
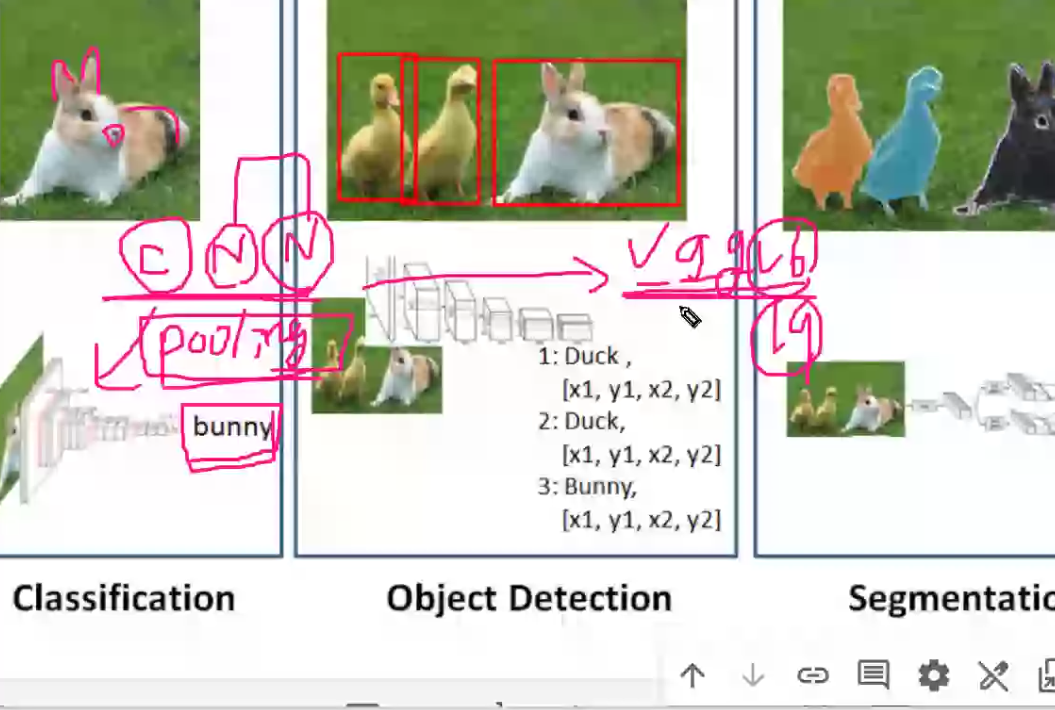
CNN(특징강조)
pooling(불필요한 내용 삭제)
욜로
친칠라
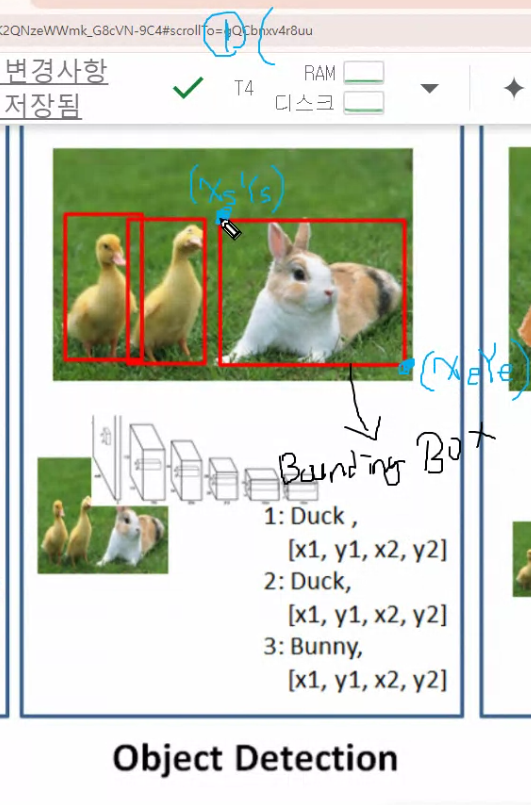
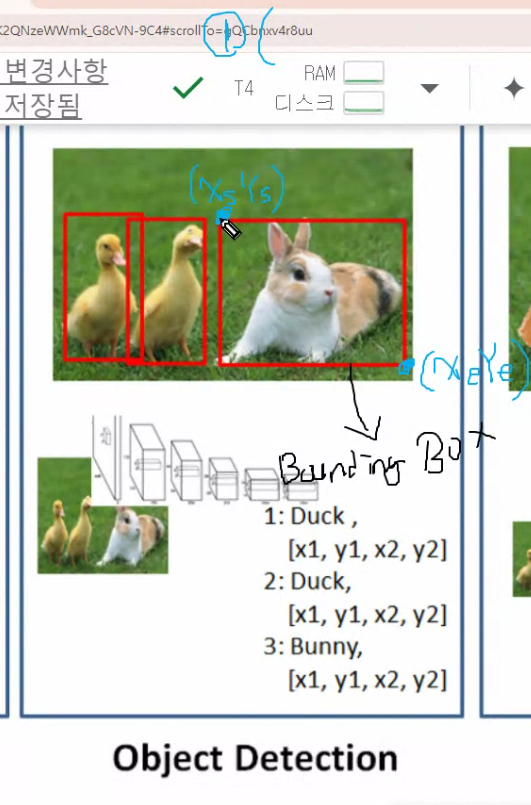
중심좌표에서 x,y 저장하는 방법
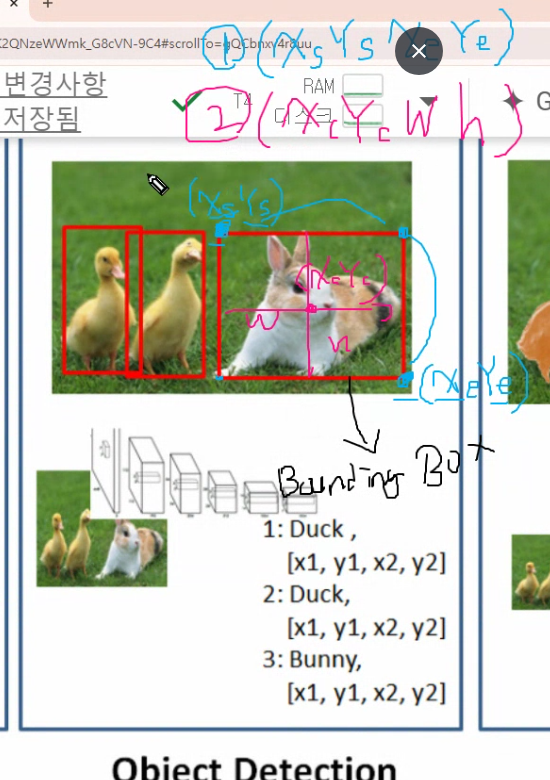
YOLO는 2번방법 중심좌표에서 시작
영역
을 맞추는 영역분할기법
세그먼테이션 어디서 쓰일까? 자율주행
ex) 차량파손 어디서 어디까지 파손되었나
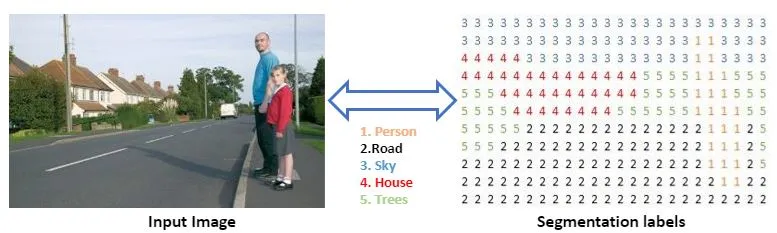
픽셀 1개 단위로 예측을 합니다.
객체탐지는 잘라서 일부
세그먼테이션은 1pix로 예측
픽셀단위로 라벨링하여 학습/예측한다
각 픽셀이 어떤 범주에 속하는지 확률 값을 에측
1픽셀에 5개 확률값이 나온다면 그 중 1개
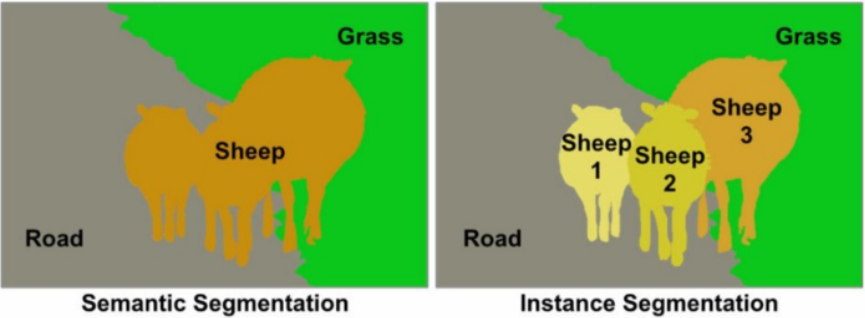
