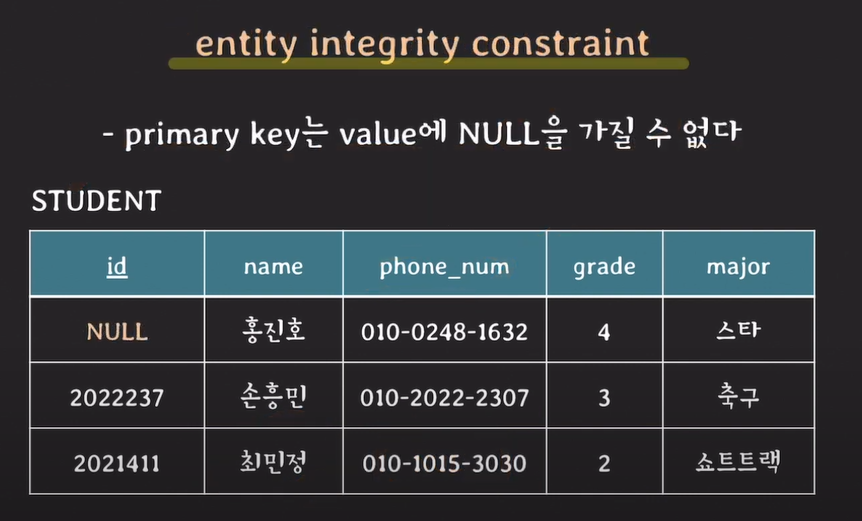
entity integrity constraint
referential integrity constraint

PK에 없는 values를 FK가 값으로 가질 수 없다.
FK는 다른 relation의 PK를 참조해야한다.
