- 잘못된 내용이 있을 수 있습니다.
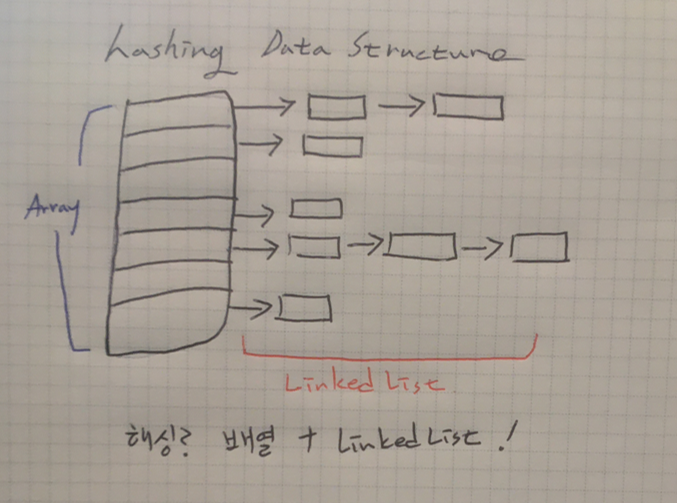
해싱과 해시함수
해싱이란 해시함수를 이용해서 데이터를 헤시테이블에 저장하고 검색하는 기법이다.
해시함수는 데이터가 저장되어 있는 곳을 알려주므로 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있다.
해싱을 구현한 클래스로 HashSet, HashMap, Hashtable 등이 있다. Hashtable은 컬렉션프레임웍 도입(JDK1.8)이후 HashMap으로 대체 되었다.
해싱의 자료 구조
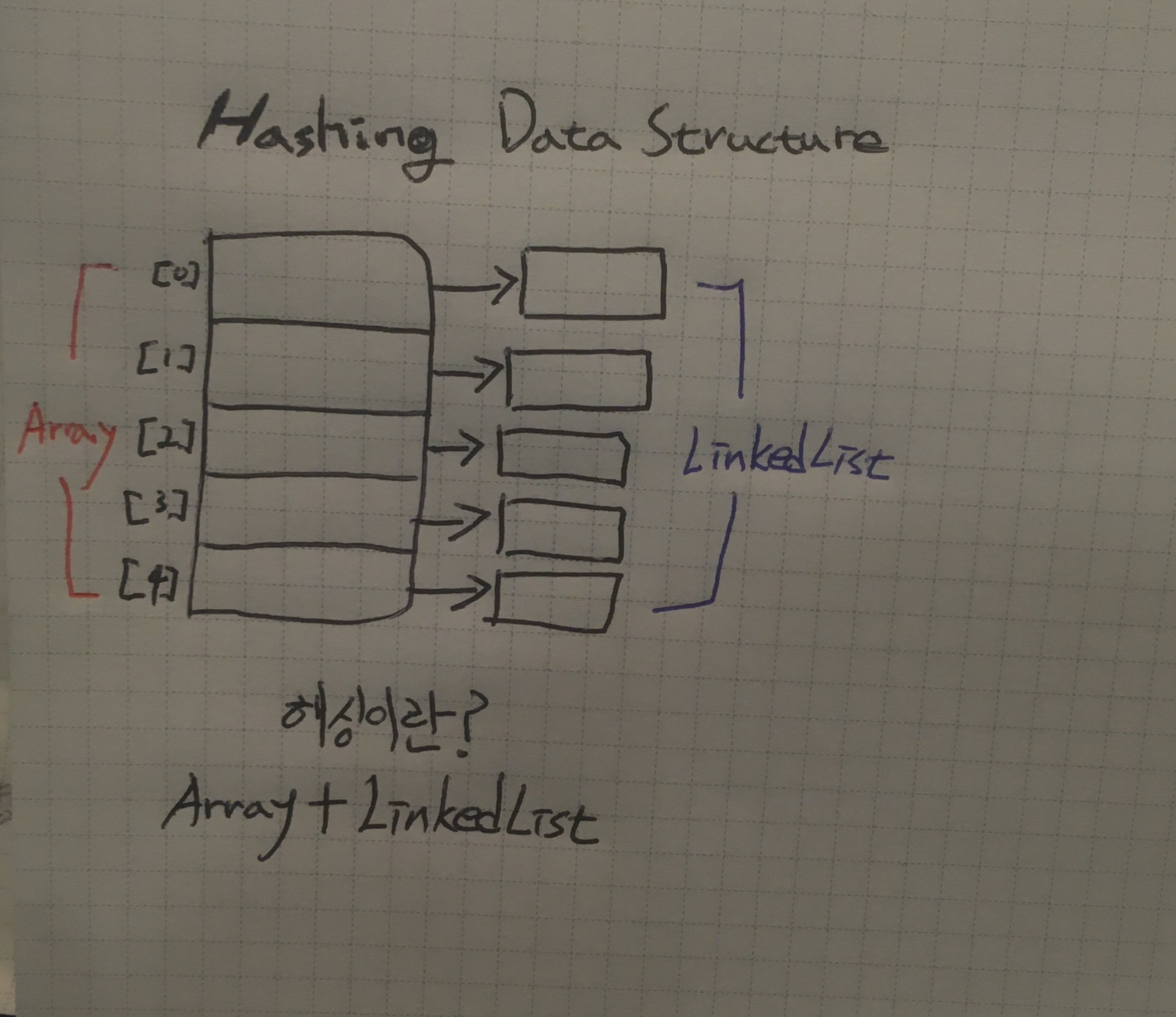
HashMap을 이용해 아주 복잡한 이름을 가진 모델명과 제조사를 묶어서 데이터를 보관해둔다고 하자. 나는 이 복잡한 이름의 모델명을 가진 제품의 제조사를 자주 구분해야 할 필요가 있다. 중복되지 않는 모델명을 key로 두고 언제든 key를 이용해 value에 접근할 수 있게 만든다면 이렇게 할 것이다.
| 아주 복잡한 이름의 제품 모델명 |
|---|
| GalaxyNote10 |
| iphoneXS |
| GalaxyS20 |
