
개요
📌 SQL Challenge
📌 WINDOW FUNCTION
-
정의
윈도우 함수는 행과 행 간의 관계를 정의하기 위해서 제공되는 함수
-
역할
윈도우 함수를 사용해서 순위, 합계, 평균, 행 위치 등을 조작할 수 있습니다.
-
특징
윈도우 함수는 GROUP BY 구문과 병행하여 사용할 수 없습니다.
윈도우 함수로 인해 결과 건수가 줄어들지는 않습니다.(집계 제외)
윈도우 함수와 group by 구문은 둘 다 파티션을 분할한다는 의미에서 유사합니다.
다른 함수와 달리 중첩해서 사용은 못하지만, 서브쿼리에는 사용할 수 있습니다. -
종류
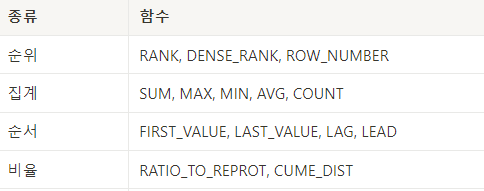
순위
RANK,DENSE_RANK,ROW_NUMBER
집계
SUM,MAX,MIN,AVG,COUNT
순서
FIRST_VALUE,LAST_VALUE,LAG,LEAD
비율
RATIO_TO_REPROT,CUME_DIST -
문법
# 윈도우 함수 기본문법
SELECT WINDOW_FUNCTION () OVER([PARTITION BY 컬럼] [ORDER BY 컬럼])
FROM 테이블명📌 실습
-
실습 환경 : DB-FIDDLE
-
테이블 생성
CREATE TABLE Employees ( JOB VARCHAR(255), NAME VARCHAR(255), SALARY INT ); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('data analyst', 'Amanda', 10000); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('data analyst', 'carloll', 10000); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('data analyst', 'Chloe', 