
#INTRO
빙글뱅글빙글뱅글

오늘만 하면 또 주말이야 !
#기초 프로젝트 발제 (09:00 ~ 10:00)
-
벌써 부트캠프 시작 5주차..
한 달 동안 학습한 내용들을 활용해 기초 프로젝트를 해보는 시간이 되었다. -
"ON AIR 분석 절차를 기반으로한 프로젝트" - 기초 프로젝트
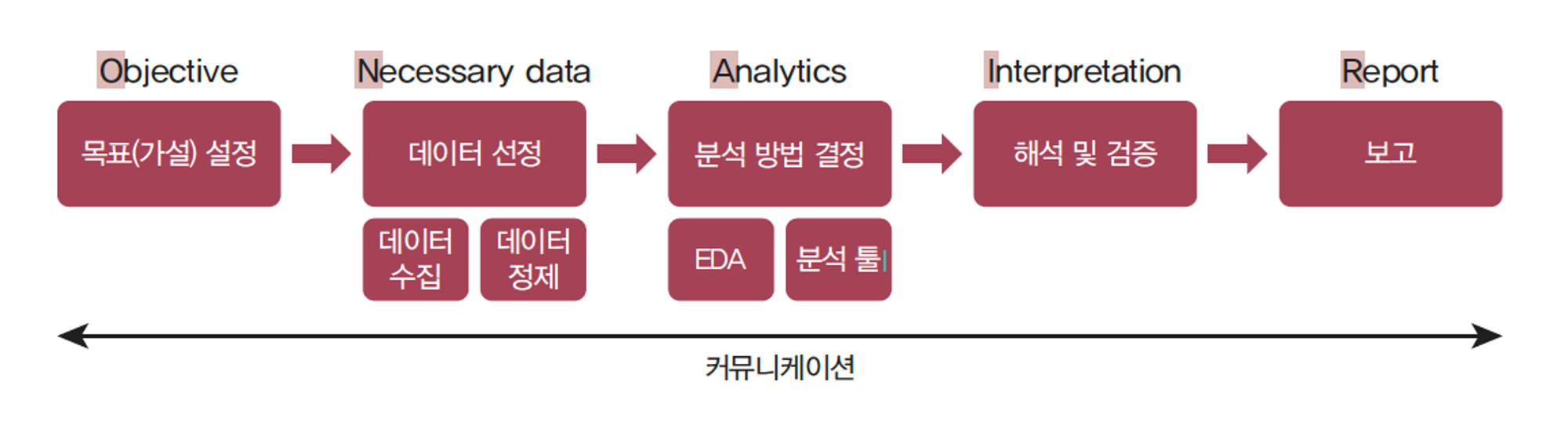
Objective (목표)- 프로젝트 목표 : 프로젝트의 주요 목표를 명확히 기술,
어떤 문제를 해결하고자 하는지, 어떤 비즈니스 목표를 달성하려는지 설명 - 예상 결과물 : 프로젝트를 통해 기대되는 결과물과 도출하고자 하는 인사이트 명시
- 프로젝트 목표 : 프로젝트의 주요 목표를 명확히 기술,
Necessary Data (데이터)- 데이터 소스 : 사용할 데이터의 출처를 설명하고, 필요한 데이터 유형과 범위 명시
- 데이터 수집 계획 : 데이터를 수집하기 위한 계획과 방법 기술,
데이터 수집의 정확성과 완전성을 보장하기 위한 조치 고려
Analytics (분석)- 분석 방법 : 사용할 데이터 분석 기법과 모델을 선정하고 분석을 위한 절차 설명
- 데이터 처리 : 데이터를 정제하고 전처리하는 방법 기술, 분석에 필요한 데이터의 품질 확인
- 시각화 계획 : 데이터를 시각적으로 표현하여 인사이트를 도출하는 계획 제시
Interpretation (해석)- 분석 결과 해석 : 분석 결과를 해석하고, 비즈니스에 어떻게 적용할 수 있는지를 설명
- 인사이트 도출: 데이터에서 도출된 인사이트와 향후 전략 수립을 위한 제언을 제시
Report (보고)- 보고서 구조: 보고서의 구조와 형식을 정의하고, 어떤 정보를 포함할 것인지를 설명
- 시각화 활용: 보고서에 사용할 시각화 도구 및 방법을 결정하고, 강조할 요소를 구체화
- 보고서 작성 일정: 보고서 작성 및 발표 일정을 계획하고, 이를 관리할 방법을 기술
-
What to do: SQL과 Python을 활용한 데이터 분석 실전 연습 단계
정말 다양한 주제와 데이터들을 준비해주셔서 갬동..
-
열심히 해보자!
- “문제에 부딪히며 해결해나가는 과정을 회고할 수 있어야 한다”
- “크고 작음과 상관없이 팀이 목표한 바를 이루어냈는가”
- “그 목표를 이루기 위해 나는 스스로 어떤 노력을 했는가”
#데이터 살펴보기 (10:00 ~ 13:00)
- 주제: 음악플랫폼 데이터에 대한 EDA 진행, 서비스 현황 확인 및 개선점 제시 - 내용: - 서비스의 현 상태 확인 - 이슈사항 확인 - 고객 세그먼트화(특정 기준에 따라 유저 나누기) - 사용자의 연령과 성별, 고객 행동 패턴에 따라 코호트를 나누어 분석하여 다양한 인사이트 도출 - 변수 간의 상관관계 확인, Heatmap 등으로 시각화, 분포 확인 등 진행 - 다양한 지표 설계 - Action Item 등 인사이트 제공 - 목표 : 유저 행동 데이터 분석을 통한 매출 증대 방안 제시 - 프로젝트 핵심 내용: 다양한 관점에서 EDA를 수행하여 변수 간 상관관계 분석 및 시각화

