생성자 : 잘 생성하려고 노력합니다. (도둑)
판별자 : 0,1 잘 분류할려고 노력합니다. (경찰)
0.이미지 생성모델 원리 이해
- GAN(Generative Adversarial Network) :
적대적생성신경망으로 생성자와 판별자 2개의 딥러닝 네트워크를 학습시켜 이미지를 생성한는 기법 - Diffusion : 잠재공간에서 정보가 확산되는 수학적 모델을 개념으로 이미지를 생성하는 기법
GAN
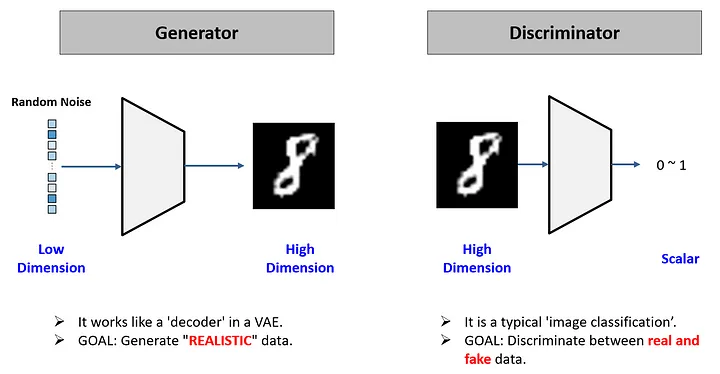
- 생성자 : 일종의 decoder 역할을 하는 모델
랜덤한 숫자 벡터에서 이미지를 생성하는 역할을 수행
목표는 판별자가 헷갈리 정도로 정교한 이미지를 만드느것 - 판별자 : 이미지 분류기(이진분류)로 진짜 이미지 (1)와 가짜 이미지(0)를 분류한다. 목표는 생성자가 만들어낸 이미지를 잘 분류하는것
생성자 훈련 프로세스
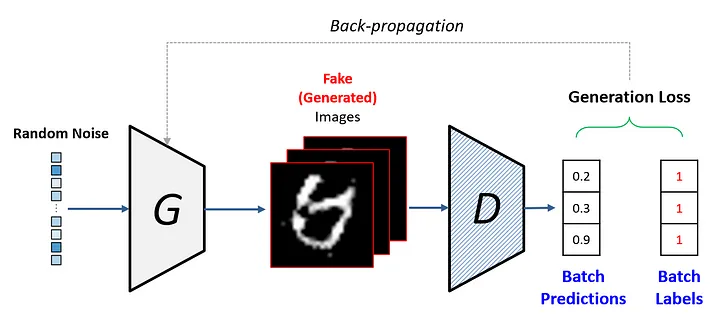
처음엔 잘 못만듭니다.
loss - 손실값
가짜가 진짜와 얼마 차이나는지 loss값을 가지고 생성자에 업데이트
차이가 얼만지 알기때문에 다음엔 조금더 정교한 이미지가 됩니다.
학습을 별개로 진행됩니다.
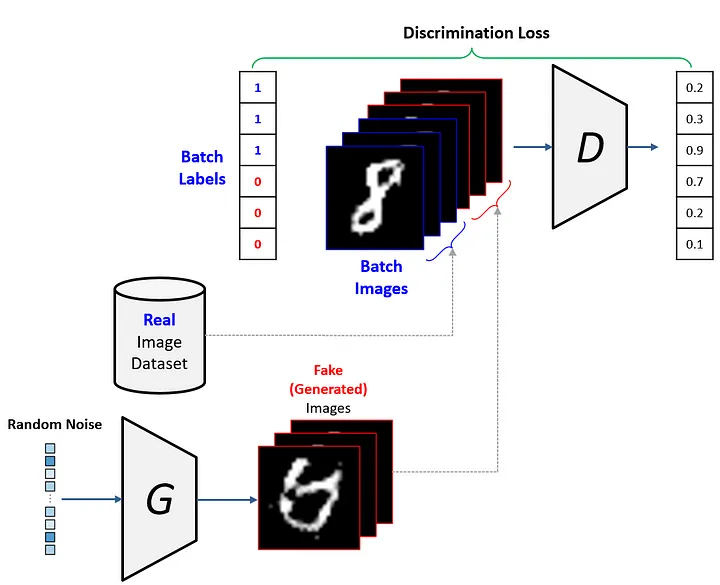
판별자 학습 - 진짜 , 가짜 구분하는 2진분류학습 (절반 , 절반)
생성자 막 만듬 가짜 - 진짜 차이값 loss => 생성자에게 줍니다.
