-
머신러닝 (기계학습)
이전에 있는 데이터를 학습하여 규칙, 패턴을 찾아 새로운 데이터를 예측하는 과정 -
머신러닝 종류 3가지
- 지도학습
정답이 있는 데이터를 학습,예측분류: 정답데이터가 범주형 (카테고리) -> 클래스 ->클래스 2개 (이진분류), 클래스 3개 이상 (다중분류)
` 회귀: 정답데이터가 연속형 (수치형태) - 비지도학습
정답이 없는 데이터를 학습, 예측군집화, 차원축소 - 강화학습
` 보상을 주는 방향으로 학습
- 지도학습
-
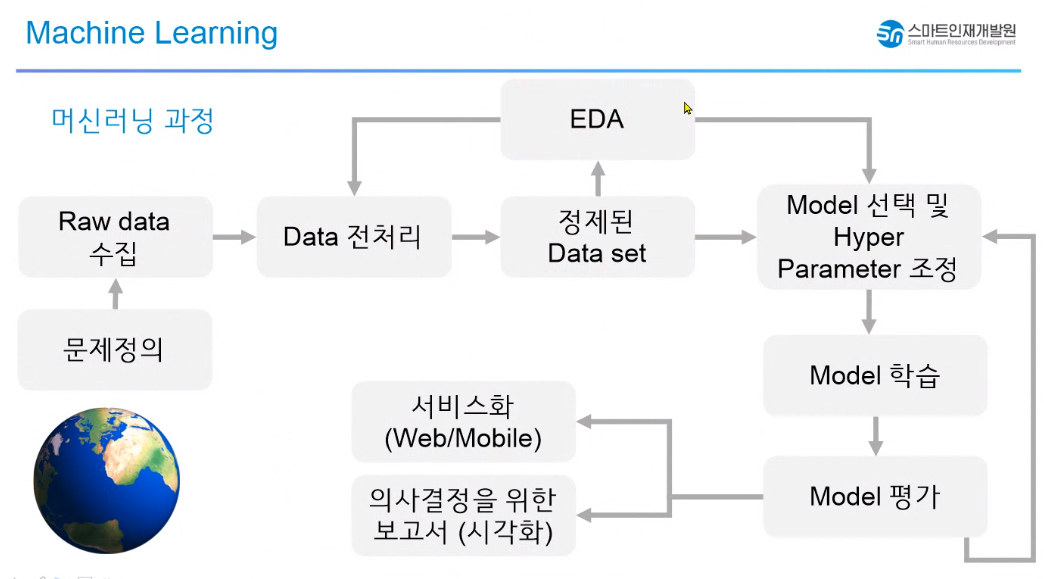
머신러닝 7과정
- 문제정의
- 데이터 수집
- 데이터 전처리 (이상치, 결측치 처리, 특성공학, 단위변환 등)
- EDA 탐색적 데이터 분석(데이터 시각화, 기술통계량/상관관계 확인)
- 모델선택, 하이퍼파라미터 설정
- 모델학습
- 모델평가
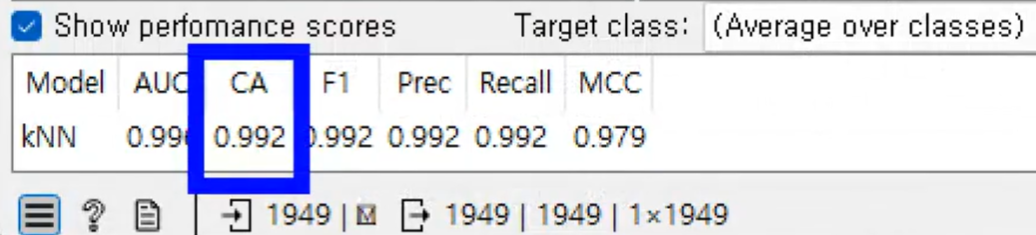
Classification
CA 0 ~ 1


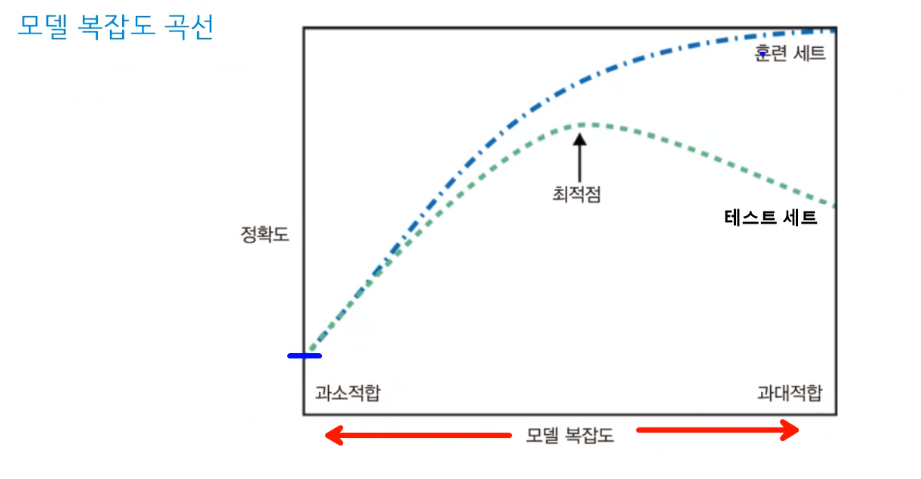
