Concurrency control
동시성 예제

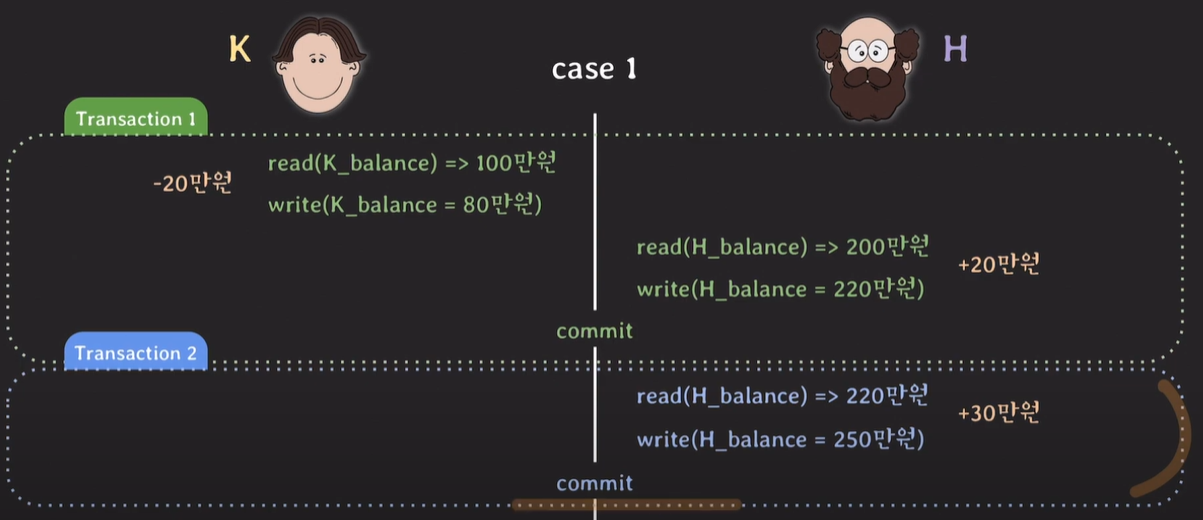
case 1.
case 2.

case 3.

case 4.