(계속 반복)
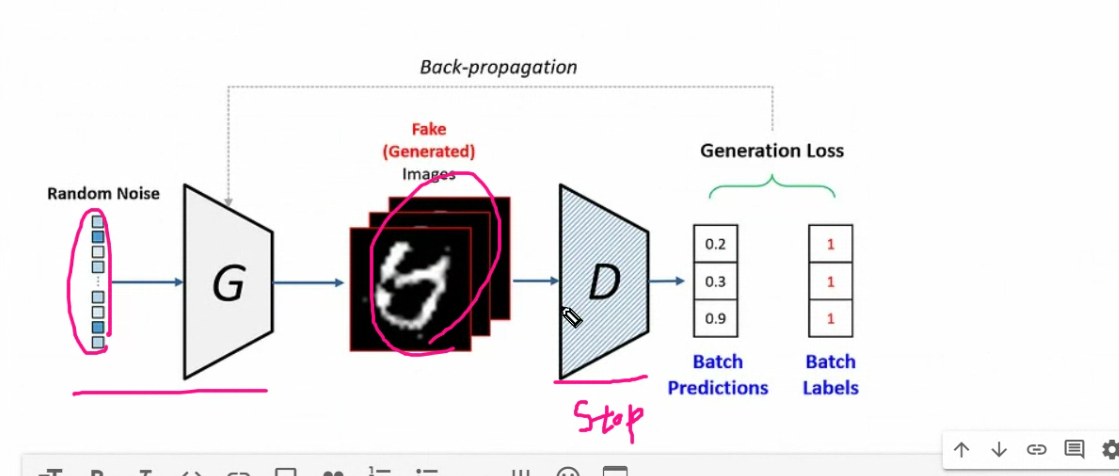
판별자도 업데이트위해서 D (stop 풉니다.) 다시 업데이트
다시 반복
생성자가 만든게 판별하기 어려운 시점
0.5양성클래스, 음성클래스인지 모호할때
랜덤한 숫자부터 아무것도 만듭니다.
기본 GAN부터 시작해서 원하는 설정값
디퓨전모델
Diffusion
- 특정 공간에 존재하는 분자 그룹에 일정한 힘이 여러번 가해지면 확산하는 패턴이 생긴다.
- 여러번 가해지는 힘의 크기를 알고 있으면 반대로 원래 분자그룹 형태로 복원하는게 가능하다.
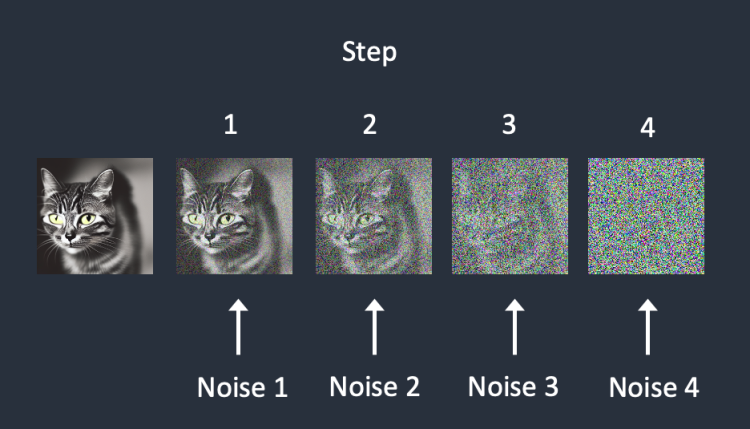
- 이미지의 픽셀들을 분자처럼 생각하고 일정한 노이즈 값(힘)을 반복적으로 연산(더하기,빼기)하여 완전한 노이즈 이미
지로부터 원래 이미지로 생성하는 과정을 적용
Diffusion 모델의 학습/예측 프로세스
- Forward Ddiffusion : 학습을 수행하는 프로세스
- Reverse Diffusion : 예측(이미지생성)을 수행하는 프로세스
- 학습을 하는 모델을 잡음 예측기(noise predictor)라고 부르며 U-net모델을 활용한다.
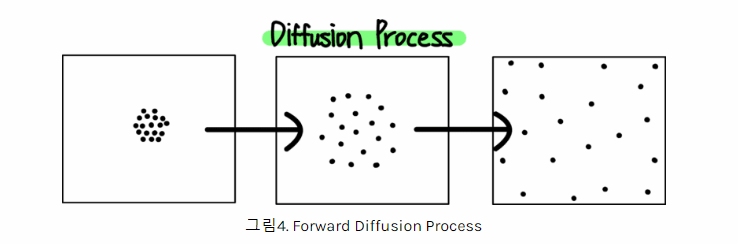
힘을 줘서 퍼지게 할 수 있다는 개념 다시 모을 수 있다는 개념
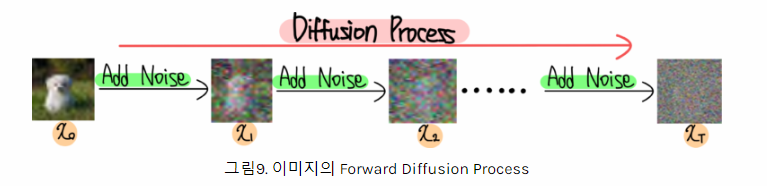
픽셀 - 분자 에 '노이즈' 주면 순수한 값
어느정도 노이즈가 껴있는지 알고 빼내면서 시작합니다.
