
개요
왜 스파크일까?
SPARK
📌 스파크란?
Apache Spark: 대규모 데이터 처리를 위한 오픈 소스 분산 컴퓨팅 프레임워크
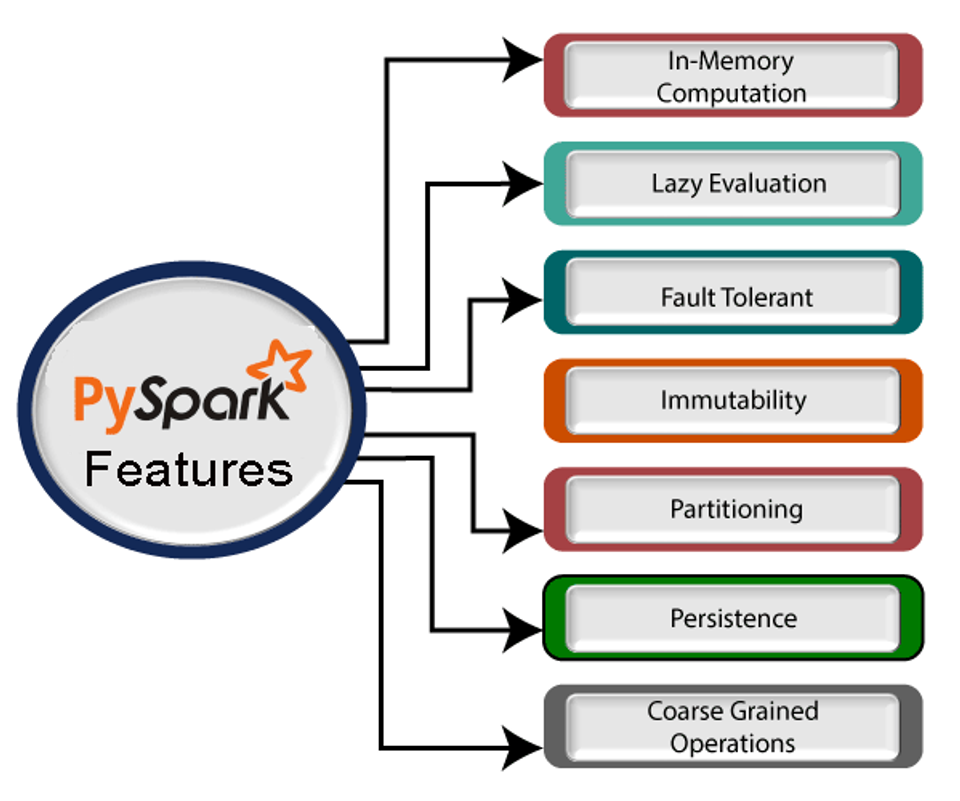
-
주요 특징:
-
속도 (Speed)
- 인메모리 처리: 데이터를 메모리에 캐싱하여 디스크 기반 시스템보다 최대 100배 빠르게 처리
- 최소한의 디스크 I/O: 디스크 읽기/쓰기를 최소화하여 처리 속도를 높임
-
다중 언어 지원 (Multi-Language Support)
- Java, Scala, Python, R, SQL 등 다양한 언어 지원
-
고급 분석 (Advanced Analytics)
-
SQL 쿼리: 분산 ANSI SQL 쿼리를 빠르게 실행하여 대시보드 및 애드혹 보고 지원
-
스트리밍 데이터: 실시간 데이터 스트리밍 처리 지원
-
머신 러닝 (MLlib): 내장된 머신 러닝 라이브러리를 통해 확장 가능한 머신 러닝 작업 수행
-
그래프 처리 (GraphX): 그래프 및 그래프 병렬 처리 기능 제공
-
-
확장성 (Scalability)
-
단일 노드에서부터 수천 대의 클러스터에 이르기까지 확장 가능한 분산 컴퓨팅 지원
-
클러스터 매니저로 YARN, Mesos, Kubernetes, Spark Standalone 사용 가능
-
-
유연성 (Flexibility)
- 구조화된 데이터(테이블), 반구조화된 데이터(JSON), 비구조화된 데이터(이미지) 모두 처리 가능
-
역사
- 2009년 UC Berkeley의 AMPLab에서 개발되었으며, 2010년에 오픈 소스로 공개됨
-
사용 사례
-
데이터 웨어하우징, ETL(Extract, Transform, Load) 작업, 실시간 데이터 스트리밍, 머신 러닝 모델 학습 및 배포, 데이터 과학 프로젝트 등에서 널리 사용
-
Apache Spark는 현재 많은 기업에서 대규모 데이터 분석과 처리에 사용되고 있으며, 80% 이상의 포춘 500 기업들이 이를 활용 중이다.
-
수정중..
-

커피 좋아하는 데이터 꿈나무