퍼셉트론 Perceptron
- 인공신공망을 만들려고 했습니다.
- 퍼셉트론은 선형모델기반입니다.
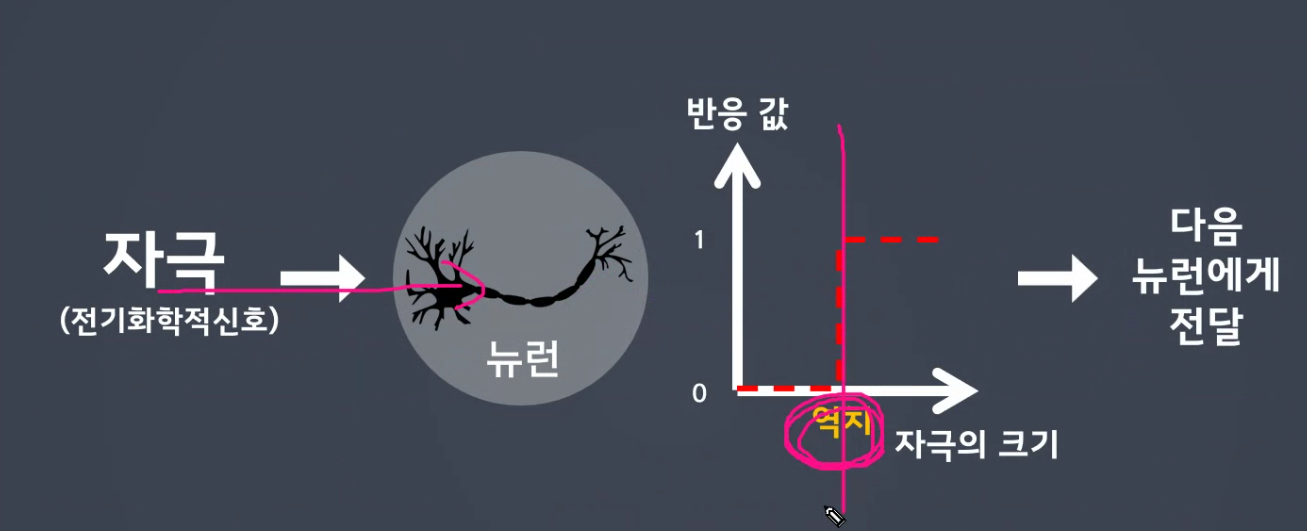
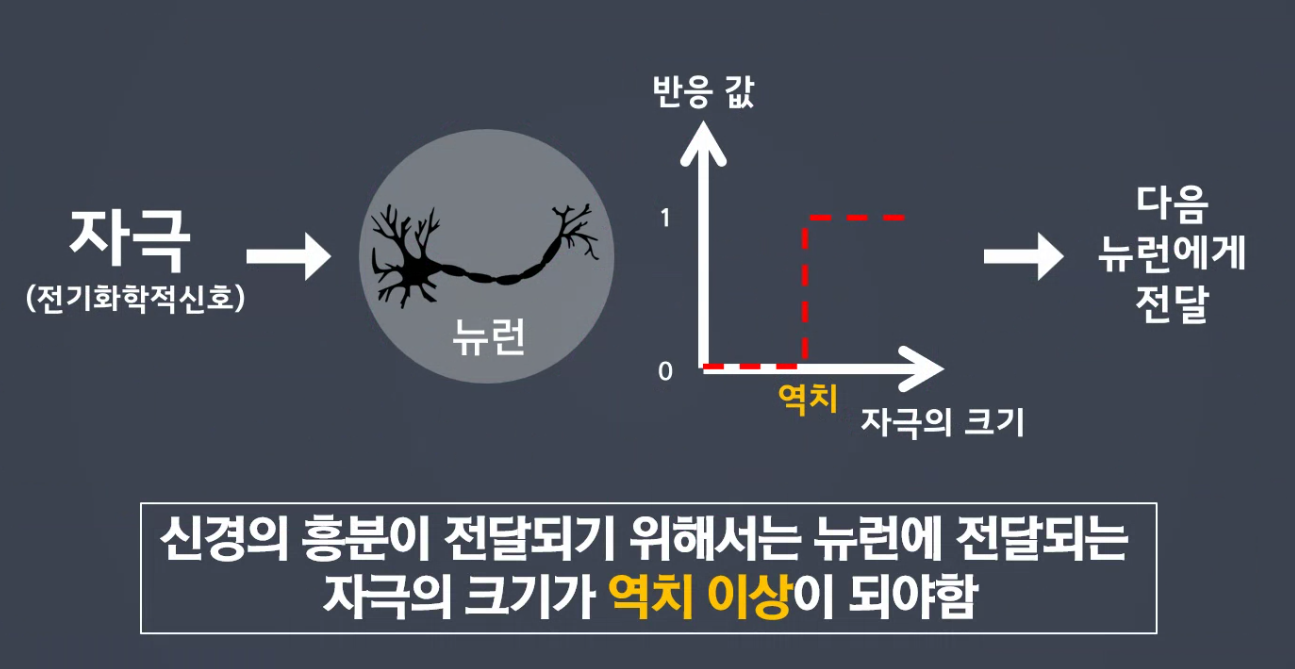
