
WHAT IS KATA?
KATA는 기술과 기술 향상에 초점을 맞춘 코드 챌린지입니다.
일부는 프로그래밍 기본 사항을 교육하는 반면 다른 일부는 복잡한 문제 해결에 중점을 둡니다.
이 용어는 The Pragmatic Programmer 라는 책의 공동 저자인 Dave Thomas 가
무술에서 일본의 카타 개념을 인정하면서 처음 만들어졌습니다.
Dave의 개념 버전은 코드 카타를 프로그래머가
연습과 반복을 통해 기술을 연마하는 데 도움이 되는 프로그래밍 연습으로 정의합니다.
리트코드 - 판다스 30일 문제
- PYTHON
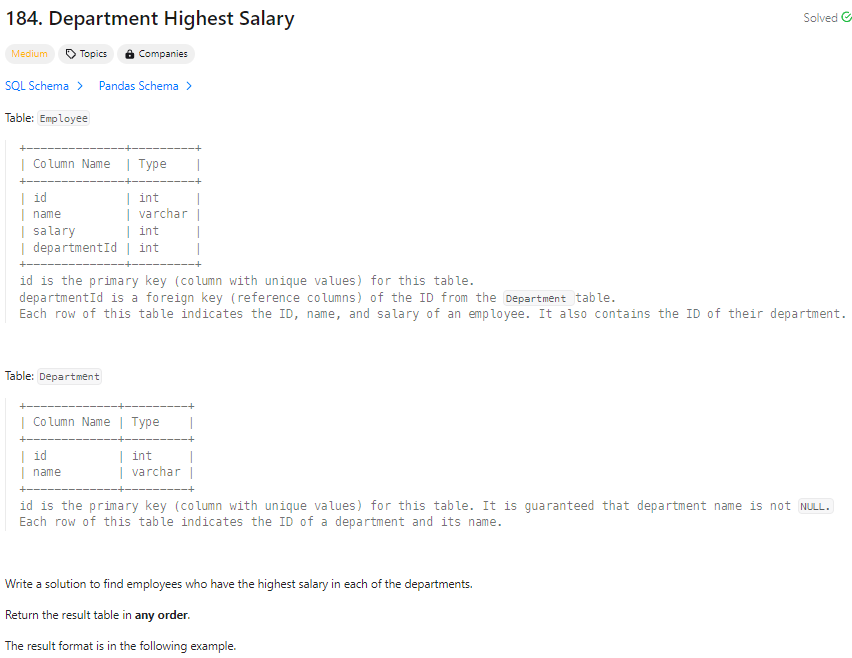
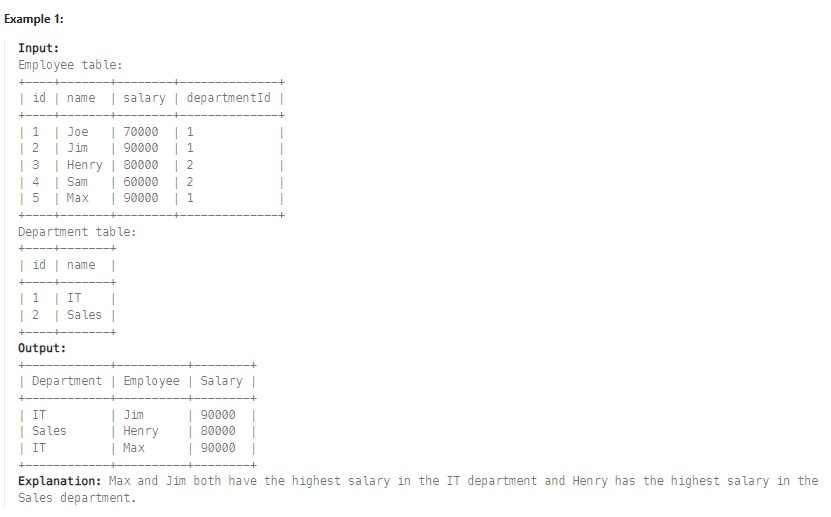
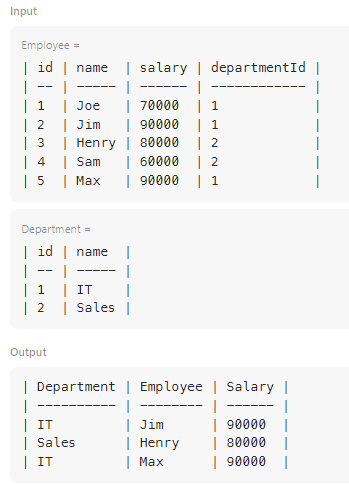
✔️ 문제 #1: Department Highest Salary
✔️ 제출 코드
✔️ 코드 분석
import pandas as pd
def department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:
merged_df = pd.merge(employee, department, left_on='departmentId', right_on='id')
max_salaries = merged_df.groupby('departmentId')['salary'].max().reset_index()
result_df = pd.merge(merged_df, max_salaries, on=['departmentId', 'salary'], how='inner')
result_df = result_df[['name_y', 'name_x', 'salary']]
result_df.columns = ['Department', 'Employee', 'Salary']
return result_df
✔️ CHECK POINT
-
PANDAS
-
merge()메서드 사용하여 두 개의 데이터프레임 병합하기# Employee 테이블과 Department 테이블을 'departmentId'와 'id'를 기준으로 병합 merged_df = pd.merge(employee, department, left_on='departmentId', right_on='id') -
groupby()와max()사용하여 각 그룹별 최대 값 계산하기# 각 부서별 가장 높은 급여를 찾기 위해 'departmentId'로 그룹화, 그룹 내 'salary' 최대 값 계산 max_salaries = merged_df.groupby('departmentId')['salary'].max().reset_index() -
merge()메서드 사용하여 조건에 맞는 데이터 필터링하기# 최대 급여를 가진 직원들을 찾기 위해 다시 병합, # 'departmentId'와 'salary'가 일치하는 행만 병합 결과에 포함됨 result_df = pd.merge(merged_df, max_salaries, on=['departmentId', 'salary'], how='inner') -
컬럼 지정하여 원하는 형식으로 데이터프레임 정리하기
# 필요한 컬럼만 선택하고, 이름을 명확하게 지정하여 결과 정리 result_df = result_df[['department', 'name', 'salary']] result_df.columns = ['Department', 'Employee', 'Salary']
-

커피 좋아하는 데이터 꿈나무