
WWW
WWW란?
- World Wide Web은 인터넷에 연결된 사용자들이 서로의 정보를 공유할 수 있는 공간으로, 정확히 말해 인터넷 상의 인기 있는 하나의 서비스이다.
- 웹 서버는 HTTP 프로토콜을 사용하며 클라이언트(웹 브라우저)는 TCP 포트 번호 80번을 이용해 서버와 연결을 시도한다.
Port
- 0 - 1023 : well -known port
- 특정 서비스, 프로토콜이 표준화된 포트 번호
- ex) 80 - HTTP, 443 - HTTPS
- 1024 - 49151 : registered port
- 특정 애플리케이션이나 서비스가 사용하기 위해 IANA(Internet Assigned Numbers Authority) 에 의해 등록된 포트를 말한다.
- ex ) 8080 - 웹 프록시 서버, 3306 - MySQL 데이터베이스
- 49152 - 65535 : dynamic port
- 클라이언트가 서버와 통신을 위해 임시로 할당하는 포트를 말한다.
클라이언트 - 서버 모델
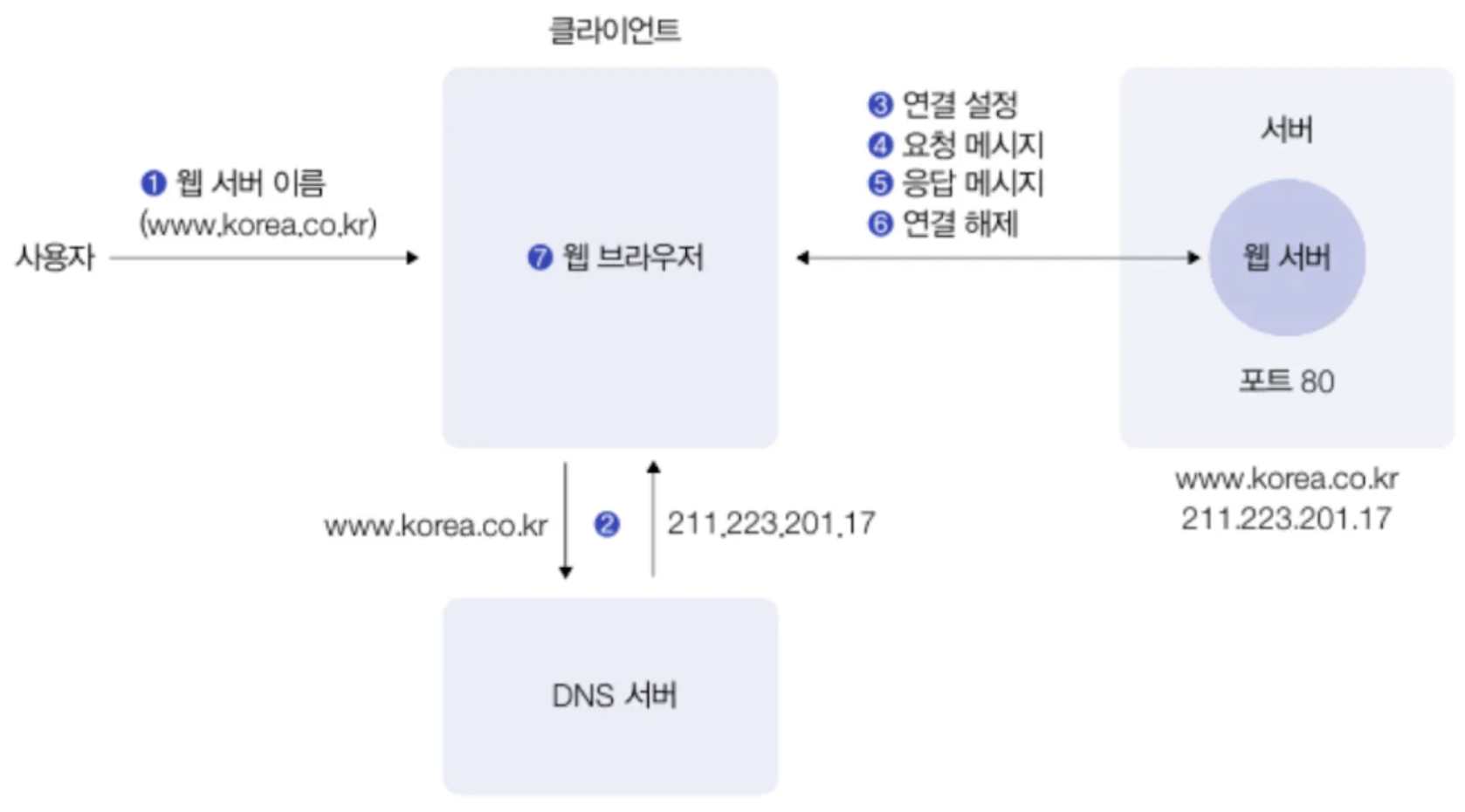
1. 사용자가 웹 브라우저에서 서버 이름을 입력한다. (GET)

2. DNS 서버를 통해 해당 도메인에 등록된 IP 주소를 응답받는다.
이 과정에서는 UDP 통신을 사용한다.