최적점 : 일반화
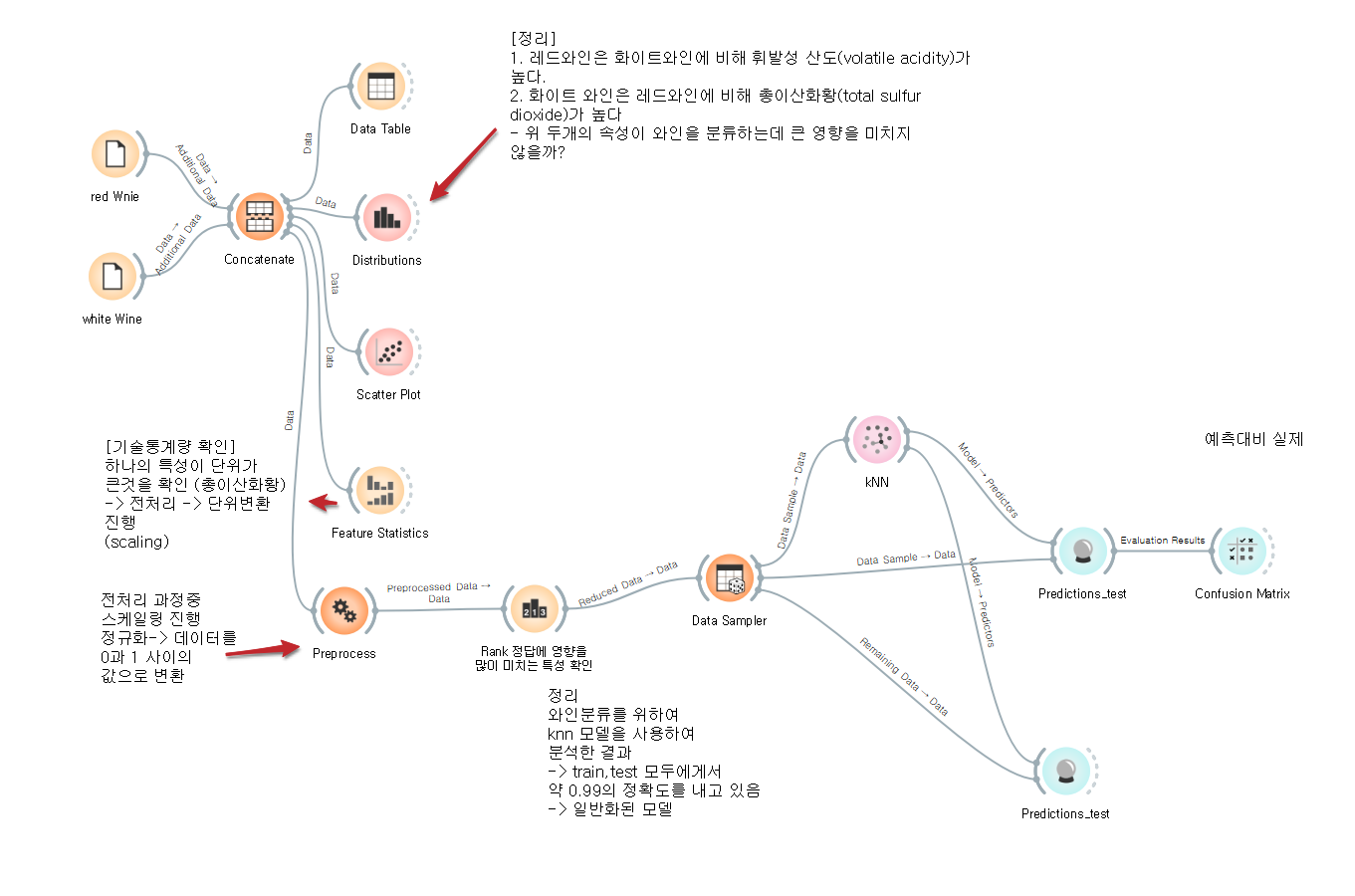
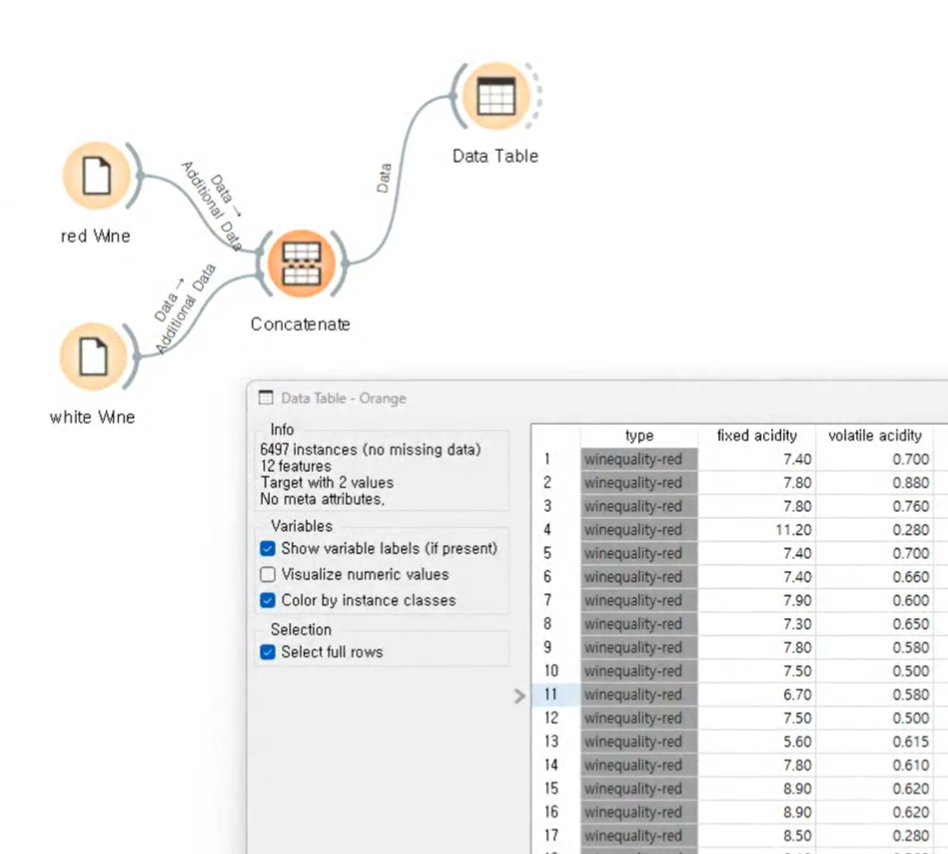
Concat
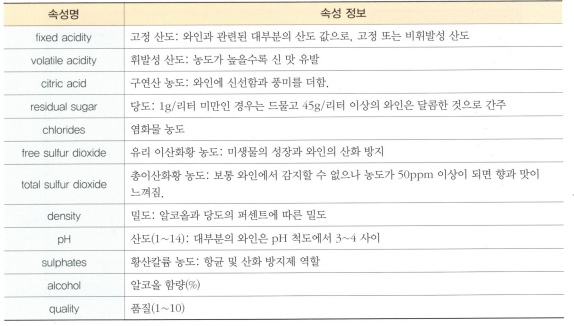
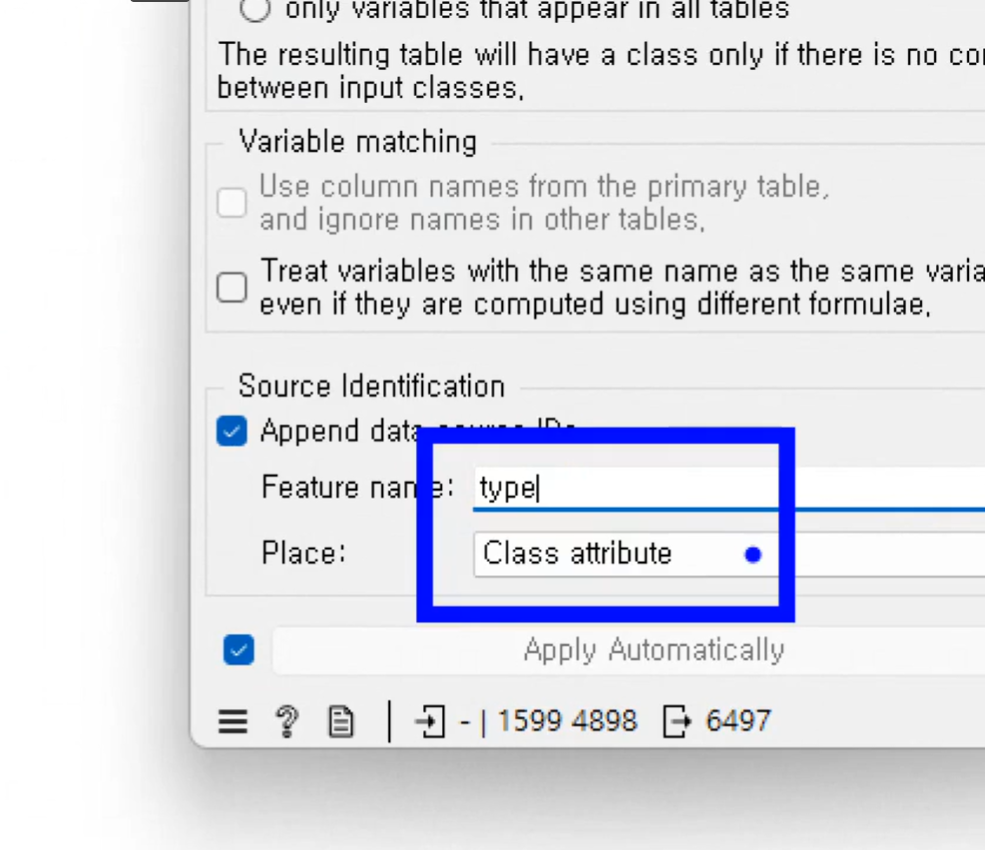
Type 레드 / 화이트 고름 레드 정답으로 함
Class attribute
Data Table로 확인 (병합이 잘 됬는가?)
