
WHAT IS KATA?
KATA는 기술과 기술 향상에 초점을 맞춘 코드 챌린지입니다.
일부는 프로그래밍 기본 사항을 교육하는 반면 다른 일부는 복잡한 문제 해결에 중점을 둡니다.
이 용어는 The Pragmatic Programmer 라는 책의 공동 저자인 Dave Thomas 가
무술에서 일본의 카타 개념을 인정하면서 처음 만들어졌습니다.
Dave의 개념 버전은 코드 카타를 프로그래머가
연습과 반복을 통해 기술을 연마하는 데 도움이 되는 프로그래밍 연습으로 정의합니다.
- SQL
✔️ 문제 #1: 우유와 요거트가 담긴 장바구니
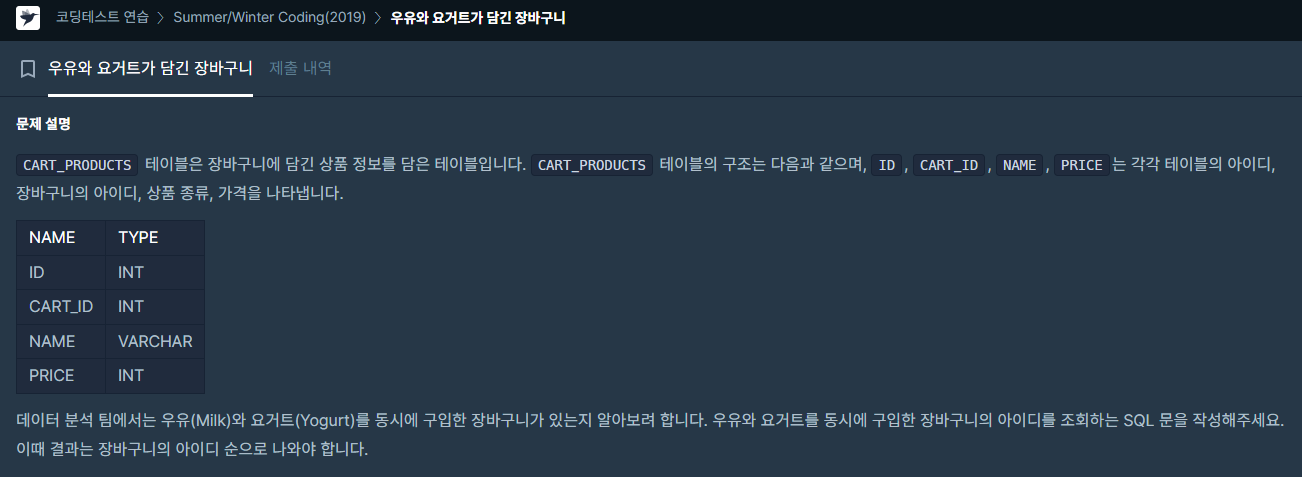
✔️ 제출 쿼리
✔️ 쿼리 분석
SELECT A.ACI CART_ID
FROM
(
SELECT CART_ID ACI,