9000); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('data analyst', 'Elizabeth', 9000); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('artist', 'Emma', 8000); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('artist', 'Arnold', 8000); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('artist', 'Grace', 7000); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('actor', 'Jade', 5000); INSERT INTO Employees (JOB, NAME, SALARY) VALUES ('actor', 'Oliver', 3000);

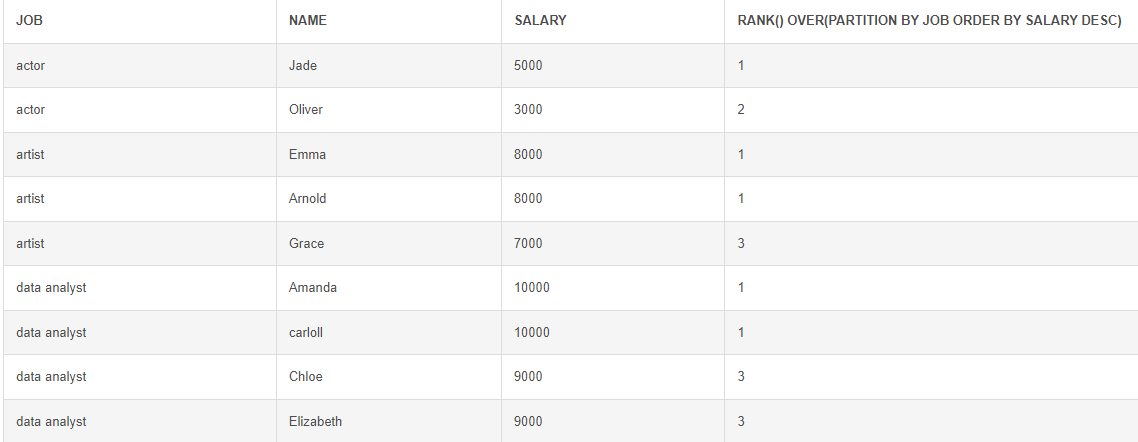
- 순위
RANK() : 중복 순위 O / EX) 1>1>3>4>4>5
# 랭크 함수 SELECT *, RANK() OVER(PARTITION BY JOB ORDER BY SALARY DESC) FROM Employees
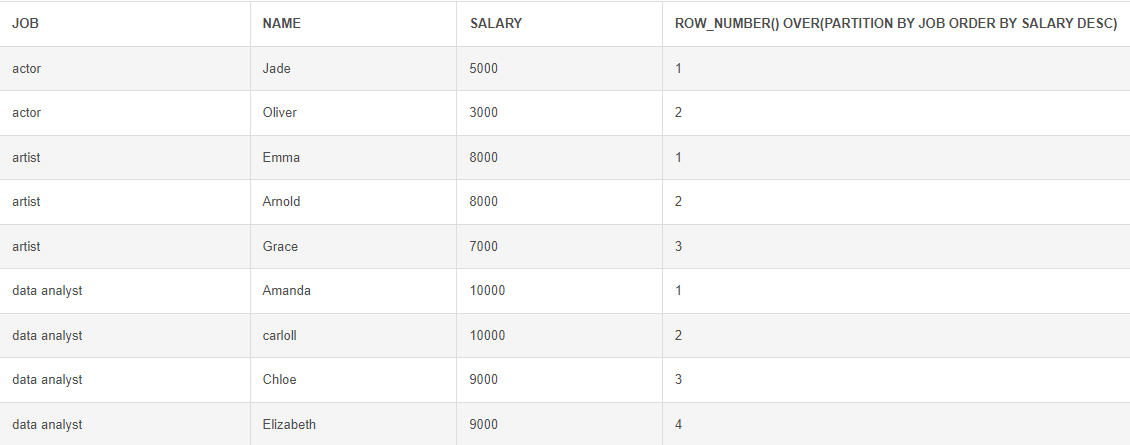
ROW_NUMBER : 어떻게든 순위 정해줌, 중복 순위 X / EX) 1>2>3>4
# 로우 넘버 함수 SELECT *, ROW_NUMBER() OVER(PARTITION BY JOB ORDER BY SALARY DESC) FROM Employees
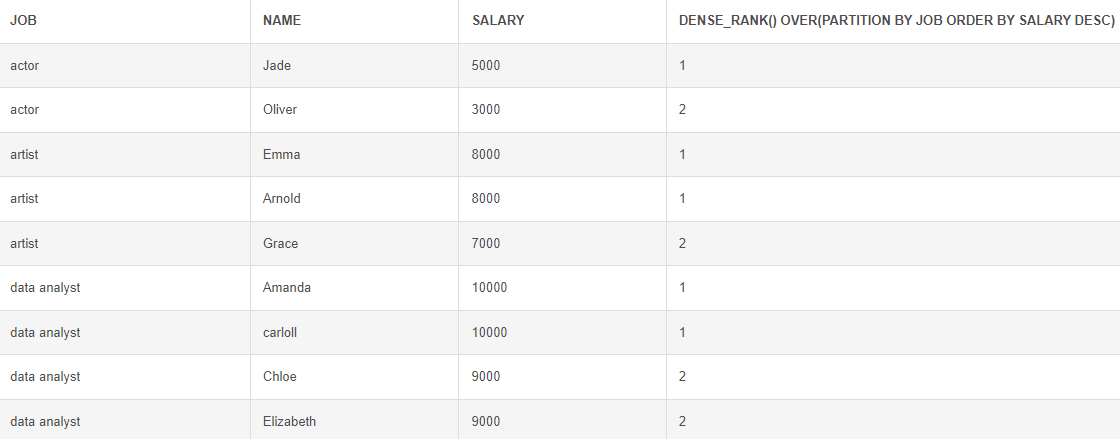
DENSE_RANK() : 중복 순위 O, 빠지는 숫자 없음 / EX) 1>1>2>3>3>3