3. 서버는 들어온 요청에 대한 정적 파일을 클라이언트에게 응답한다. (POST)
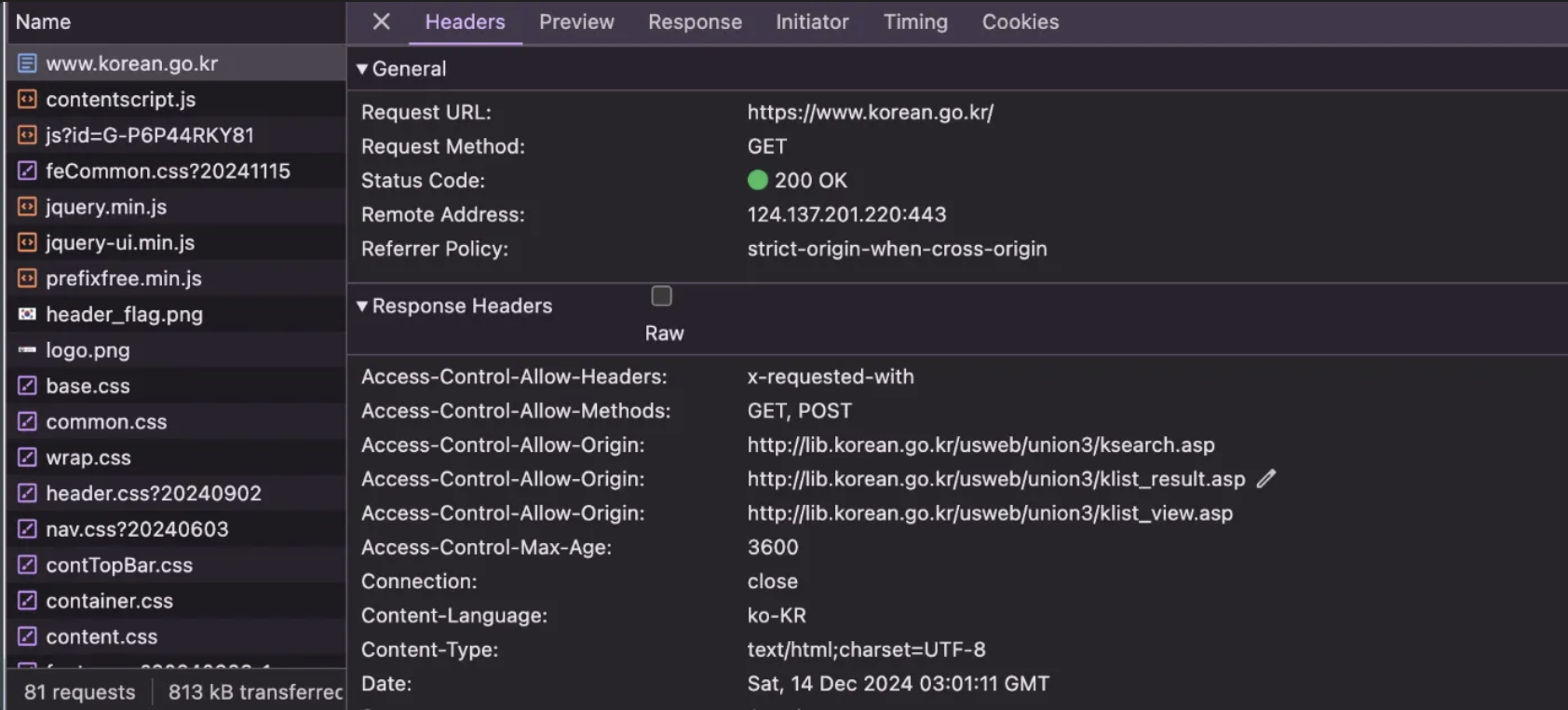
- Remote Address를 보면
www.korean.go.kr의 IP 주소가124.137.201.220인 것을 알 수 있다. 또한, port 번호를443을 사용하기 때문에 HTTPS 프로토콜이라는 것을 알 수 있다.
- Response Headers에
Content-Type을 보면text/html것을 확인할 수 있다.