- 자극(화학자극) > 뉴런(화학변화) > 필터(역치 자극의 크기) > 뉴런(화학변화) >
뉴런을 수학적모델
병렬적 다층 구조 - 레이어
수학적모델 - 선형함수
역치 - 활성함수(역치개념)
일정 역치 이상이 되어야지만 다음 퍼셉트론에게 전달이 가능합니다.
선형모델 - 입력,출력

식(역치)<=0 이면 0
식(역치) >0 이면 1
기준값이상일때만
1 > 값 그대로 전달
0 > 값 소멸, 비활성화 모방
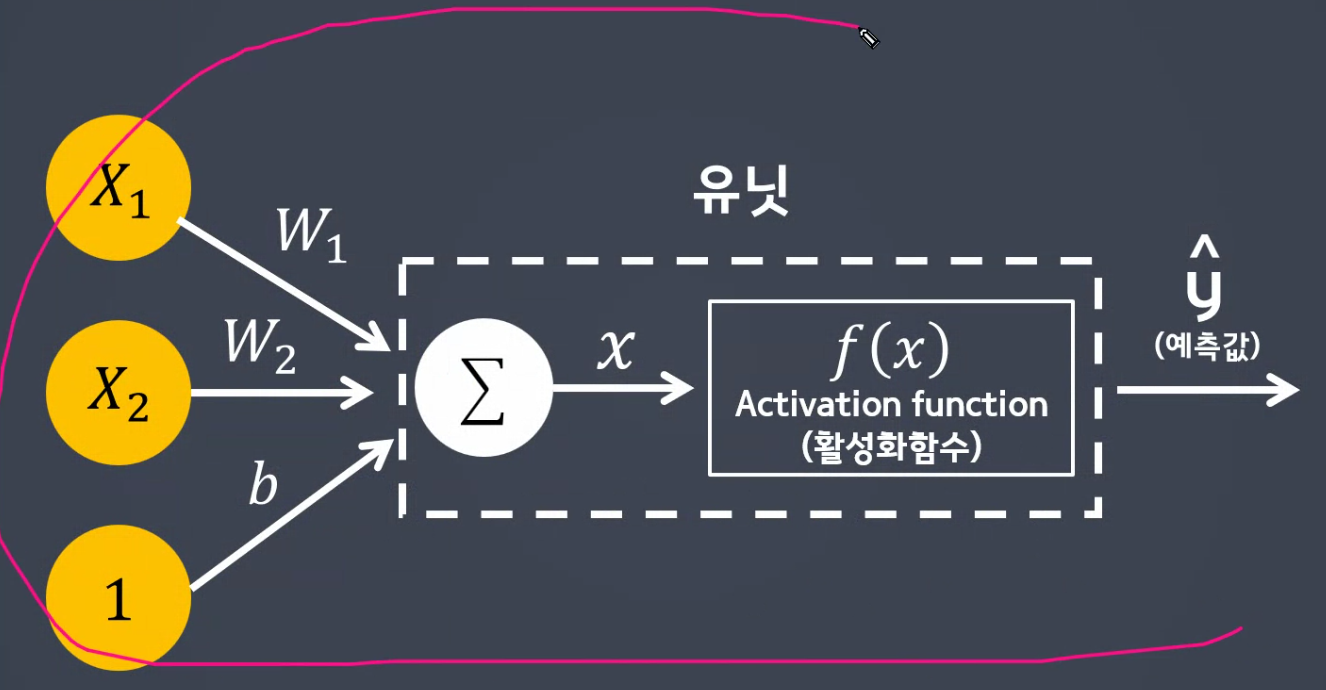
