
#INTRO
인생무상 : )

힘내자.
#코드카타 (09:00 ~ 10:00)
-
SQL
- MySQL 8.0 버전 미만에서 WITH 문 사용이 안돼서 서브쿼리로 문제를 풀었지만,
같은 문제를 WITH 문 활용한 CTE 생성으로 쿼리 작성 시도
- MySQL 8.0 버전 미만에서 WITH 문 사용이 안돼서 서브쿼리로 문제를 풀었지만,
WITH MaxScores AS (
# CTE: 각 해커가 각 도전 과제에서 얻은 최고 점수 계산
SELECT s.hacker_id,
s.challenge_id,
MAX(s.score) AS max_score
FROM Submissions s
GROUP BY s.hacker_id, s.challenge_id
# GROUP BY: 해커와 도전 과제별로 그룹화하여 각 그룹 내에서 최대 점수 계산
)
SELECT s.hacker_id,
h.name,
SUM(s.max_score) AS total_score
# 외부 쿼리: 각 해커의 이름과 총 점수 반환
FROM MaxScores s
LEFT JOIN Hackers h ON s.hacker_id = h.hacker_id
# JOIN: CTE(MaxScores)를 Hackers 테이블과 결합하여 해커 이름 가져오기
GROUP BY s.hacker_id, h.name
# GROUP BY: 해커별 그룹화하여 총 점수 계산
HAVING SUM(s.max_score) > 0
# HAVING: 총 점수가 0보다 큰 해커만 선택
ORDER BY total_score DESC, s.hacker_id
# ORDER BY: 총 점수 기준 내림차순 정렬, 동일 점수인 경우 해커 ID로 정렬#실전 프로젝트 진행 (10:00 ~ 22:00)
-
데이터를 다시 바꿨다.
-
태블로에서 제공하는 샘플데이터에서 찾아보다가 INC 5000 이라는 데이터를 발견하게 되었고,
구글링을 통해서 비교적 최근 (2021년) 데이터셋을 활용해
데이터 분석 & 대시보드 제작을 하기로 했다.
Inc. 5000은 미국에서 가장 빠르게 성장하는 비상장 기업들을 순위 매기는 리스트이다.
1982년에 시작된 Inc. 500 리스트에서 확장되어 2007년에 Inc. 5000이 되었다.
이 리스트는 혁신과 기업가 정신을 기념하며, 3년 간의 총 수익 성장률을 기준으로 순위를 매긴다.
또한, 업종, 지역, 수익, 직원 수 등을 기준으로도 순위가 매겨진다.
- 이 데이터를 선택하게 된 이유이다.
미국에서 가장 빠르게 성장하는 비상장 기업들의 데이터를 활용해,
미국 산업 시장을 분석하고, 인사이트를 도출하여, 대시보드를 구성해보고 싶었다.
- 이번 프로젝트에서 나의 목표는 대시보드 기획 ~ 제작 모든 과정을 시도해보는 것
최초 원본 데이터는 엑셀 파일로 되어 있었고,
웹 크롤링으로 생성된 데이터 파일 같았다.
