
이 글은 'HTTP 완벽 가이드' 책을 읽고 정리한 내용입니다.
- HTTP는 어떻게 TCP 커넥션을 사용하는가
- TCP 커넥션의 지연, 병목, 막힘
- 병렬 커넥션, keep-alive 커넥션, 커넥션 파이프라인을 활용한 HTTP의 최적화
- 커넥션 관리를 위해 따라야 할 규칙들
4.1 TCP 커넥션
TCP/IP
TCP(Transmission Control Protocol) - 전송 제어 프로토콜로 한 기기에서 다른 기기로 데이터 전송을 담당
IP(Internet Protocol) - 인터넷 프로토콜로 데이터의 조각(fragment)을 대상 IP주소로 보내는 역할
TCP
- 커넥션을 맺을 수 있다.
- 케넥션이 맺어지면 클라이언트 <-> 서버 컴퓨터 간에 데이터 손실없이 안전하게 전달된다.
UDP
- User Datagram Protocol
- 커넥션을 맺을 수 없다.
- TCP에 비해 안전성은 떨어지지만 더 빠르고 간단하다. (스트리밍, 게임과 같은 곳에서 사용)
URL입력시 동작 과정
- 브라우저가 (특정 URL)의 호스트 명을 추출한다.
- 브라우저가 호스트 명에 대한 IP주소를 찾는다.
- 브라우저가 포트 번호(80)를 얻는다.
- 브라우저는 IP주소의 80번 포트로 TCP 커넥션 을 생성한다.
- 이후 클라이언트 <-> 서버의 요청 응답
- 브라우저가 커넥션을 끊는다.
4.1.1 신뢰 할 수 있는 데이터 전송 통로인 TCP
- TCP 커넥션은 인터넷을 안정적으로 연결해준다. (신뢰할 만한 통신 방식 제공)
- 바이트들이 순서에 맞게 정확히 전달된다. (데이터의 손실, 손상 등이 없기 때문에)
4.1.2 TCP 스트림은 세그먼트로 나뉘어 IP 패킷을 통해 전송된다.
HTTPS (Hypertext Transfer Protocol Secure)
- 기존 http protocol 의 보안 기능을 더한 것
- TLS or SSL 이라고 불리는 암호화 계층이 추가
HTTP 메세지 전송
- TCP 커넥션을 통해 데이터의 내용을 순서대로 전송
- 세그먼트라는 단위로 데이터 스트림을 나눈 후에 IP 패킷에 담아 전송
- IP 패킷
- IP 패킷 헤더 (20 ~ 60byte) - 20byte 초과 시 option 필드가 존재한다. (in IPv4)
- TCP 세그먼트 헤더 (20byte)
- TCP 데이터 조각(0 ~ 그 이상의 byte)
4.1.3 TCP 커넥션 유지하기
- 컴퓨터 여러 개의 TCP 커넥션을 가지고 있다.
- 포트 번호를 통해서 여러 커넥션을 유지
- TCP 커넥션 식별
- < src ip addr, src port, des ip addr, des port>
- 이 값들이 모두 같은 경우는 존재할 수 없다.
4.1.4 TCP 소켓 프로그래밍
- 운영체제는 TCP 커넥션의 생성과 관련된 여러 기능 제공
클라이언트와 서버가 TCP 소켓 인터페이스를 사용하여 상호작용
- S 소켓 생성 후 80포트로 소켓을 묶는다. 이후 커넥션 허가 및 커넥션을 기다린다(클라이언트로부터)
- C IP addr, port를 얻고 소켓을 생성 후 서버의 IP:port 로 연결
- S <-> C 연결 이후 요청과 응답 과정을 수행
- 더 이상의 요청이 없을 때, 커넥션을 종료
4.2 TCP의 성능에 대한 고려
- HTTP는 TCP의 상위 계층이기 때문에 HTTP 트랜잭션의 성능은 TCP 성능에 영향을 받는다
4.2.1 HTTP 트랜잭션 지연
- 트랜잭션을 처리하시는 시간 < TCP 커넥션 설정 시간, 요청 전송 및 응답 시간
- 대부분의 HTTP 지연은 TCP 네트워크 지연 때문에 발생
1. URL 호스트 명을 IP주소로 변환하는 과정 (초기 방문시)
2. 클라이언트의 TCP 커넥션 요청 ( 보통 1~2초지만 요청이 많으면 소요 시간 크게 증가)
3. 서버가 요청 메세지를 읽고 처리하는 시간
4. 요청 처리 후 HTTP 응답을 보내는 시간 - 이러한 TCP 네트워크 지연은 다음과 같은 요인이 있다.
- HW 성능
- 네트워크와 서버의 전송 속도
- 요청과 응답 메세지의 크기
- 클라이언트와 서버 간의 거리
- 대부분의 HTTP 지연은 TCP 네트워크 지연 때문에 발생
4.2.2 성능 관련 중요 요소 ( 가장 일반적인 TCP 관련 지연들 )
4.2.3 TCP 커넥션 핸드셰이크 지연
TCP 커넥션 핸드셰이크
- TCP 커넥션을 맺기 위해 연속적으로 IP패킷을 교환하는 과정
- 하지만, 작은 크기의 데이터 전송에 이러한 커넥션 연결과정은 HTTP 성능을 저하시킬 수 있다.
- 핸드셰이크 과정
1. 클라이언트가 SYN 라는 플래그를 가지는 TCP 패킷(40~60byte)을 서버에게 보낸다.
2. 서버는 몇가지 커넥션 매개변수 산출 후, 요청이 받아졌다는 SYN + ACK 플래그를 가진 TCP 패킷을 보낸다.