K계좌에서 20만원을 출금하고 H의 계좌에 200만원이 있는것을 확인 한 후 다른 트랜잭션이 시작이되고, H계좌에 30만원이 입금이되고, 트랜잭션이 끝난 후 H의 계좌에는 230만원이 존재하고, 기존 트랜잭션은 read한 200만원에 20만원을 입금한다.
총 250만원이 되어야 하지만, 하나의 트랜잭션이 동작 중 같은 데이터에 접근하여 read, write한 상황 이런 현상을 Lost Update라 부른다. (업데이트 된 데이터가 사라진다)
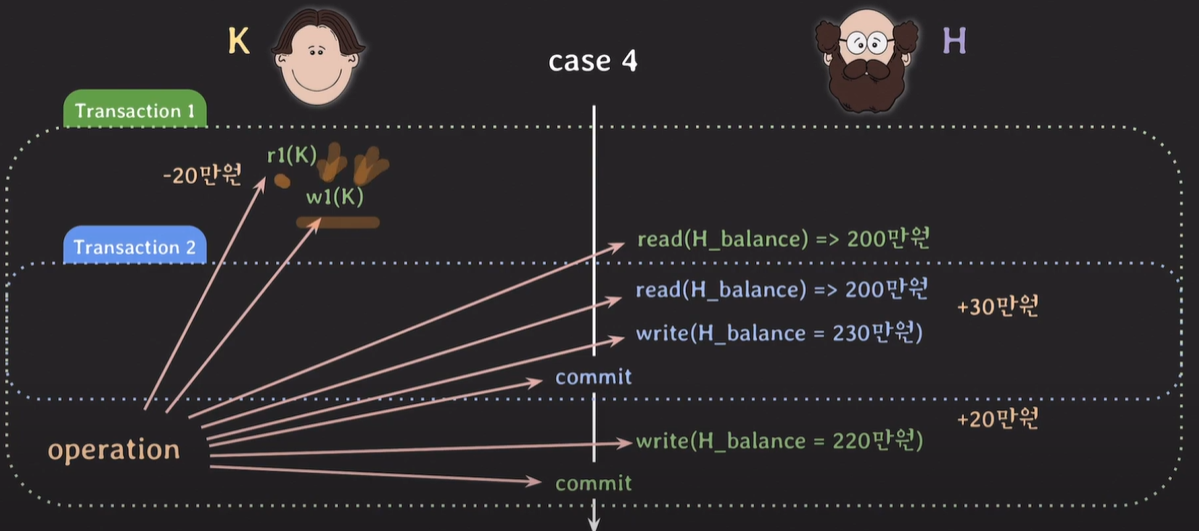
행동하나하나를 operation이라 부르며, write(w), read(r), 트랜잭션명 데이터명으로 구성된다. commit(c)
r1(K) : 트랜잭션1 이 K의 데이터 read
W1(K) : 트랜잭션1 이 K의 데이터 write
Schedule
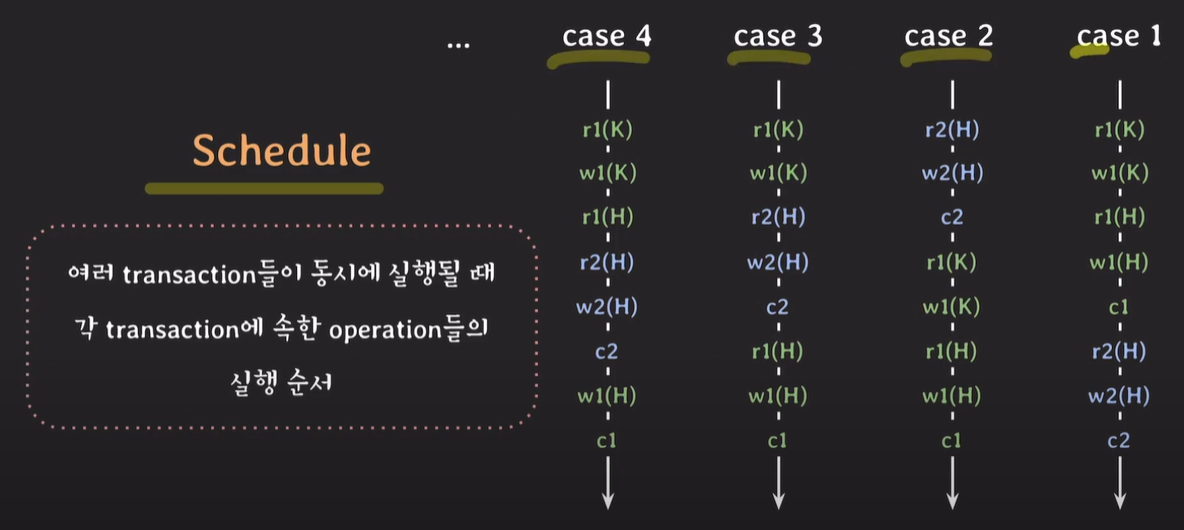
schedule : 여러 트랜잭션들이 동시에 실행될 때 각 트랜잭션에 속한 operation들의 실행 순서, 각 트랜잭션 내의 operation들의 순서는 바뀌지 않는다.
serial schedule

serial schedule : schedule 1번과 schedule 2번은 transaction들이 겹치지 않고 한번에 하나씩 실행된다. (순차적으로 트랜잭션이 시작한다)
* serial : 순차적인
성능