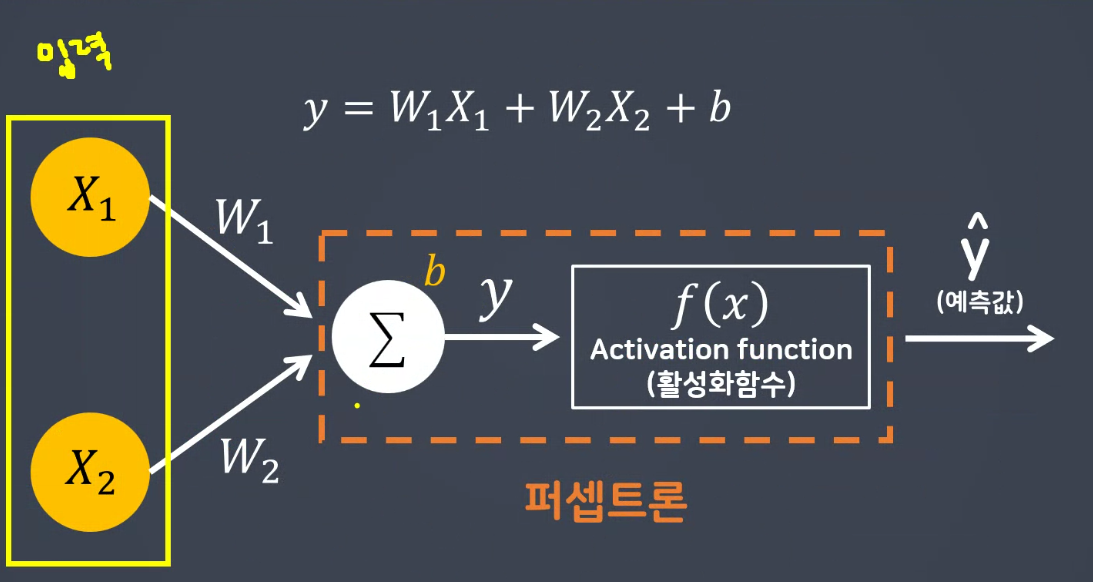
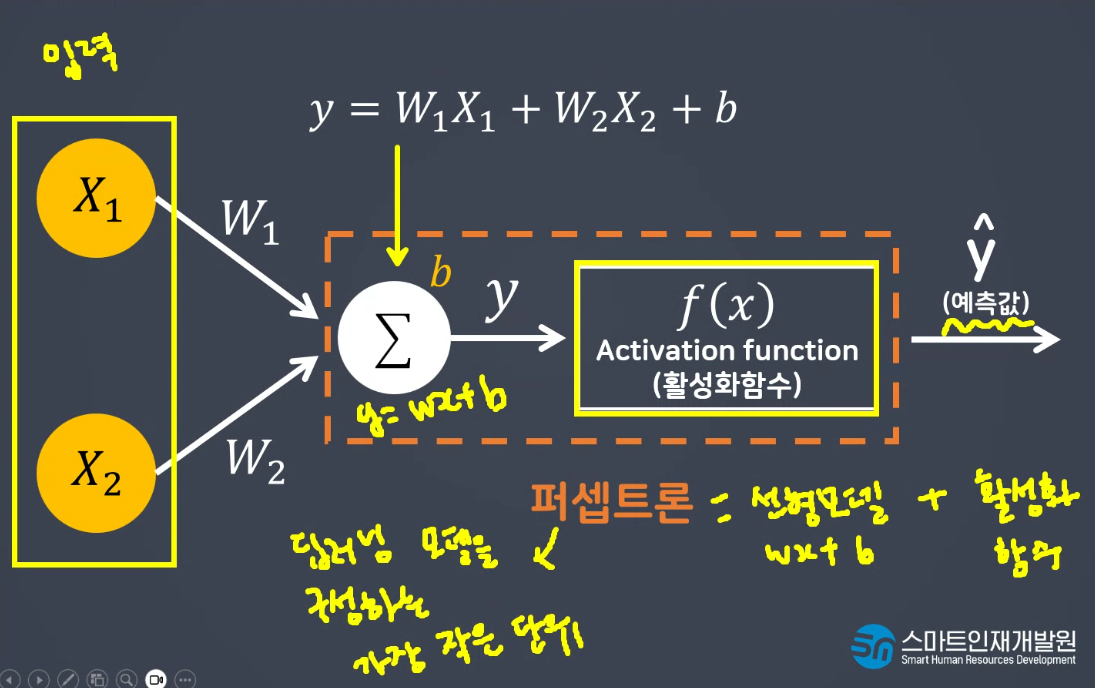
퍼셉트론 단위 : 유닛
입력데이터 * 가중치 sum =>