3. 마지막으로, 클라이언트는 커넥션이 잘 맺어졌음을 알리는 응답신호를 보낸다.( 이때 같이 데이터를 보낼 수 있다.) - 크기가 작은 HTTP 트랜잭션은 50%이상의 시간을 위와 같은 TCP 커넥션을 구성하는데 사용된다.
4.2.4 확인응답 지연
- 인터넷 자체가 패킷 전송을 완벽히 보장하지 않는다.
- 혼잡 상태거나 TTL이 0이 되는 패킷들은 라우터에서 폐기한다.
성공적인 데이터 전송을 보장하기 위한 TCP의 자체적 확인 체계
- 각 TCP 세그먼트는 순번, 데이터 무결성 체크섬을 가진다.
- 전송 성공 시(각 세그먼트를 온전히 받음), src 쪽에 확인 응답 패킷 전송
- 전송 실패 시(확인 응답 패킷 X), 다시 재전송
- 확인 응답
- 편승 - 크기가 작기 때문에 같은 방향(즉, 수신자가 송신자에게 보낼 때)으로 송출되는 데이터에 같이 실어서 보낸다
- 편승되는 경우의 수를 늘리기 위해 확인응답 지연 알고리즘을 구현
1. 송출할 확인응답을 특정 시간동안 버퍼에 저장
2. 편승시키기 위한 데이터 패킷 탐색
3. 일정 시간 내 찾지 못하면 별도의 패킷으로 전송 - 실제로 편승시킬 수 있는 경우가 적기 때문에 지연 알고리즘으로 인한 지연이 자주 발생
- 요청과 응답 두가지 형식으로만 이루어져 있기 때문에
- 편승되는 경우의 수를 늘리기 위해 확인응답 지연 알고리즘을 구현
4.2.5 TCP 느린 시작(slow start)
인터넷의 혼잡 제어 방법
- TCP 커넥션은 만들어진 지 얼마나 지났는지에 따라 달라질 수 있다.
- 시간이 지나면서 자체적으로 튜닝 된다.
- 속도 제한
- 처음에는 커넥션의 최대 속도 제한, 이후 성공적으로 전송 시 속도 제한을 높여나간다.
- 패킷 수 제한
- 패킷이 성공적으로 전달 시, 추가로 2개의 패킷을 더 전송할 수 있는 권한이 생긴다.
- 속도 제한
[정리]
처음부터 많은 데이터, 빠른 속도로 보낼 시 혼잡이 발생할 수 있기 때문에
천천히, 작은 데이터를 보내보면서 속도와 크기를 늘려나가는 방식의 혼잡 제어
4.2.6 네이글 알고리즘과 TCP_NODELAY
- 애플리케이션이 어떤 크기의 데이터든지 TCP 스택으로 전송할 수 있도록 인터페이스를 제공
- TCP 세그먼트는 40byte 상당의 플래그와 헤더를 포함
- 작은 데이터 패킷을 많이 보내면 위와 같은 헤더 또한 같은 수로 증가하기 때문에 네트워크 성능 저하
많은 양의 TCP 데이터를 합치는 알고리즘 ??
- 네이글 알고리즘은 세그먼트가 최대 크기 (1500byte 정도)가 되지 않으면 전송 X
- 다른 모든 패킷이 확인응답 받았을 경우, 최대 크기보다 작은 패킷 전송 허락
- 다른 패킷들이 아직 전송 중, 데이터는 버퍼에 저장된다.
- 전송되고 나서 확인응답을 기다리던 패킷이 확인응답 혹은 충분한 패킷이 쌓였을 때 버퍼에 저장된 데이터가 전송된다.
- TCP가 데이터를 전송할 때, 첫 번째 패킷이 네트워크를 통해 전송되고 그에 대한 확인 응답(ACK)을 기다립니다.
- 첫 번째 패킷에 대한 ACK가 도착하기 전에는, 작은 크기의 메시지들을 큐에 저장하고, 이 메시지들을 누적시켜 하나의 큰 패킷으로 만듭니다.
- 첫 번째 패킷에 대한 ACK가 도착하면, 큐에 누적된 메시지들을 하나의 큰 패킷으로 전송합니다.
문제점
- 크기가 작은 HTTP 메세지는 추가적인 데이터를 기다리며 지연
- 확인응답 지연과 함께 쓰일 경우 형편없이 동작
- 확인응답이 도착할때까지 데이터 전송을 멈추고 있는 반면, 확인응답 지연 알고리즘은 확인응답을 100~200ms 지연시킨다.
- 그래서 성능 향상을 위해 TCP_NODELAY를 설정해 네이글 알고리즘을 비활성화 하기도 한다.
- 이럴 경우 작은 크기의 패킷이 많이 생기는 것을 방지하기 위해 큰 크기의 데이터 덩어리를 만들어야함.
4.2.7 TIME_WAIT의 누적과 포트 고갈
- TCP 커넥션을 끊으면 종단에서는 커넥션의 IP 주소와 포트 번호를 메모리의 작은 제어영역에 기록
- 이는 새로운 커넥션이 일정시간동안 생성되지 않기 위한 목적
- 세그먼트 최대 생명주기의 두배(약 2분)가 유지된다.
- 서버의 성능에 따라 포트 고갈이 일어날 수도 있다.
- 트랜잭션을 빠르게 처리하면 일어날 가능성이 높다.
- 커넥션을 너무 많이 맺거나 대기 상태로 있는 제어 블록이 많아지는 상황을 주의해야한다.
4.3 HTTP 커넥션 관리
- 커넥션을 생성하고 최적화하는 HTTP 기술
4.3.1 흔히 잘못 이해하는 Connection 헤더 ??
- HTTP는 클라이언트와 서버 사이 중개 서버(프락시, 캐시)가 놓으는 것을 허락한다.