# 덴스 랭크 함수 SELECT *, DENSE_RANK() OVER(PARTITION BY JOB ORDER BY SALARY DESC) FROM Employees
- 순서
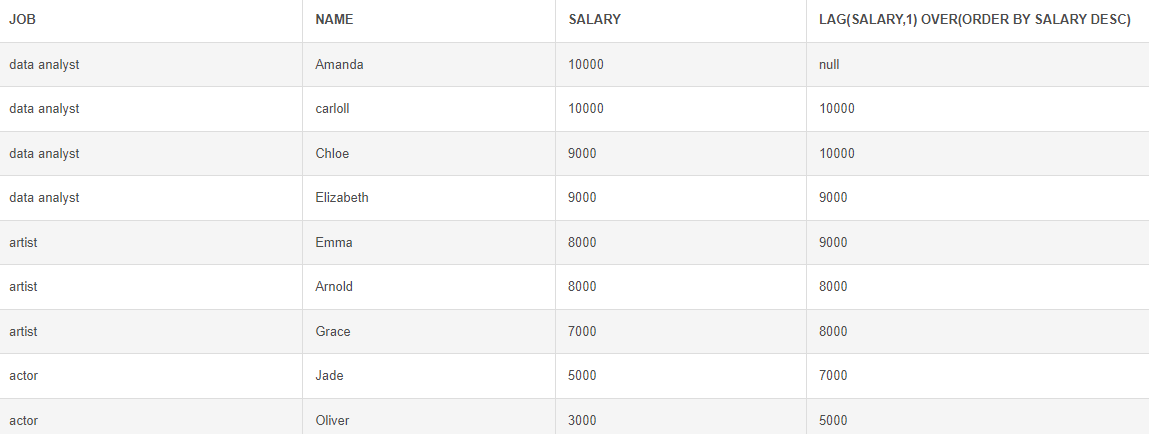
LAG() : 이전 N 번째의 행을 가져오는 함수 (N의 최대값은 3, 기본값은 1)
# 래그 함수 (값을 지연시키는 함수, N 값은 최대 3) SELECT *, LAG(SALARY,1) OVER(ORDER BY SALARY DESC) FROM Employees
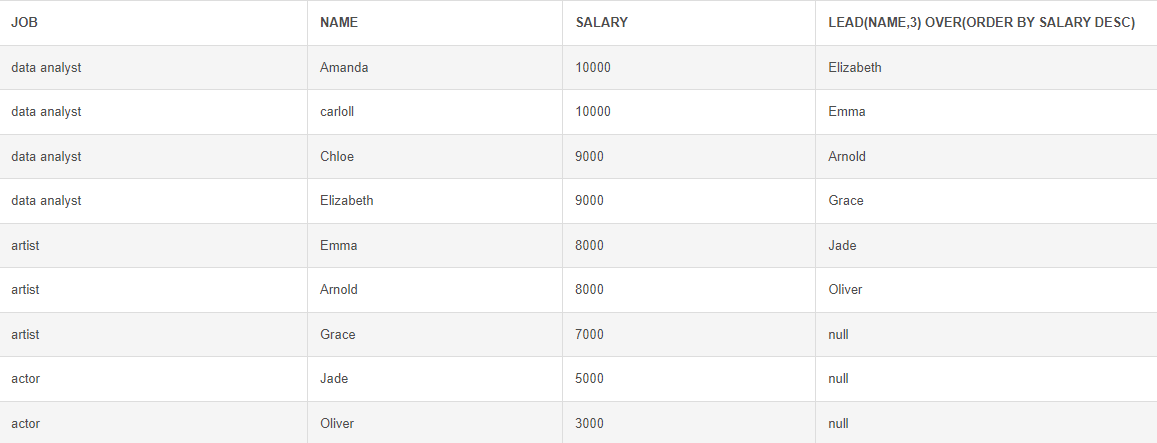
LEAD() : 이후 N행의 값을 가져오는 함수 (N의 최대값은 3, 기본값은 1)
# 리드 함수 (값을 당겨오는 함수, N 값은 최대 3) SELECT *, LEAD(NAME,3) OVER(ORDER BY SALARY DESC) FROM Employees
📌 String 함수
CONCAT() : 문자열을 병합할 때 사용
# CONCAT 함수 SELECT CONCAT('피카츄','라이츄')

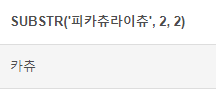
SUBSTRING() : 문자열을 자를때 사용
# SUBSTR 함수 ('문자열', 위치, 길이) SELECT SUBSTR('피카츄라이츄', 2, 2)
SUBSTRING_INDEX() : 문자열을 특정 구분기호를 통해 출력할 때 사용
# SUBSTRING_INDEX 함수 (문자열, 구분자, 갯수) # SELECT SUBSTRING_INDEX('피카츄.라이츄.파이리.꼬부기.버터플','.',3) SELECT SUBSTRING_INDEX(SUBSTRING_INDEX('피카츄.라이츄.파이리.꼬부기.버터플','.',3),'.',-1)

REVERSE() : 문자열을 뒤집을 때 사용, 특정 문자를 찾고자 할 때, RVERSE 함수를 이용하기도 함.
