RAID (redundant array of Independent disks)
독립된 디스크들의 중복된 array
다중 디스크 사용해 다양한 방식으로 데이터 구성
신뢰성 향상을 위해 중복성 여러 방법으로 추가
0 ~ 6까지의 7개의 레벨로 구성
계층적 관계는 없음
3가지 공통된 특성을 공유
-
운영체제에 의해서 단일 논리적 드라이브로 판단되는 물리적 디스크 드라이브의 집합
-
데이터는 배열의 물리적 드라이브에 스트라이핑 기법을 사용하여 분산
-
중복된 디스크 용량은 패리티 정보를 저장하기 위해 사용
이것은 디스크 실패가 발생했을 때 데이터 복구 보장
raid 0과 1은 세번째 특성 거부
raid 0
데이터를 스트립이라는 단위로 나누어서 이용가능한 디스크에게 분산
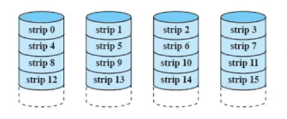
스트립 : 물리적 블록, 섹터, 다른 단위
round robin 방식으로 매핑
물리적으로는 다른 디스크에 매핑됐지만 논리적으로 연속적인 스트립 집합 => 스트라이프!
n개의 디스크 가진 디스크 배열 첫 n개의 논리적 스트립들은 n개이 물리 디스크의 첫번째 스트립들에 저장, 첫번째 스트라이프 형성 ( 그림의 가로)
성능 향상, 신뢰성을 위한 중복 포함 X
신뢰성보다는 저비용 중요시
raid1
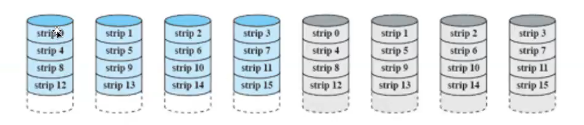
그대로 복사해서 중복을 도입 ( 미러링) (2n개의 디스크)
읽기 요청이 두개의 디스크중 최소인 디스크에 서비스 가능(read는 빠름)
write는 느림
raid2
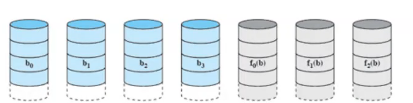
병렬적 접근 기술 사용
striping을 하기는 하는데 미러링을 하지 않고 해밍코드로 함 디스크 수 (n+m)
디스크 비용 감소
raid3
비슷한데 parity bit 사용 (n+1개의 디스크)
두개 깨지면 복구 불가능
비용이 좋음
성능 나빠짐
raid4
블럭 단위로 (더 큰 스트립) 사용
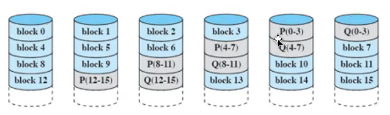
raid5
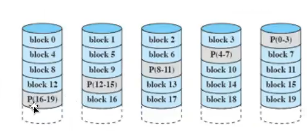
페리티 스트립을 모든 디스크에 분산
패리티 디스크의 잠재적 입출력 병목현상을 피할 수 있음
raid6
두개의 parity bit 사용
두개가 동시에 깨지면 살릴 수 있음
디스크 n+2개 필요