- HTTP 메세지는 이 중개 서버를 거치면서 전달된다.
- Connection 헤더 필드는 커넥션 토큰을 쉼표로 구분하여 가지고 있는다.
- 세 종류의 토큰이 전달 될 수 있다.
- HTTP 헤더 필드 명은, 이 커넥션에만 해당되는 헤더들을 나열
- 임시적인 토큰 값은, 커넥션에 대한 비표준 옵션을 의미
- close 값은, 커넥션이 작업이 완료되면 종료되어야함을 의미
- 커넥션 토큰이 HTTP 헤더 필드 명을 가지고 있으면, 현재 커넥션만을 위한 정보이므로 다음 커넥션에 전달되면 안된다.
4.3.2 순차적인 트랜잭션 처리에 의한 지연
- 3개의 이미지가 있는 웹페이지. 이 페이지를 보여주기 위해서
- 4개의 HTTP 트랜잭션을 만든다.
- 커넥션 발생 지연 + 느린 시작 지연 발생
- 여러 개의 이미지 동시 로드
- 모든 객체를 내려받기 전까지 텅 빈 화면을 보여줘야 한다.
- 4개의 HTTP 트랜잭션을 만든다.
HTTP 커넥션의 성능을 향싱 시킬 수 있는 기술
- 병렬 커넥션
- 여러 개의 TCP 커넥션을 통한 동시 HTTP 요청
- 지속 커넥션
- 커넥션을 맺고 끊는 데서 발생하는 지연 제거를 위한 케녁션 재활용
- 파이프라인 커넥션
- 공유 TCP 커넥션을 통한 병렬 HTTP dycjd
- 다중 커넥션
- 요청과 응답들에 대한 중재( 실험적인 기술 )
4.4 병렬 커넥션
- HTTP는 클라이언트가 여러 개의 커넥션을 맺음으로써 여러 개의 HTTP 트랜잭션을 병렬로 처리할 수 있게 한다.
4.4.1 병렬 커넥션은 페이지를 더 빠르게 내려받는다
- 단일 커넥션의 대역폭 제한, 커넥션이 동작하지 않고 있는 시간을 활용하면 => 객체가 여러 개 있는 웹페이지를 더 빠르게 내려받을 수 있다.
- 즉, 단일 커넥션의 대역폭을 쪼개서 사용하는 것 -> 한번의 핸드셰이크만 필요한가? No
4.4.2 병렬 커넥션이 항상 더 빠르지는 않다
- 일반적으로 더 빠르지만 항상 그렇지는 않다.
- 대역폭이 좁을 때 여러개의 객체를 병렬로 내려받는 경우, 제한된 대역폭 내에서 전송받는 것은 느리기 때문에 성능상에 장점은 거의 없다.
- 다수의 커넥션은 메모리를 많이 소모, 자체적인 성능 문제 발생
- 실제로는 4개 정도의 벙렬 커넥션만을 허용
4.4.3 병렬 커넥션은 더 빠르게 '느껴질 수' 있다.
- 항상 빠르게 로드하지는 않는다.
- 하지만 여러 개의 객체가 동시에 보여지면서 더 빠르게 느낄 수 있다.
4.5 지속 커넥션
- 요청에 대한 처리가 완료된 후에도 계속 연결된 상태로 있는 TCP 커넥션
- 커넥션을 끊기 전까지는 트랜잭션 간에도 커넥션을 유지한다.
- TCP의 느린시작으로 인한 지연을 피함으로써 더 빠르게 데이터 전송이 가능
4.5.1 지속 커넥션 vs 병렬 커넥션
병렬 커넥션
장점
- 여러 객체가 있는 페이지를 더 빠르게 전송한다.
단점
- 각 트랜잭션마다 새로운 커넥션을 맺고 끊기 때문에 시간, 대역폭이 소요
- 각 새로운 커넥션은 TCP 느린 시작으로 인한 지연 발생
- 실제로 연결 가능한 병렬 커넥션 수의 제한
지속 커넥션
장점
- 커넥션을 맺기 위한 사전 작업, 지연을 줄여준다.
- 튜닝된 커넥션을 유지하며 커넥션의 수를 줄여준다.
단점
- 지속 커넥션을 잘못 관리할 경우, 계속 연결된 상태로 수많은 커넥션이 쌓인다.
- 이는 로컬의 리소스, 원격의 클라이언트와 서버의 리소스에 불필요한 소모를 발생한다.
[결론]
지속 커넥션은 병렬 커넥션과 함께 사용될 때 가장 효과적이다!
HTTP/1.0+ : keep-alive 커넥션
HTTP/1.1 : 지속 커넥션
4.5.2 HTTP/1.0+의 Keep-Alive 커넥션
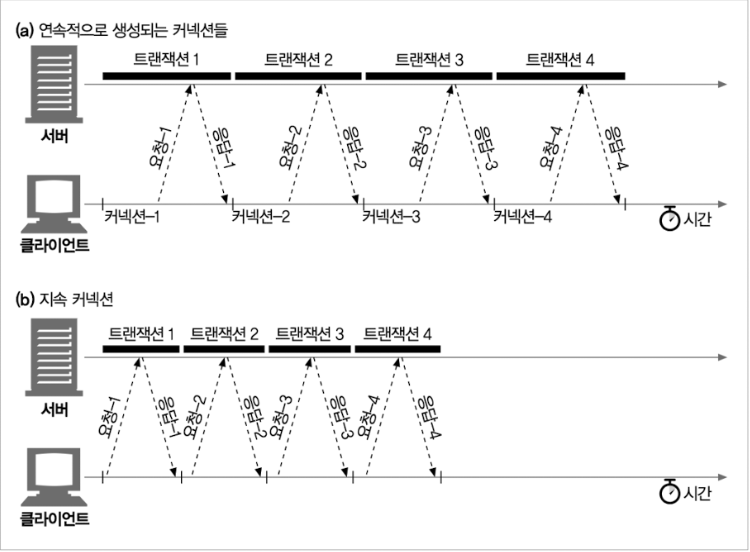
새로운 커넥션을 맺고 끊는 데 필요한 작업이 없어서 시간이 단축
4.5.3 Keep-Alive 동작
- 클라이언트는 요청에 Connection:Keep-Alive 헤더를 포함 시킨다.
