
#INTRO
코로나라니..

어쩐지 쫌 마이 아프더라
#코드카타
-
PANDAS
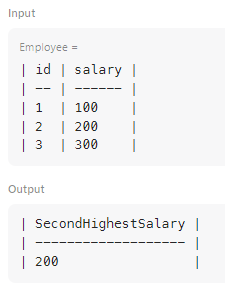
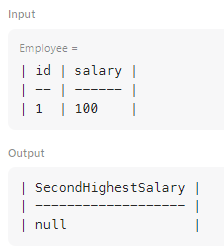
drop_duplicates()메서드를 사용하여 중복된 값을 제거한 후,sort_values(ascending=False)를 통해 내림차순으로 정렬하기# 중복된 급여를 제거하고, 높은 급여부터 낮은 급여 순으로 정렬하여 # 두 번째로 높은 급여를 찾기 위한 준비 sorted_salaries = employee['salary'].drop_duplicates().sort_values(ascending=False)iloc[1]을 사용하여 정렬된 리스트에서 두 번째 값을 선택하기# iloc[1]로 두 번째 값 가져오기 second_highest = sorted_salaries.iloc[1]- 조건문을 사용하여 두 번째 급여가 존재하지 않으면 None을 반환하기
# 만약 두 번째로 높은 급여가 존재하지 않으면 None을 반환하여 # 데이터를 처리할 때 발생할 수 있는 오류 방지 if len(sorted_salaries) < 2: second_highest = None
#최종 프로젝트 진행
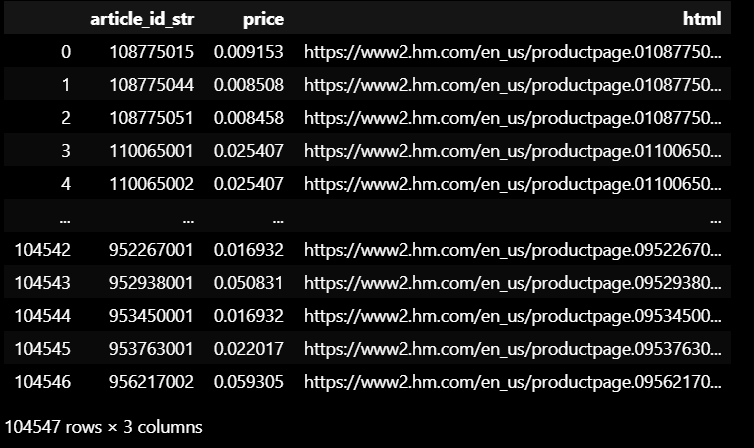
제품 이미지 크롤링 시도