serial schedule의 경우 이상한 데이터, lost update가 발생할 확률이 없다. 하지만, 데이터를 읽고 쓰는 I/O 작업 시 CPU는 해당 작업을 완료할 때 까지 다른것을 하지 않아 처리속도가 느리다.
★현실적으로 사용할 수 없는 방식이다.
nonserial schedule
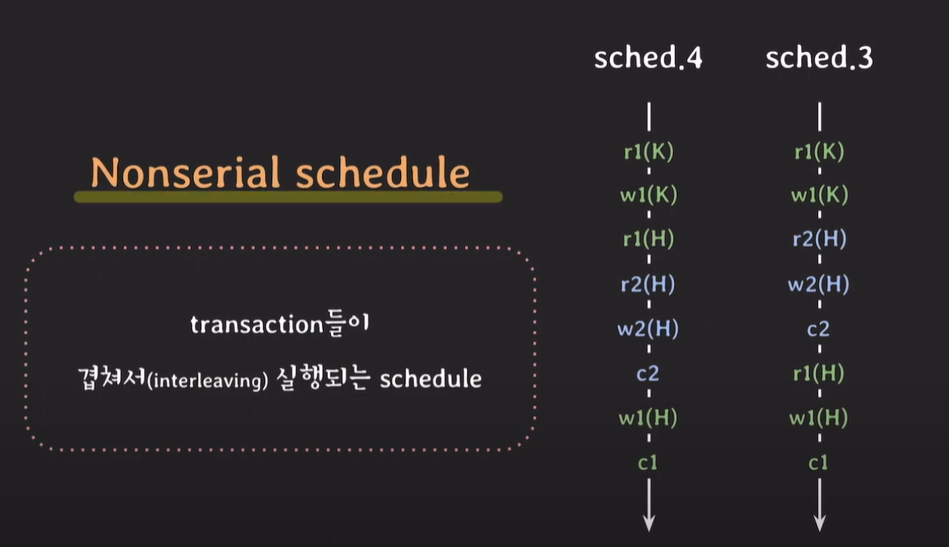
Nonserial schedule : transaction들이 겹처서 실행되는 schedule
성능

하나의 트랜잭션이 I/O 작업을 진행 중일때 다른 트랜잭션이 시작되고, 트랜잭션들이 겹쳐서 실행되기 때문에 동시성이 높아져서 같은 시간동안 더 많은 트랜잭션들을 처리할 수 있다.
단점

트랜잭션들이 동시에 동작하기 때문에 이상한 결과가 발생할 수 있다.
ex) lost update

성능을 향상시키기 위해 Nonserial schedule을 사용하고 싶지만, 이상한 데이터가 나오지 않게 하려면 어떻게 해야할까? serial schedule과 동일한 nonserial schedule을 실행하면 된다.
Conflict