- 요청을 받은 서버는 두가지 경우가 존재
- Keep-Alive 지원
- 응답 메세지에 같은 헤더를 포함 시켜 응답
- Keep-Alive 미지원
- 헤더를 포함시키지 않고 응답 -> 응답 전송 후 서버 커넥션을 끊을 것이라 추정
- Keep-Alive 지원
4.5.4 Keep-Alive 옵션
- 언제든지 현재의 Keep-Alive 커넥션을 끊을 수 있으며 처리되는 트랜잭션의 수를 제한할 수 있다.
- Keep-Alive의 동작은 Keep-Alive 헤더의 쉼표로 구분된 옵션들로 제어
- timeout
- Keep-Alive 응답 헤더를 통해 보낸다.
- 커넥션이 얼마나 유지될 것인지를 의미( 실제로 이대로 동작한다는 보장은 없다.)
- max
- Keep-Alive 응답 헤더를 통해 보낸다.
- 몇 개의 HTTP 트랜잭션을 처리할 때까지 유지 될 것인지를 의미( 실제로 이대로 동작한다는 보장은 없다.)
- timeout
- Keep-Alive 헤더 사용은 선택 사항이지만 Conncetion: Keep-Alive 헤더가 있을 때만 사용할 수 있다.
- Keep-Alive의 동작은 Keep-Alive 헤더의 쉼표로 구분된 옵션들로 제어
Connection: Keep-Alive
Keep-Alive: max:5, timeout:120=> 5개의 추가 트랜잭션이 처리될 동안 or 2분동안 커넥션 유지하라는 응답 헤더
4.5.5 Keep-Alive 커넥션 제한과 규칙
- keep-alive는 HTTP/1.0에서 기본으로 사용되지 않는다. 클라이언트는 Connection: Keep-Alive 요청 헤더를 보내야 한다.
- 커넥션을 유지하려면 모든 메세지에 Connection: Keep-Alive 헤더를 포함해야한다. 미 포함시 서버가 커넥션을 끊을 것이다.
- 클라이언트는 서버의 Connection: Keep-Alive 응답 헤더가 없는 것을 보고 커넥션을 끊을 것을 알 수있다.
- 커넥션이 끊어지기 전 엔터티 본문의 길이를 알 수 있어야 커넥션을 유지할 수 있다.
- 엔터티 본문이 정확한 Content-Length값과 Type, 청크 전송 인코딩으로 인코드 되어야 함을 뜻함