선형모델 <= 0(비활성) or >0(활성) =>
예측값(y-hat)
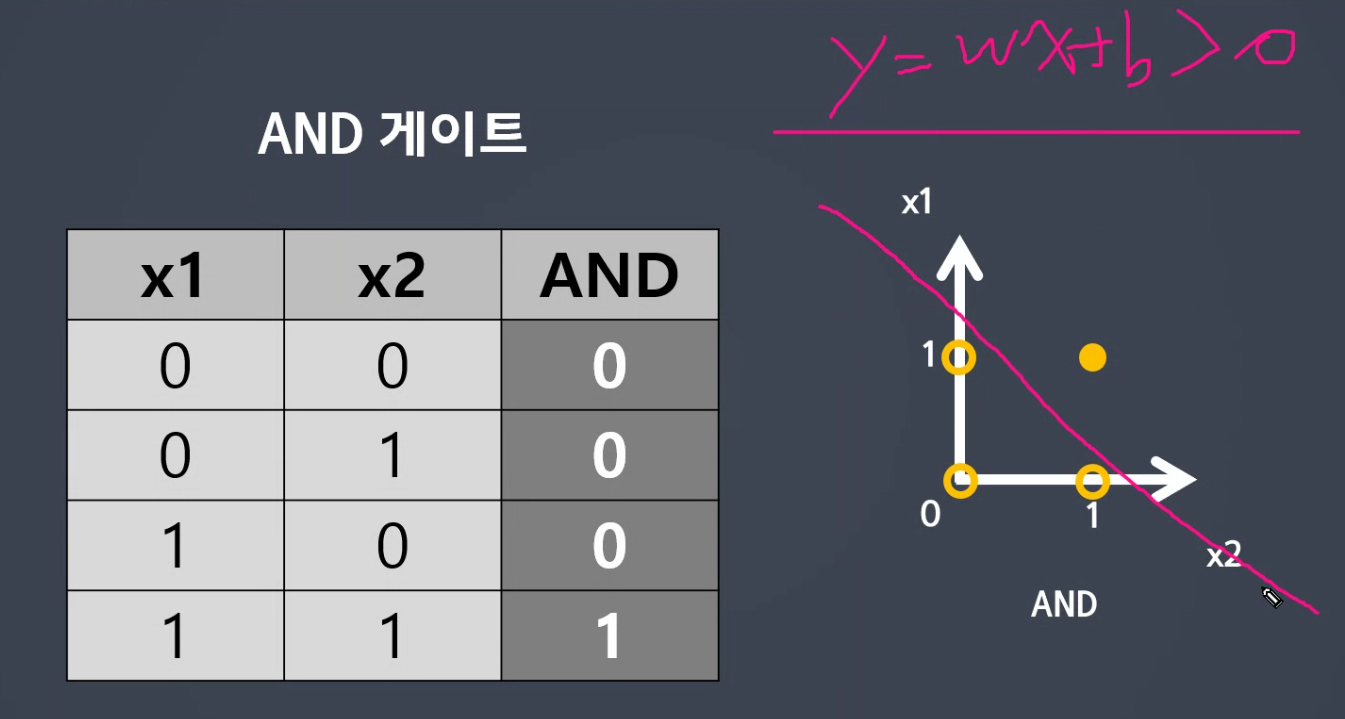
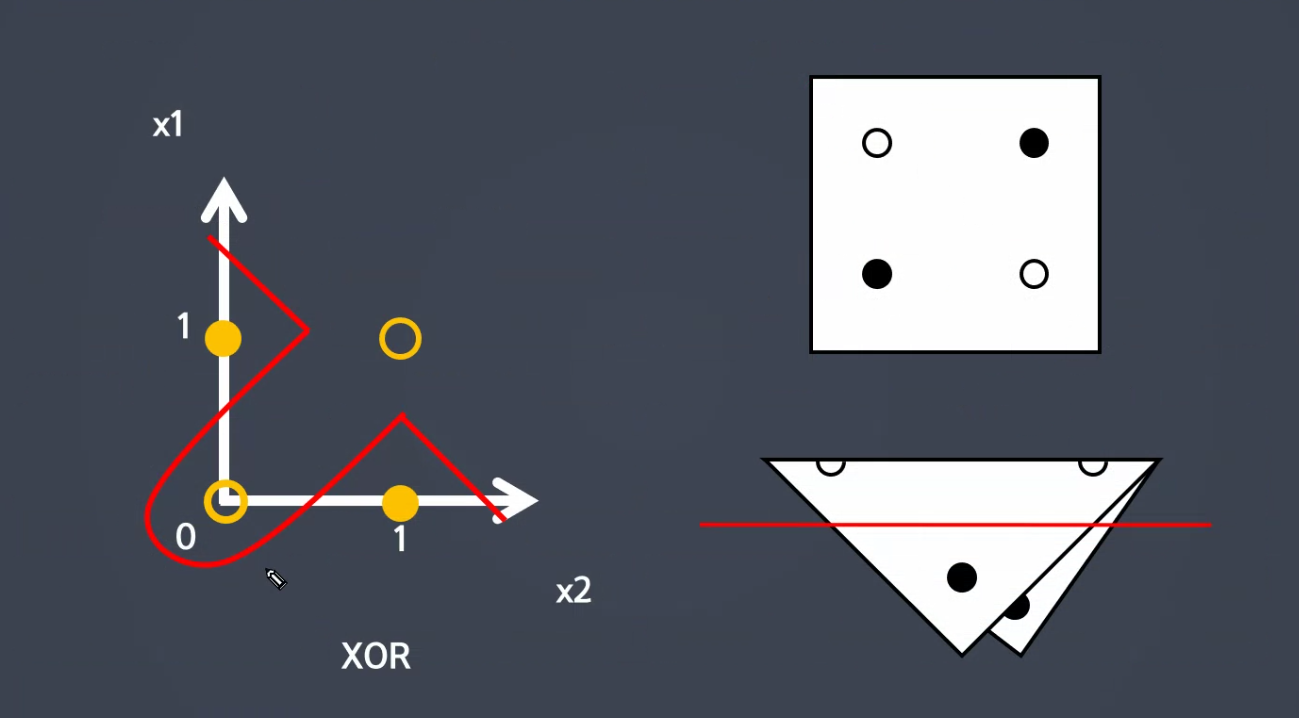