실제로 응답된 html
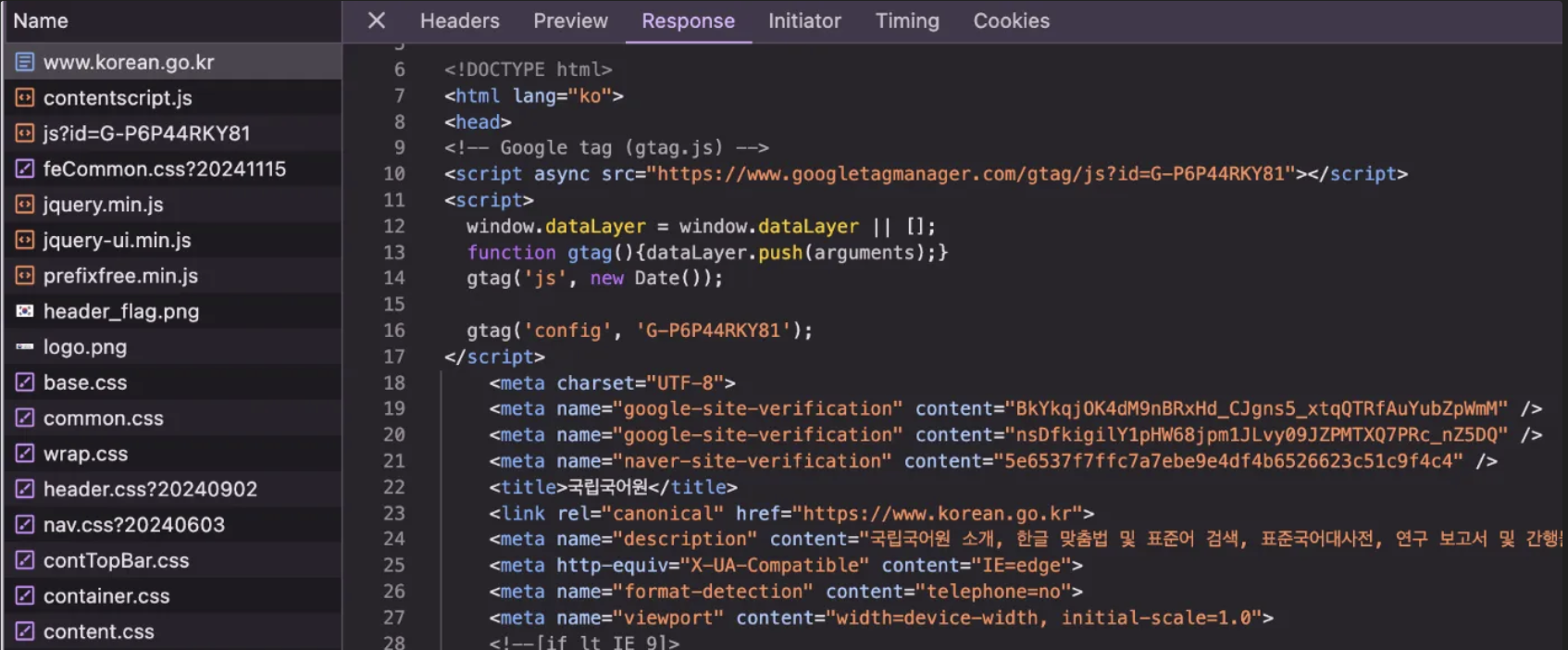
HTTP 프로토콜
HTTP란?
- HyperText Transfer Protocol으로 분산 하이퍼미디어 환경에서 빠르고 간편하게 데이터를 전송하는 프로토콜.
- 서버는 80번 포트에서 대기하고, 클라이언트는 TCP를 사용해 연결을 설정
State vs Stateless
| 구분 | 상태(State) | 비상태(Stateless) |
|---|---|---|
| 상태 유지 | 이전 상태를 저장하고 다음 요청에 반영 | 각 요청이 독립적이며 상태를 저장하지 않음 |
| 메모리 사용 | 세션, 상태 정보 저장을 위해 리소스 필요 | 상태를 저장하지 않아 리소스 소모가 적음 |
| 확장성 | 확장하기 어려움 | 확장성이 뛰어남 |
| 예시 | 로그인 세션, 장바구니 | HTTP, REST API |
Q. 상태가 있는 시스템이 확장이 어려운 이유?
- 서버간 세션 동기화
- A에서 저장된 세션 정보를 B서버에서도 사용할 수 있어야한다.
- 세션 데이터를 동기화하려면 네트워크 비용, 지연이 발생하며 서버 수가 늘어날 수록 동기화가 어려워지고 성능 저하가 발생한다.
Q. JWT 기반 인증 방식은 State일까 Stateless일까?
- Stateless이다. 표를 보면 다음과 같이 구분할 수 있다.
| 구분 | Stateful | Stateless |
|---|---|---|
| 저장 위치 | 서버 세션 저장소 | 클라이언트 쿠키에 저장 (JWT) |
| 확장성 | 확장성 낮음 (세션 동기화 필요) | 확장성 높음 |
| 상태 유지 | 서버에서 사용자 상태 유지 | 서버에서 사용자 상태 유지하지 않음 |
| 속도 및 성능 | 세션 조회로 인한 오버헤드 | 토큰 검증만으로 빠르게 처리 |
| 보안 | 세션 ID 유출 방지 필요 | 토큰 유출 시 보안 위험 (만료 설정 필수) |
- 즉, 서버 세션 저장소에 상태를 저장하는 state와 달리 JWT는 클라이언트에서 토큰 등으로 사용자 정보를 관리하는 stateless 방식이다. 그러므로 서버 세션 저장소를 동기화해야하는 state와 달리 JWT 인증 방식은 확장성이 높다. 대신, 토큰의 유출 시 보안 문제를 고려해 만료 설정 및 리프래시 토큰을 통해 보안을 고려해야한다.
