
WHAT IS KATA?
KATA는 기술과 기술 향상에 초점을 맞춘 코드 챌린지입니다.
일부는 프로그래밍 기본 사항을 교육하는 반면 다른 일부는 복잡한 문제 해결에 중점을 둡니다.
이 용어는 The Pragmatic Programmer 라는 책의 공동 저자인 Dave Thomas 가
무술에서 일본의 카타 개념을 인정하면서 처음 만들어졌습니다.
Dave의 개념 버전은 코드 카타를 프로그래머가
연습과 반복을 통해 기술을 연마하는 데 도움이 되는 프로그래밍 연습으로 정의합니다.
- SQL
✔️ 문제 #1: Exchange Seats
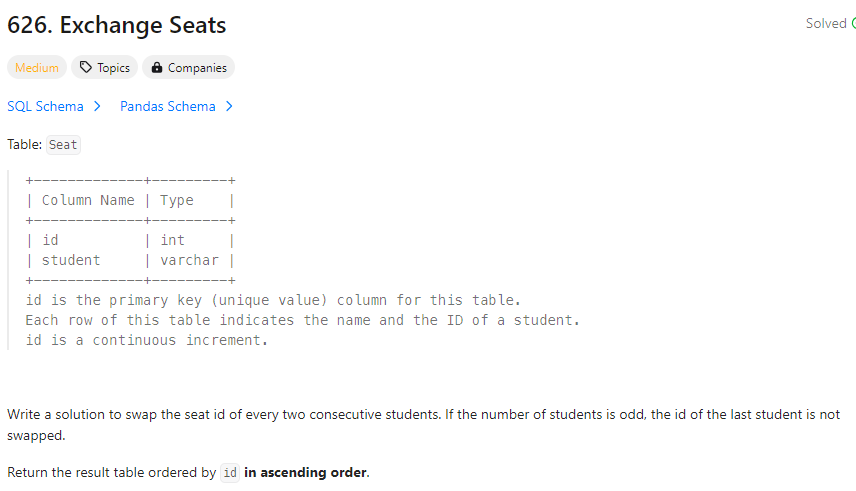
- 문제를 이해하는 데 한참 걸렸다..ㅋㅋ
- 연속하는 학생들의 자리를 바꿔주는 문제.
홀수와 짝수를 구분하여 id 를 +1 해주거나 -1을 해주는 방식으로 접근했고,
마지막 홀수 자리의 학생이 혼자일 때 자리를 바꾸지 않는다는 것을 표현하는 게 살짝 어려웠다.
✔️ 제출 쿼리
✔️ 쿼리 분석
SELECT CASE WHEN MOD(id, 2) = 0 THEN id - 1
WHEN MOD(id, 2) = 1 AND id + 1 NOT IN (SELECT id FROM seat) THEN id
ELSE id + 1 END id,
student
FROM Seat
ORDER BY id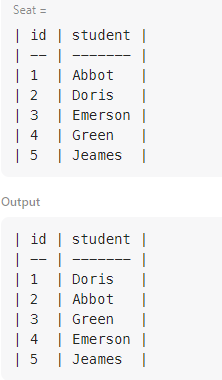
✔️ 문제 #2: Movie Rating
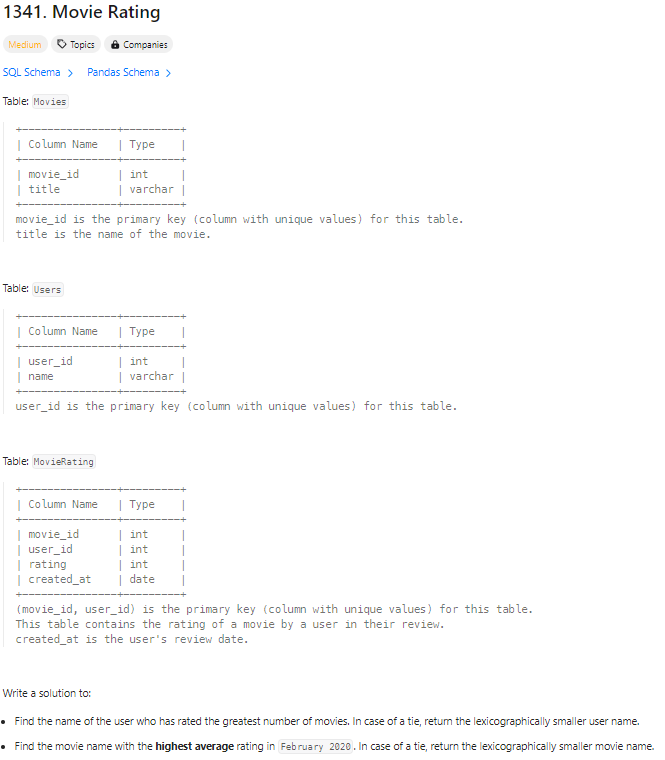
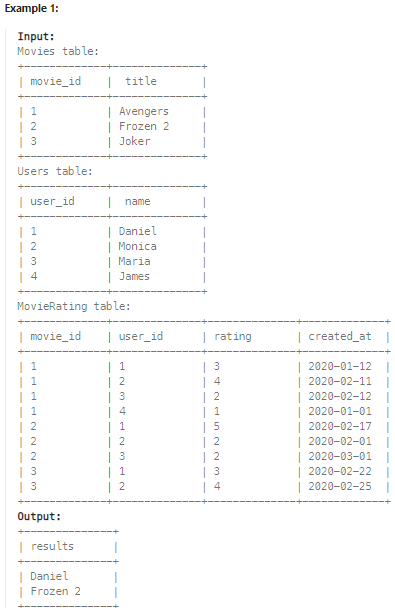
-
출력 예시를 보고 이해할 수 있었던 문제.