| iphone5 |
| G10 |
| GoolgePhone1 |
이 분류가 위 그림에서 Array부분에 해당한다.
그 다음은 중복을 허용하는 value 부분에 제조사를 추가한다.
| 아주 복잡한 이름의 제품 모델명 | 제조사 |
|---|---|
| GalaxyNote10 | apple |
| iphoneXS | apple |
| GalaxyS20 | Samsung |
| iphone5 | Samsung |
| G10 | LG |
| GoolgePhone1 |
정리하자면, 해싱에 사용되는 자료구조(Array+LinkedList)에서
분류는 Array, 실제 데이터는 LinkedList로 저장한다.
이러면 언제든지, 필요할 때마다 이 복잡한 이름의 제품을 어떤 회사가 만들었는지 쉽게 알 수 있다.
아래는 원하는 요소를 찾는 과정이다.
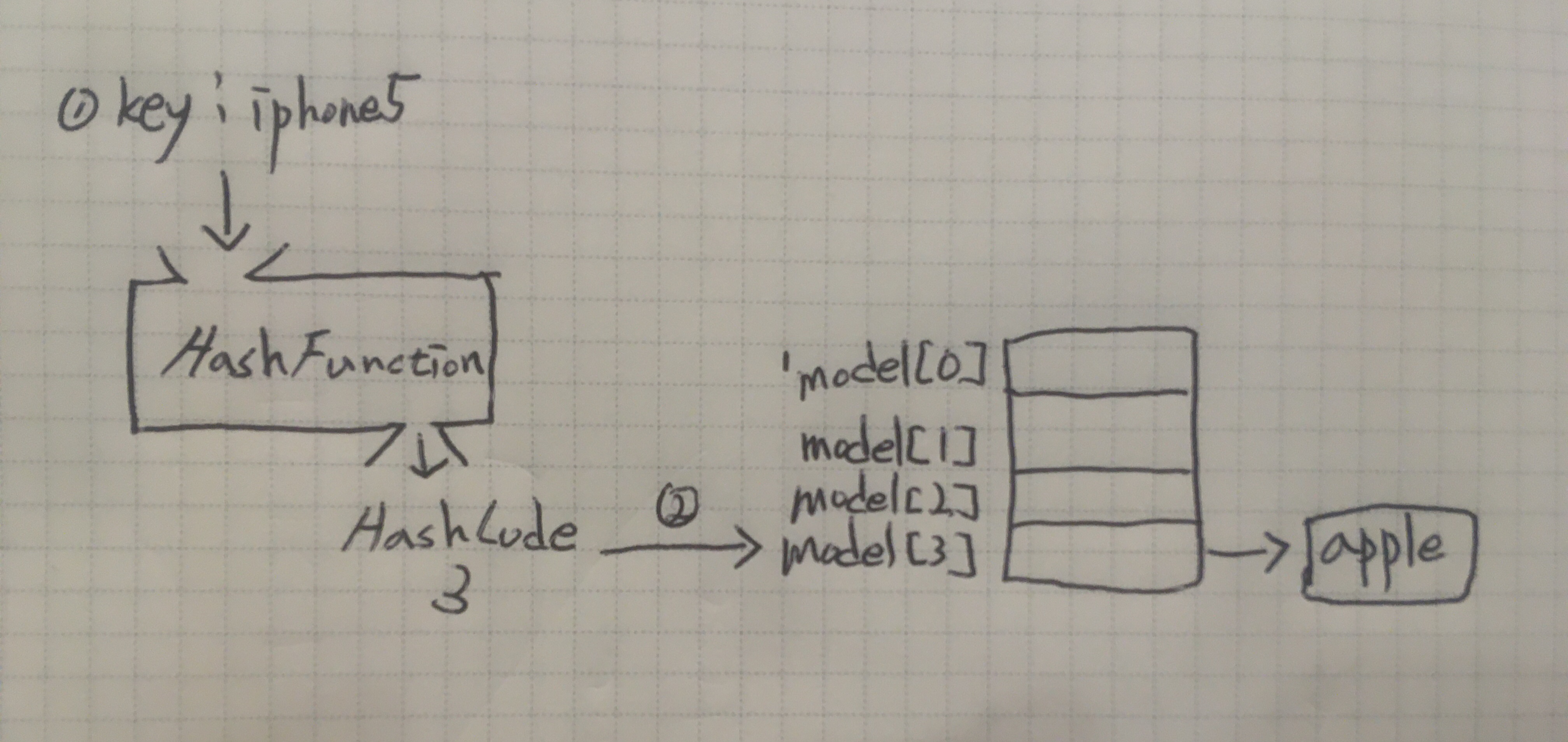
- 검색할 key로 해시함수 호출
- 해시함수 결과(hash code)로 해당 값이 저장된 LinkedList를 찾는다.
- 최종 결과 값 반환(apple)