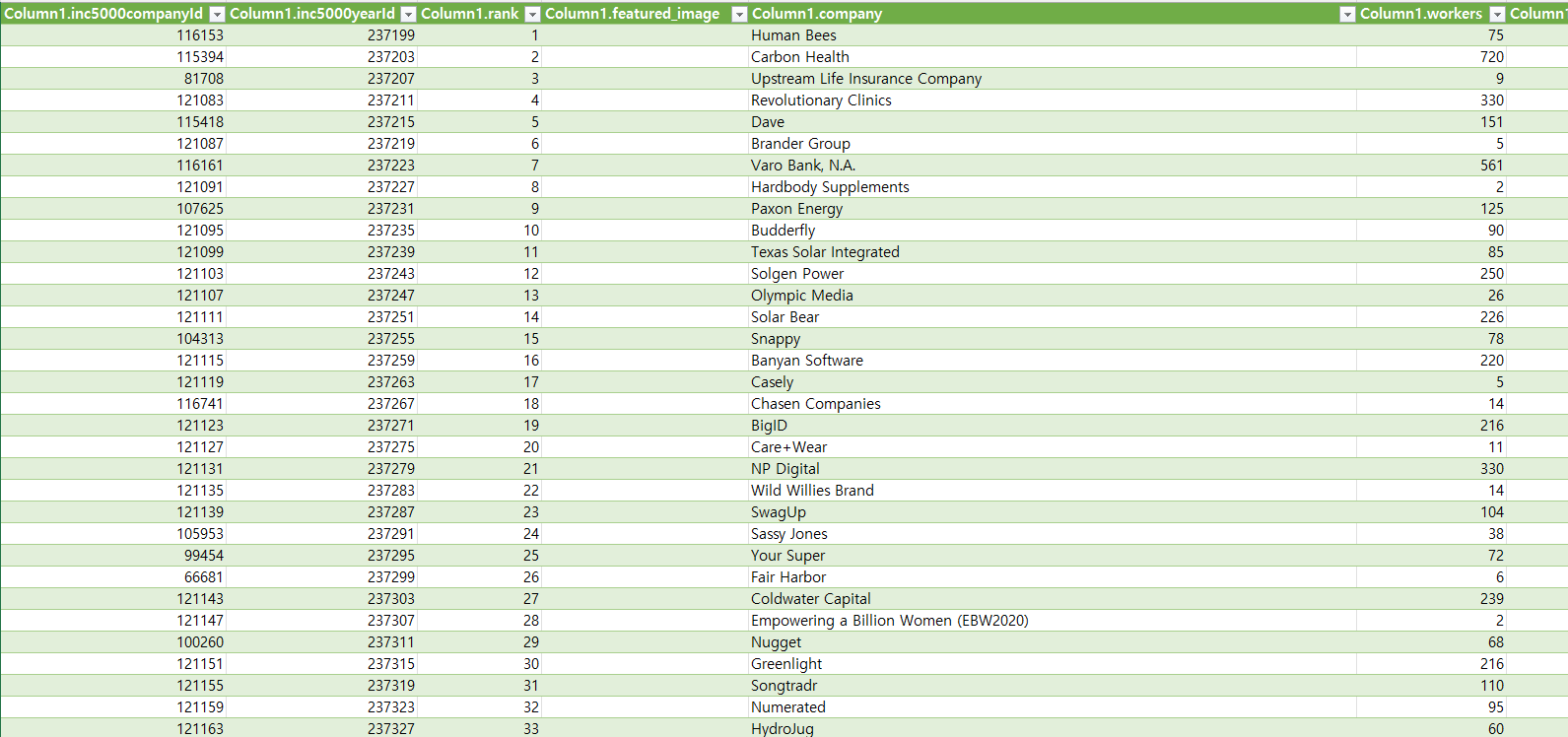
컬럼들의 이름이 보기 불편하게 되어 있어 삭제하고 확인
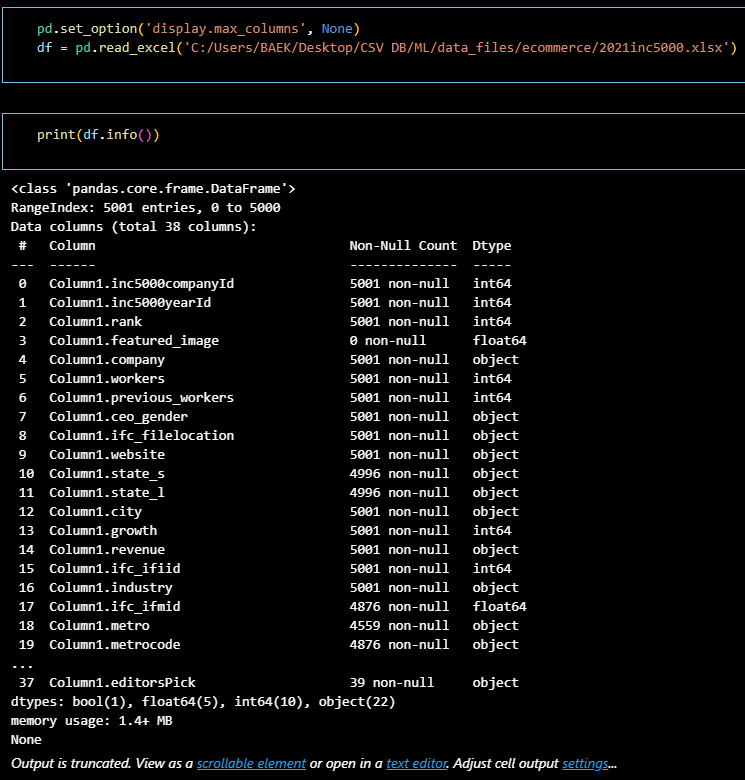
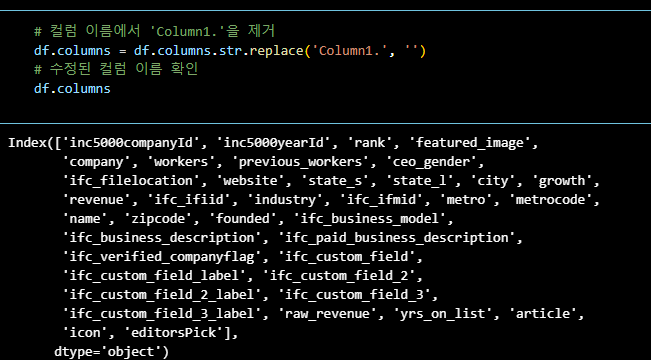
데이터셋 컬럼 상세 inc5000companyid: Inc5000 회사의 고유 ID inc5000yearid: 데이터가 기록된 연도의 ID rank: 해당 연도의 Inc5000 순위 featured_image: 회사에 대한 특징 이미지 파일 위치 company: 회사 이름 workers: 현재 직원 수 previous_workers: 이전 연도의 직원 수 ceo_gender: CEO의 성별 ifc_filelocation: 파일 위치 website: 회사 웹사이트 주소 state_s: 주(state) 약어 state_l: 주(state) 전체 이름 city: 도시 growth: 성장률 revenue: 연간 매출 ifc_ifiid: ifiid industry: 산업 분류 ifc_ifmid: ifmid metro: 광역지역 metrocode: 광역지역 코드 name: 이름 zipcode: 우편번호 founded: 설립 연도 ifc_business_model: 사업 모델 ifc_business_description: 사업 설명 ifc_paid_business_description: 유료 사업 설명 ifc_verified_companyflag: 검증된 회사 플래그 ifc_custom_field: 사용자 정의 필드 ifc_custom_field_label: 사용자 정의 필드 레이블 ifc_custom_field_2: 사용자 정의 필드 2 ifc_custom_field_2_label: 사용자 정의 필드 2 레이블 ifc_custom_field_3: 사용자 정의 필드 3 ifc_custom_field_3_label: 사용자 정의 필드 3 레이블 raw_revenue: 원시 매출 yrs_on_list: 목록에 올라간 연수 article: 기사 icon: 아이콘 editorspick: 편집자 추천
컬럼과 결측값을 확인하며 분석에 활용할 컬럼 선택
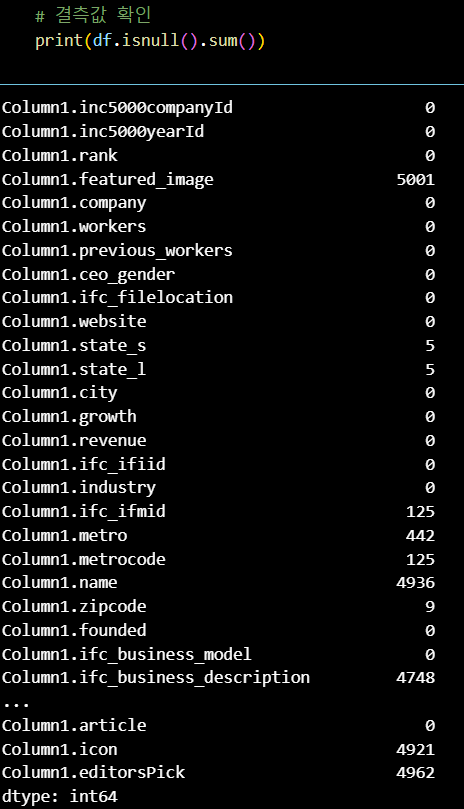
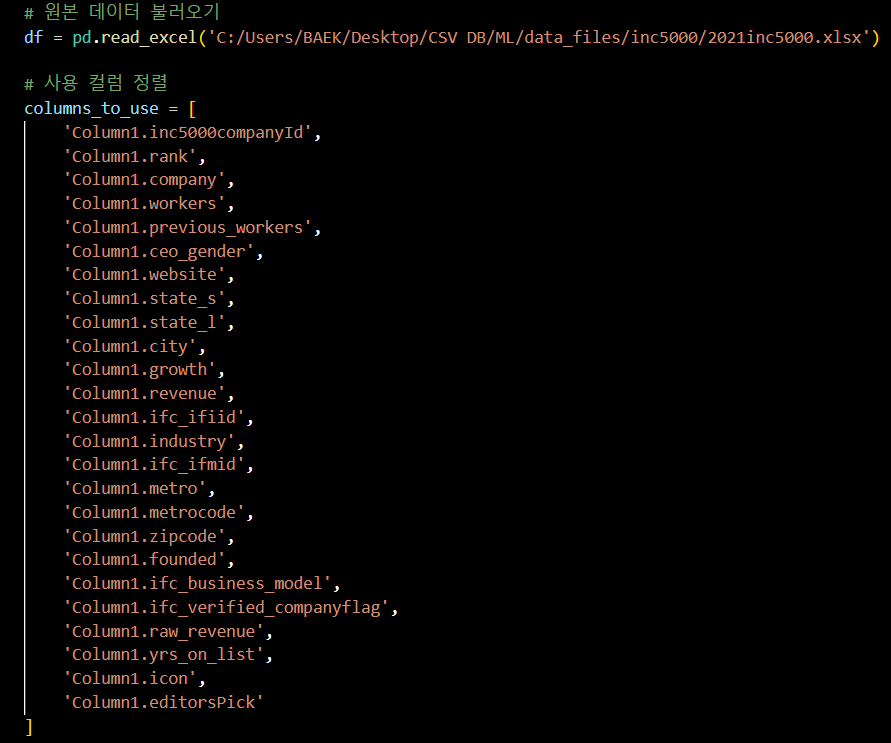
팀 회의를 통해 사용 컬럼을 정리하고,
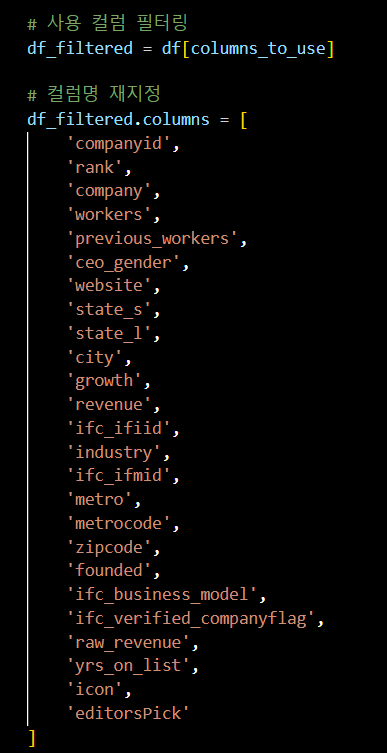
컬럼명을 보기 편하게 변경,
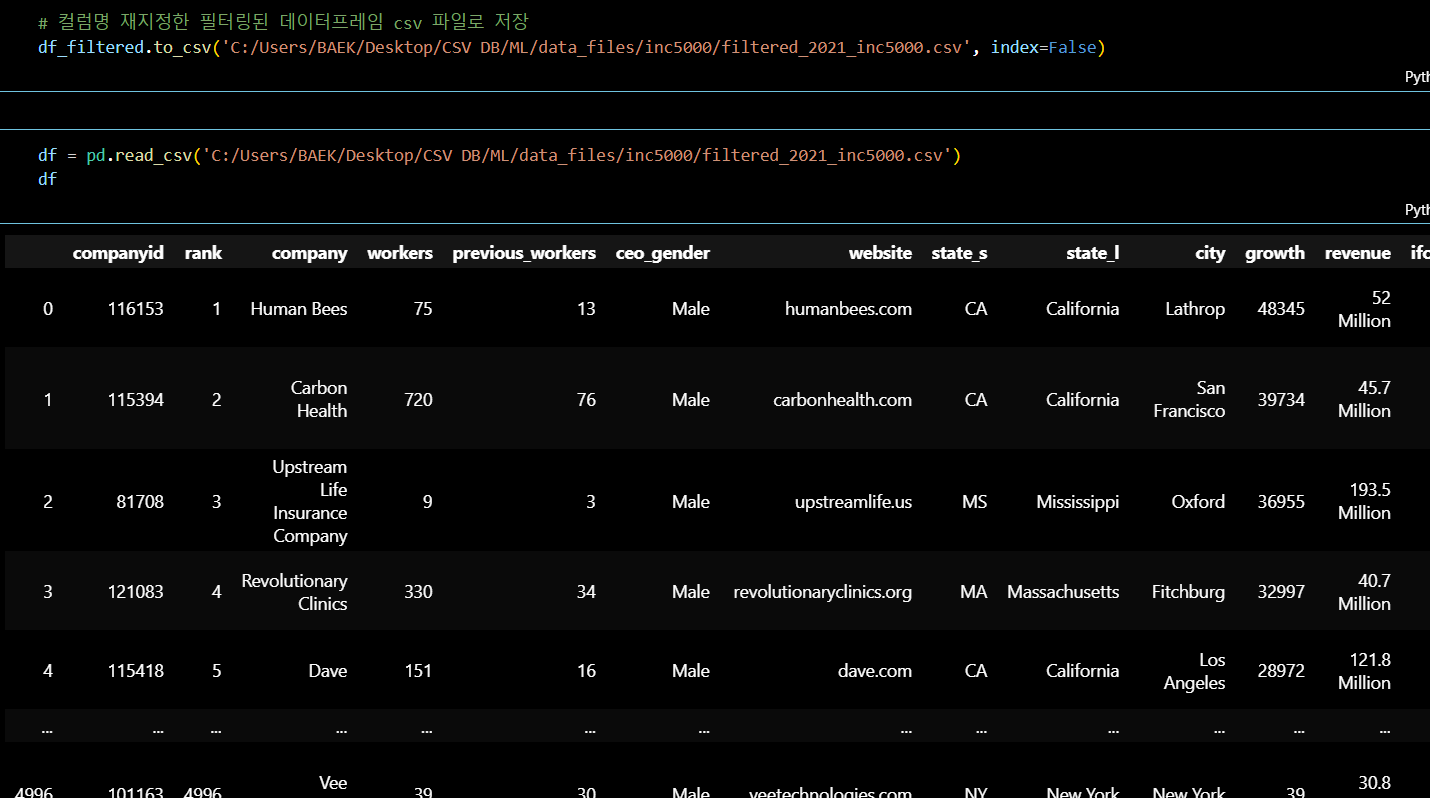
csv 파일로 저장하여 팀원 모두 같은 데이터셋으로 분석을 시작할 환경을 세팅했다.
내일부터 데이터를 자세히 확인하면서,
유의미한 인사이트를 도출하고,
지표들을 설정해서 대시보드를 기획하는 것을 시도해볼 예정
#OUTRO
오늘의 한 줄.
다시 차근차근 해보자 !

커피 좋아하는 데이터 꿈나무