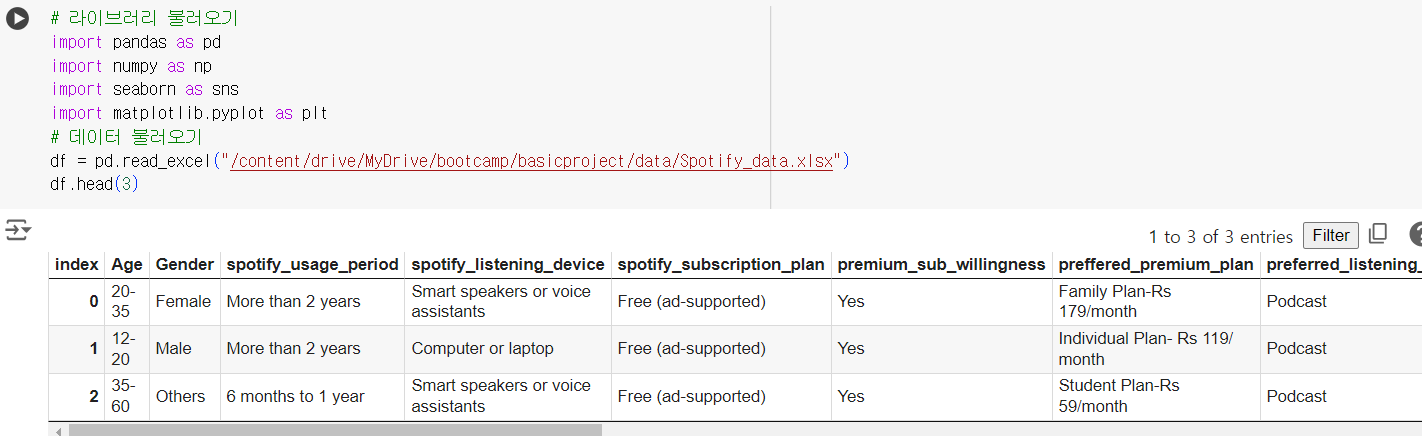
- 먼저 데이터를 불러오고 전체적으로 살펴봤다.
# 라이브러리 불러오기 import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt # 데이터 불러오기 df = pd.read_excel("/content/drive/MyDrive/bootcamp/basicproject/data/Spotify_data.xlsx") df.head(3)
# 시각화 관련 폰트 깨짐 문제 해결 !sudo apt-get install -y fonts-nanum !sudo fc-cache -fv !rm ~/.cache/matplotlib -rf # 폰트 설치 import matplotlib.pyplot as plt plt.rc('font', family='NanumBarunGothic') plt.rcParams['axes.unicode_minus'] =False # 기본 폰트 설정