MovieRating 이라는 테이블에서 조건을 걸고 해당하는 user_id와 title을 조회 후,
results라는 컬럼 아래 값을 그대로 붙여야 했다.
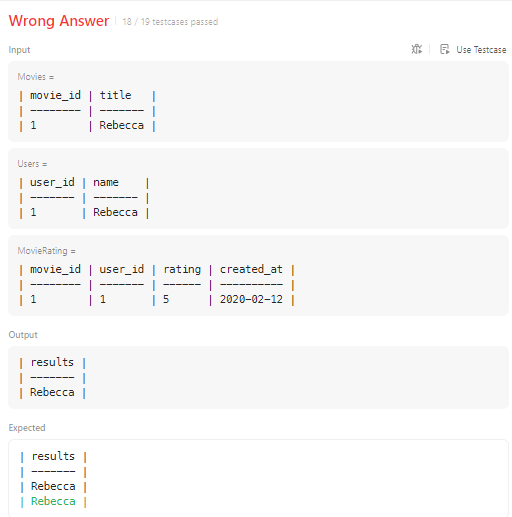
-
각각 조건에 해당하는 것들을 WITH 절로 잘 만들어 냈는데,
results로 UNION을 하니 사용자 이름과 영화 제목이 동일한 케이스에서 통과되지 않았다. -
그래서 UNION을 하면서 중복값을 제거해주는 UNION ALL 을 사용 : )
✔️ 제출 쿼리
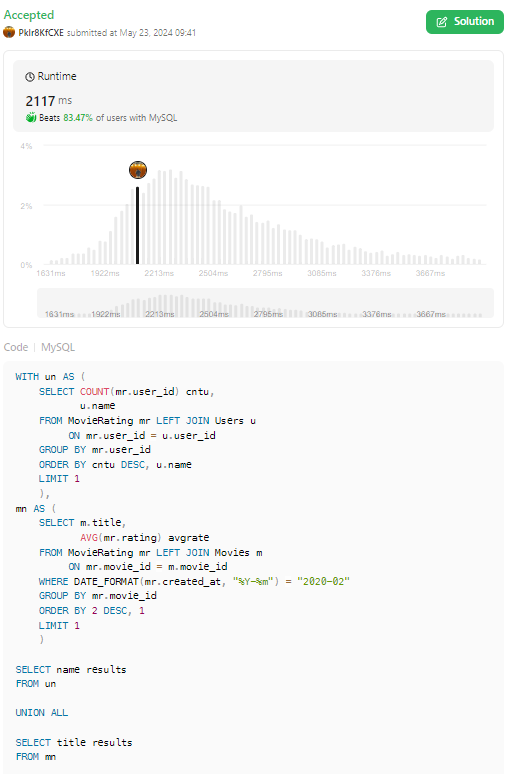
✔️ 쿼리 분석
WITH un AS (
SELECT COUNT(mr.user_id) cntu,
u.name
FROM MovieRating mr LEFT JOIN Users u
ON mr.user_id = u.user_id
GROUP BY mr.user_id
ORDER BY cntu DESC, u.name
LIMIT 1
),
mn AS (
SELECT m.title,
AVG(mr.rating) avgrate
FROM MovieRating mr LEFT JOIN Movies m
ON mr.movie_id = m.movie_id
WHERE DATE_FORMAT(mr.created_at, "%Y-%m") = "2020-02"
GROUP BY mr.movie_id
ORDER BY 2 DESC, 1
LIMIT 1
)
SELECT name results
FROM un
UNION ALL
SELECT title results
FROM mn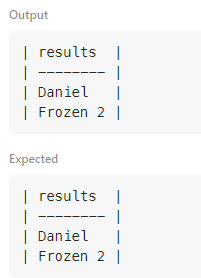
- PYTHON
✔️ 문제 #1: 문자열 나누기
✔️ 제출 코드
✔️ 코드 분석
def solution(s):
answer = 1 # s는 처음에 한 문단으로 이루어져 있고 분할할 때마다 문단 수 증가
x = s[0] # x는 현재 문자열 s에서 맨 앞 문자
x_count = 0 # x와 같은 문자의 갯수
y_count = 0 # x가 아닌 문자의 갯수
for i in s:
#x_count와 y_count가 같다면, 문단 분할 후 x를 현재 값으로 초기화
# 분할 후 다음 문자를 바로 i로 할당
if x_count != 0 and x_count == y_count:
answer += 1 # 분할로 인한 문단 수 증가
x_count = 0 # 카운트 변수 초기화
y_count = 0 # 카운트 변수 초기화
x = i # x값에 나머지 문자열의 앞 문자 i 할당
if i == x: # i가 x와 동일한 값이면 x_count 1 추가
x_count += 1
else: # 다른 경우 y_conut 1 추가
y_count += 1
return answer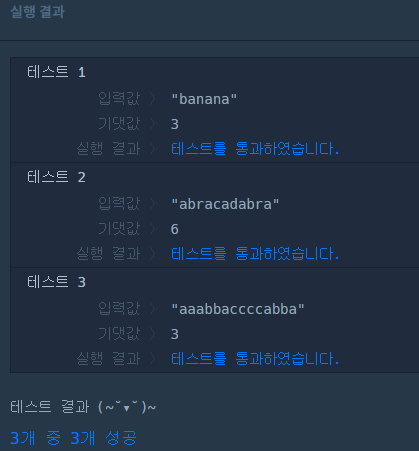
✔️ CHECK POINT
- SQL
- 나머지를 조회하는 MOD()
MOD(대상 컬럼, 나눌 숫자) = ? - 중복값을 제거하면서 행을 결합하는 UNION ALL
- 나머지를 조회하는 MOD()

커피 좋아하는 데이터 꿈나무