산점도 - 이상치 확인이 쉽다
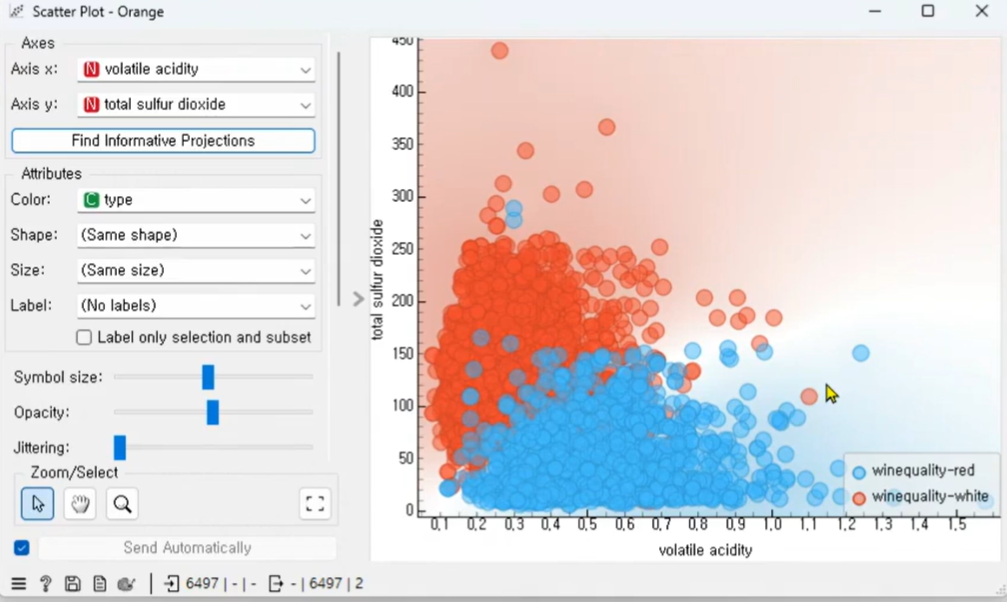
분류가 잘되는 데이터
어떤 컬럼을 사용할지 정함
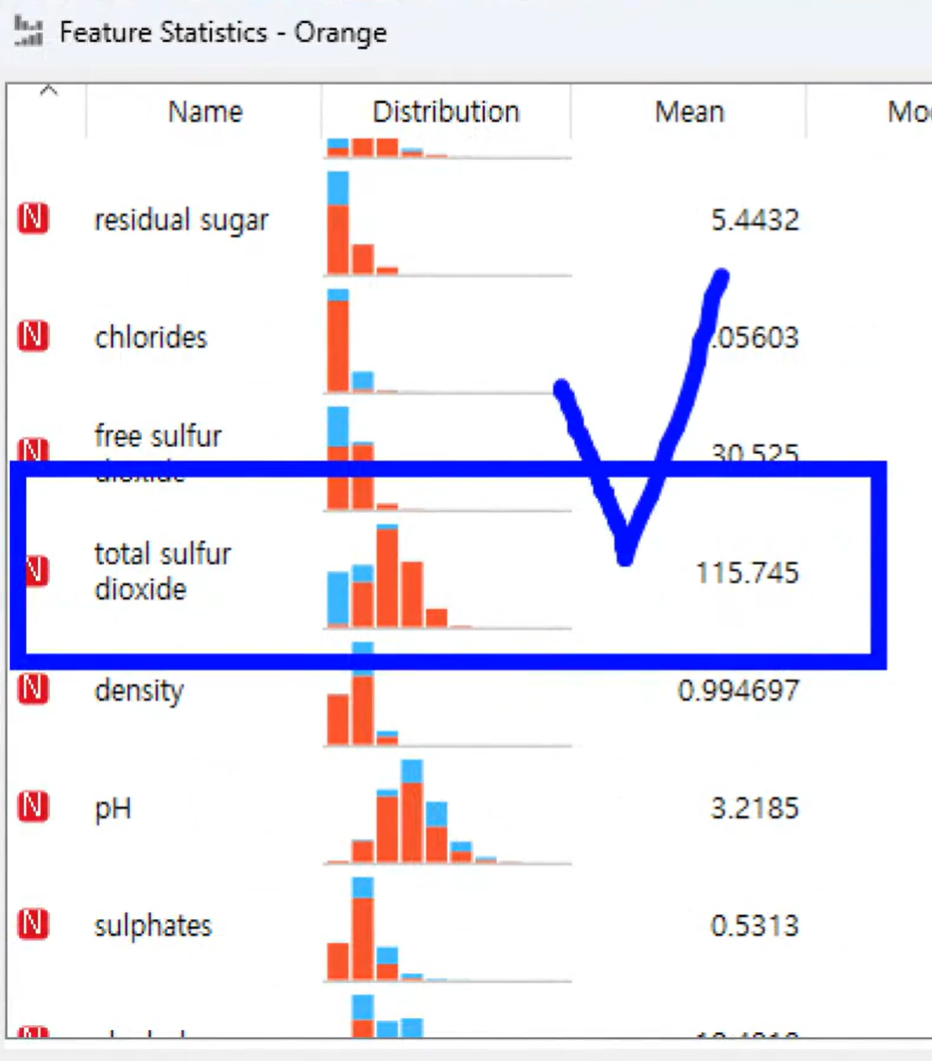
기술통계량 - Feature Statistics - 이상치가 없는지
