
문제 설명
시작 단어를 주어진 값을 활용해서 target 단어로 변환하여 단어를 바꾼 횟수를 계산하는 문제이다. 추가로, 한 번에 한 개의 알파벳만 바꿀 수 있다는 조건이 있다. 해당 문제와 조건을 보고 다음과 같은 주요 로직을 생각해봤다.
- 현재 단어와 바꿀 단어가 1개만 차이나는지 확인해야 한다.
- 주어진 단어 중에 target 단어가 없으면 굳이 동작을 수행 할 필요가 없다.
- 깊이, 너비 중 어떤 탐색을 통해 해야하는가?
1. DFS와 백트래킹을 사용한 접근 ( 실패 )
처음에 가장 먼저 떠오른건 DFS와 백트래킹을 사용하여 되는 경우를 찾아보는 것이다. (이전에 풀었던 문제가 백트래킹을 사용했 던 것이라 그런 것 같다.).
코드
class Solution {
boolean[] visited;
int answer;
public int solution(String begin, String target, String[] words) {
visited = new boolean[words.length];
answer = 0;
dfs(begin, target, words, 0);
return answer;
}
void dfs(String word, String target, String[] words, int len){
if(word.equals(target)){
answer = len;
return;
}
if(len == words.length){
return;
}
for(int i=0; i < words.length; i++){
if(!visited[i]){
visited[i] = true;
int cnt = 0;
for(int j=0; j<word.length(); j++){
if(word.charAt(j) != words[i].charAt(j)){
cnt++;
}
if(cnt > 1){
break;
}
}
if(cnt <= 1){
dfs(words[i], target, words, len+1);
}
}
visited[i] = false;
}
}
}- 방문 정보를 확인하며 깊이 우선 탐색을 통해 되는 경우를 확인한다.
- 현재 단어와 비교할 단어의 길이만큼 차이를 비교해서 2개 이상 차이날 경우는 탐색하지 않는다.
결과
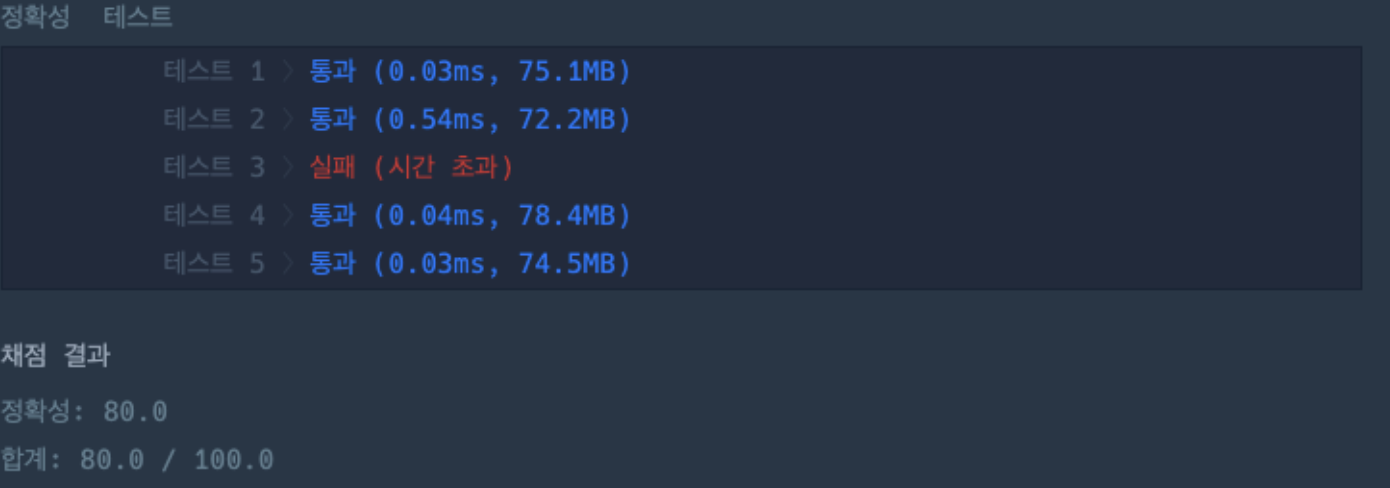
3번째 테스트에서 시간 초과가 발생했다.
문제 원인으로는 2가지 정도가 있을 것이라고 추측했다.
1. 단어를 비교하는 로직의 시간 복잡성
2. 깊이 우선 탐색 시, 최악의 경우 연산량이 많아진다.
- 단어의 개수를 50(최대)개라고 했을 때, 한번 최대 깊이로 갈 때,50 * 49 * 48 * ... * 41 정도의 연산이 필요한데 마지막에 답을 찾을 경우, 너무 많은 연산이 이뤄진다.