NAME AN
FROM CART_PRODUCTS
GROUP BY CART_ID, NAME
HAVING NAME LIKE 'Milk' OR NAME LIKE 'Yogurt'
) A
GROUP BY A.ACI
HAVING COUNT(A.ACI) > 1
ORDER BY 1
# CART_ID 와 NAME 으로 각각 그룹화하여
이름 그룹 내 우유와 요거트가 들어있는 행만 조회하는 인라인 뷰 생성 후
다시 CART_ID로 그룹화하여 행의 수가 2개 이상인 것(우유 행 요거트 행)을 조회.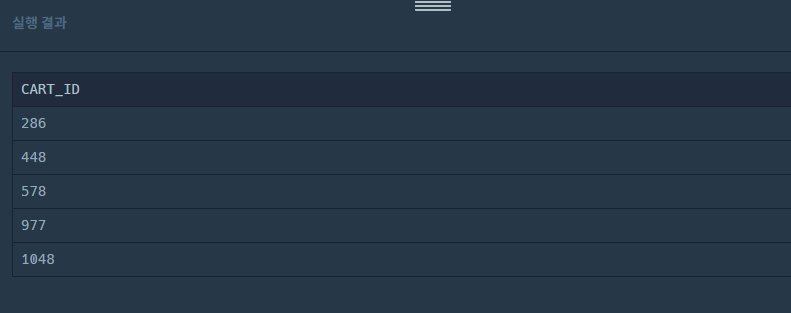
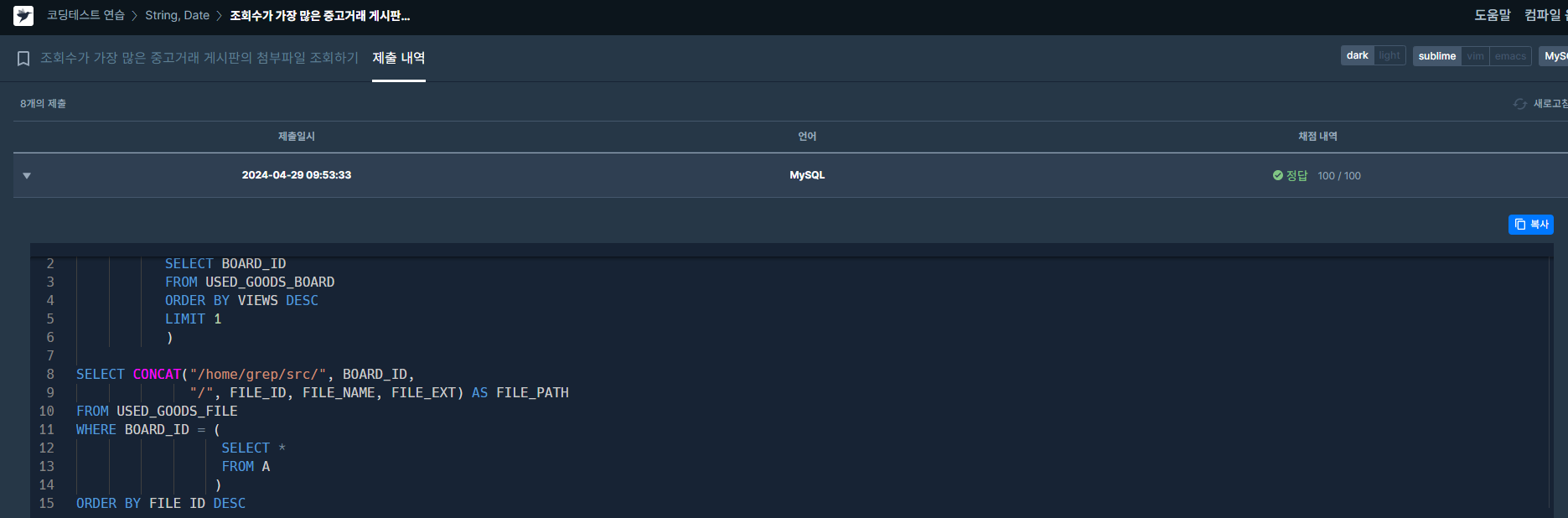
✔️ 문제 #2: 조회수가 가장 많은 중고거래 게시판의 첨부파일 조회하기
✔️ 제출 쿼리
✔️ 쿼리 분석