- 데이터 확인
# 데이터 크기 확인 df.shape

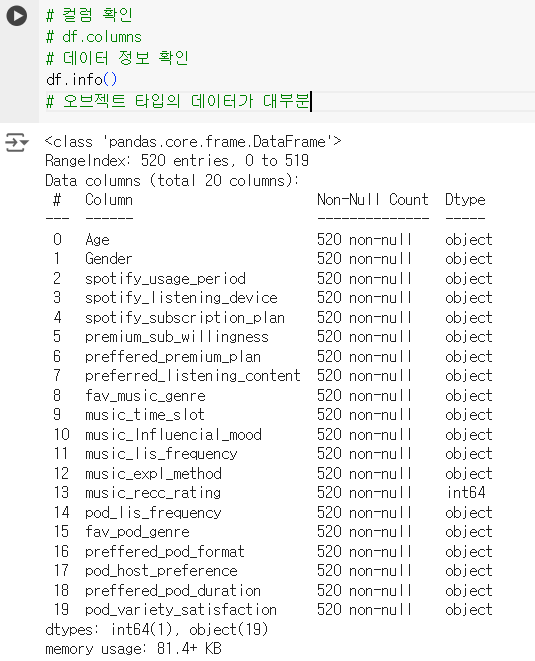
# 컬럼 확인 # df.columns # 데이터 정보 확인 df.info() # 오브젝트 타입의 데이터가 대부분
# 결측치 확인 print(df.isnull().sum())
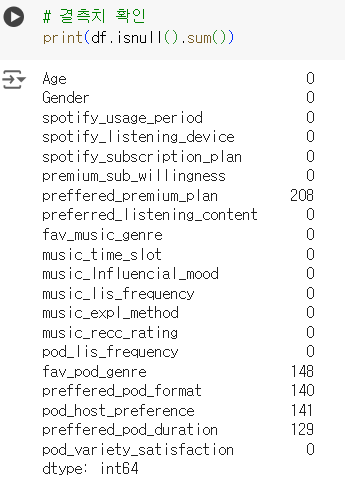
# 결측치 처리 어떻게..? # NaN 값은 실제로는 None 의 값을 가짐 # 설문에 응답하지 않은 데이터로 "N" 으로 대치 df = df.fillna(str("N")) print(df.isnull().sum()) df

# 데이터 기초 통계 확인 (범주형 데이터) df.describe(include = "object")

#EDA (탐색적 데이터 분석) (14:00 ~ 20:00)
-
프로젝트 관련 내용은 따로 정리해야겠다.
-
각 컬럼별
value_counts()를 조회하고 데이터의 특징을 파악EDA 역할분담
결측치 공통적으로 처리 후 EDA탐색 시작
- 팀원들이 각자 컬럼을 하나씩 잡고 각 컬럼 기준 특징을 파악하는 시간을 가졌다.
주로 확인하고자 했던 컬럼들은 spotify_usage_period(사용기간) 기준music_time_slot기준Gender, Age기준music_recc_rating기준spotify_subscription_plan(Free vs Premium) 기준- 각 기준에 따른 이용자 현황분석으로 인사이트 도출이 목표 !
- 팀원들이 각자 컬럼을 하나씩 잡고 각 컬럼 기준 특징을 파악하는 시간을 가졌다.
-
오늘 프로젝트 진행의 결론은 괄목할만한 인사이트 도출에는 실패..
다음주에는 기준에 따른 특징의 데이터와 다른 변수들과의 관계나 특징을 위주로 파악해볼 예정!
# 오늘 나의 시도
범주형 - 범주형 데이터를 분석하기 위해 교차검증 사용 후 히트맵으로 시각화
# 시도 결과
이용기간을 기준한 분석으로는 유의미한 인사이트나 결론 도출이 어려웠다.
데이터의 분포가 편향이 큰 편인 것 같다.
(music과 podcast 의 사용 비율, 성별 비율(female 이 압도적), 무료 플랜 사용자 비율(무료가 압도적) 등)
# 다른 시도할만한 재료
추천을 통해 음악을 처음 접하는 사람이 가장 많다.
추천시스템에 대한 만족도, 음악장르, podcast 사용 등에 대한 관련성이나 특징을 종합적으로 살펴보자.#OUTRO
오늘의 한 줄.
즐겁게 하자 !

커피 좋아하는 데이터 꿈나무