[기술통계량 확인]
하나의 특성이 단위가( 평균)
큰것을 확인 (총이산화황)
-> 전처리 -> 단위변환
(scaleing)
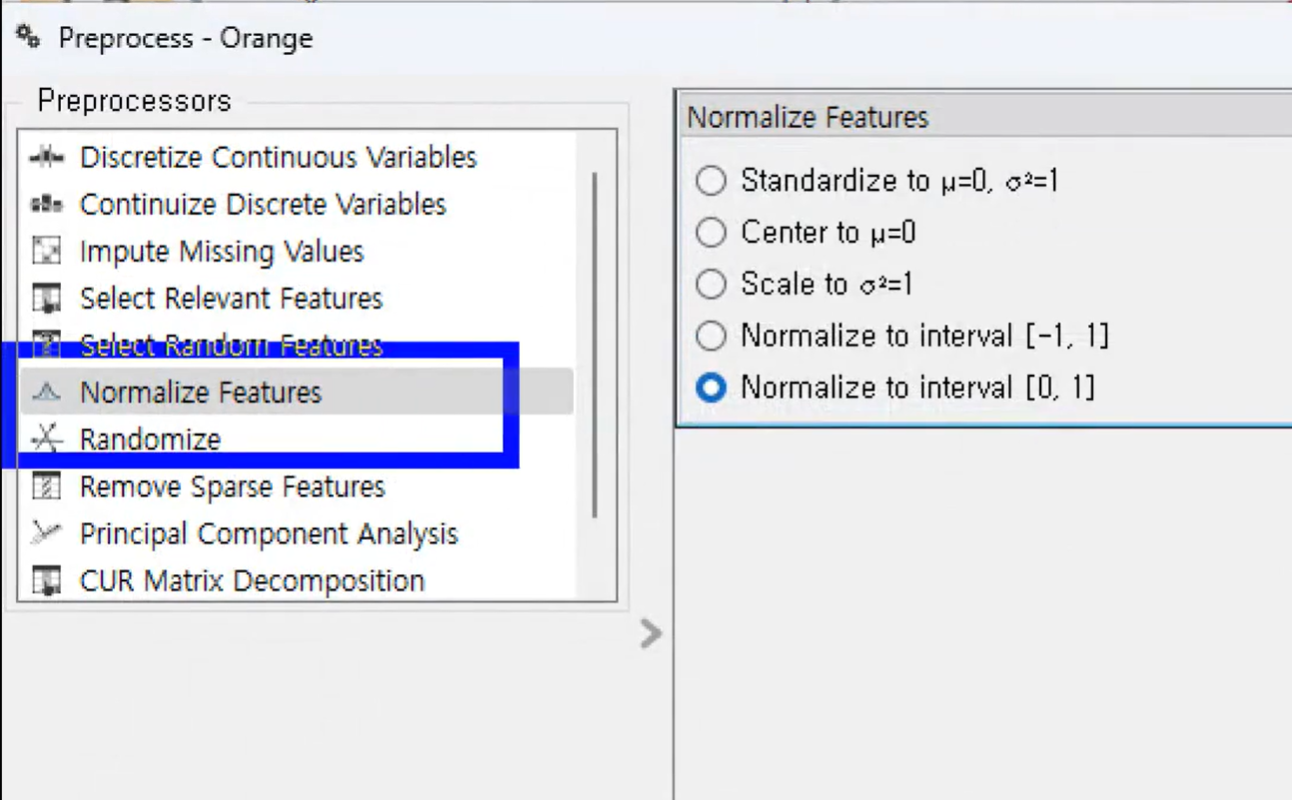
preprocess
전처리 과정중 스케일링 진행
정규화 > 데이터를 0과 1사이의 값으로 변환