-
제품별 홈페이지로 이동하는 url 링크 정리
-
이미지 링크에서 이미지 태그 찾기


-
가져올 링크 부분 확인하기 (
<img>태그 →srcset요소 텍스트)
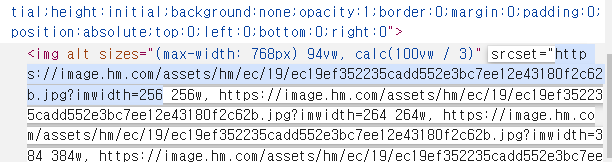
-
크롤링 코드 작성
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.common.exceptions import NoSuchElementException
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
def get_image(url):
options = Options()
wd = webdriver.Chrome(options=options)
wd.get(url)
time.sleep(2) # 페이지 로딩 대기
try:
# 현재 페이지 URL 확인 (만약 다른 페이지로 리디렉션된 경우)
current_url = wd.current_url
if current_url != url:
# 다른 페이지로 이동했을 경우 null 반환
return None
# 첫 번째 이미지의 srcset 속성을 찾음
img_tag = wd.find_element(By.TAG_NAME, 'img')
srcset = img_tag.get_attribute('srcset')
if srcset:
# 쉼표로 스플릿하여 첫 번째 요소 선택
first_part = srcset.split(',')[0]
# 공백으로 스플릿하여 첫 번째 요소 선택 (URL 추출)
img_url = first_part.split(' ')[0]
return img_url
else:
return None
except NoSuchElementException:
return None
finally:
wd.quit()
# CSV 파일 로드
df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/h&m/preprocessed/image_link.csv')
# 제품 이미지 링크를 저장할 리스트 초기화
image_link_list = []
# 각 URL에 대해 첫 번째 이미지 링크 추출
for url in df['html'][11:20]:
img_url = get_image(url)
if img_url:
image_link_list.append({'url': url, 'image_url': img_url})
else:
image_link_list.append({'url': url, 'image_url': 'No Image'})
# 결과를 데이터프레임으로 변환
result_df = pd.DataFrame(image_link_list)