WITH A AS (
SELECT BOARD_ID
FROM USED_GOODS_BOARD
ORDER BY VIEWS DESC
LIMIT 1
)
SELECT CONCAT("/home/grep/src/", BOARD_ID,
"/", FILE_ID, FILE_NAME, FILE_EXT) AS FILE_PATH
FROM USED_GOODS_FILE
WHERE BOARD_ID = (
SELECT *
FROM A
)
ORDER BY FILE_ID DESC
#WITH 구문으로 조회수가 가장 높은 BOARD_ID를 추출한 CTEs를 생성하고
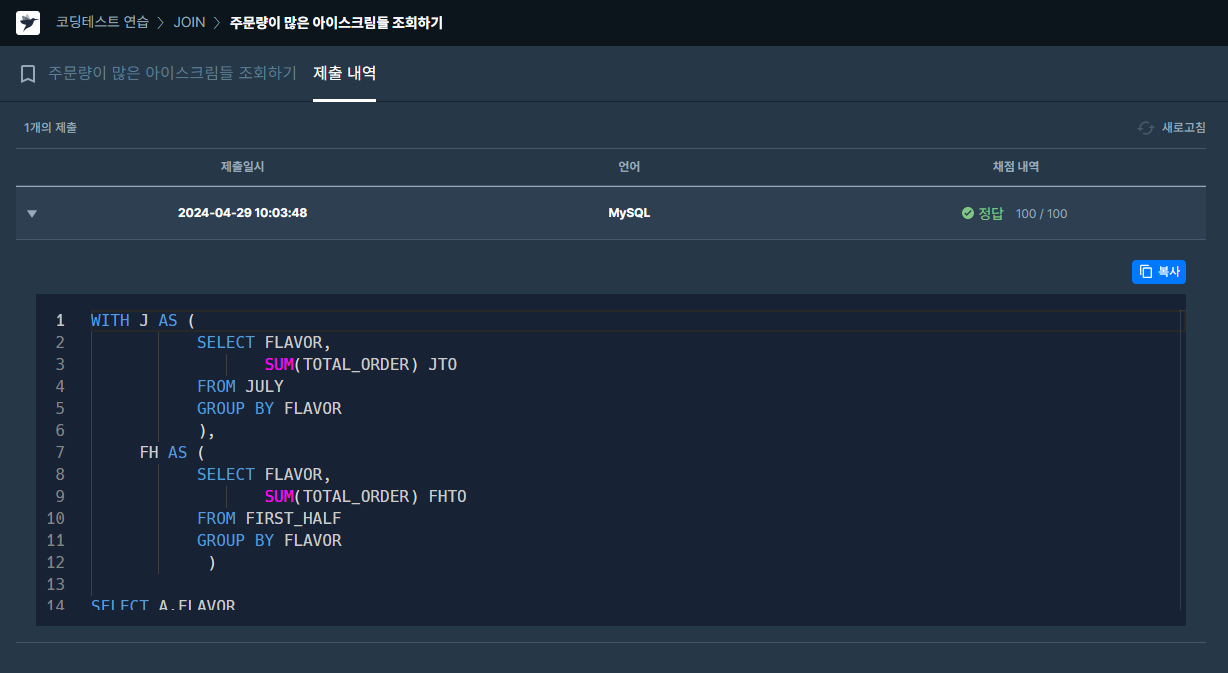
FILE 테이블에서 같은 BOARD_ID를 가진 데이터를 활용해 파일 경로 생성.✔️ 문제 #3: 주문량이 많은 아이스크림들 조회하기