- 잘못된 Length값은 트랜잭션이 끝나는 시점에 기존 메세지의 끝과 새로운 시작을 정확히 알 수 없다.
- keep-alive 커넥션은 Connection: Keep-Alive 헤더를 인식하지 못하는 서버와 맺어지면 안된다. 현실적으로는 쉽지 않다.
- 기술적으로 HTTP/1.0을 따르는 기기로부터 받는 모든 Connection 헤더 필드는 무시해야한다.
- 오래된 프락시 서버로부터 실수로 전달될 수 있고 오래된 프락시에 행이 걸릴 수 있는 위험이 있다.
- 하지만 이 규칙을 지키지 않기도 한다.
- 클라이언트는 응답 전체를 모두 받기 전 커넥션이 끊어졌을 경우, 요청이 반복될 경우 생기는 문제가 있기 때문에 요청을 다시 보낼 수 있게 준비되어있어야한다.
4.5.6 Keep-Alive와 멍청한(dumb) 프락시
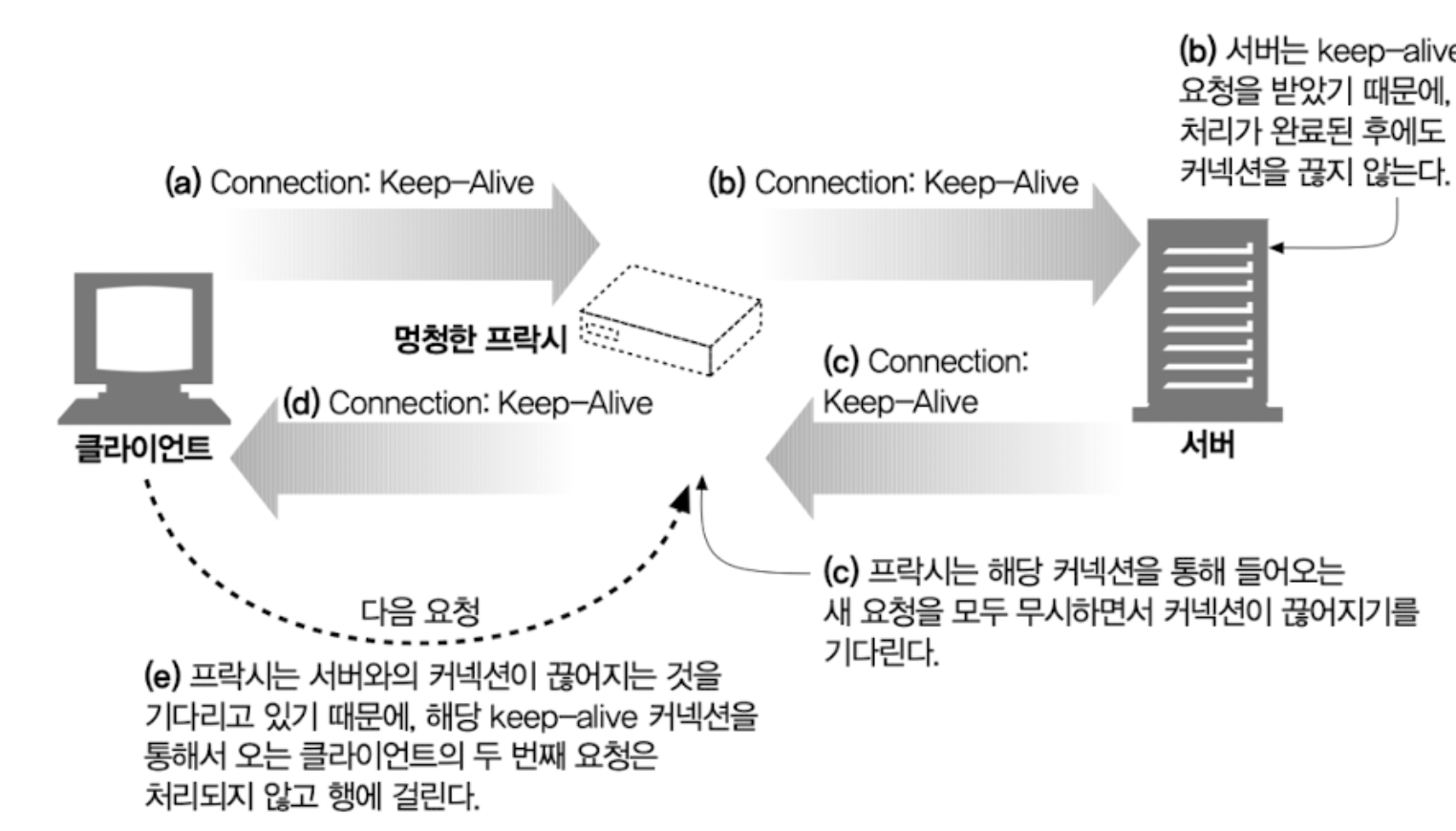
- 멍청한 프락시는 HTTP의 Connection 헤더를 단순히 확장 헤더로만 취급. 즉, 이해하지 못한다.
- 첫 요청과 응답을 통해 클라이언트와 서버는 프락시 서버와 같이 커넥션을 유지하는 것으로 알고 있다.
- 클라이언트는 keep-alive 커넥션으로 계속 요청을 보낸다.
- 서버는 적어도 max, timeout과 같은 매개변수의 값만큼 커넥션을 유지한다.
- 하지만 멍청한 프락시는 커넥션이 끊이지기만을 기다린다.
프락시와 홉별 헤더
- 이런 잘못된 통신을 피하기 위해 프락시는 Connection 헤더를 전달하면 안된다.
- 또한, Proxy-Connection 등과 같은 홉별 헤더들 역시 전달하거나 캐시하면 안된다.
4.5.7 Proxy-Connection 살펴보기
- Proxy-Connection 헤더를 사용해 클라이언트의 요청이 중개서버를 통해 이어지는 경우 모든 헤더를 무조건 전달하는 문제를 해결
- 멍청한 프락시는 홉별 헤더를 무조건 전달하기 때문에 문제를 일으킨다.
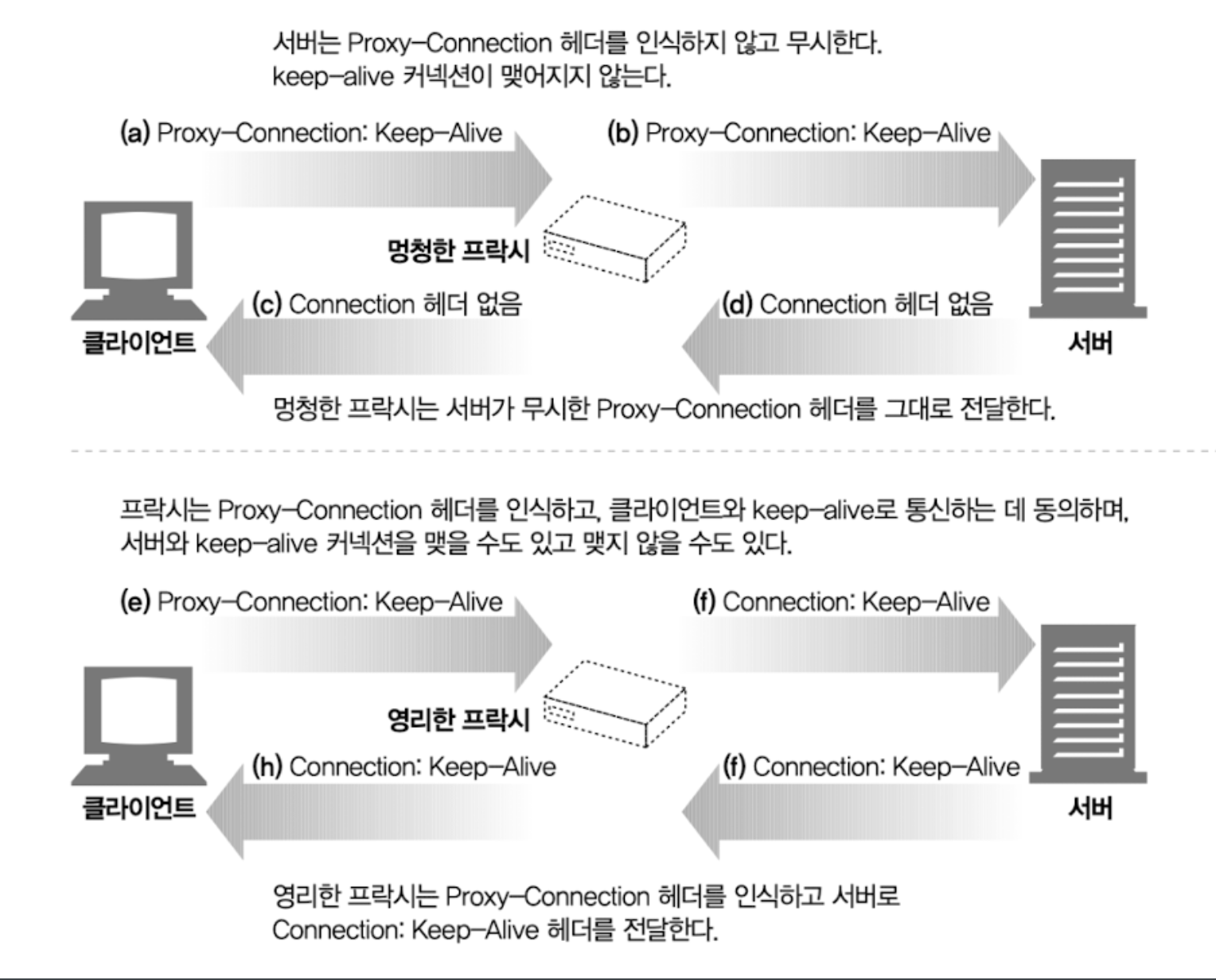
멍청한 프락시
- 클라이언트는 Proxy-Connection을 보내고 프락시 서버는 그대로 전달한다.