Segmentation 종류
- Semantic Segmentation : 각 픽셀이 어떤 범주영역에 속하는지만 예측하는 방식(각 객체를 구별하지 않는다.)
- 1,2,3 양들이 뭉쳐있는 영역이에요
- Instance Segmentation : 각 픽셀이 어떤 범주영역에 속하는지 예측을 수행하고 같은 도메인을 가진 영역에서도 객체를 분할하여 예측을 수행
- 각자 개체 구분할때
Segmentation 기술의 발전
-
기존 classification의 문제점 : CNN(특징강조)와 Pooling(불필요한정보삭제)을 거치면서 이미지 정보가 압축이 됩니다. 추상화되면서 압축된 정보가 도출
-
각 개별 픽셀들의 정보(색상, 위치)는 소실 또는 추상화되고 전체 이미지에 대한 압축된 정보만 남게 된다.
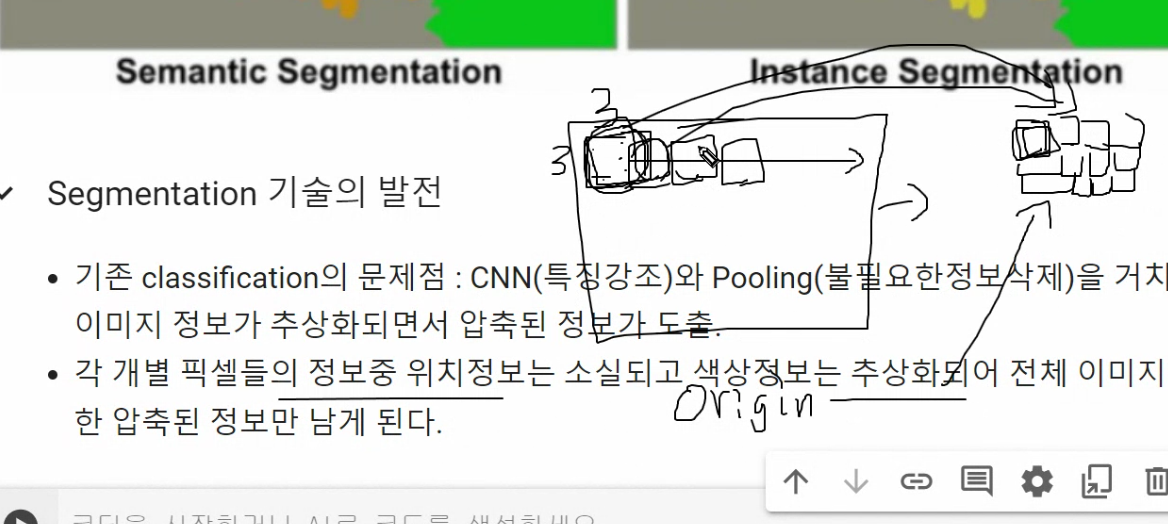
묶어서 압축
위치정보는 없어지고 색상정보는 추상화
문제를 해소하기 위해서 새로운 모델이 있습니다.