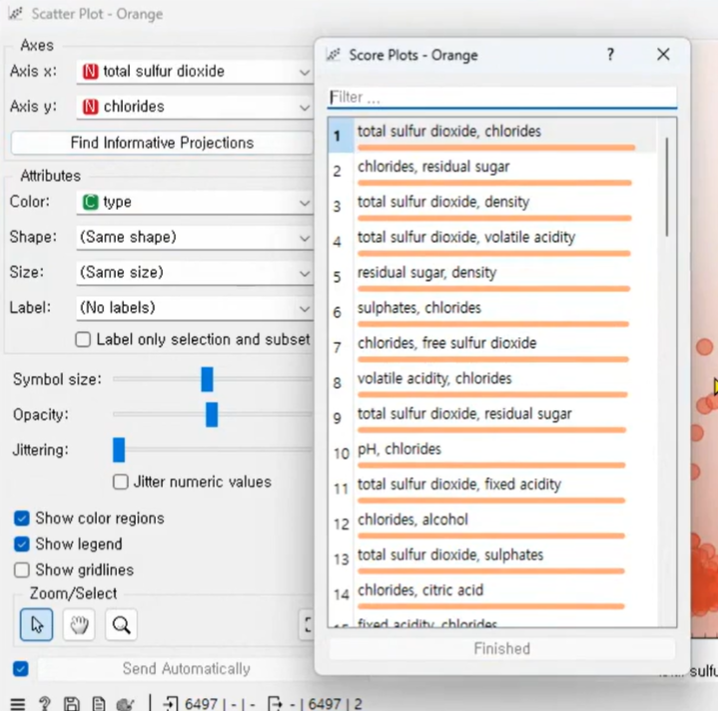
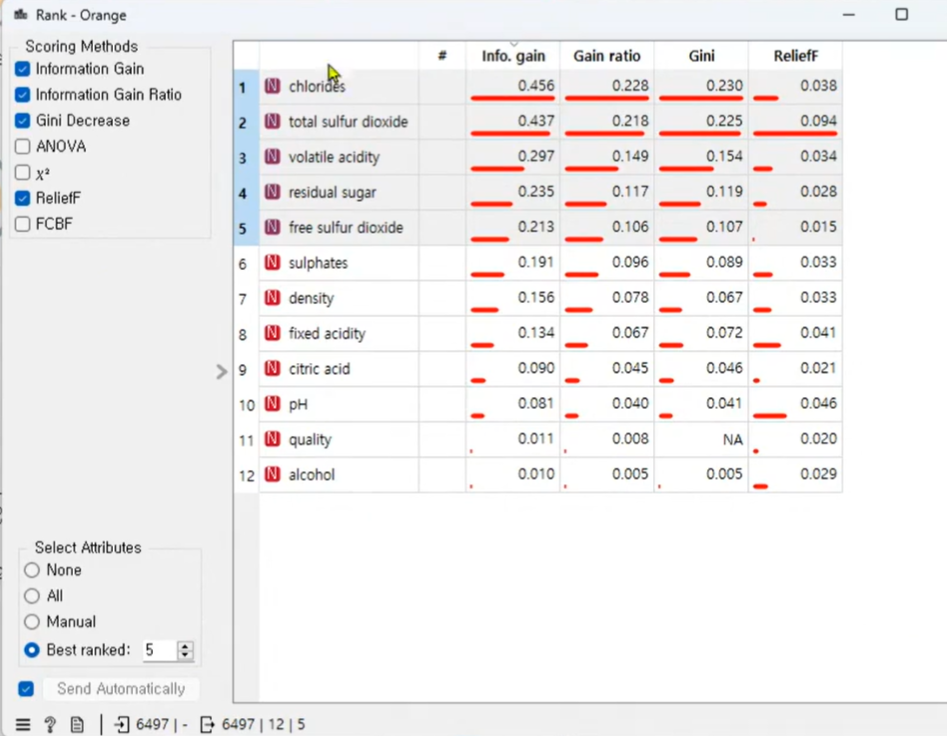
Rank
RelidIF
정답에 영향에 많이 미치는정도 (총 이산화황 데이터가 위로 올라옴을 볼 수 있다.)
연산속도가 빠르고 핵심속성을 가져와서 오차를 줄일 수 있다.