선형으로 생각하면 결정경계선을 만듭니다.
구분하는 능력있습니다.
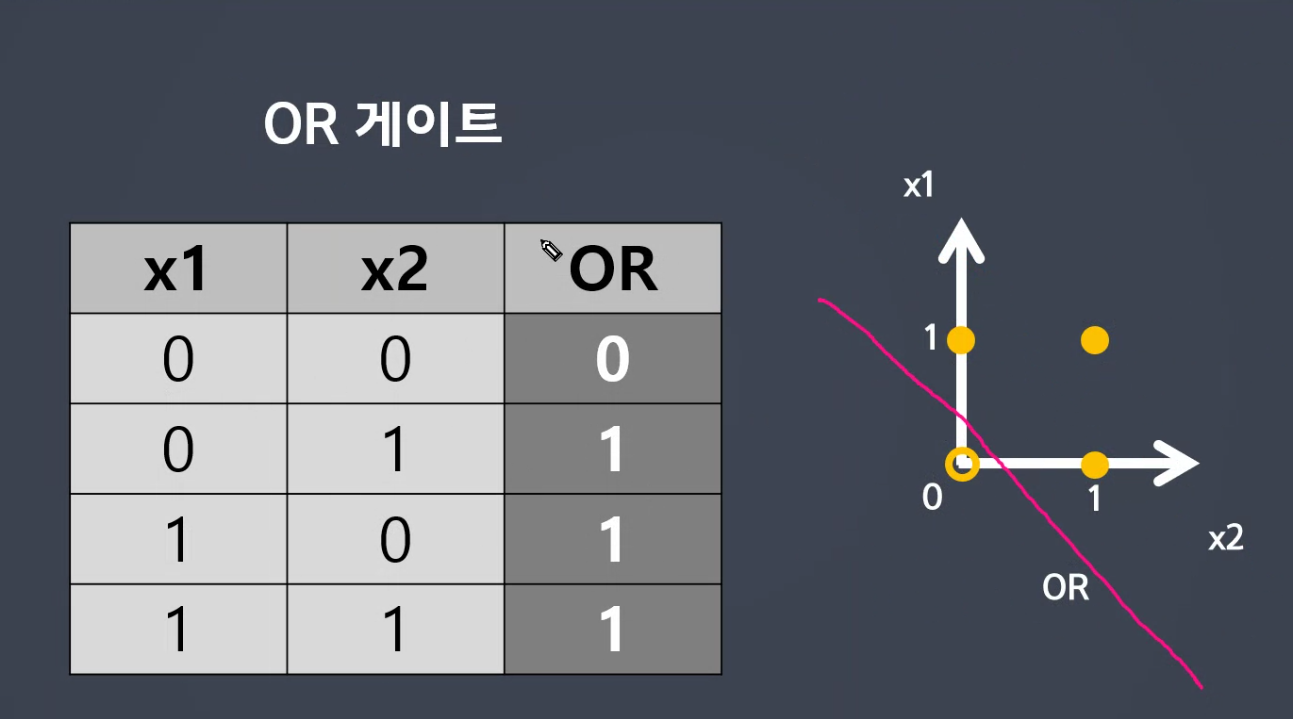
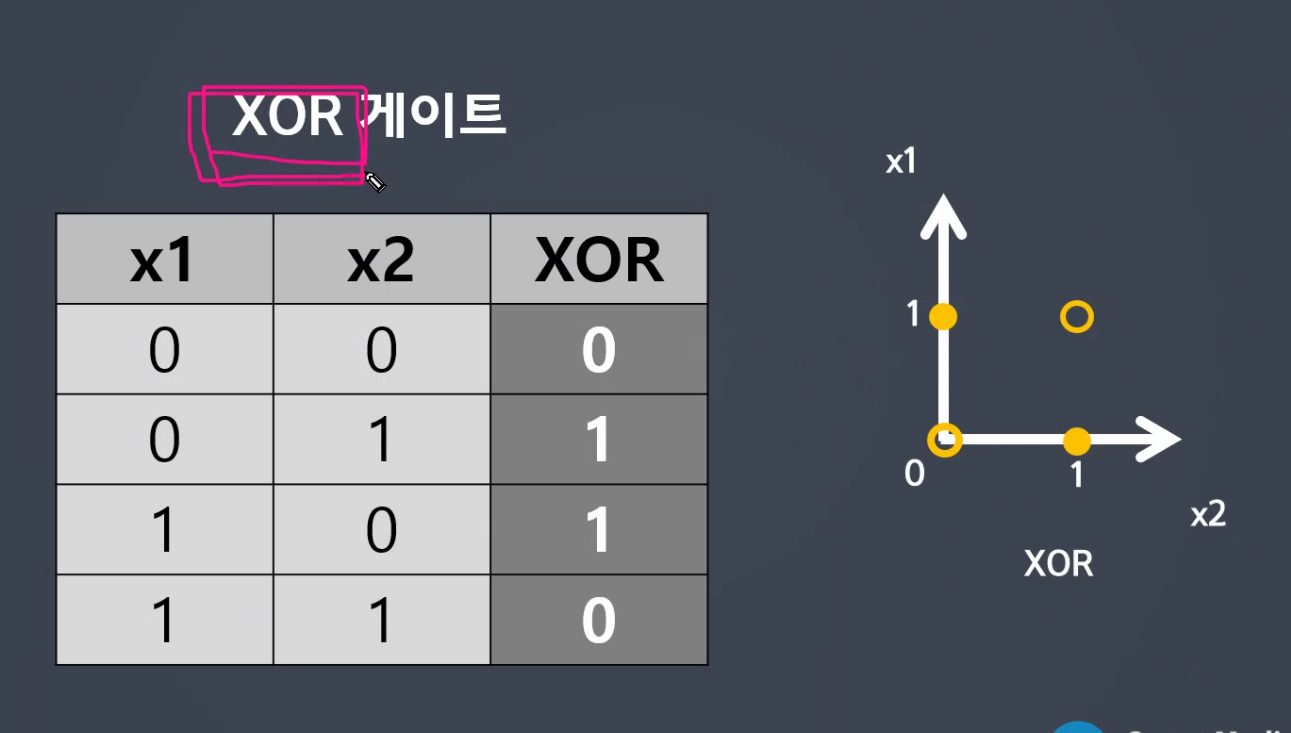
XOR은 구분못합니다.