두개의 operation이 위 세가지 조건을 만족하면 conflict라 한다.
- 서로 다른 트랜잭션
- 같은 데이터에 접근
- 최소 하나는 write operation(데이터 변경)
read-write conflict
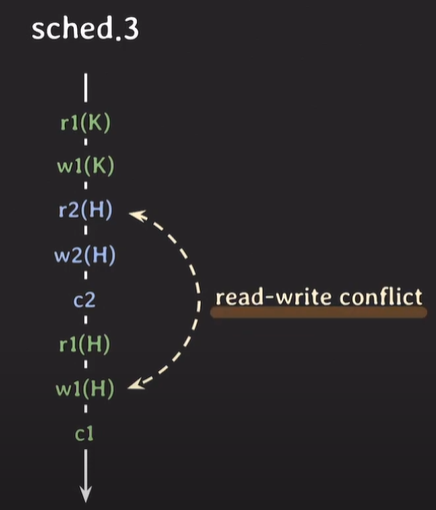
서로 다른 트랜잭션에 속하는 operation들 중 같은 데이터에 접근 하는데, 하나는 read operation 또 다른 하나는 write operation
write-write conflict
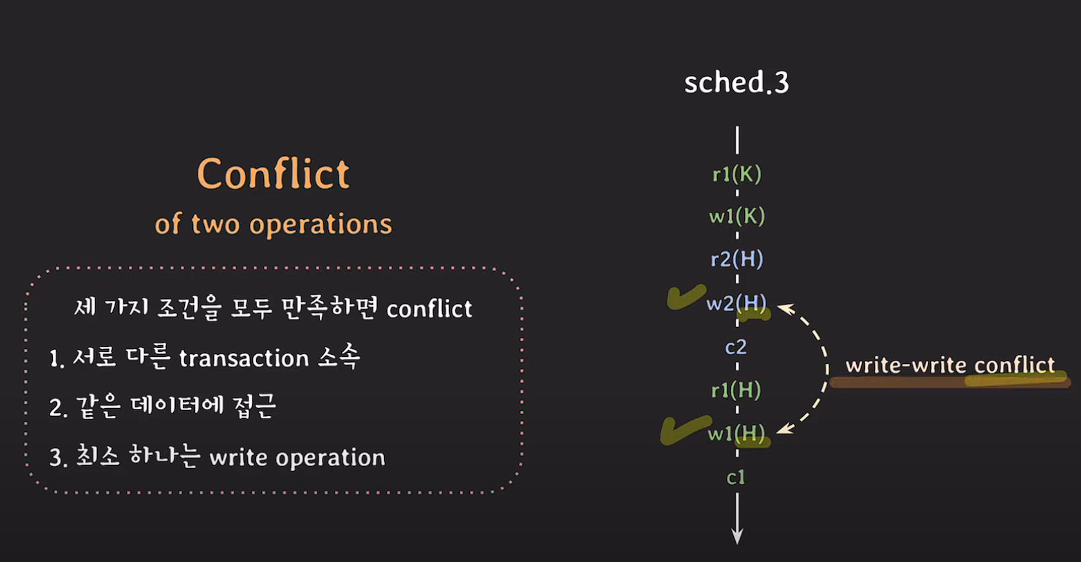
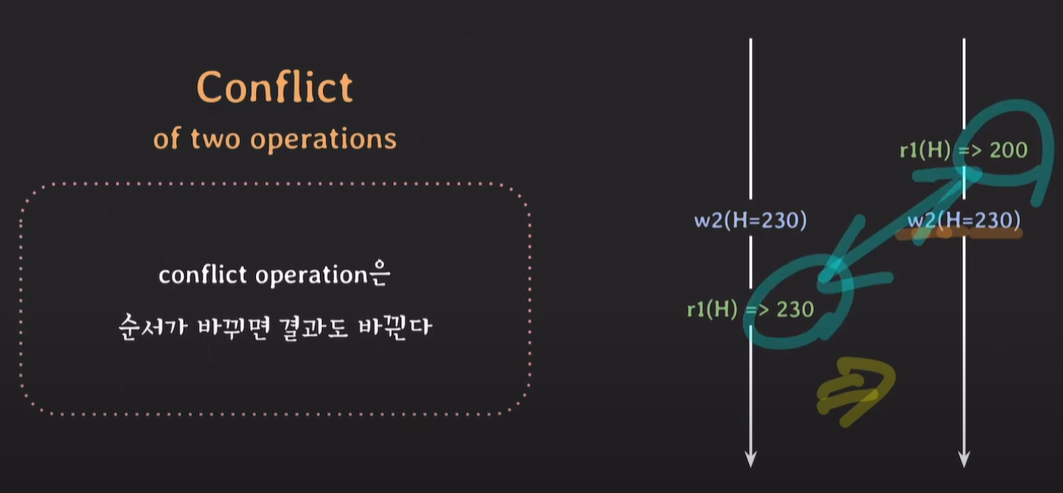
★conflict operation은 순서가 바뀌면 결과도 바뀐다.
conflict equivalent
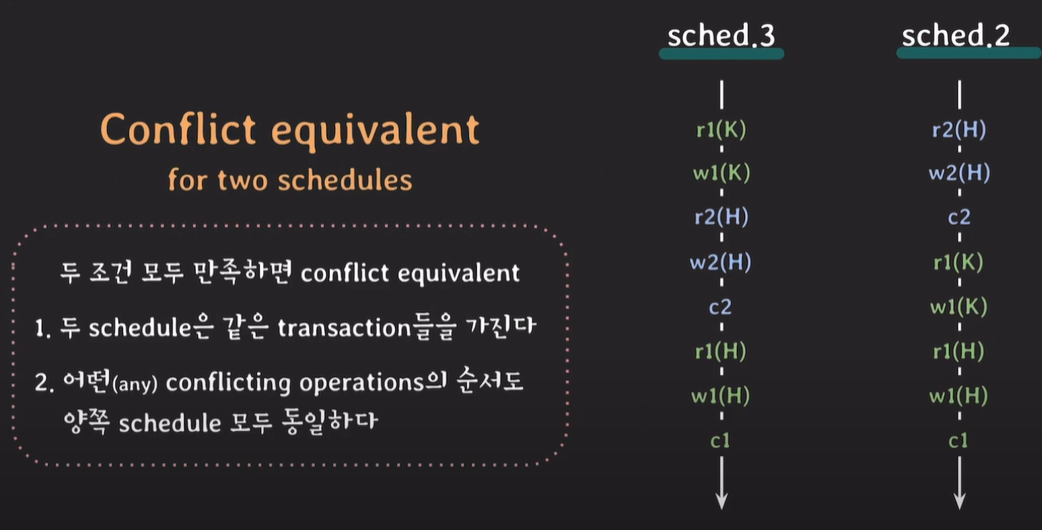
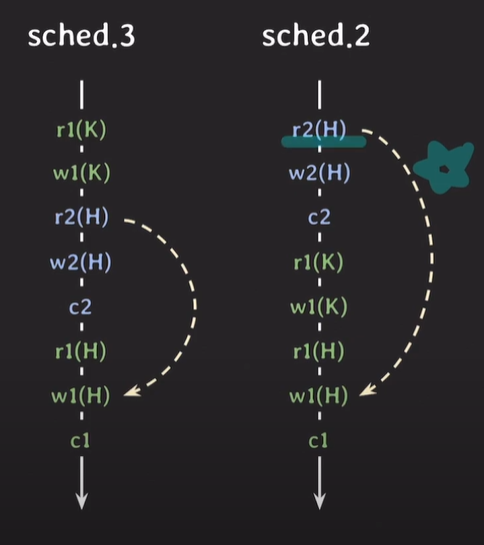
트랜잭션 2가 H에 대해 read 그 후 트랜잭션 1이 H에 대해 write하는 순서가 스케쥴 2와 3이 동일하다.
스케쥴2와 3은 conflict equivalent하다
conflict serializable