✔️ 제출 쿼리
✔️ 쿼리 분석
WITH J AS (
SELECT FLAVOR,
SUM(TOTAL_ORDER) JTO
FROM JULY
GROUP BY FLAVOR
),
FH AS (
SELECT FLAVOR,
SUM(TOTAL_ORDER) FHTO
FROM FIRST_HALF
GROUP BY FLAVOR
)
SELECT A.FLAVOR
FROM
(
SELECT FH.FLAVOR,
(J.JTO + FH.FHTO) TOTAL
FROM J INNER JOIN FH
ON J.FLAVOR = FH.FLAVOR
ORDER BY (J.JTO + FH.FHTO) DESC
LIMIT 3
) A
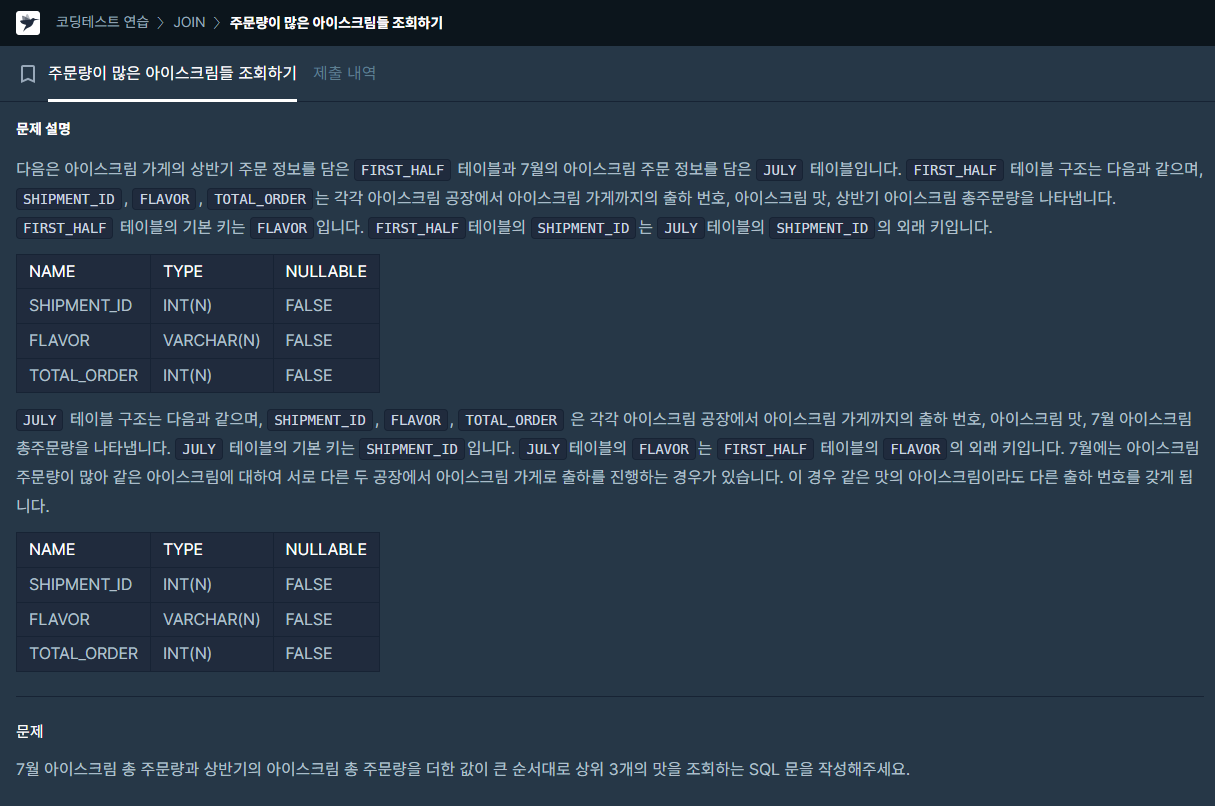
# WITE 구문을 활용해 7월 FLAVOR 기준 총 주문량 합계 테이블과
상반기 FLAVOR 기준 총 주문량 합계 테이블을 각각 생성하고,