3. 주어진 단어 중에 target 단어가 없을 때 확인
해당 문제는 없어도 크게 상관 없을 것 같아 고려하지 않았다.
일단, 깊이 우선 탐색이 가장 문제 될 것 같아. Queue를 사용해 너비 우선 탐색으로 풀어봤다.
2. BFS를 사용한 접근 방식 (성공)
코드
import java.util.*;
class Solution {
class Node{
String word;
int len;
public Node(String word, int len){
this.word = word;
this.len = len;
}
String getWord(){
return this.word;
}
int getLen(){
return this.len;
}
}
int answer;
public int solution(String begin, String target, String[] words) {
answer = 0;
Queue<Node> q = new LinkedList<>();
q.add(new Node(begin, 0));
while(!q.isEmpty()){
Node current = q.poll();
if(current.getLen() > words.length){
break;
}
if(current.getWord().equals(target)){
answer = current.getLen();
break;
}
for(int i=0; i<words.length; i++){
boolean check = checkWord(current.getWord(), words[i]);
if(check){
q.add(new Node(words[i], current.getLen()+1));
}
}
}
return answer;
}
boolean checkWord(String a, String b){
int cnt = 0;
for(int i=0; i<a.length(); i++){
if(a.charAt(i) != b.charAt(i)){
cnt++;
}
if(cnt>1){
break;
}
}
if(cnt < 2){
return true;
}else{
return false;
}
}
}a. Class Node
class Node{
String word;
int len;
public Node(String word, int len){
this.word = word;
this.len = len;
}
String getWord(){
return this.word;
}
int getLen(){
return this.len;
}
}- 가장 먼저 단어와 현재 깊이를 가질 수 있는 Node 클래스를 선언했다. 여기서 Len이 현재 깊이를 의미하며 최대 깊이는 words의 length일 것이다.
b. Solution
public int solution(String begin, String target, String[] words) {
answer = 0;
Queue<Node> q = new LinkedList<>();
q.add(new Node(begin, 0));
while(!q.isEmpty()){
Node current = q.poll();
if(current.getLen() > words.length){
break;
}
if(current.getWord().equals(target)){
answer = current.getLen();
break;
}
for(int i=0; i<words.length; i++){
boolean check = checkWord(current.getWord(), words[i]);
if(check){
q.add(new Node(words[i], current.getLen()+1));
}
}
}
return answer;
}- 첫번째 단어와, 0(len)을 Queue에 넣고 반복을 시작
- 현재 노드가 최대 깊이(words.length)보다 클 경우, 반복문을 종료
- 방문 처리를 따로 하지 않기도 했고, words.length보다 더 많이 탐색할 수 없기 때문이다.
- 현재 노드의 단어가 target단어와 같다면 answer에 len을 할당하고 종료 (정답을 추출하는 부분)
- 현재 단어와 바꿀 단어를 비교하는 로직은 그대로 사용했으나 함수로 만들어서 사용했다.
- 한 글자만 다르다면 Queue에 삽입하고 , len을 1 증가시킨다.
결과
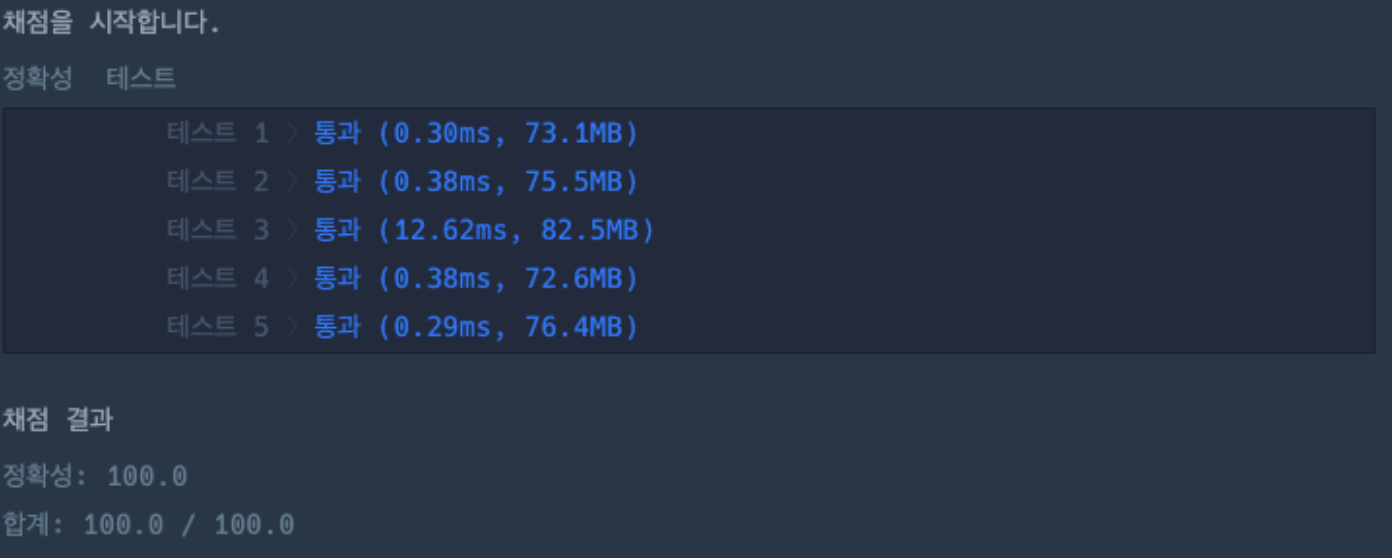
이전에 통과 못했던 테스트 3를 통과해서 정답을 맞췄다. 하지만 여전히 테스트 3의 실행 시간이 다른 테스트에 비해 매우 긴 것을 볼 수 있고 완벽히 최적의 해를 찾은 건 아닌 것 같았다.