- 서버는 이를 무시하고 응답을 보낸다.
- 프락시와 클라이언트, 서버 사이에 커넥션이 유지되지 않는다.
영리한 프락시
- 클라이언트는 Proxy-Connection을 보내고 프락시 서버는 제대로된 Connection 헤더를 보낸다.
- 서버는 일반적으로 커넥션을 유지하기 위해 응답을 보낸다.
- 프락시와 클라이언트, 서버 사이에 커넥션이 유지된다.
중개 서버에 멍청한 프락시와 영리한 프락시가 같이 있으면 문제가 발생한다.
- 게다가 문제를 발생시키는 프락시들은 방화벽, 캐시 서버, 리버스 프락시 서버 가속기와 같이 네트워크상에서 '보이지 않는' 경우가 많다.
4.5.8 HTTP/1.1의 지속 커넥션
- HTTP/1.1에서는 keep-alive를 지원하지 않는 대신 더 개선된 지속 커넥션을 지원한다.
- HTTP/1.1에서는 별도 설정을 하지 않는 한, 모든 커넥션을 지속 커넥션으로 취급한다.
- HTTP/1.1 애플리케이션은 트랜잭션이 끝난 후 Connection:close 헤더를 명시해야 커넥션을 끊을 수 있다.
- 하지만 Connection:close 를 보내지 않는 것이 서버가 커넥션을 영원히 유지하겠다는 뜻은 아니다.
- 클라이언트와 서버는 마친가지로 언제든지 커넥션을 끊을 수 있다.
- 이게 Connection 헤더의 파라미터 값대로 동작을 보장하지 못하는 이유
4.5.9 지속 커넥션의 제한과 규칙
- 클라이언트가 요청에 Connection:close 헤더를 포함했다면, 더 이상 그 커넥션으로 요청을 보낼 수 없다.
- 클라이언트가 추가 요청이 없을 경우 마지막에 Connection:close 헤더를 보내야한다.
- 커넥션에 있는 모든 메세지는 자신의 Length정보가 정확해야 커넥션을 지속 가능
- 엔터티 본문은 정확한 Content-Length값을 가진다
- 청크전송 인코딩으로 인코드 되어 있어야한다.
- HTTP/1.1 프락시는 클라이언트, 서버 각각에 별도의 지속 커넥션을 맺고 관리
- HTTP/1.1 프락시 서버는 클라이언트의 지원 범위를 알고 있지 않다면 지속 커넥션을 맺으면 안된다.
- 오래된 프락시의 Connection 헤더 전달 문제
- 현실적으로 지키기 쉽지 않다.
- 서버는 메세지 전송 중 커넥션을 끊지 않고 끊기 전 적어도 한개의 요청에 대해 응답은 하지만 HTTP/1.1 기기는 Connection 헤더 값과 상관 없이 언제든지 끊을 수 있다.
- HTTP/1.1 애플리케이션은 중간에 끊어지는 커넥션을 복구할 수 있어야만 한다.
- 클라이언트는 전체 응답전 커넥션이 끊어지면 요청을 반복해서 보내도 문제 없는 경우 보낼 준비가 되어있어야한다.
- 하나의 사용자 클라이언트는 서버 과부화를 방지하기 위해, 넉넉하게 2개의 지속 커넥션을 유지해야 한다.
4.6 파이프라인 커넥션
파이프라인의 제약 사항
- HTTP 클라이언트는 커넥션이 지속 커넥션인지 확인하기 전까지는 파이프라인을 이어서는 안된다.
- HTTP 응답은 요청 순서와 같게 와야 한다. HTTP 메세지는 순번이 매겨져 있지 않아서 응답이 순서 없이 오면 순서에 맞게 정렬시킬 방법이 없다.
- HTTP 클라이언트는 커넥션이 언제 끊어지더라도, 완료되지 않은 요청이 파이프라인에 있으면 언제든 다시 요청 보낼 준비가 되어 있어야 한다.
- 10개 요청후 5개의 응답만 받고 커넥션이 끊김
- 남은 5개의 실패한 요청을 커넥션을 다시 맺고 요청을 보낼 수 있어야한다.