요청 메세지와 응답 메세지
| 명령 | 설명 |
|---|---|
| GET | 클라이언트가 서버에 URL이 가리키는 웹 문서의 내용을 전송하도록 요청한다. 문서 내용은 서버가 회신하는 응답 메시지의 바디에 포함된다. |
| HEAD | 문서 내용보다는 특정 문서의 정보를 원할 때 사용한다. |
| POST | 클라이언트가 서버에 정보를 전송할 수 있도록 해준다. 보통 게시판, 방명록처럼 사용자가 입력한 정보를 서버에게 전달하는 용도로 사용한다. |
| PUT | 클라이언트가 서버에 문서를 전달하려고 사용한다. 문서 내용은 바디에 포함된다. |
| 추가로, DELETE 등의 요청 명령도 있다. |
멱등성이란?
- 동일한 작업을 여러 번 수행해도 그 결과가 처음 한번 수행 했을 때와 동일한 상태를 유지하는 성질
- GET, PUT, DELETE, HEAD
- 반면에 POST는 멱등성을 가지지 않는다.
GET 요청 후 응답 예시

DNS
IP 주소 클래스
네트워크 주소는 장치들을 그룹화하고, 호스트 주소는 해당 그룹 내에서 개별 장치를 식별한다.
| 클래스 | IP 주소 범위 | 네트워크 주소 | 호스트 주소 |
|---|---|---|---|
| A | 0 ~ 127 | www | xxx.yyy.zzz |
| B | 128 ~ 191 | www.xxx | yyy.zzz |
| C | 192 ~ 223 | www.xxx.yyy | zzz |
- A클래스가 가장 많은 호스트를 가질 수 있고 주로 대규모 네트워크(글로벌 기업 등)에 사용된다.
- C클래스는 가장 적은 호스트를 가질 수 있고 주로 소규모 네트워크(가정용 네트워크, 소규모 회사)에서 사용된다.
Q. 유니캐스팅 vs 멀티캐스팅
유니캐스팅은 1대1 통신 방식으로 단일 수신자를 대상으로 데이터 전송하기 때문에 특정 IP 주소를 기반으로 특정 host에게만 데이터를 전달한다.
멀티캐스팅은 1대다 통신 방식으로 특정 그룹에 속한 수신자에게 동시에 데이터를 전송한다. 그래서 전부 네트워크 주소로 이루어진 D클래스가 해당 통신방식을 지원한다.