Fully Convolutional Network(FCN)의 등장
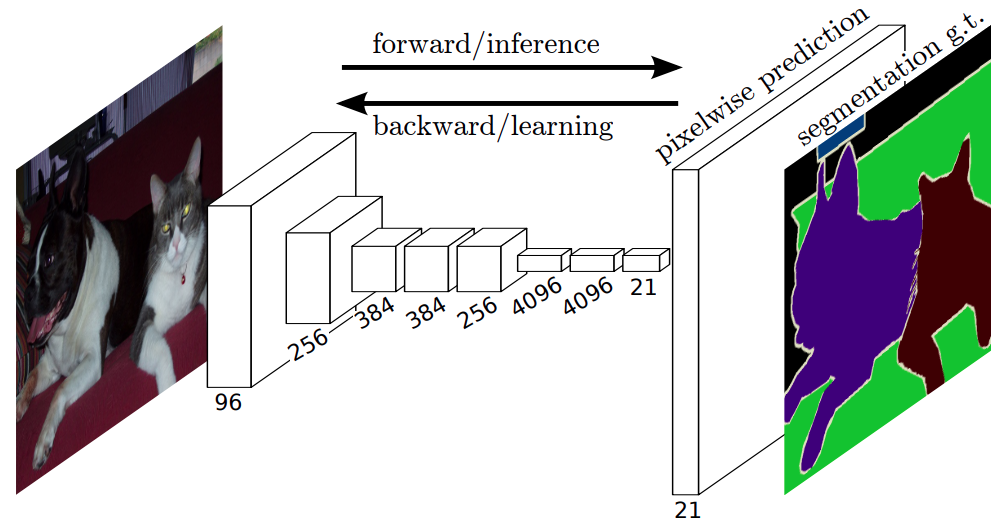
마지막 21때는
확률을 알기위해서 MLP에 붙여줍니다. (Flatten 해서 위치정보소실 이미 됨 + MLP 넣기위해선 1차원이어야함)
하지만
- 기존 classification 모델의 마지막에 사용되던 MLP를 제거하고 convolution layer로 대체
- 압축된 정보를 원래 이미지 크기로 복원하는 CNN레이어가 마지막에 붙게 됨
- 모델 내부에 CNN레이어로만 구성이 되어있어 FCN이라는 이름이 붙음
원래 크기만큼 키워서 끝에다가 붙여버림
예측이 향상
깔끔하게 안됩니다. >발전> 인코더 디코더
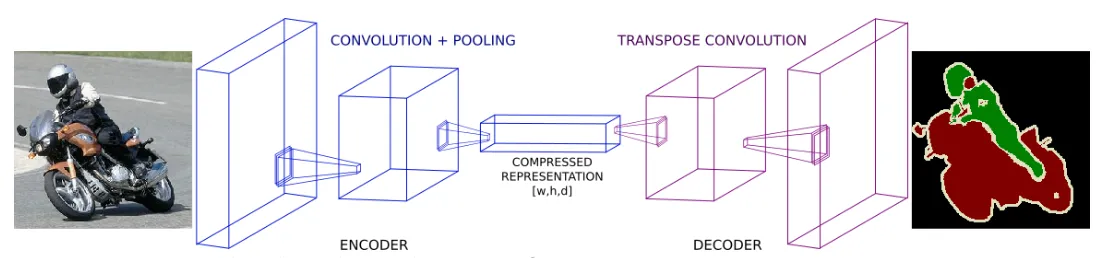
- Encoder : 원본 이미지의 주요 정보를 압축해가는 역할 (Downsampling)
- Decoder : 압축된 정보로 원본 크기의 segmentation정보를 복원하는 역할(Upsampling)
- Skip connection : Decoder가 복원시 최종 압축된 정보만 활용하는게 아니라 이전에 pooling된 정보를 참고해서 합쳐주는 방식
인코더, 오리지날을 압축해서 전달
디코더, 압축해서 원래대로 복원한다.
자연어에서 비슷하게 채용해서 씁니다.