두 테이블의 총 주문량을 더한 값의 내림차순으로 정렬 후 상위 3개 행만 추출한 서브쿼리에서
FLAVOR만 추출.- PYTHON
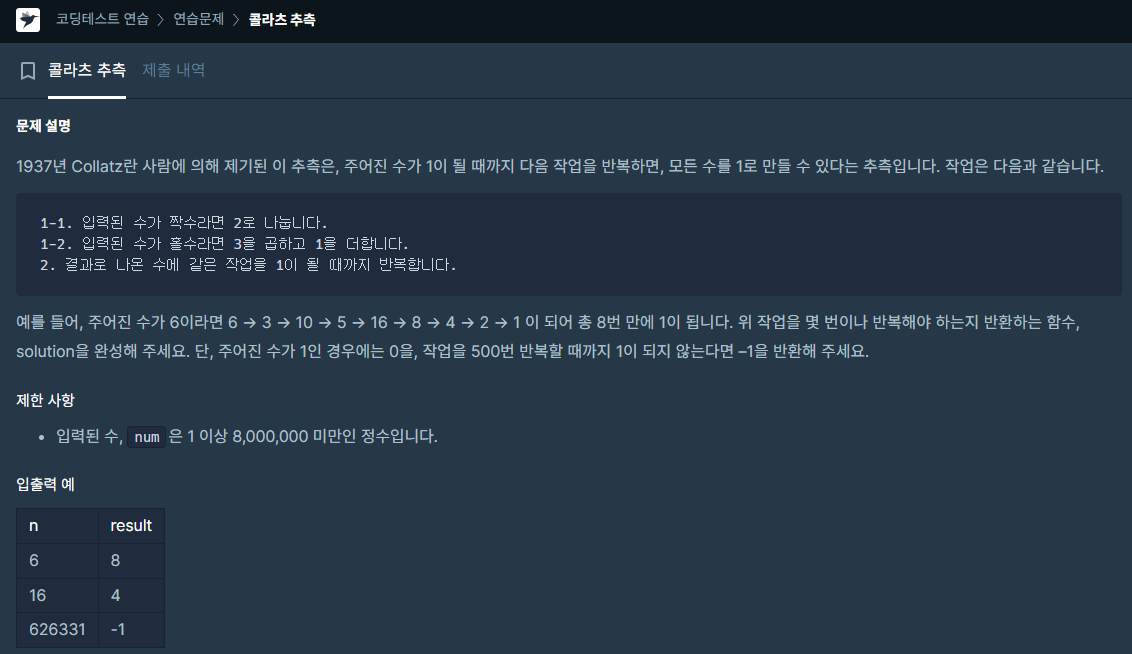
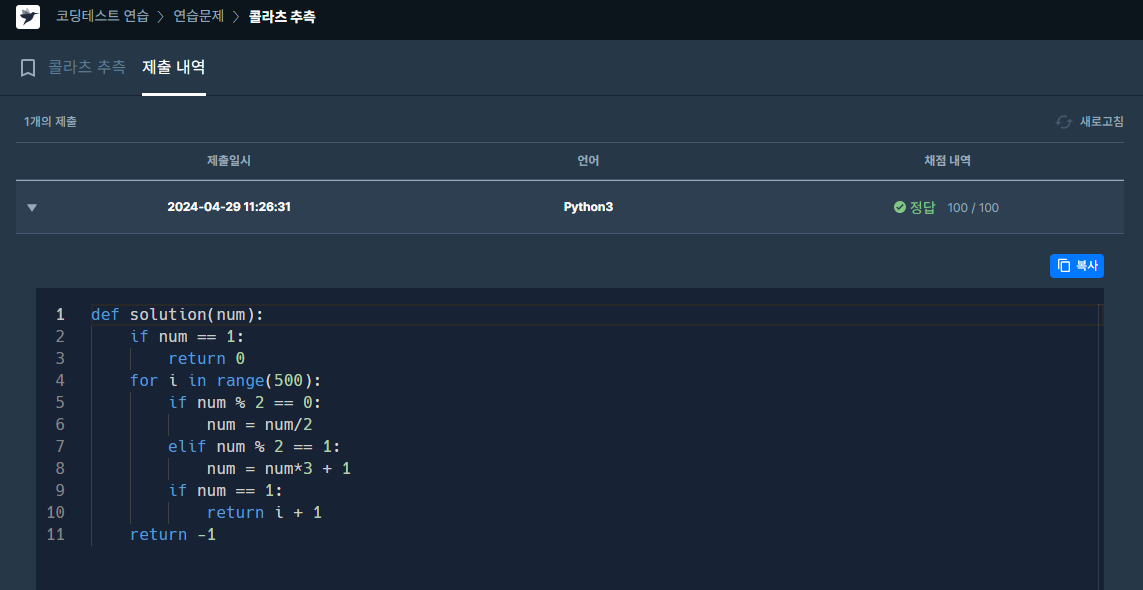
✔️ 문제 #1: 콜라츠 추측
✔️ 제출 코드
✔️ 코드 분석
def solution(num):
if num == 1:
return 0 - 주어진 수가 1인 경우 0을 반환
for i in range(500): - 500번 반복으로 범위 지정
if num % 2 == 0: - num을 2로 나눴을 때 나머지가 0인 경우 (짝수)
num = num/2 - num/2 가 num 이 된다.