- HTTP 클라이언트는 POST 요청같이 반복해서 보낼 경우 문제가 생기는 요청은 파이프라인을 통해 보내면 안된다.
- 에러 발생시, 요청 중 어떤 것들이 서버에서 처리되었는지 클라이언트가 알 방법이 없다.
- POST와 같은 비멱등(연산이 한번 일어날 때 마다 결과가 변할 수 있는) 요청을 재차 보내면 문제가 생길 수도 있다.
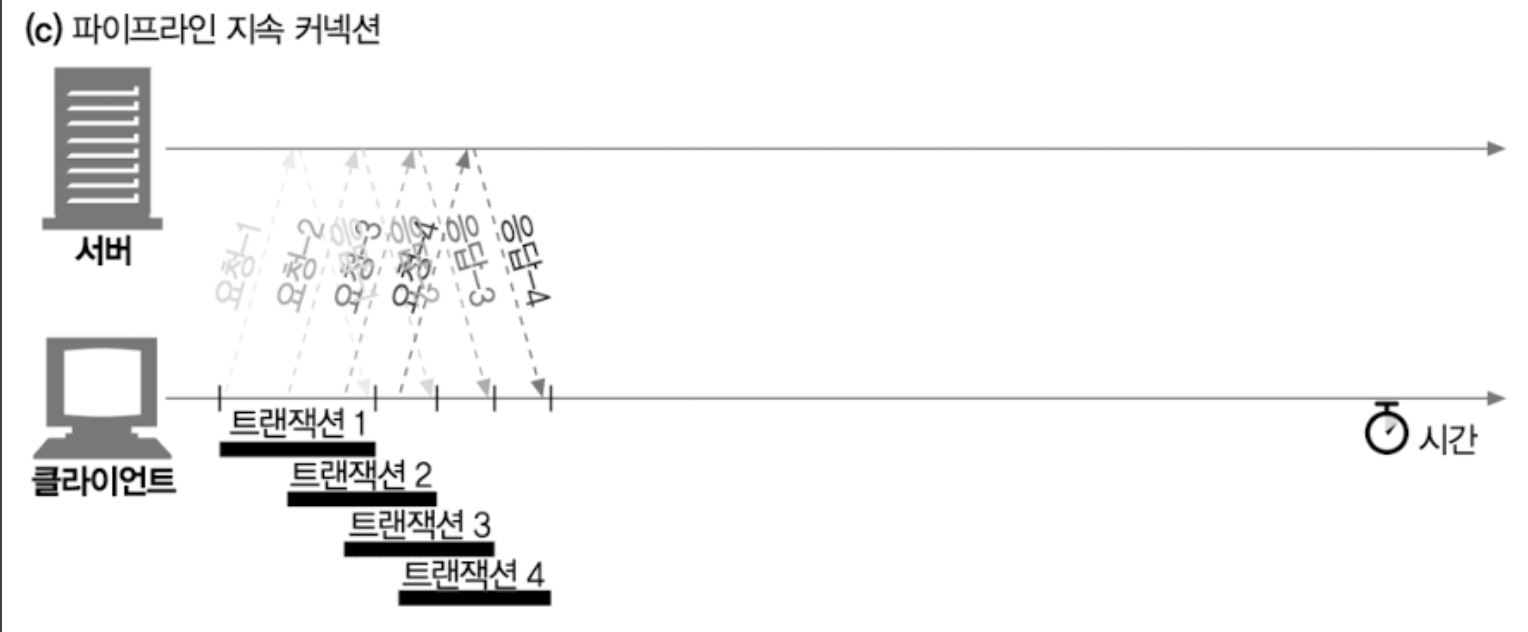
4.7 커넥션 끊기에 대한 미스터리
- 커넥션 관리(언제 끊어야 하는지)에는 명확한 기준이 없다.
4.7.1 '마음대로' 커넥션 끊기
- 어떠한 HTTP 클라이언트, 서버, 혹은 프락시든 언제든 TCP 커넥션을 끊을 수 있다.
- 보통은 메세지를 다 보낸 다음 끊는다
4.7.2 Content-Length와 Truncation
- 각 HTTP 응답은 본문의 정확한 크기 값을 가지는 Content-Length 헤더를 가지고 있어야 한다.
4.7.3 커넥션 끊기의 허용, 재시도, 멱등성
- 커넥션은 심지어 에러가 없더라도 언제든 끊을 수 있다.
- 이에 HTTP 애플리케이션은 예상치 못하게 커넥션이 끊어졌을 때에 적절히 대응할 수 있는 준비가 되어있어야한다.
- 트랜잭션 수행중 커넥션이 끊기면, 클라이언트는 다시 커넥션을 맺고 한번 더 전송 시도
- 클라이언트는 요청을 큐에 쌓아 놓을 수 있다.
- 반면, 서버는 아직 처리되지 않고 스케줄이 조정되어야하는 요청을 남겨둔 채로 커넥션을 끊어 버릴 수 있다.
- 클라이언트는 커넥션이 끊기면 서버에서 얼마만큼 요청이 처리되었는지 알 수 없다.
- 이는 GET요청은 상관 없지만 POST같은 비멱등 경우 문제가된다.
- 멱등
- GET, HEAD, PUT, DELETE, TRACE
- 비멱등
- POST
[멱등, 비멱등]
여러번 요청해도 서버에서 상태가 변하는 유무에 따라 나뉘게 된다.
PUT -> 여러번 실행해도 리소스의 상태가 마지막 PUT 요청의 페이로드를 반영한 상태로 유지된다.
DELETE -> 여러번 실행해도 서버에서 리소스의 상태가 '삭제'라는 최종 상태에는 변함이 없다.