# 제품 아이디와 이미지 주소만 결과로 저장
result = pd.merge(df, result_df, left_on = 'html', right_on = 'url', how = 'inner')
cols = ['article_id_str', 'image_url']
# 결과를 CSV 파일로 저장
result[cols].to_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/h&m/preprocessed/extracted_image_links.csv', index=False)
print("크롤링 및 데이터 저장 완료")
- 10개 테스트 (성공)


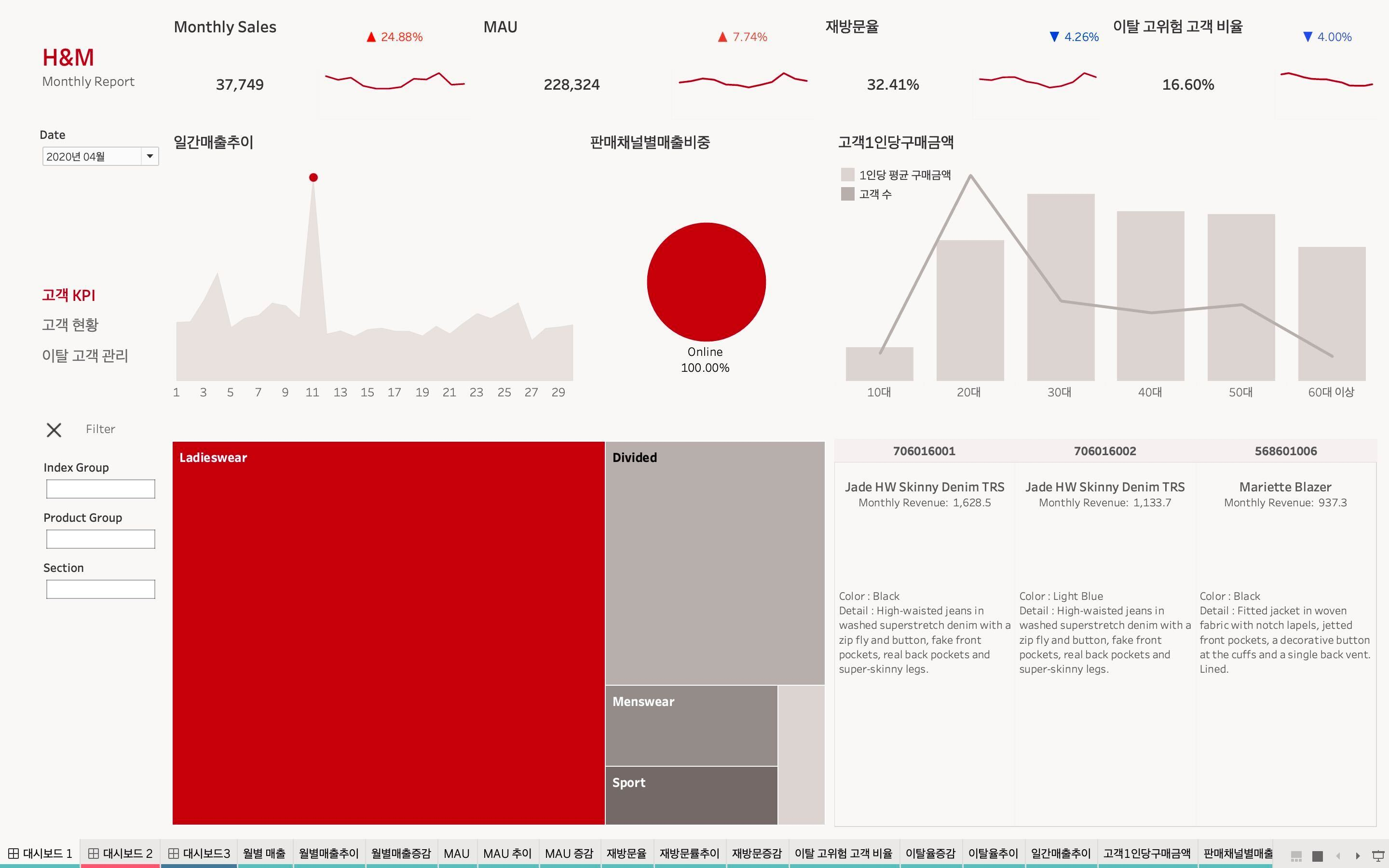
BI 대시보드 제작
- 매출 관련 대시보드
(우측 하단 매출 TOP3 상세 정보에 제품 이미지가 들어갈 예정
; 제품 이미지 링크를 크롤링한 이유)
- 고객 관련 대시보드
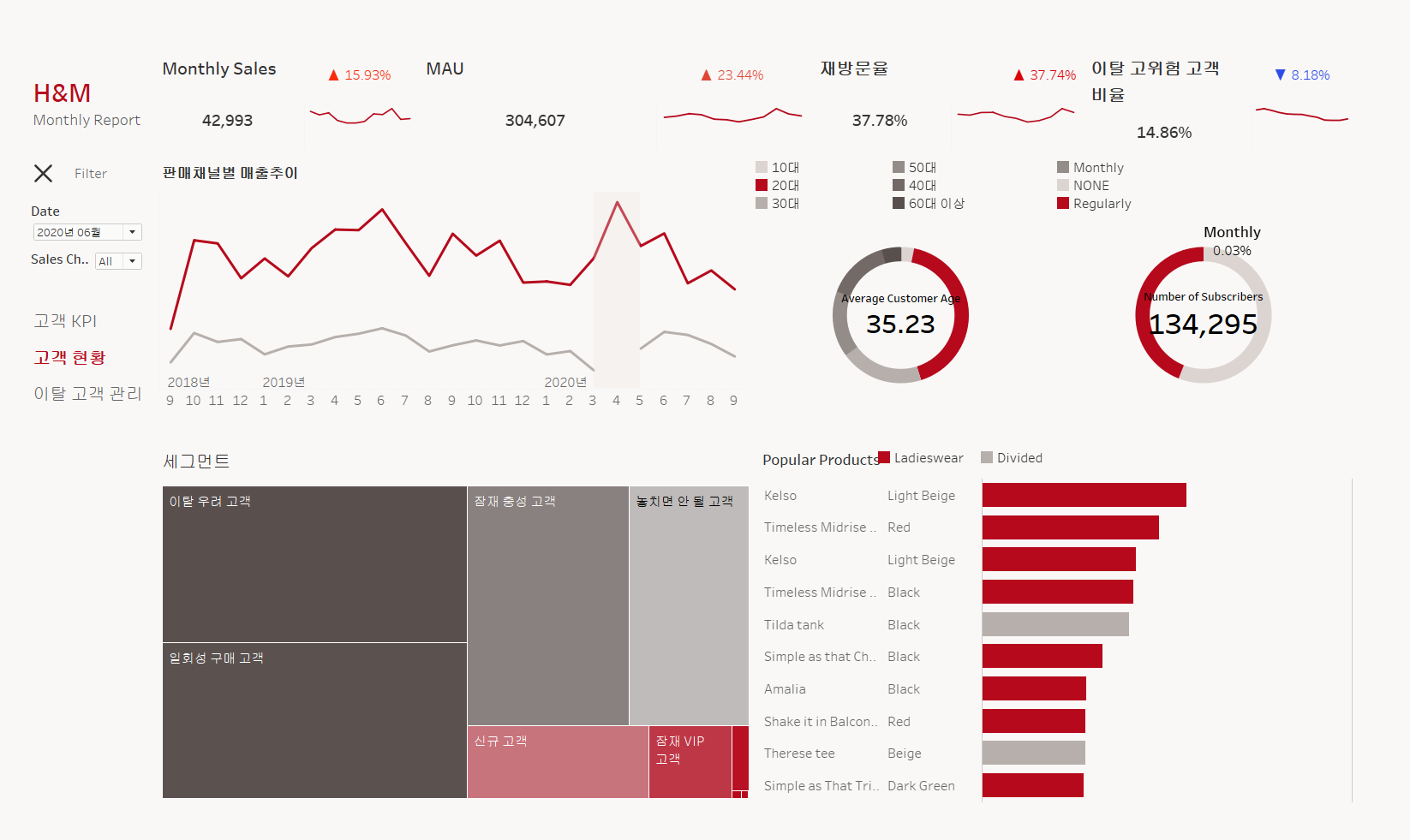
- 이탈 고객 관리 대시보드
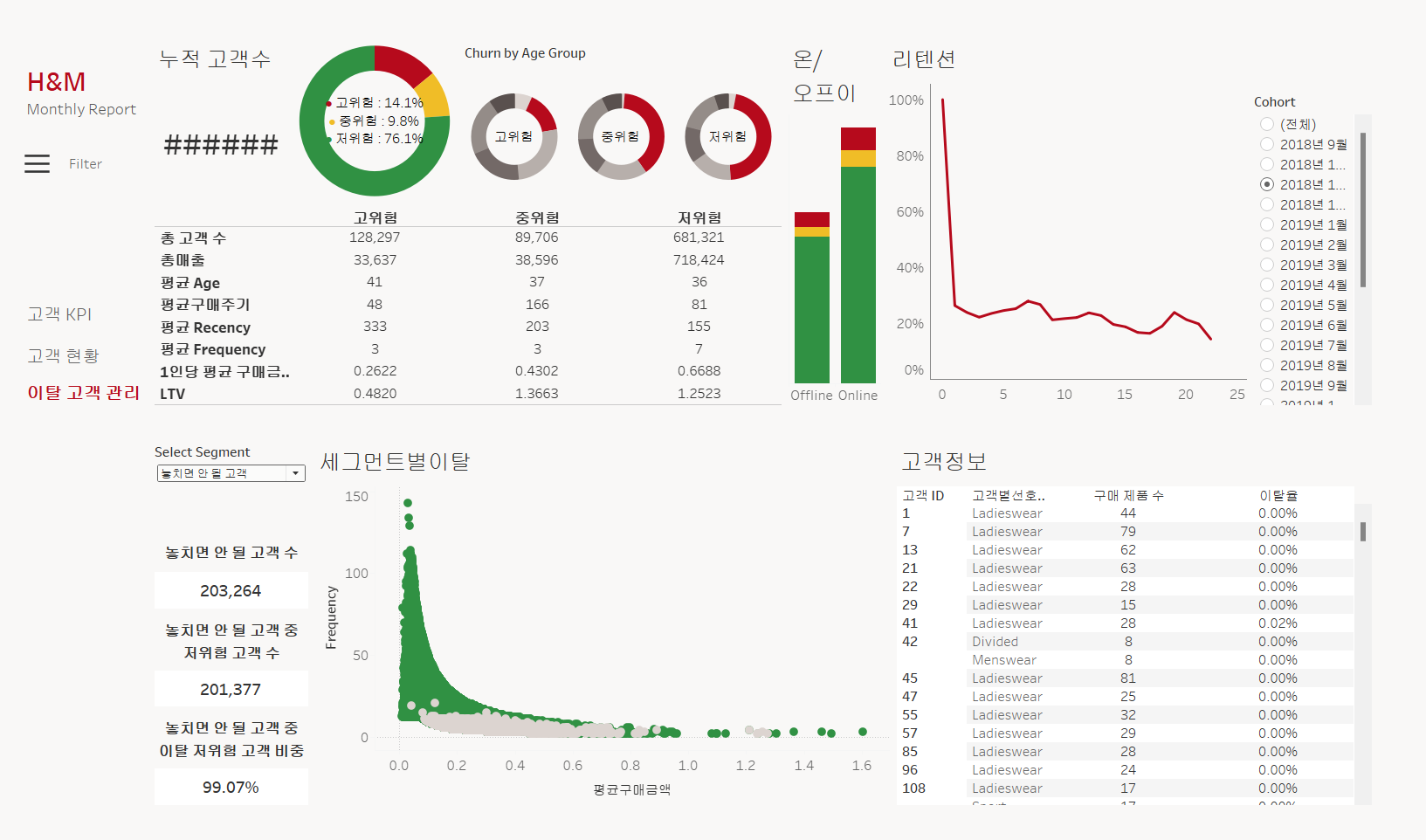
생각했던 주요 지표들의 구현은 완성되었고,
디테일적인 부분에서 어떻게 작동하게 하고,
어떤 것들을 보여줄 것인지에 대한 논의와 결정 후
최종 대시보드 완성이 될 것 같다.
#OUTRO
오늘의 한 줄.
광복절. 쉬어가야겠다.

커피 좋아하는 데이터 꿈나무