# REVERSE 함수 SELECT REVERSE('피카츄')

LEFT(), RIGHT() : 문자열을 기준으로부터 N 개 출력
# LEFT, RIGHT 함수 SELECT LEFT('피카츄라이츄1234', 5) SELECT RIGHT('피카츄라이츄1234', 5) SELECT RIGHT('스파르타코딩클럽데이터분석2기짱', 3)


📌 Math 함수
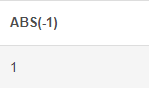
ABS() : 절대값
# ABS 함수 SELECT ABS(-1)
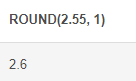
ROUND() : 숫자를 소수점 이하 자릿수에서 반올림하여 출력 (, 이후에 몇번째 까지 출력할 지 입력)
# ROUND 함수 SELECT ROUND(2.55, 1)
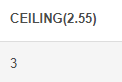
CEILING() : 소수점을 올림하여 출력
# CEILING SELECT CEILING(2.55)
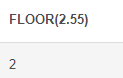
FLOOR() : 소수점을 버림하여 출력
# FLOOR SELECT FLOOR(2.55)
📌 날짜 함수
NOW, SYSDATE, CURRENT_TIMESTAMP : 현재시간과 날짜를 출력
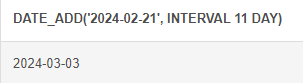
# NOW(), SYSDATE(), CURRENT_TIMESTAMP() - 현재 시간 출력DATE_ADD : 날짜에서 기준값 만큼 덧셈하여 출력
# DATE_ADD (날짜에서 기준값만큼 덧셈, 기준값: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) SELECT DATE_ADD('2024-02-21', INTERVAL 11 DAY)
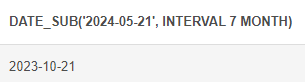
DATE_SUB : 날짜에서 기준값 만큼 뺄셈하여 출력
# DATE_SUB (날짜에서 기준값만큼 뺄셈, INTERVAL 기준값: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) SELECT DATE_SUB('2024-05-21', INTERVAL 7 MONTH)
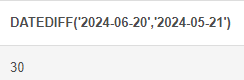
DATEDIFF : 두 날짜를 뺄셈하여 출력
# DATE_DIFF (두 날짜를 뺄셈하여 출력, DATE1(큰 날짜) - DATE2(작은 날짜)) SELECT DATEDIFF('2024-06-20','2024-05-21')
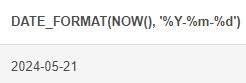
DATE_FORMAT : 날짜를 형식에 맞게 출력
# DATE_FORMAT (날짜를 형식에 맞체 출력) SELECT DATE_FORMAT(NOW(), '%Y-%m-%d')
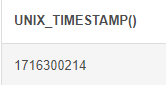
UNIX_TIMESTAMP : 현재시간을 UNIXTIME 으로 출력
# UNIX_TIMESTAMP (현재 시간을 UNIXTIME으로 출력) SELECT UNIX_TIMESTAMP()
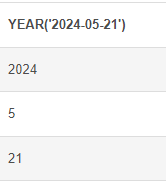
YEAR, MONTH, DAY : 날짜의 연도, 월, 일 출력
# YEAR, MONTH, DAY 함수 SELECT YEAR('2024-05-21') UNION SELECT MONTH('2024-05-21') UNION SELECT DAY('2024-05-21')
📌 WITH절, SUBQUERY
- WITH절과 서브쿼리, 무엇을 써야 할까?
- 하나의 테이블처럼 사용하는 FROM절 서브쿼리 (인라인 뷰),
1번이라면 WITH절을 사용하는 것과 성능에 큰 차이가 없을 수 있다. - 다만 재사용성과 가독성의 측면에서 WITH절을 사용하는 것을 추천
📌 쿼리 스타일 가이드
# MOZILLA SQL 스타일 가이드 (쿼리문 스타일 권장사항) # 예약어는 대문자로 작성 (SELECT FROM WHERE 등) # 컬럼 이름은 `snake_case` 추천 / 또는 CamelCase (일관성이 중요) # 명시적 VS 암시적 이름 (WITH 절의 테이블명이나 컬럼 이름 명시할 때 명시적으로 작성) # 왼쪽 정렬 권장 # 예약어나 칼럼은 한 줄에 하나씩 권장

+)
# GROUP BY 사용 시, SELECT절에 집계함수를 제외한 모든 컬럼을 GROUP BY에 명시