하나의 key에 여러 LinkedList를 저장할 수 있지만 그렇게하면 성능이 떨어진다. 알다시피 LinkedList는 검색에 취약하기 때문이다. 따라서 하나의 key에 하나의 LinkedList만 저장해두는 것이 좋다.
- HashMap의 크기를 적절히 지정한다.
- 해시함수가 다른 key에 대해 중복된 해시코드를 반환을 최소화 한다.
그래서 해싱을 구현할 때 중요한 것은 해시함수 알고리즘이다. 보통은 HashMap과 같이 해싱을 구현한 컬렉션 클래스에서는 Object클래스에 정의된 hashCode()를 해시함수로 사용한다. hashCode()는 객체의 주소를 이용하는 알고리즘으로 해시코드를 만들기 때문에 모든 객체에 대해 hashCode()를 호출한 결과가 다르다. 좋은 방법이다.
String클래스의 경우, Object에서 상속받은 hashCode()를 오버라이딩해서 문자열의 내용으로 해시코드를 만든다. 따라서 다른 String인스턴스라고 해도, 문자열이 같다면 같은 해시코드를 반환한다.
equals()로 비교환 결과가 true인 동시에 hashCode()의 반환값이 같아야 같은 객체로 인식한다. HashMap도 마찬가지며, 이미 존재하는 key값을 저장하면 기존 값을 새로운 값으로 덮어쓴다.