elif num % 2 == 1: - num을 2로 나눴을 때 나머지가 1인 경우 (홀수)
num = num*3 + 1 - num*3 + 1 이 num 이 된다.
if num == 1: - 반복 중 num이 1이라면
return i + 1 - 반복 횟수 (i + 1) 반환
return -1 - 500번 반복 후 (if에 걸리는 조건이 없다면) -1 반환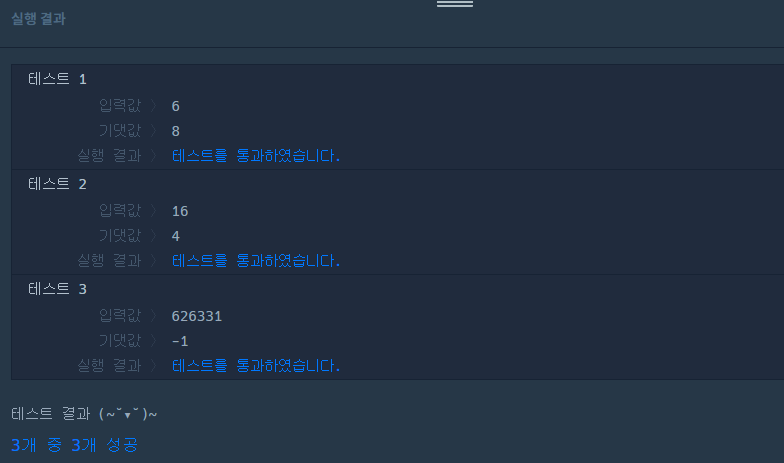
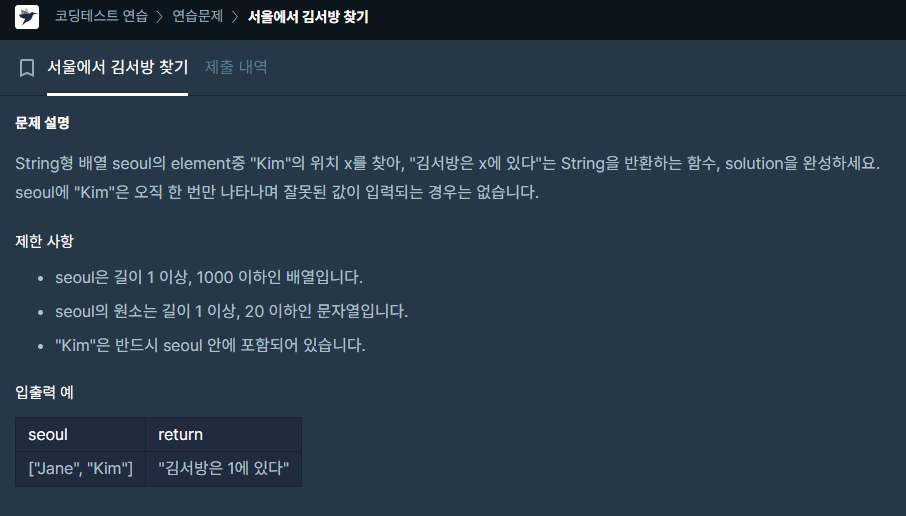
✔️ 문제 #2: 서울에서 김서방 찾기
✔️ 제출 코드
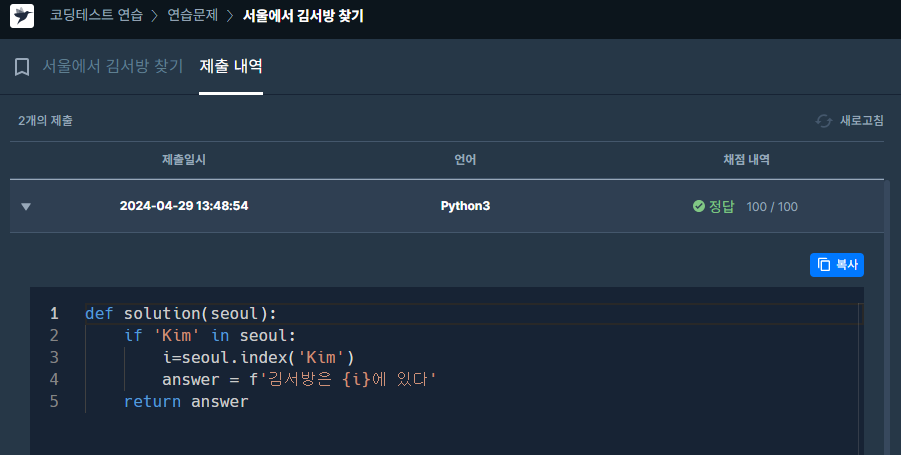
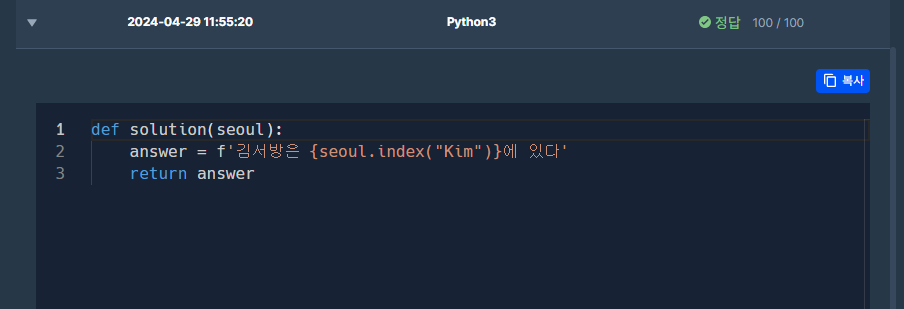
✔️ 코드 분석
def solution(seoul):