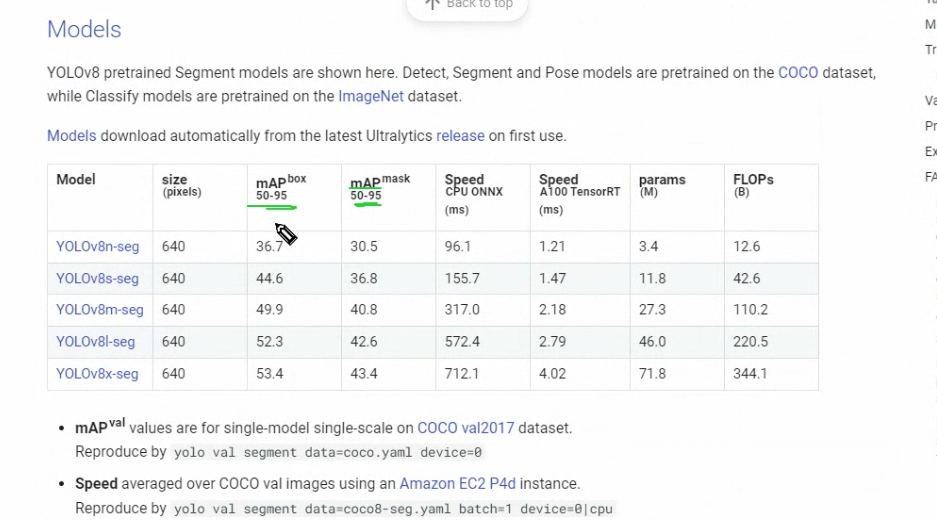
- 모델종류 확인
- https://docs.ultralytics.com/tasks/segment/
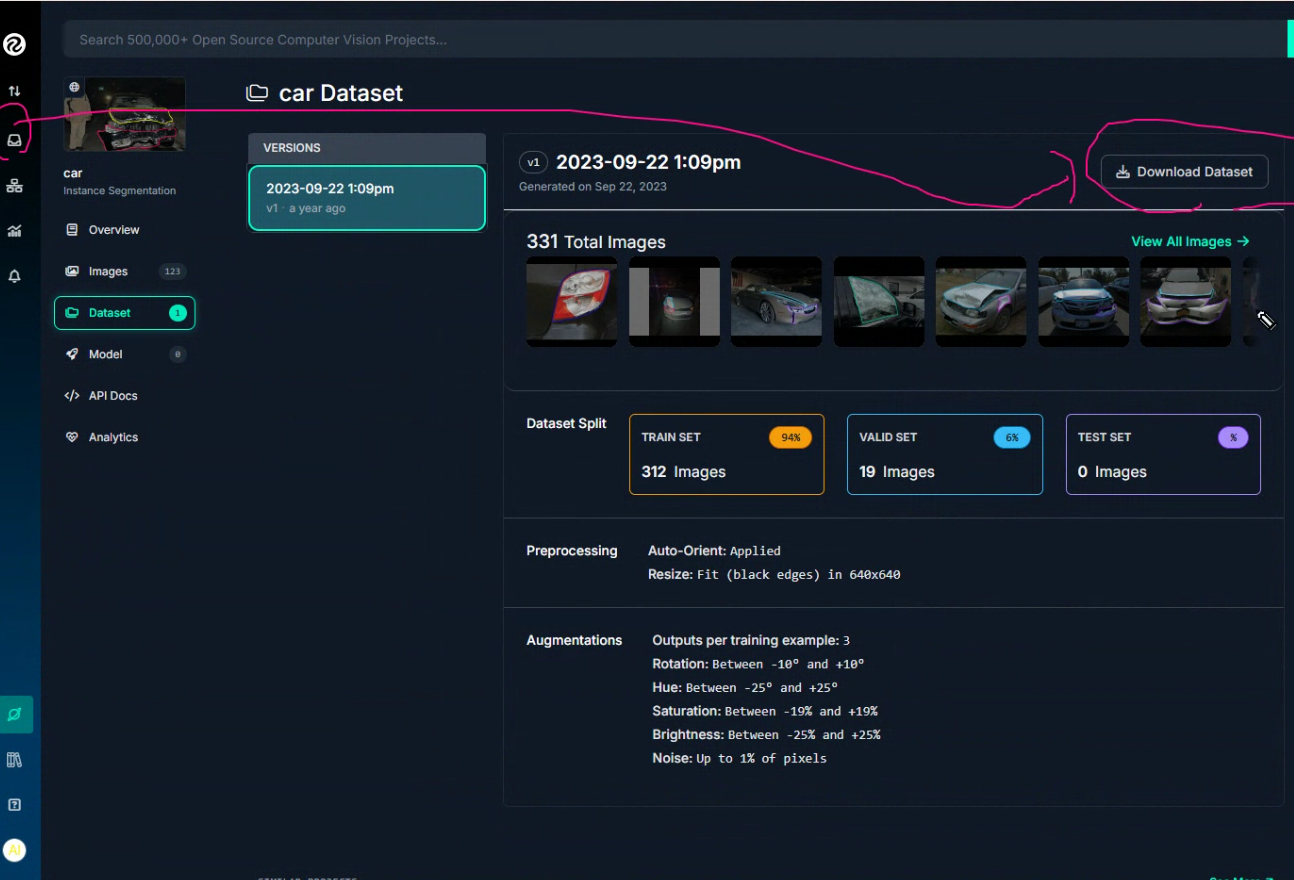
- 데이터셋 가이드
- https://docs.ultralytics.com/datasets/segment/
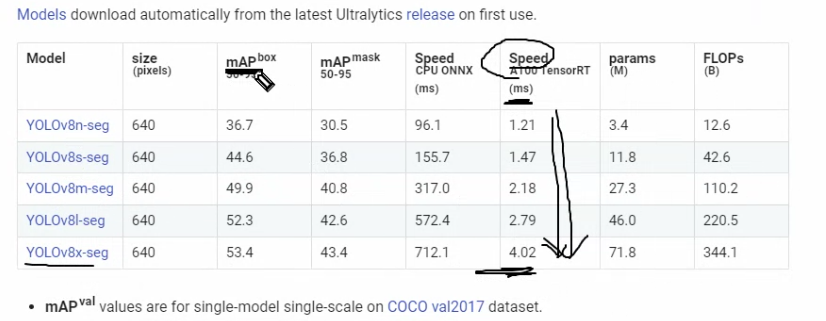
mAP 평가지표가 큰거가 성능이 더 좋지만 속도는 떨어집니다.