스케쥴2는 serial schedule이고, 스케쥴3은 nonserial schedule이다.
nonserial schedule이 serial schedule과 conflict equivalent일 때
conflict serializable이라 부른다.
*serializable : 직렬화
스케쥴3은 nonserial임에도 불구하고 conflict serializable하다.
serial schedule과 결과가 동일하다.
즉, serial schedule과 트랜잭션이 같고, operation의 순서가 같은 스케쥴은conflict serializable을 만족한다.

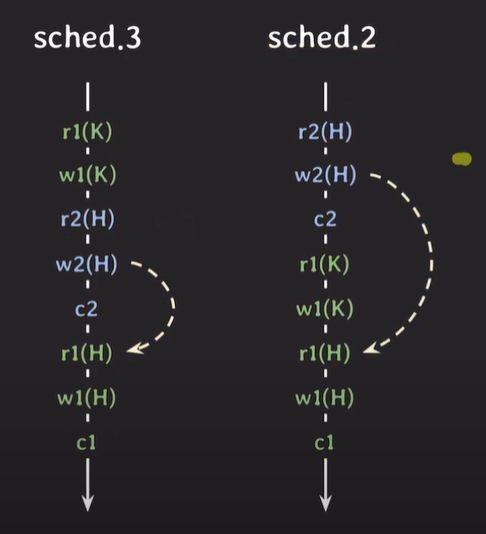
- 서로 동일한 트랜잭션을 가진다 -> O
- operation 순서가 동일하다 -> X
구현


conflict serializable한 스케쥴만 실행되도록 보장하는 프로토콜을 사용한다.
Concurrency control이 어떤 스케쥴이던 serializable하게 만들어준다. > nonserial schedule (non-block I/O)이지만, serial schedule과 트랜잭션이 같고, 오퍼레이션의 순서가 같은 스케줄만 실행된다.
하지만, isolation의 격리 레벨을 너무 높이면 성능이 너무 떨어질 수 있다.
Recoverability