if 'Kim' in seoul:
i=seoul.index('Kim')
answer = f'김서방은 {i}에 있다'
return answerdef solution(seoul):
answer = f'김서방은 {seoul.index("Kim")}에 있다'
return answer
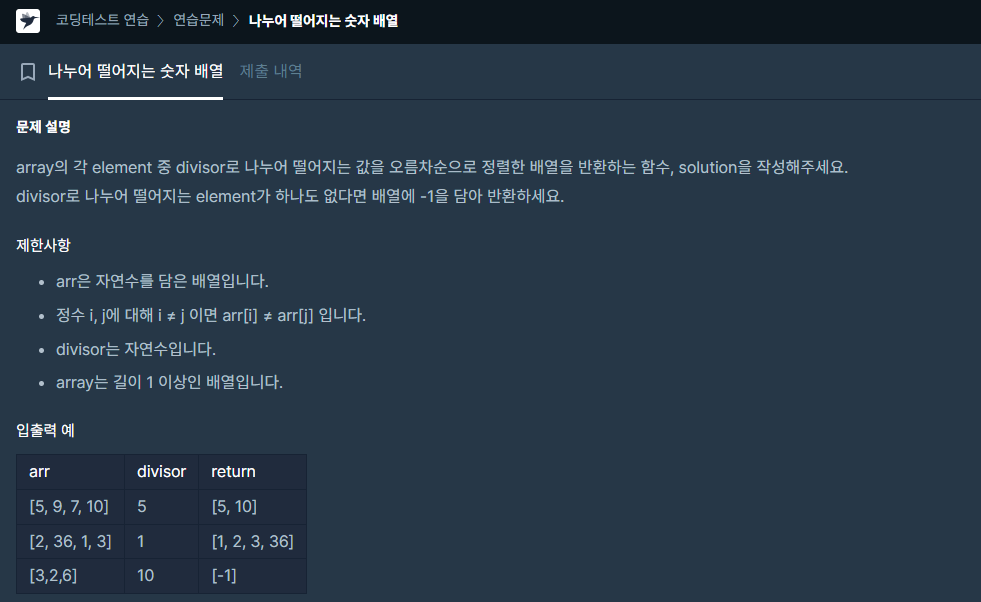
✔️ 문제 #3: 나누어 떨어지는 숫자 배열
✔️ 제출 코드
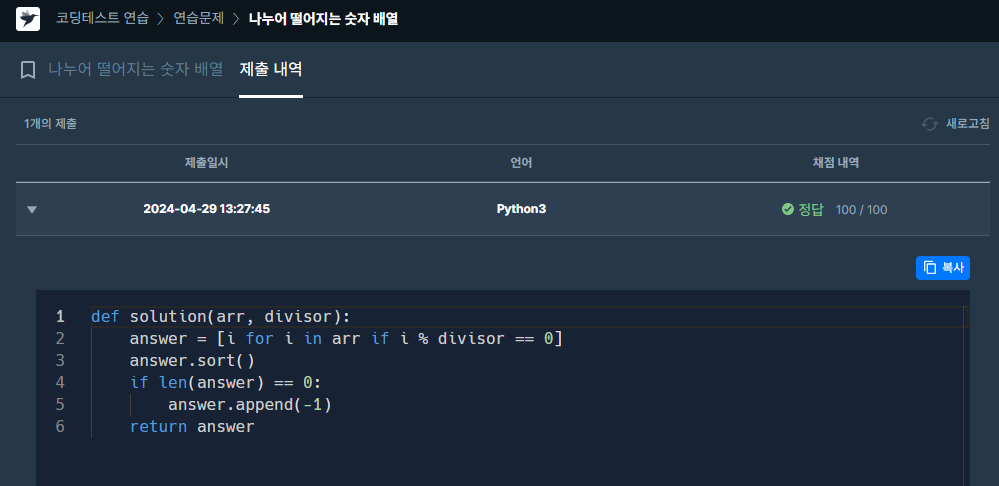
✔️ 코드 분석
def solution(arr, divisor):
answer = [i for i in arr if i % divisor == 0]
answer.sort()
if len(answer) == 0:
answer.append(-1)
return answer
✔️ CHECK POINT
- PYTHON
- 들여쓰기 오류 : expected an indented block
- 리스트 내 값이 비어있는지 확인하는 방법으로 len(list) == 0 사용 가능!
- 리스트에서 특정 문자열 추출하기
-
문자열 리스트 만들기 (문장의 경우 split 활용 공백 기준으로 단어로 잘라주기)
-
for 문 사용하기
#a_list는 특정 문자열이 추출된 리스트 / b_list는 기본 문자열 리스트 a_list = [] for word in b_list: if '특정 문자열' in word: a_list.append(word) -
리스트 컴프리헨션 사용하기
#a_list는 특정 문자열이 추출된 리스트 / b_list는 기본 문자열 리스트 a_list = [word for word in b_list if '특정문자열' in word]
-

커피 좋아하는 데이터 꿈나무