쏘카
Skip Connection 을 넣어 만들었습니다.
완전한 노이즈가 있을때 거꾸로 돌립니다.
실제 노이즈 값
ex) 100 > 100(합산 200) > 80(합산 280)
잡음 예측기가 예측하는 노이즈값 비교합니다.
ex) 80 > 170(합산 200-170 = 30) > 270(합산 280 -270 = 10)
잡음 예측기의 학습과정
노이즈를 조금씩 추가합니다.
잡음이 얼마나 있는지 예측합니다.
- 원본 이미지에 일정한 noise를 추가하여 noise한
이미지를 생성 - 잡음 예측기에 입력으로 집어 녛어 얼마나 noise값이
추가된건지 예측 수행 - 모델의 예측 값(잡음의 정도)과 실제 noise값의 차이
(loss)를 계산하여 모델을 업데이트 - 위 과정을 반복적으로 진행하면 특정 이미지를 집어 넣으면 noise값이 얼마나 추가되었는지 예측하는 모델(잡음예측기)가 완성됨
잡음 예측기의 예측과정
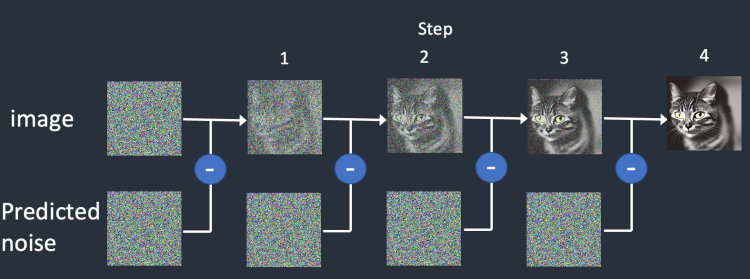
- 완전한 noise 이미지를 준비(랜덤)
- 학습된 잡음 예측기에게 이미지를 입력한다.
- 모델이 예측한 잡음 정도를 입력 이미지에서 제거한다
- 조금 더 선명한 이미지가 생성된다.
- 선명해진 이미지를 다시 입력으로 활용하여 위 과정을 반복한다.
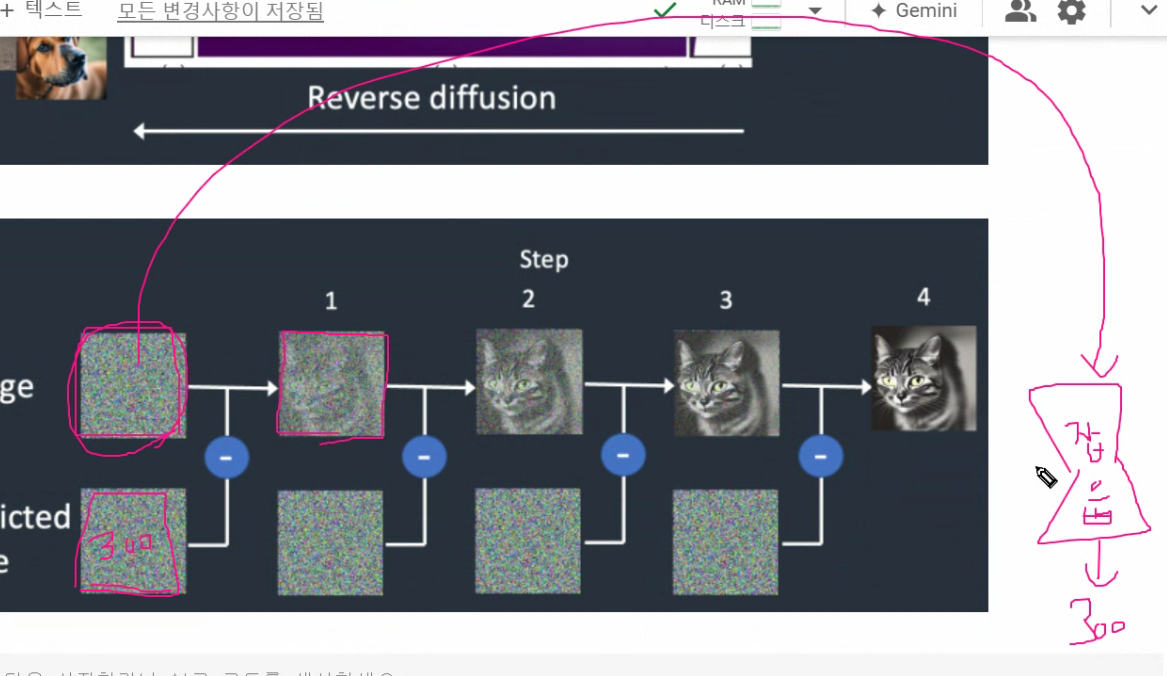
완전 램덤 노이즈 > 잡음예측기 예측시 300?정도
이미지에 다시 뺍니다. 선~명
조금 더 형태가 잡힌 사진
반 to the 복
분자가 퍼졌다가 다시 모이는 과정
학습의 효율성을 위해서 추가한 방법
- 오리지날 이미지의 경우 크기가 크기 때문에 연산량이 많아 학습과 예측에 시간이 많이 걸린다.