640x640
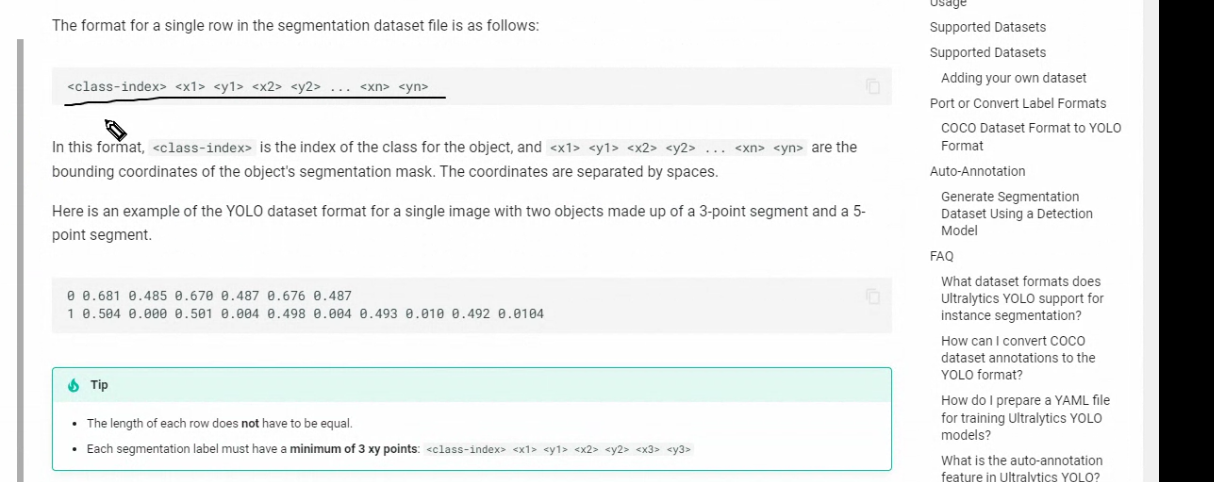
한줄에 하나의 객체
나열
숫자는 클래스 정보
해당영역 좌표정보
0번 클래스 3개점
1번 클래스 5개 점으로 영역을 표시하는 라벨 데이터
누끼를 따듯이 포인트정보가 데이터로 들어와있습니다.
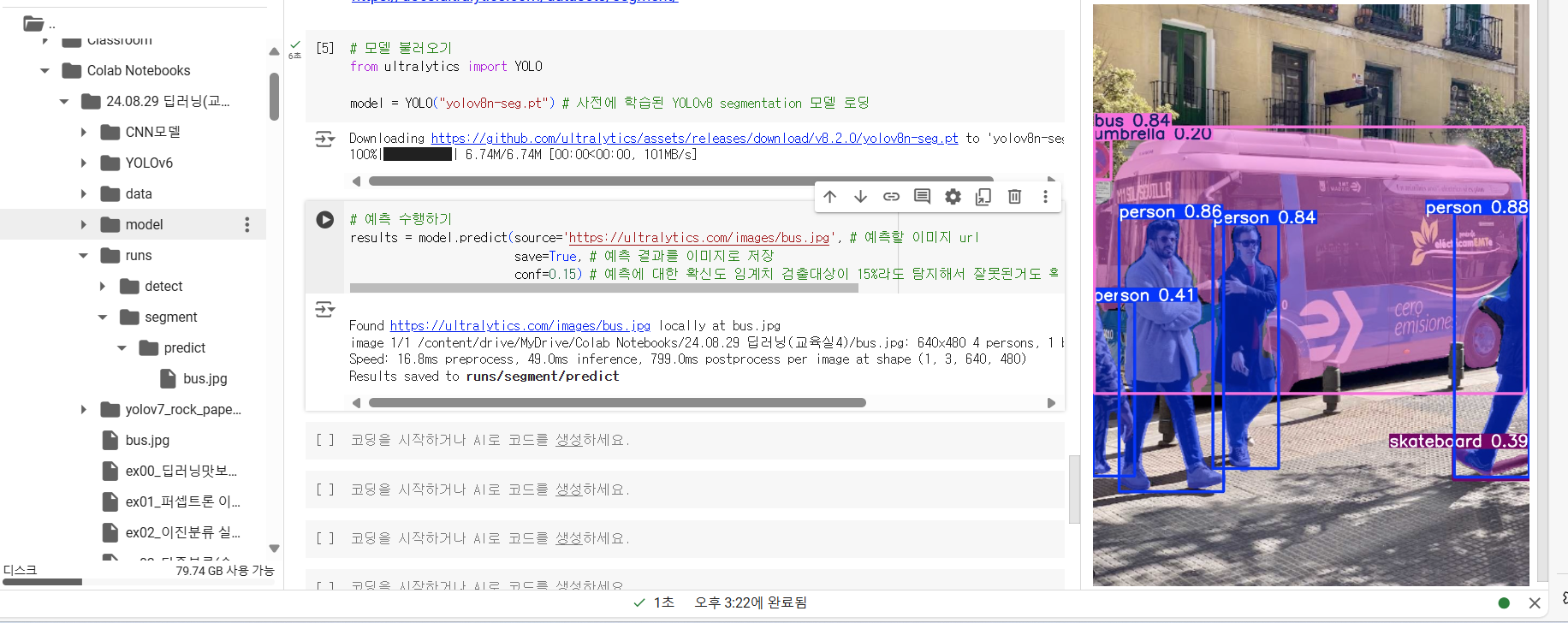
conf =0.15
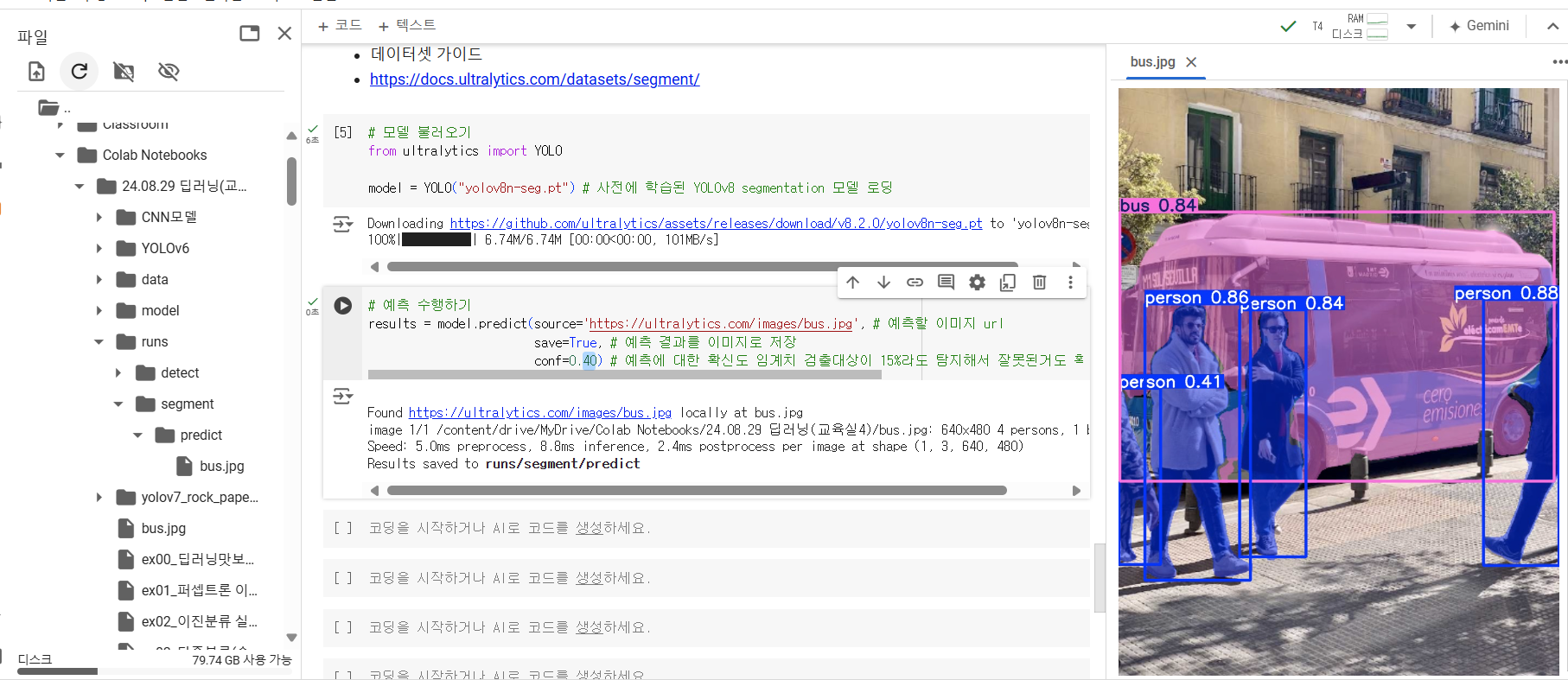
conf = 0.4
우산,스케이트보드 잘못선택한거 사라짐
쏘카 기술블로그 딥러닝 모델 내용 중

1번 정상 차 / 불량 차
먼저 판별 후 아마 임계치를 높여서 합 / 불 판별을 해서 사진 파악 속도를 높였을 겁니다.
2번
세그먼테이션
일부러 빗겨난 사진 넣어서 강건하게 만듦 + 사진 가이드라인 추가