Review
친구와 푼 문제를 리뷰화는 과정에서 이전 정답에서 완벽히 해결하지 못했던 부분의 문제를 알 수 있었다. 단어끼리 틀린 개수를 확인하는 로직이 문제였는데, 기존 내가 작성한 정답을 생각해보면 단어의 길이가 10일 때, 대충 다음과 같은 연산 수를 가지게 된다. (단어 개수는 50개)
depth 1 일 때, 10 50
depth 2 일 때, 10 50 50
...
최악의 경우를 생각하면 대략 계산만 해도 마지막 depth 일 때, 10 10 * 50 ^ 50 정도 되는 것 같다.. ^^; (정확하지 않을 수 있다.)
코드
import java.util.*;
public class Solution {
public int solution(String begin, String target, String[] words) {
Set<String> wordSet = new HashSet<>(Arrays.asList(words));
Set<String> visited = new HashSet<>();
int answer = 0;
int wordSize = words[0].length();
// 큐에 시작 단어와 변환 횟수를 담음
Queue<Pair> queue = new LinkedList<>();
queue.offer(new Pair(begin, 0));
visited.add(begin);
while (!queue.isEmpty()) {
Pair current = queue.poll();
String word = current.word;
int count = current.count;
// 목표 단어에 도달한 경우
if (word.equals(target)) {
return count;
}
// 단어의 각 문자를 하나씩 바꿔가며 탐색
for (int i = 0; i < wordSize; i++) {
for (char j = 'a'; j <= 'z'; j++) {
char[] tempArr = word.toCharArray();
tempArr[i] = j;
String temp = new String(tempArr);
// 바꾼 단어가 words 목록에 있고, 아직 방문하지 않은 경우
if (wordSet.contains(temp) && !visited.contains(temp)) {
queue.offer(new Pair(temp, count + 1));
visited.add(temp);
}
}
}
}
return answer; // target에 도달하지 못한 경우
}
// 단어와 변환 횟수를 저장할 클래스
class Pair {
String word;
int count;
Pair(String word, int count) {
this.word = word;
this.count = count;
}
}
}변경된 주요 코드를 보면 다음과 같다.
Set<String> wordSet = new HashSet<>(Arrays.asList(words));
Set<String> visited = new HashSet<>();
...
for (int i = 0; i < wordSize; i++) {
for (char j = 'a'; j <= 'z'; j++) {
char[] tempArr = word.toCharArray();
tempArr[i] = j;
String temp = new String(tempArr);
// 바꾼 단어가 words 목록에 있고, 아직 방문하지 않은 경우
if (wordSet.contains(temp) && !visited.contains(temp)) {
queue.offer(new Pair(temp, count + 1));
visited.add(temp);
}
}
}
- 방문 단어를 다시 탐색하지 않도록 하기 위한
HashSetvisited와 words를HashSet에 넣어 비교할 단어와 확인 할 수 있다.- HashSet의 contain은 시간 복잡도가 O(1)이기 때문에 반복해서 찾을 때의 O(n)보다 빠르게 찾을 수 있다.
- 이후, 선택된 단어를 Queue에 넣고 visited를 설정해 너비 우선 탐색 과정을 수행할 수 있다.
결론
이전까지 Array 형태로 반복해서 적절한 값을 찾는 방법으로 해왔는데, Set을 적절하게 사용하면 실행 시간을 많이 단축할 수 있을 것 같다.