추가
A,B,C 클래스는 단일 호스트 통신에 최적화 되어있는 경우로, 네트워크와 호스트를 명확하게 구분하기 때문에 멀티캐스팅을 지원하기에는 부적합하다.
DNS가 필요한 이유?
IP주소의 문자 표현
- IPv4에서 32bit의 주소를 8비트 씩 10진수로 바꿔 표현한다. 하지만 이러한 주소 표현도 사용자 입장에서 특정 호스트 서버에 접근하는데 어려움이 있기 때문에 문자로 된 호스트 이름을 추가로 정의했다.
초기 DNS 관리 방법
- 문자로된 호스트 이름을 추가로 정의했기 때문에 특정 IP와 매칭시킨 정보가 필요.
- 컴퓨터 시스템이 전체 호스트의 명칭 정보를 관리했지만 호스트가 증가하면서 모든 호스트의 정보를 유지하기가 불가능해졌다.
- 이로 인해, DNS 서비스가 등장했다.
DNS 서비스의 동작과정
DNS 서비스란?
- 도메인 이름에서 IP주소를 얻을 수 있는 분산 데이터베이스 시스템.
- 해석기는 UDP를 이용해 자신이 위치한 지역의 DNS 네임 서버에 변환을 요청하여 IP주소를 얻을 수 있다.
DNS 서비스의 계층 구조 - 네임스페이스
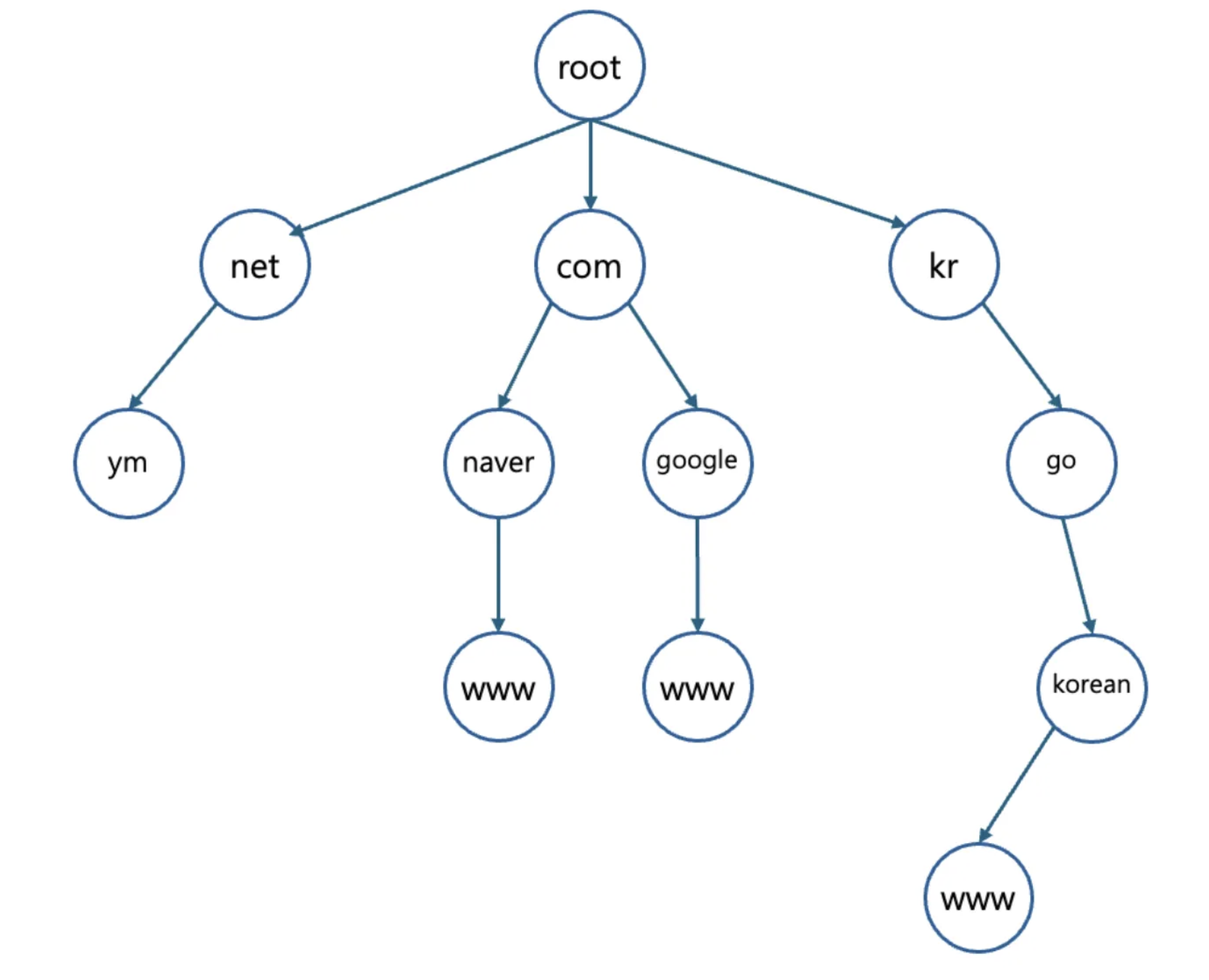
- 도메인 이름을 체계적으로 관리하고 구분하는 계층적 구조를 말한다.
- 최상위에 이름이 없는 Root가 존재하고, Root 바로 밑에 위치한 호스트인 TLD(Top Level Domain) 이 있다.
- 보통, TLD는 com, net 처럼 기구의 이름이나 kr, us와 같이 일반 도메인과 별도로 국가 코드를 정의한다.
Spring boot에서 엿보는 DNS
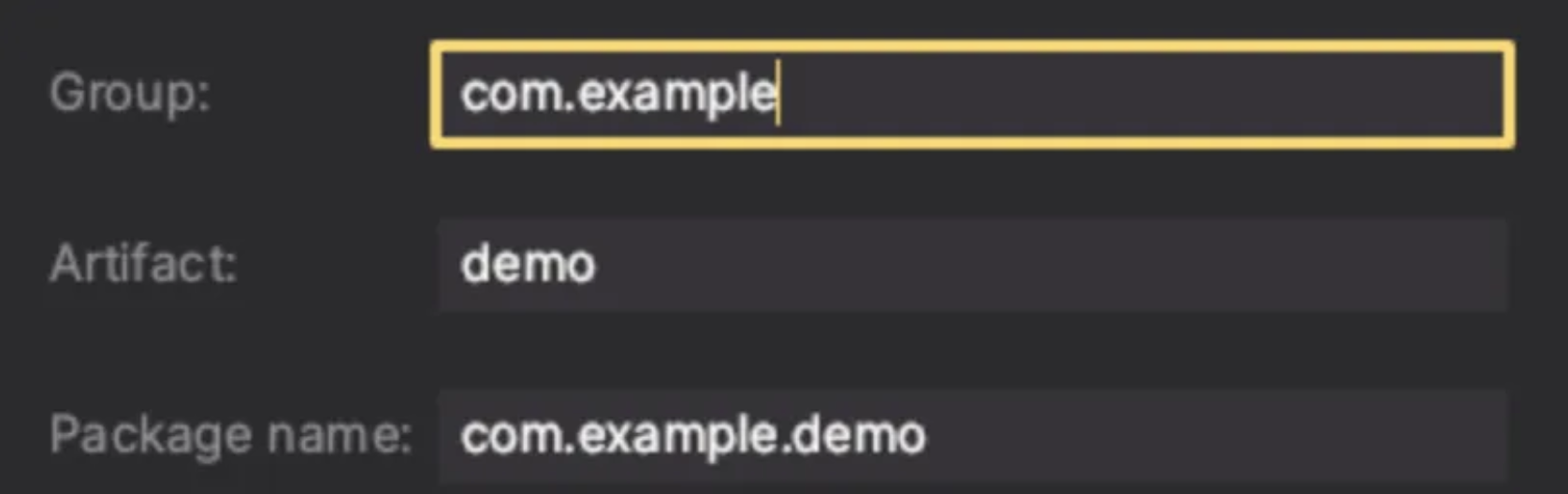
Spring boot 프로젝트를 생성 시, 볼 수 있는 인터페이스인데 이와 같이 Group, Package name으로 네임스페이스와 같은 계층 구조로 프로젝트를 생성하는 것을 알 수 있다.