- 학습 및 예측의 효율성을 위해 가변 자동 인코더(VAE, Variational AutoEncoder) 개념을 도입한다
- 잡음 예측기에 오리지널 데이터를 집어 넣지 않고 인코더를 통해 주요한 정보만 압축된 잠재공간벡터(Latent space vector)를 넣어서 연산량을 줄였다
- 위 방식으로 학습된 잡음 예측기를 활용해 이미지 생성을 하면 역시 압축되고 노이즈가 제거된 잠재공간벡터가 만들어지기 때문에 사람들이 아는 픽셀단위 이미지로 만들어내기 위해 디코더를 활용하게된다(후처리)
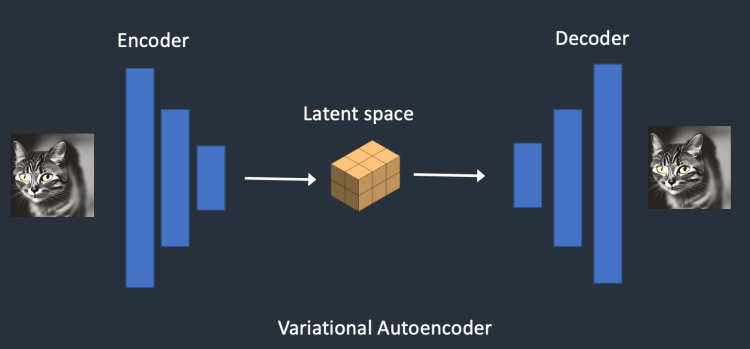
고양이의 특이한 정보를 싹 모읍니다. 압축
▶️◀️
픽셀단위 이미지 디코더
Diffusion 모델의 다양한 활용법
- 기본 Diffusion 모델의 구조는 학습된 이미지 중에 랜덤하게 만들어져서 제어가 어렵다
- 사용자가 원하는 정보(condition:조건)를 잠재공간(Latent space)에 추가하여 맞춤형 이미지를 만들어 낼 수 있도록 모
델이 발전했다
정보를 녹입니다. - 잠재공간
노이즈 예측기가 해당방향으로 발전시켜서 모델을 만듭니다.
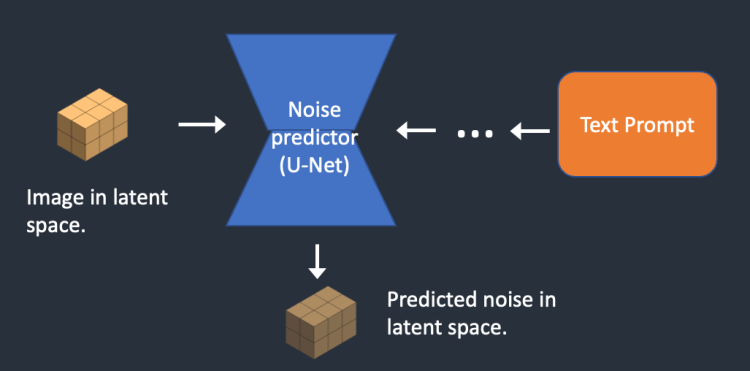
-
완전 랜덤한 정보이나 text prompt
결합해서 노이즈가 없어지게되기때문입니다. -
텍스트기반 이미지생성
-이미지 기반 이미지
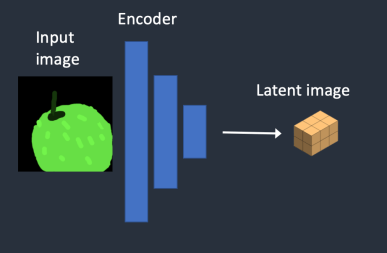
-
엉성한 사과이미지 > 잠재벡터이미지로 만듭니다.
-
잠재벡터이미지를 시작점으로 만듭니다. (형체정보)에서 노이즈 만듭니다.
(컨디션)((조건으로 사용))
이미지 to 이미지
이미지 부분을 다시 이미지 만듭니다.