info.gain
정보를 많이 획득하는 컬럼을 우선순위로 정리
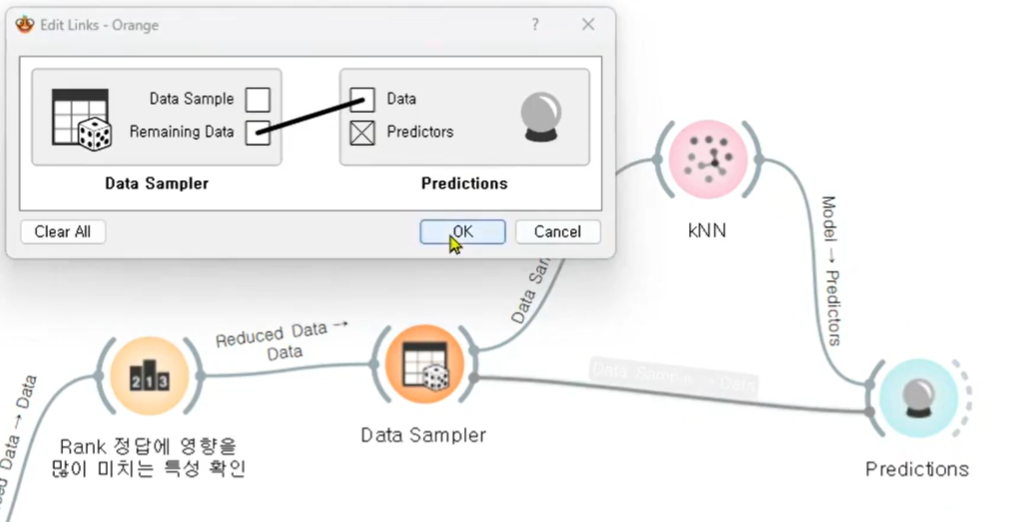
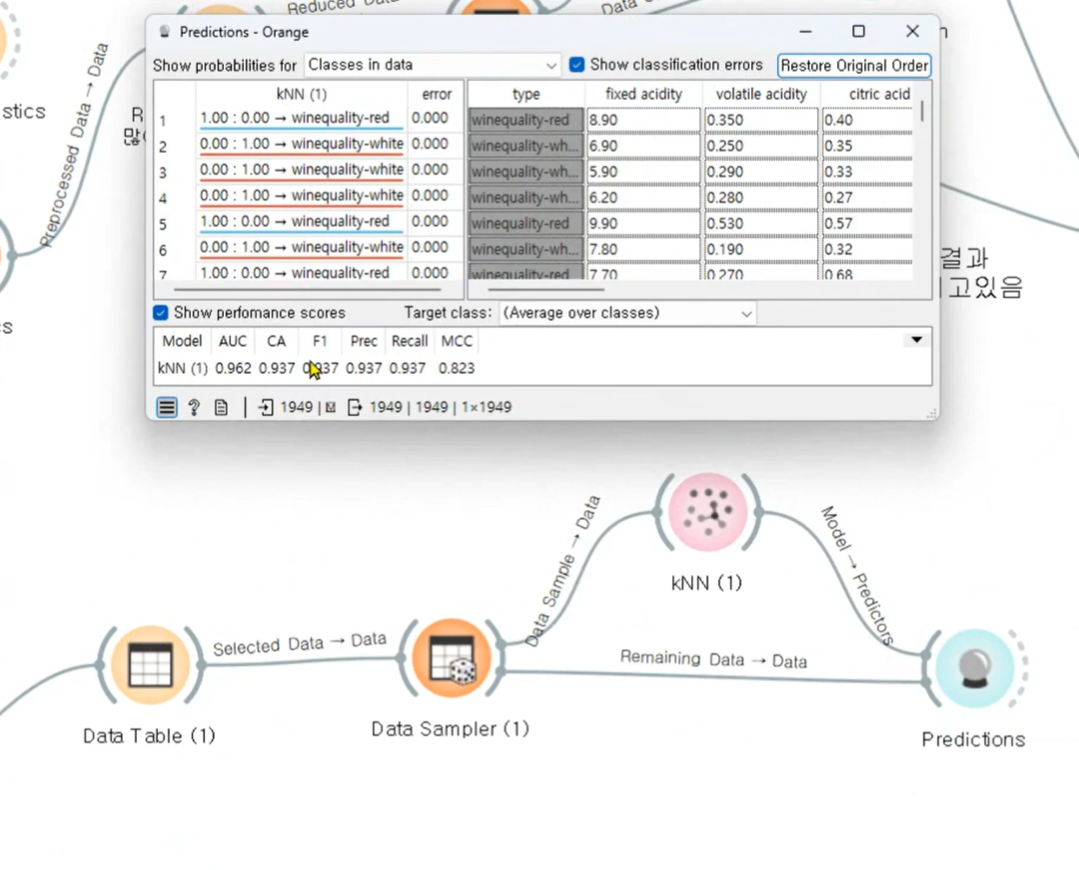
Data Sampler
KNN
70%
Predictions
예측은 30% 데이터로 해야한다.