동작과정
동작과정을 설명하기 전에 네임 서버와 DNS 서비스가 분산된 데이터베이스 시스템이라는 것을 알고 있어야한다.
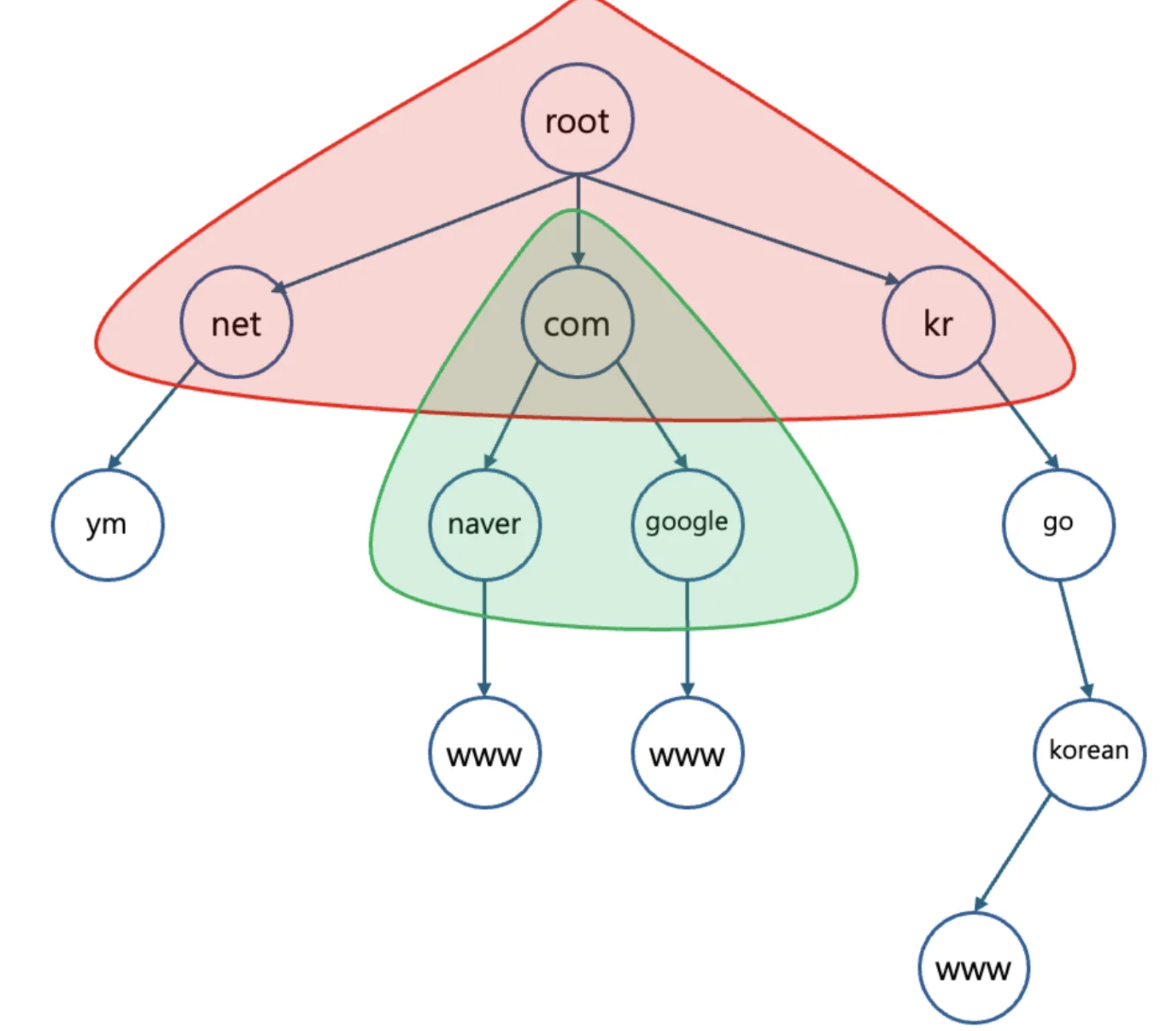
네임 서버와 존
위 사진과 같이 네임 서버 즉, 실제 도메인 이름과 IP 주소 간의 매핑 정보를 제공하는 곳은 존에 따라 분류된다.
네임 서버의 종류
- 루트 네임 서버
- 도메인 네임스페이스의 최상위 레벨을 관리한다.
- ex)
.com,.org,.net과 같은 TLD에 대한 정보를 제공한다.
- TLD 네임 서버
- 각 최상위 도메인(TLD)에 대한 정보를 관리한다.
- ex)
.com에 속한 모든 도메인의 정보를 관리한다.
- 권한 네임 서버
- 특정 도메인에 대한 최종 정보를 제공한다.
- ex)
example.com의 IP 주소에 대한 정확한 매핑 정보를 제공한다.
- 캐시 네임 서버
- 자주 요청된 DNS 정보를 캐싱하여 저장하고, 빠르게 응답한다.
- ex) 사용자가 이전에 방문한 사이트의 DNS 정보를 임시로 저장한다.