POST -> 예를 들어 첫번째 요청으로 사용자가 생성된 후 또 요청을 보내면 중복되는 새로운 사용자가 생성될 수 있기 때문에 서버의 상태가 두번의 요청 후에 다르게 되기 때문에 비멱등이다.
4.7.4 우아한 커넥션 끊기
- TCP 커넥션은 양방향이다.
전체 끊기와 절반 끊기
- 전체 끊기
- 애플리케이션은 TCP 입력 채널과 출력 채널 중 한 개만 끊거나 둘 다 끊을 수 있다.
- 방법 : close() 호출
- 절반 끊기
- 입력, 출력 중 하나를 개별적으로 끊을 수 있다.
- 방법: shutdown() 호출
TCP 끊기와 리셋 에러
- 단순한 HTTP 애플리케이션은 전체 끊기만 사용할 수 있다.
- 애플리케이션이 각기 다른 HTTP 클라이언트, 서버, 프락시와 통신할 때
- 그들과 파이프라인 지속 커넥션을 사용할 때
- 예상치 못한 쓰기 에러를 예방하기 위해 절반 끊기를 사용해야함
- 보통은 출력 채널을 끊는 것이 안전
- 반대편 기기는 더이상 입력이 없음으로 내가 출력 커넥션을 끊었다는 것을 알게 됨
- 클라이언트는 데이터를 더 보내지 않는 것에 확신하지 않는 이상, 입력 채널을 끊는 것은 위험
- 끊긴 상태에서 데이터 전송시 , 서버의 운영체제는 TCP 'connection reset by peer' 메세지를 보냄
- 이는 심각한 에러로 취급, 버터에 저장된 + 아직 읽히지 않은 데이터 전부 삭제
- Example
- C - 10개의 요청을 파이프라인 지속 커넥션을 통해 전송
- S - 10개의 응답을 버퍼에 저장 ( 아직 애플리케이션이 읽지 않음)
- 이미 충분히 오래 유지되었다고 판단 -> 커넥션 종료
- C - 11번째 요청 전송
- S - 'connection reset by peer' 메세지 응답 및 , 버퍼에 저장된 응답 데이터 전부 삭제
우아하게 커넥션 끊기
- 애플리케이션의 우아한 커넥션 끊기
- 자신의 출력 채널 끊는다.
- 다른 쪽의 출력 채널이 끊기는 것을 기다린다. ( 자신의 입력채널에 더 이상 데어티가 안들어옴)
- 하지만 상대방이 절반 끊기를 구현했다는 보장 X
- 절반 끊기를 했는지 검사해준다는 보장 X
- 따라서 자신의 출력 채널에 절반 끊기 후, 입력 채널의 대해 상태를 주기적으로 검사
- 만약 입력 채널이 timeout 시간 내에 끊어지지 않는다면 리소스 보호를 위해 커넥션을 강제로 종료
Spring에서의 동작과정
- Spring Framework에서 요청과 응답을 담당하는 서블릿 컨테이너는 WAS의 일부
- HTTP 요청을 받아 처리하고 응답을 반환하는 역할을 한다.
- TCP 커넥션 관리는 이 과정에서 중요한 부분 중 하나
- 동작 과정
1. TCP 커넥션 개설: 클라이언트가 -> 서버 연결 요청. 서블릿 컨테이너 내부의 웹 서버는 TCP 소켓을 열고, 클라이언트와 서버 간의 TCP 커넥션 개설(3-way handshake과정을 통해 연결 설정)
2. 요청 처리: TCP 커넥션을 통해 전송된 HTTP 요청은 서블릿 컨테이너에 도달합니다. 서블릿 컨테이너는 해당 요청을 분석하여 적적한 서블릿에 전달. (서블릿은 요청을 처리 후 응답 생성)- Handler Mapping
- 들어오는 요청을 해당하는 핸들러(컨트롤러)를 찾아 매핑한다. (Spring MVC)
1. 요청 식별: 클라이언트로부터 들어온 요청은 먼저 DispatcherServlet에 의해 받아진다. DispatcherServlet은 Spring MVC의 프론트 컨트롤러 역할.
2. 핸들러 매핑 조회: DispatcherServlet은 등록된 핸들러 매핑 전력을 조회, 요청 URL에 해당하는 핸들러(컨트롤러 메소드) 를 찾는다.
3. 핸들러 실행: 매핑된 핸들러가 결정되면, DispatcherServlet은 해당 핸들러 실행. (이 과정에서 핸들러에 필요한 다양한 파라미터가 바인딩, 비지니스 로직이 수행)
4. 뷰 리졸빙 및 응답 반환: 핸들러의 실행 결과를 바탕으로, DispatcherServlet은 적절한 뷰를 찾아 클라이언트에게 응답을 반환. (혹은 JSON 타입의 데이터 반환) - @RequestMapping
3. 응답 반환: 처리된 응답은 다시 HTTP 응답으로 클라이언트에게 전송
4. 커넥션 유지 및 종료 : HTTP/1.1 스펙에 따라, 일정 시간동안 커넥션 유지 될 수 있다.
5. 커넥션 풀링: 성능 최적화를 위해 서블릿 컨테이너는 종종 TCP 커넥션 풀을 사용. 미리 생성된 TCP 커넥션의 집합으로, 요청이 들어올 때마다 새로운 커넥션을 개설하는 대신 풀에 있는 커넥션을 재사용
6. 비동기 처리: 최신의 서블릿 컨테이너는 비동기 처리 지원, 하나의 요청 처리가 완료될 때까지 TCP 커넥션을 유지하면서도 그 동안 다른 요청을 처리할 수 있다.
- 들어오는 요청을 해당하는 핸들러(컨트롤러)를 찾아 매핑한다. (Spring MVC)
- Handler Mapping