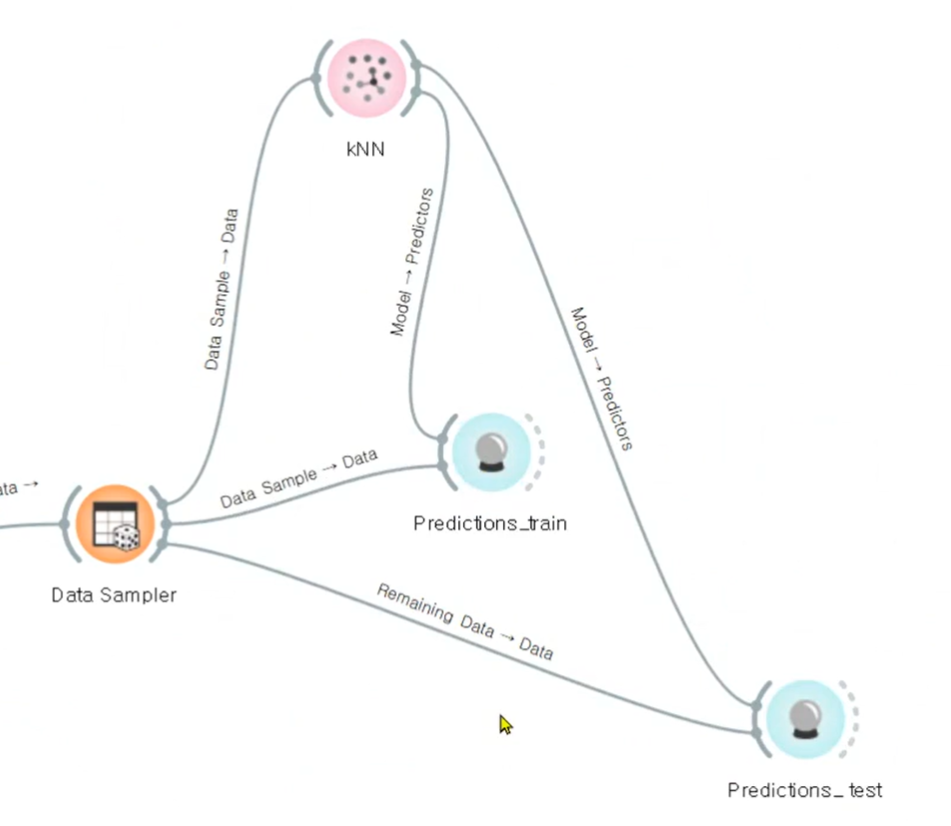
과대적합? 새로운 데이터 왔을때 맞을 수 있을까? 너무 쉬운 데이터로만 하지 않았을까? 데이터 분포라든지..
예측을 한번 더 해본다.
일반화 가능성을 위해서
트레인도 높고 테스트도 높으면 좋은거다
스케일링됬고
특성불류가 잘 분류되어 있는 Rank에서 0.09 인 총 이산화황이 영향을 미쳤구나 분리가 잘 됬구나
과적합은 아니다
정리
와인분류를위하여 knn모델을 사용하여
분석한 결과
- train, test
모두에게서 약 0.99의 정확도를 내고있음- 일반화된 모델이다.

Evaluate
평가
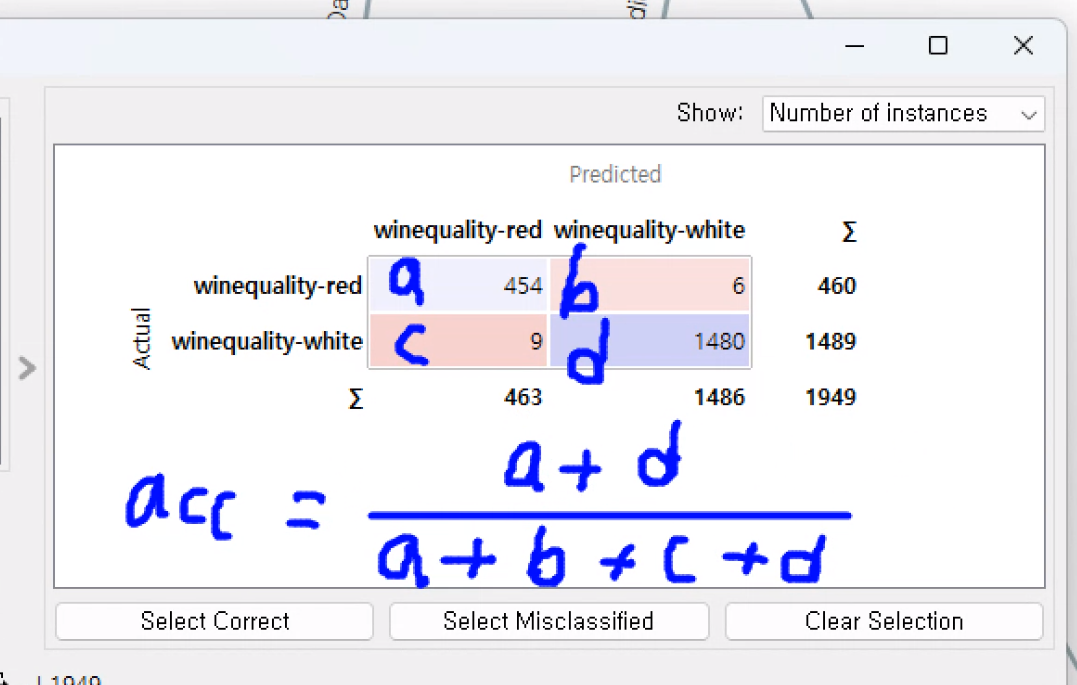
Confusion Matrix
예측한 결과 대비 실제 결과
a,d가 많이 나와야 좋음
전처리 생략 데이터
거리계산하는것 하면 확실히 성능이 올라간다.
- 노멀라이즈
0-1 정규화방법