보완방법
모델 결합 (위치결합, 색상)
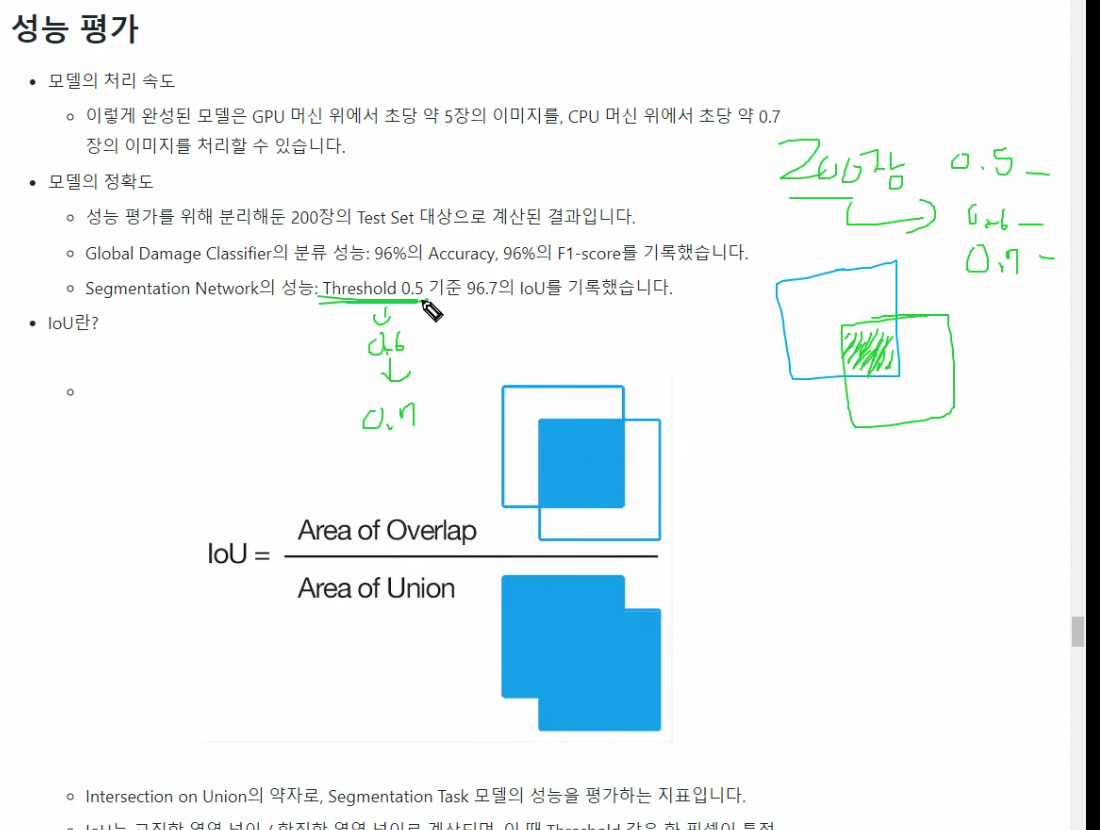
성능평가
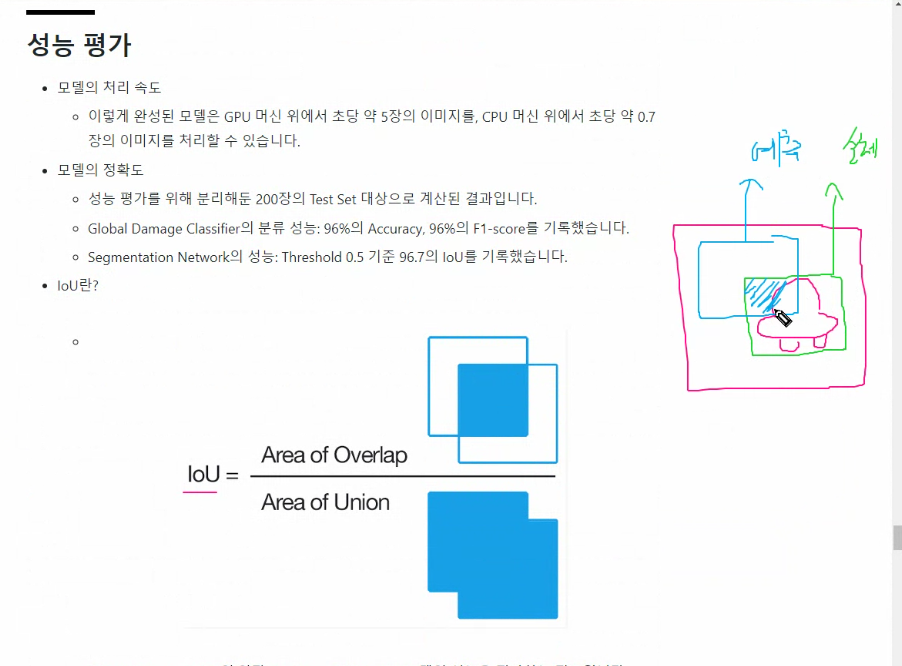
겹치는 정도가 얼마인가
바꿔가면서 평균적으로 몇개 맞추는지 점수
Ap 라고 부릅니다.
0.5-0.95 겹친거까지 정밀도 내서 평균값
차 Ap
사람 Ap
전체 다 더하고 평균이 = mAp 입니다.
box, mask
box 겹쳐진거끼리
mask 누끼 실제영역
box는 추정값으로 해서 조금 더 점수가 높게 나왔습니다.

라벨 - 정답
2개 인스턴스가 있습니다. 좌표값이 나열되어 있습니다.
학습된 best.pt는 runs > train > weights 폴더 안에 있는데 구체적으로 어디였는지
