퀵정렬
기준값(pivot)을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘으로, 평균 시간 복잡도는 O(nlogn)이나 최악의 경우(피벗의 위치에 따라) 시간 복잡도가 O(n^2)이다.
핵심 이론
pivot을 중심으로 데이터를 2개의 집합으로 나누면서 정렬하는 것
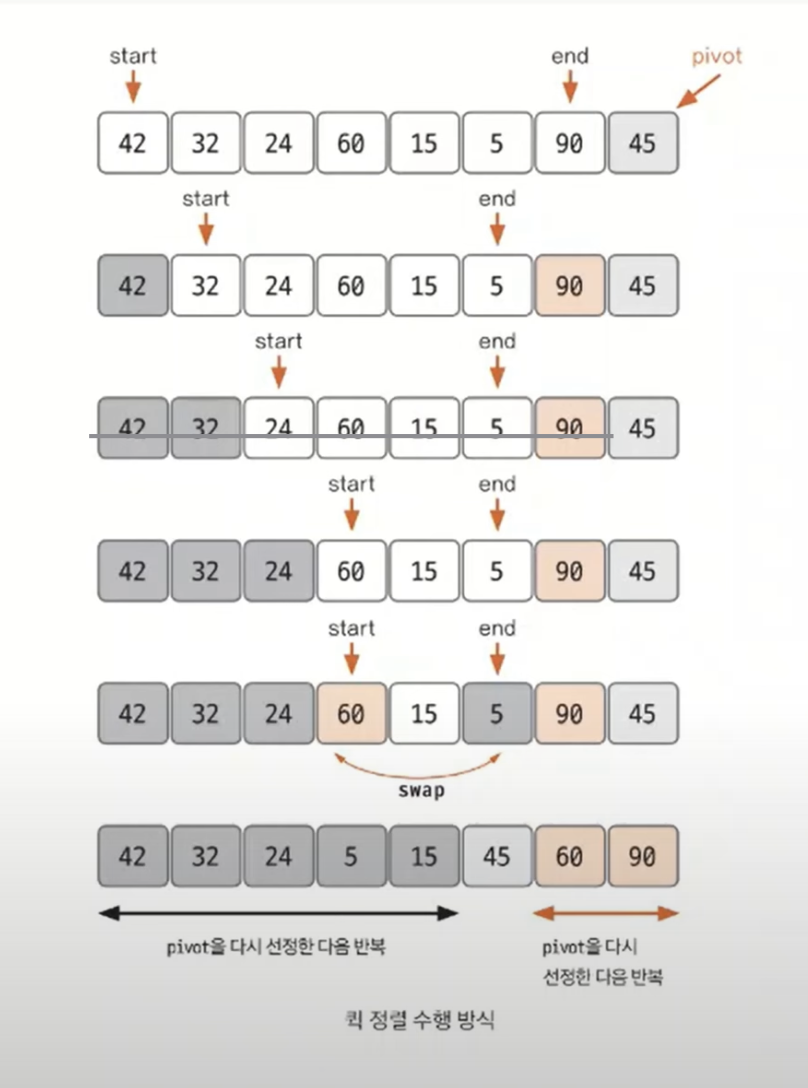
정렬 과정
- 데이터를 분할할 기준 점(pivot)을 설정한다.
- pivot을 기준으로 아래의 과정을 거쳐 데이터를 2개의 집합으로 분리한다.
a. start의 데이터가 pivot의 데이터보다 작으면 start를 오른쪽으로 1칸 이동한다.
b. end의 데이터가 pivot의 데이터보다 크면 end를 왼쪽으로 1칸 이동한다.
c. start의 데이터가 pivot이 가리키는 데이터보다 크고, end가 가리키는 데이터가 pivot이 가리키는 데이터보다 작으면 start와 end의 데이터를 swap하고, start는 오른쪽, end는 왼쪽으로 1칸씩 이동한다.
d. start와 end가 만날 때까지 위 과정을 반복한다.
e. start와 end가 만나면 만난 지점의 왼쪽에 pivot이 가리키는 데이터를 삽입- 분리 집합에서 각각 다시 pivot을 선정
- 분리 집합이 1개 이하가 될 때까지 1~3번을 반복
코드 구현
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2] # 피벗은 리스트의 중간 요소로 선택
left = [x for x in arr if x < pivot] # 피벗보다 작은 값들로 이루어진 부분 리스트
middle = [x for x in arr if x == pivot] # 피벗과 같은 값들로 이루어진 부분 리스트
right = [x for x in arr if x > pivot] # 피벗보다 큰 값들로 이루어진 부분 리스트
# 분할된 부분 리스트에 대해 재귀적으로 퀵 정렬을 수행하고, 합쳐서 반환
return quick_sort(left) + middle + quick_sort(right)