동작과정 1. (비)재귀적 처리
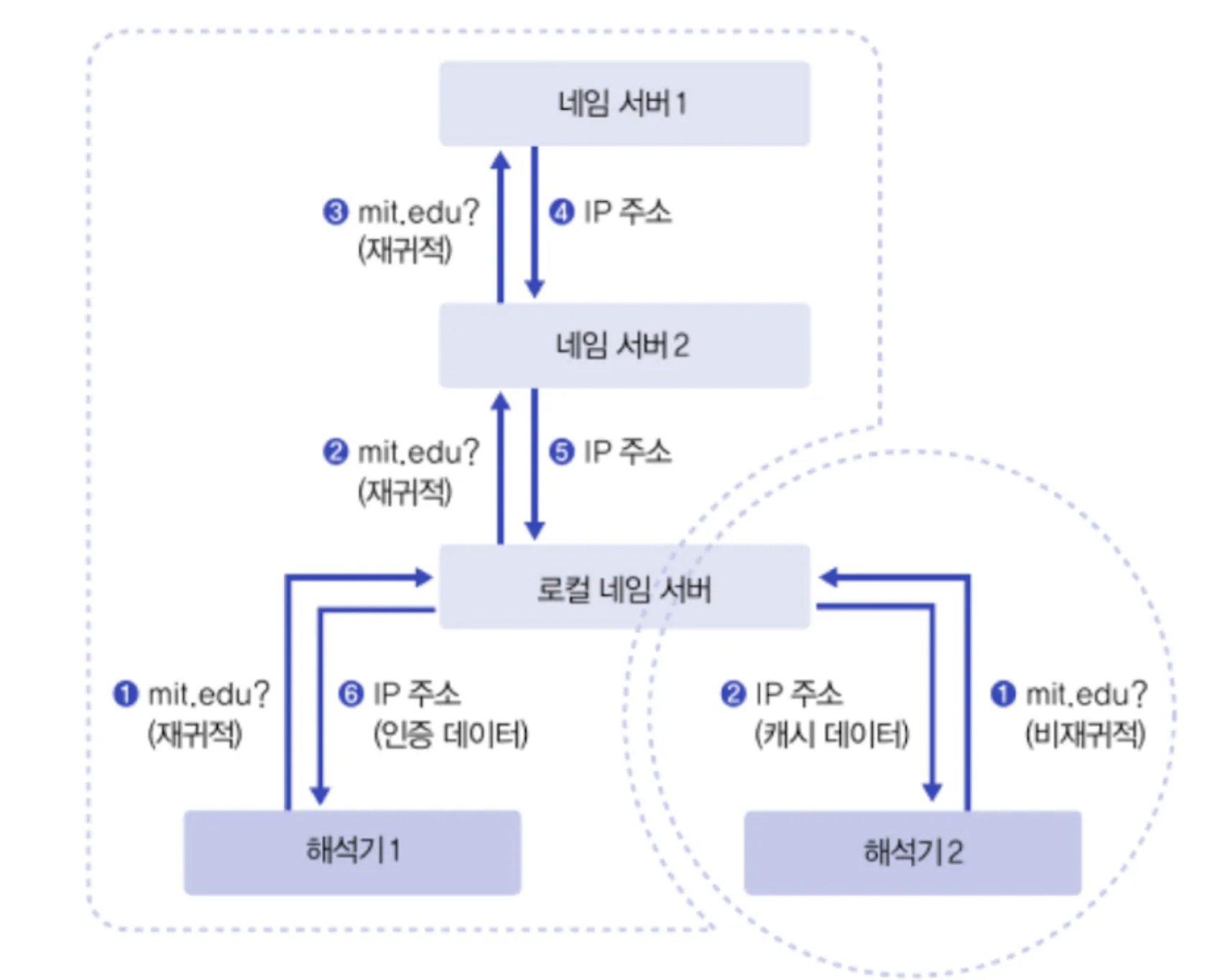
- 해석기에서 가장 가까운 네임 서버(로컬 네임 서버)와 접촉해 IP 주소를 요청하고 다른 네임서버에 요청을 재귀적으로 수행하면서 IP주소를 응답받는다.
- 해석기 : 도메인 이름과 호스트 주소의 변환 정보를 원하는 네트워크 응용 프로그램
- 로컬 네임 서버가 보관하고 있는 캐시 정보를 회신함으로써 재귀적인 호출 없이 IP주소를 응답받을 수 있다.
- 만약에 내가
www.naver.com의 대한 IP주소를 원한다면 com을 관리하는 네임서버(존으로 분류)에 요청을 하고 해당 존은 naver를 관리하는 네임 서버에 요청을 반복하면서 최종적으로www.naver.com의 IP주소를 응답 받을 수 있는 것이다.