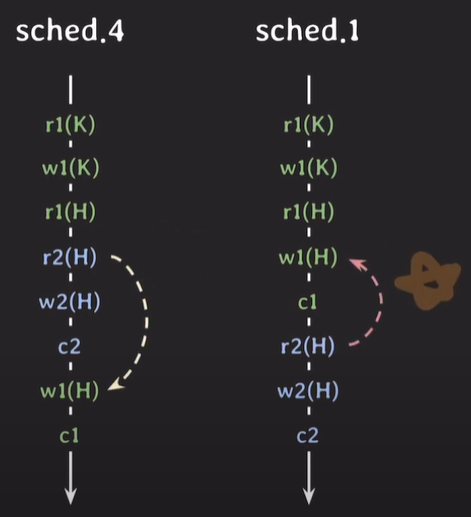
해당 순서로 트랜잭션들의 operation이 실행 됐지만, 트랜잭션 2번이 롤백을 하게 된다면? 230만원으로 읽은 트랜잭션1은 어떻게 처리되어야 할까?
(트랜잭션의 커밋 순서에 따라 달라 질 수 있다.)
unrecoverable schedule

그러나, 트랜잭션1은 이미 commit된 상태이므로 durability 속성 때문에 rollback할 수 없다.
*durability : 커밋된 트랜잭션은 영속성으로 저장되어야한다.

commit된 트랜잭션 (트랜잭션1)이 rollback된 트랜잭션(트랜잭션2)이 write했었던 데이터를 읽은 경우를 unrecoverable schedule이라고 한다.
rollback을 해도 이전 상태로 회복 불가능할 수 있기 때문에 이런 schedule은 DBMS가 허용하면 안된다.
트랜잭션2는 롤백을 하여 H의 계좌는 200만원이지만, 트랜잭션1은 롤백이 불가능하기 때문에 K의 계좌는 그대로 80만원이다. 따라서, 데이터 불일치가 발생한다.
recoverable 한 스케줄이 실행되어야한다.
recoverable schedule

트랜잭션2가 먼저 commit된 후 트랜잭션1이 commit되어야한다. 트랜잭션2가 rollback한 경우 트랜잭션1도 rollback이 되어야한다.

트랜잭션1이 트랜잭션2의 오퍼레이션에 의존하고 있다. 이런 경우 의존대상이 되는 트랜잭션이 먼저 커밋 또는 롤백이 발생한 후 의존하고 있는 트랜잭션이 커밋되거나 롤백이 되어야한다.

rollback할 때 이전 상태로 온전히 돌아갈 수 있기 때문에 DBMS는 이런 schedule만 허용해야 한다.
문제점
cascading rollback : 하나의 트랜잭션이 롤백하면 의존성 있는 다른 트랜잭션도 롤백 해야한다. 여러 트랜잭션의 롤백이 연쇄적으로 일어나면 처리 하는 비용이 많이 든다.

따라서, 다른 트랜잭션에 존재하는 데이터를 사용하고 싶은경우 write한 트랜잭션이 먼저 commit또는 rollback이 된 후에 데이터를 사용하는 schedule만을 사용하도록 한다.
*하나의 트랜잭션이 write operation을 수행한 경우 commit 또는 rollback이 된 후 데이터를 읽는 스케줄만 허용하도록 하자.
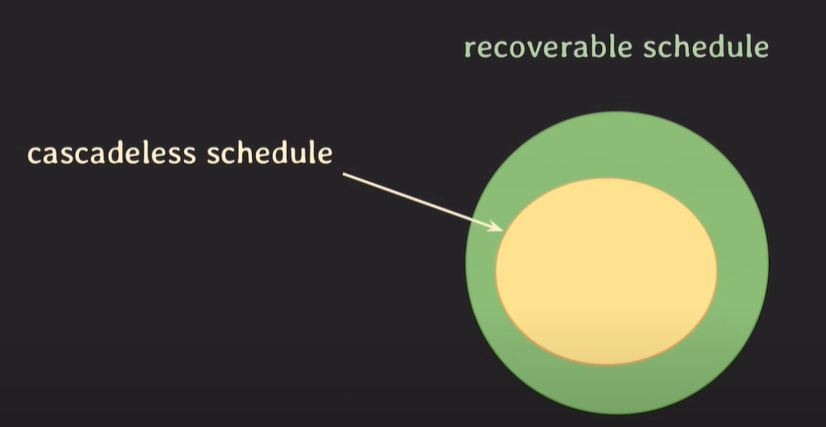
cascadeless schedule


트랜잭션2가 문제가 생겨 롤백을 해도 트랜잭션2만 롤백하면되고, 트랜잭션1은 롤백된 데이터에 20만원을 추가한다.