- xor : 1개라도 on이면 true
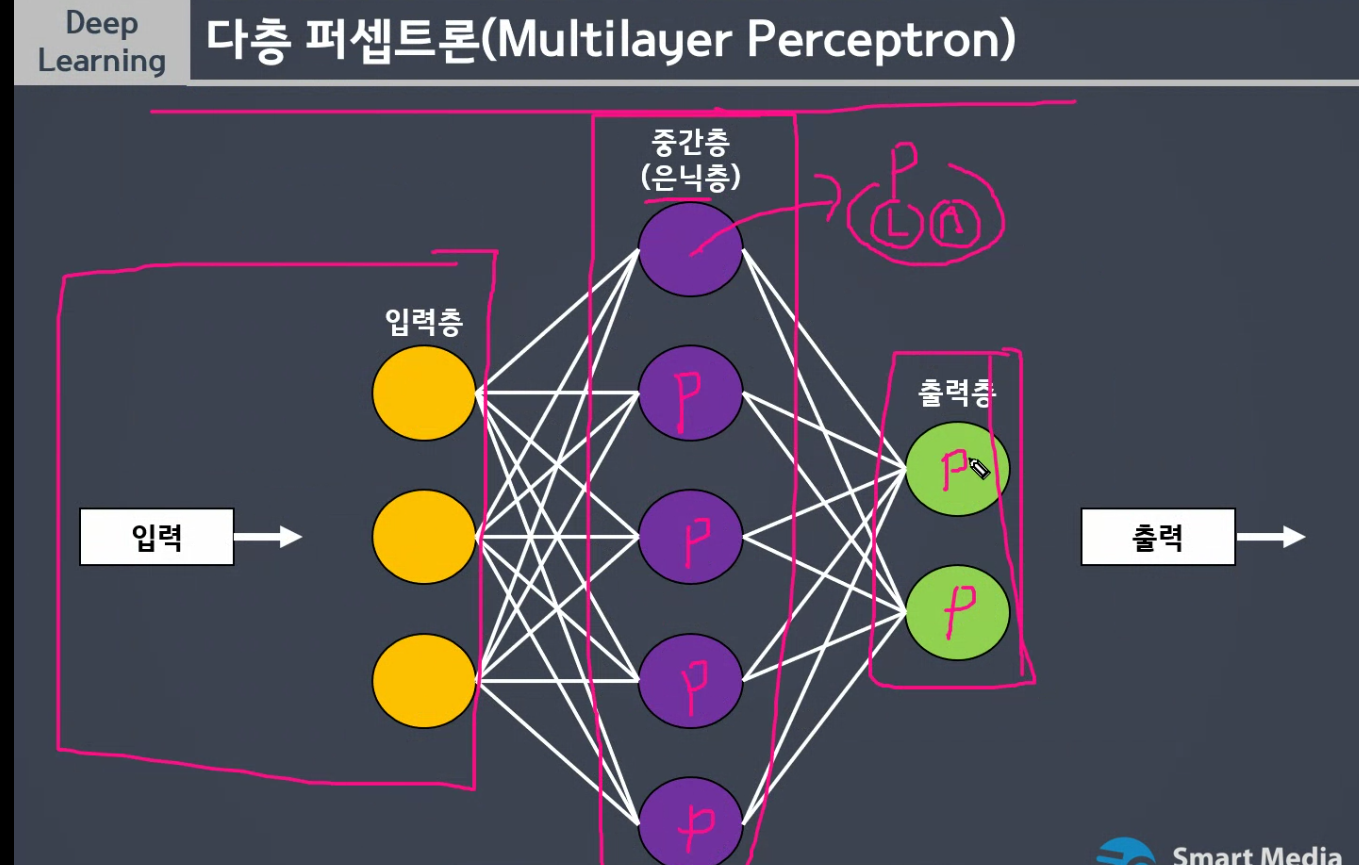
- 해결.멀티레이어퍼셉트론 (
MLP)
-다층
각각 선형모델이 따로 있어서 각각 학습해서 결국은
비선형성의 특징을 가지며
예측이 가능합니다.