동작과정 2. 반복적 처리
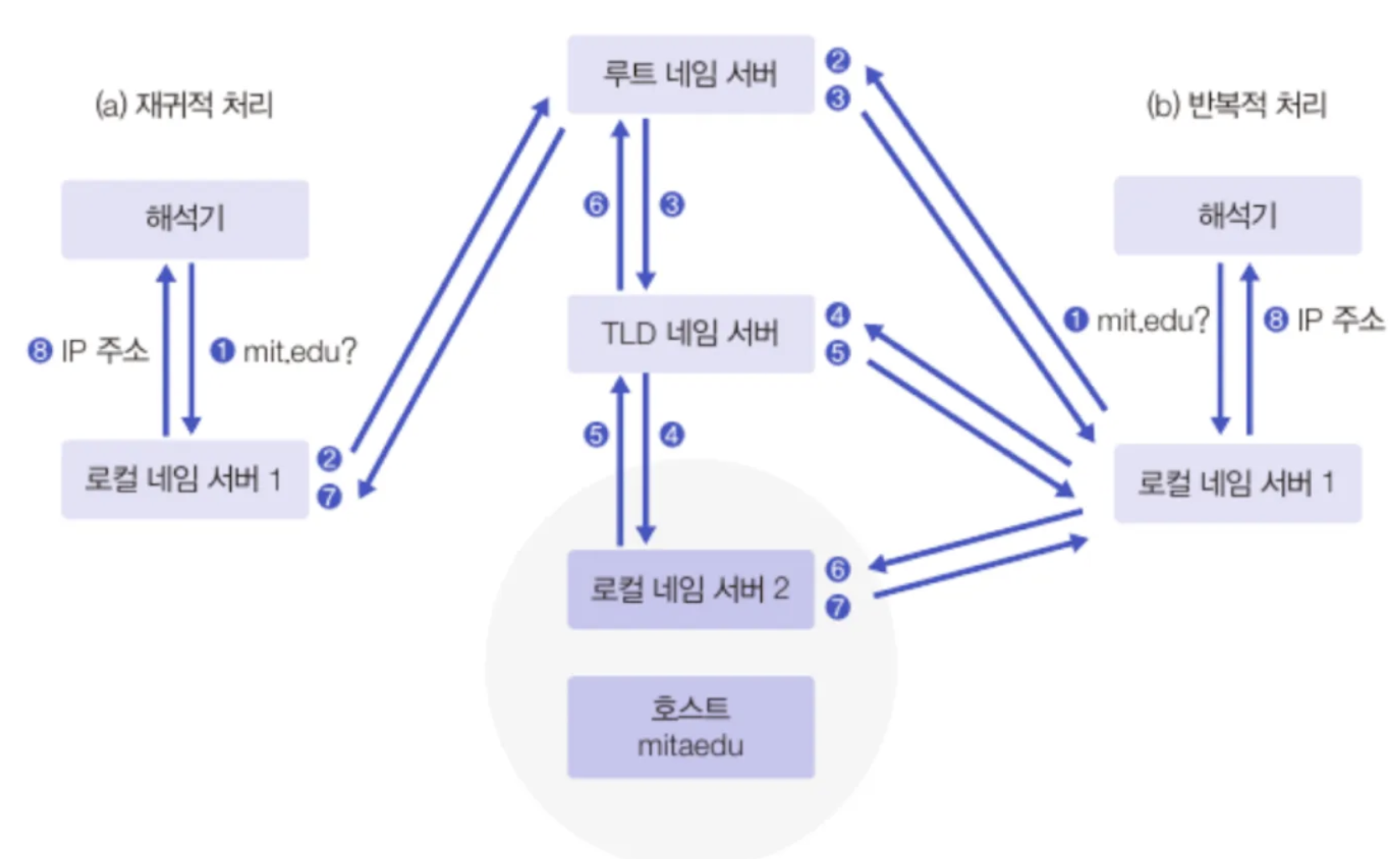
재귀적인 처리 방법과는 다르게 로컬 네임 서버가 반복적으로 직접 여러 네임서버에 접촉해서 부족한 정보를 모두 채워나가 IP주소를 응답하는 방식이다.
Q. 서버가 도메인 주소로 IP주소를 얻는 과정에 대해서 설명하시오.
DNS 서비스를 이용해 IP 주소를 얻을 수 있다. 클라이언트가 웹 브라우저에서 도메인 주소로 요청을 보내면 DNS 서버에 해석기가 요청을 보내 재귀적 처리 혹은 반복적 처리를 통해 IP 주소를 응답 받을 수 있다.
추가
일반적으로 재귀적 처리는 웹사이트 접근 시 사용된다.
- 클라이언트가 단순히 요청만 하기 때문에 간편하다
- DNS 해석기가 주간 결과를 캐시해서 재사용이 가능하다.
반면에 반복적 처리는 네트워크 디버깅, DNS 테스트에서 사용된다.
- 각 네임 서버가 자신의 역할만 수행하기 때문에 특정 서버에 과도한 부하가 걸리지 않는다.
Q. 그럼 재귀적 호출은 각 네임 서버가 자신의 역할만 수행하는게 아닌건가??
=> 재귀적 호출은 최종 IP주소를 찾을 때까지 모든 과정을 처리하는데, 자신이 요청받은 도메인의 IP주소를 모를 경우 자신 영역 외의 요청도 처리하며, 답을 찾아 클라이언트에게 전달하기 때문이다.
출처: 캡쳐된 사진을 출처는 "쉽게 배우는 데이터 통신과 컴퓨터 네트워크 - 박기현"에서 인용한 자료입니다.