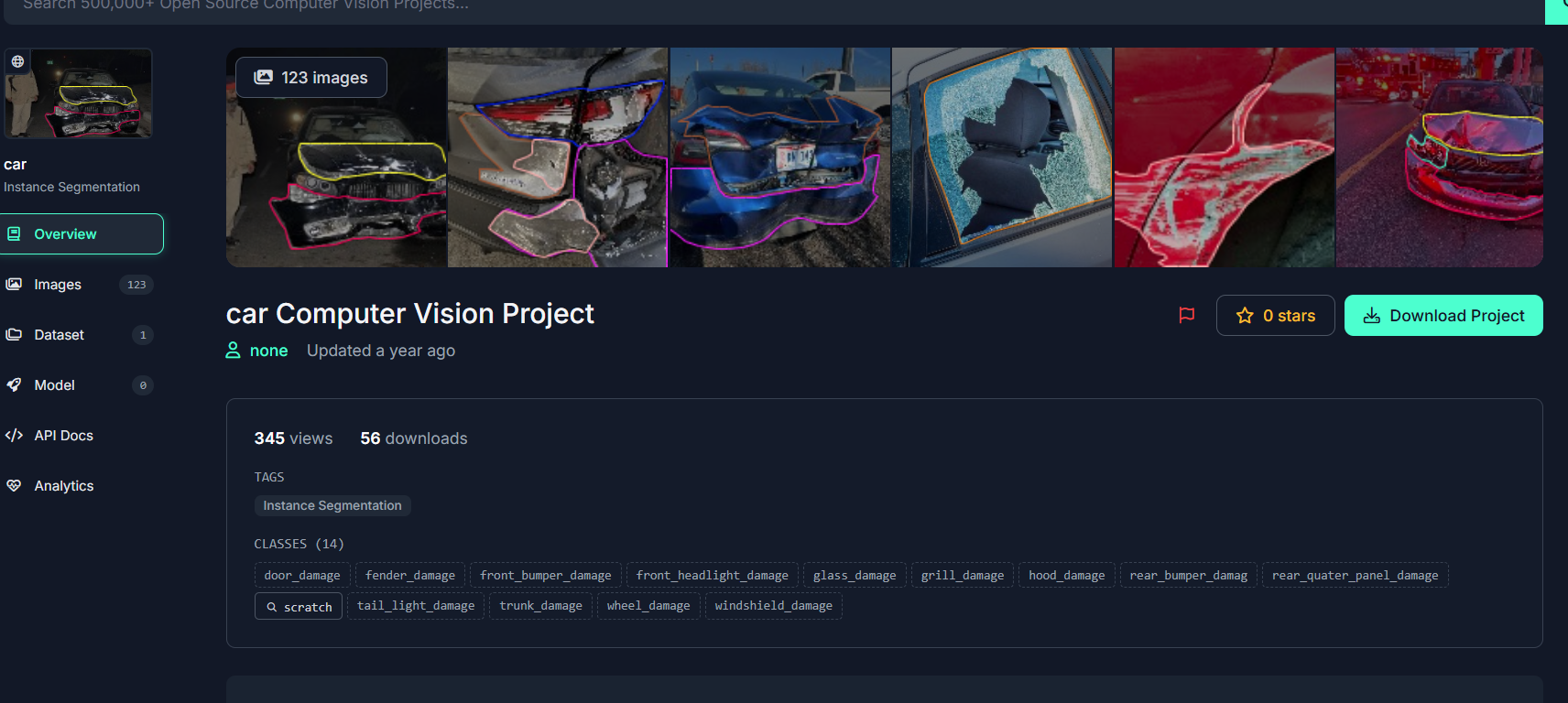
클래스는 14개로 되어있습니다.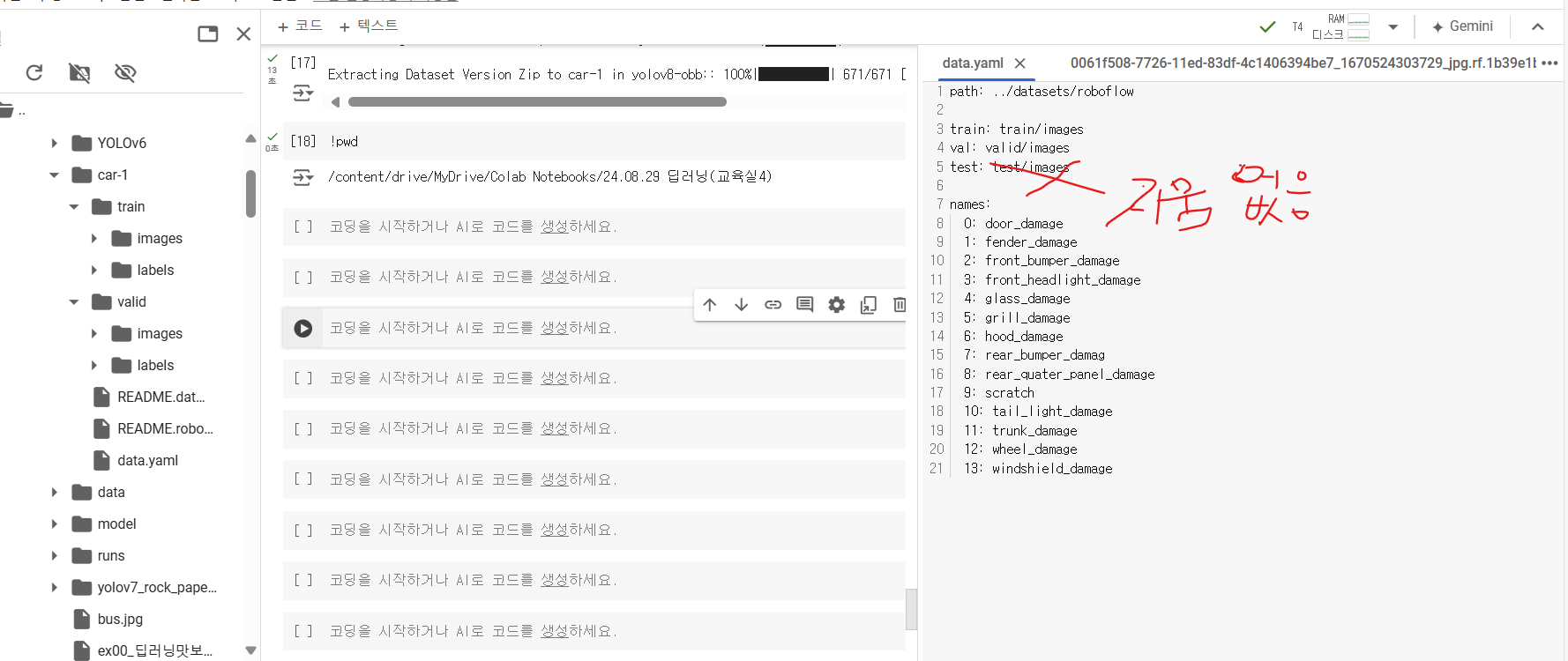
√ 학습된 모델로 로컬에서 예측 수행하기
• 영상을 활용해 차량파손범위 예측
• 참고 : https://docs.ultralytics.com/modes/predict/#streaming-source-for-loop
↑ √
local·jupyternotebook으로 ·이동
참고 URL을 이용해서 영상내에서 예측 수행
OpenCV, Ultralytics 설치 확인
#라이브러리 설치
!pip install opencv-python ultralytics
import cv2
from ultralytics import YOLO
Load the YOLOv8 model
model = YOLO("./best.pt")
Open the video file
video_path = "./car.mp4"
cap = cv2.VideoCapture(video_path)
Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 inference on the frame
results = model(frame)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLOv8 Inference", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
breakRelease the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
