· 텍스트 마이닝의 개념과 프로세스를 이해한다.
· 텍스트 데이터를 이용해 머신러닝 학습을 수행할 수 있다.
.
.
텍스트 마이닝이란 ?
-
텍스트 데이터로부터 유용한 인사이트를 발굴하는
Data Mining의 한 종류
(Data Mining : 빅데이터 안에서 규칙이나 패턴을 분석하여 가치 있는 정보를 추출하는 과정) -
자연어 처리 방식(NaturalLanguageProcessing)과 문서처리 방법을 적용
하여 유용한 정보를 추출/가공하는 것을 목적으로 하는 기술
자연어(Nature language)란?
- 인간이 일상생활에서 사용하는 언어
- 인간이 정보를 전달하는 수단
- 특정 집단에서 사용되는 모국어의 집합 (한국어, 영어, 일본어, 중국어 등)
- 인공언어와 대비되는 개념
자연어처리 응용 분야
-
인간의 언어가 사용되는 실세계의 모든 영역
-
정보검색, 질의응답 시스템
· Google, Naver, iphone siri, 갤럭시 bixby, IBM Watson -
기계번역, 자동통역
• Google 번역기, 네이버 Papago, ETRI 지니톡 -
문서작성, 문서요약, 문서 분류, 철자 오류 검색 및 수정, 문법 오류 검사 및
수정
사소하게 다 나눠서하면 오버피팅
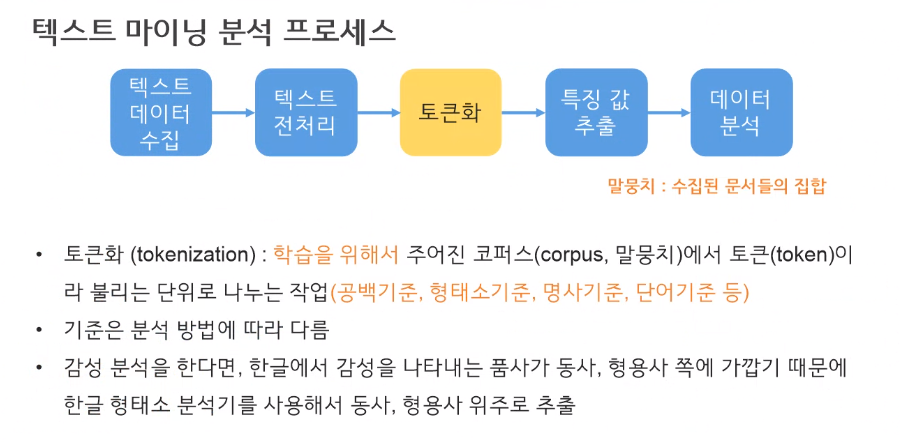


많이 나오는 단어를 찾아야한다.
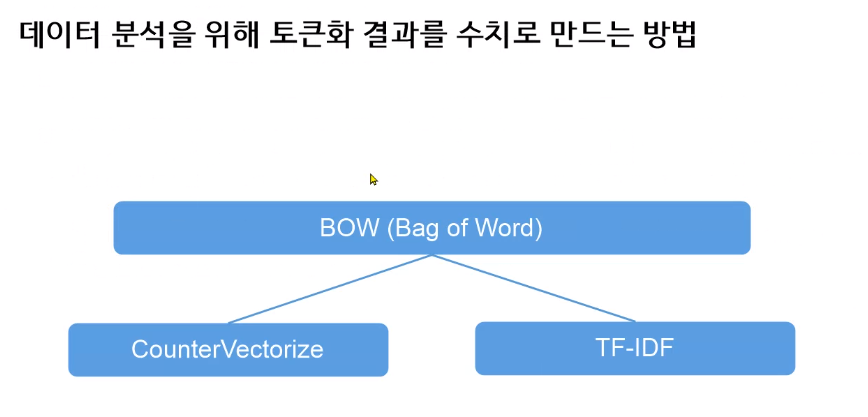
벡터화[중요]
BOW 방식 두가지
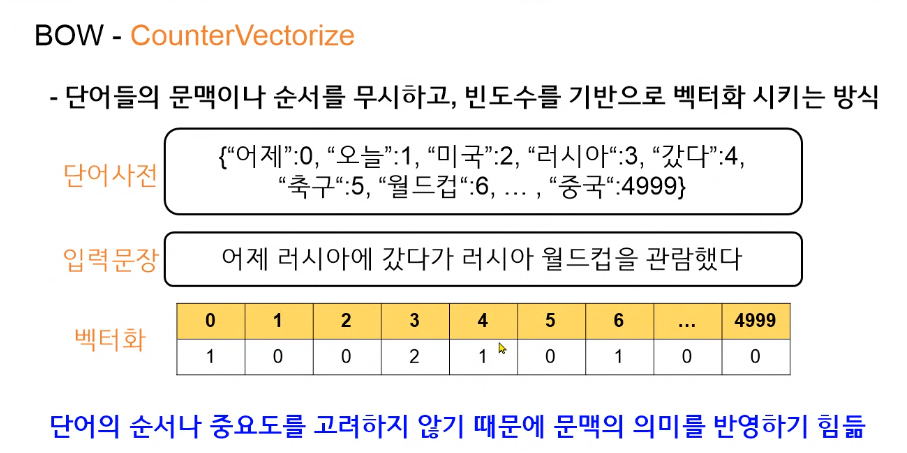
•단순 카운트기반의 벡터화
-> 카운트 벡터화는 카운트 값이 높을수록 중요한 단어로 인식(분별성 X)
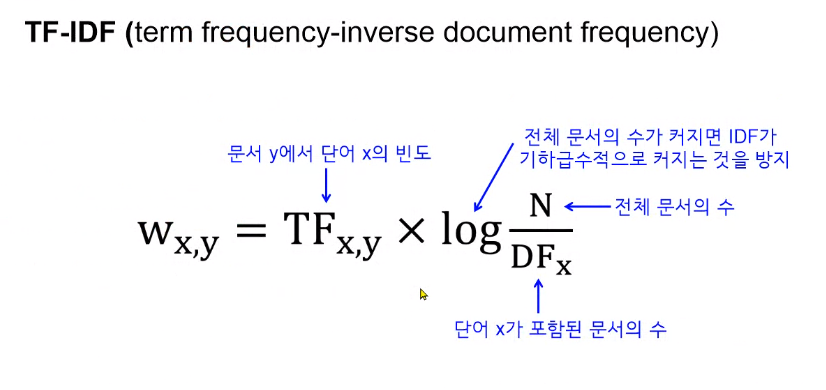
.TF-IDF(Term Frequency - Inverse Document Frequency)
-> 카운트 벡터화 보완 (패널티 부여)
워드클라우드
문서에서 중요한 부분 요약해줌


성장하는 하루가 되자