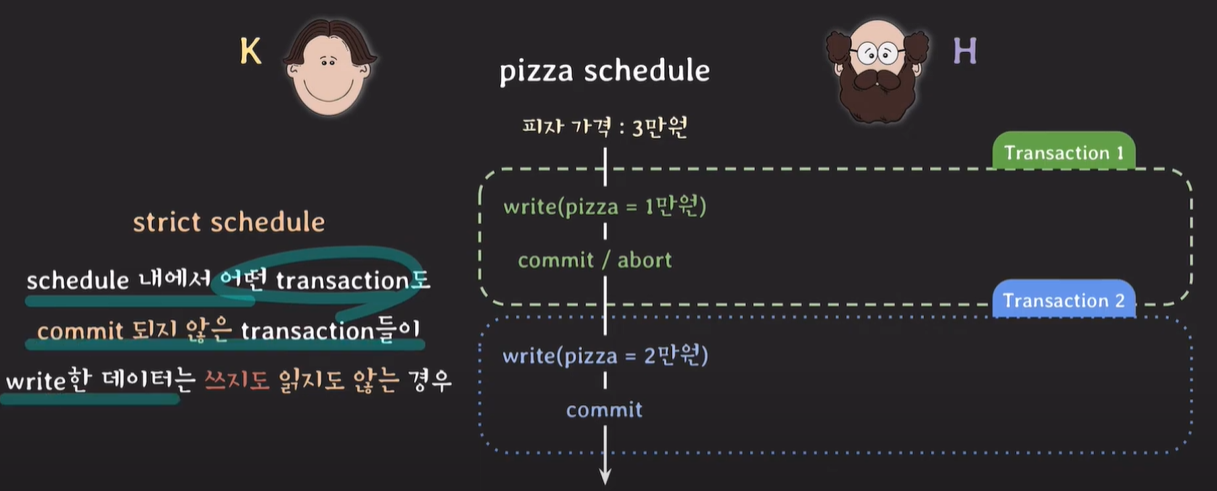
strict schedule
schedule 내에서 어떤 transaction도 commit되지 않은 transaction들이 write한 데이터는 쓰지도, 읽지도 않는다.
커밋 되지 않은 데이터는 읽지도, 쓰지도 않는다.
rollback할 때 recovery가 쉽다. transaction 이전 상태로 돌려 놓기만 하면된다.
정리

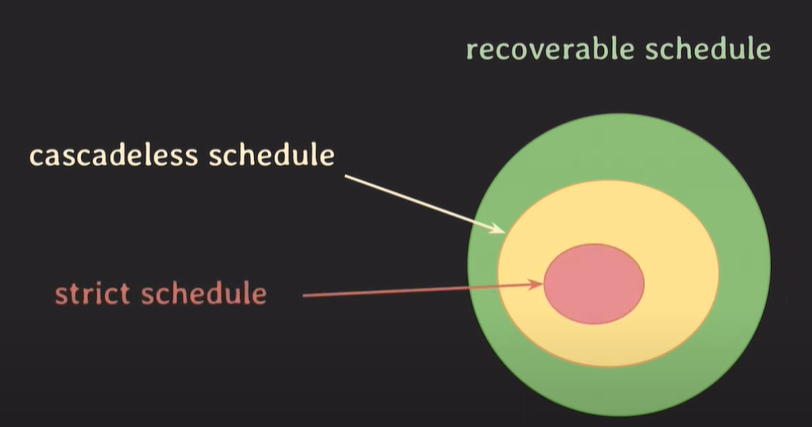

unrecoverable schedule : 회복이 불가능한 스케쥴, DBMS자체에서 허용을 해서는 안된다.
recoverable schedule : 회복이 가능한 스케쥴
cascadeless schedule : 회복이 가능한 스케쥴 중 연속적인 롤백이 일어나지 않는 스케쥴
strict schedule : write한 데이터가 commit / rollback 되기 전까지는 다른 트랜잭션은 해당 데이터를 이용할 수 없다.