EX) 8개씩 2개씩 층을 쌓는것도 여러개를 층층히 하면 비선형성을 만들 수 있다.
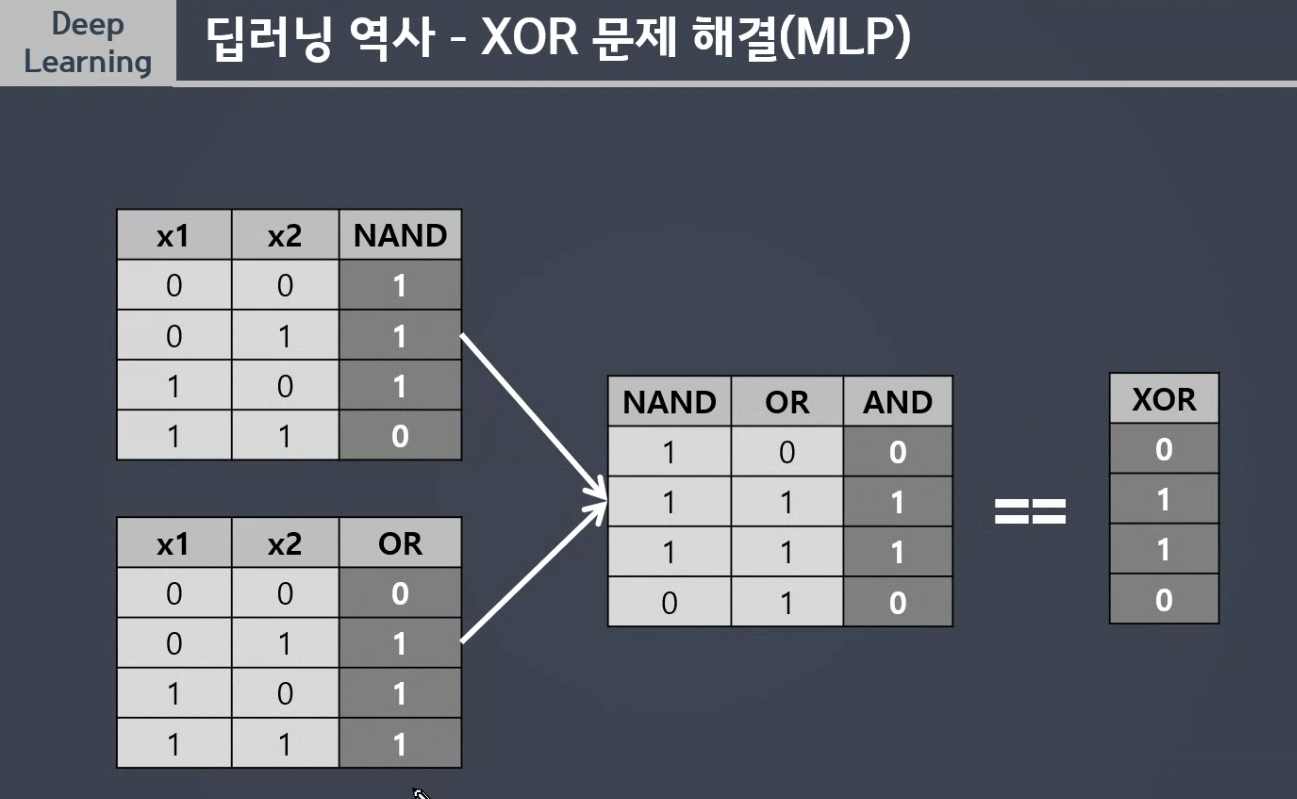
3개를 합치면 해결 =>XOR

input_layer


2번이 더 기억력이 좋지만 부작용은 과적합입니다.
가중치 초기값 , W , 랜덤
# 2. 학습방법 및 평가방법 설정
# 얼마나 틀린지 loss fn
xor_model.compile(loss='binary_crossentropy', # 손실함수 : 분류일때 모델 예측의 틀린 정도를 계산,
optimizer='adam',
metrics=['binary_accuracy'])
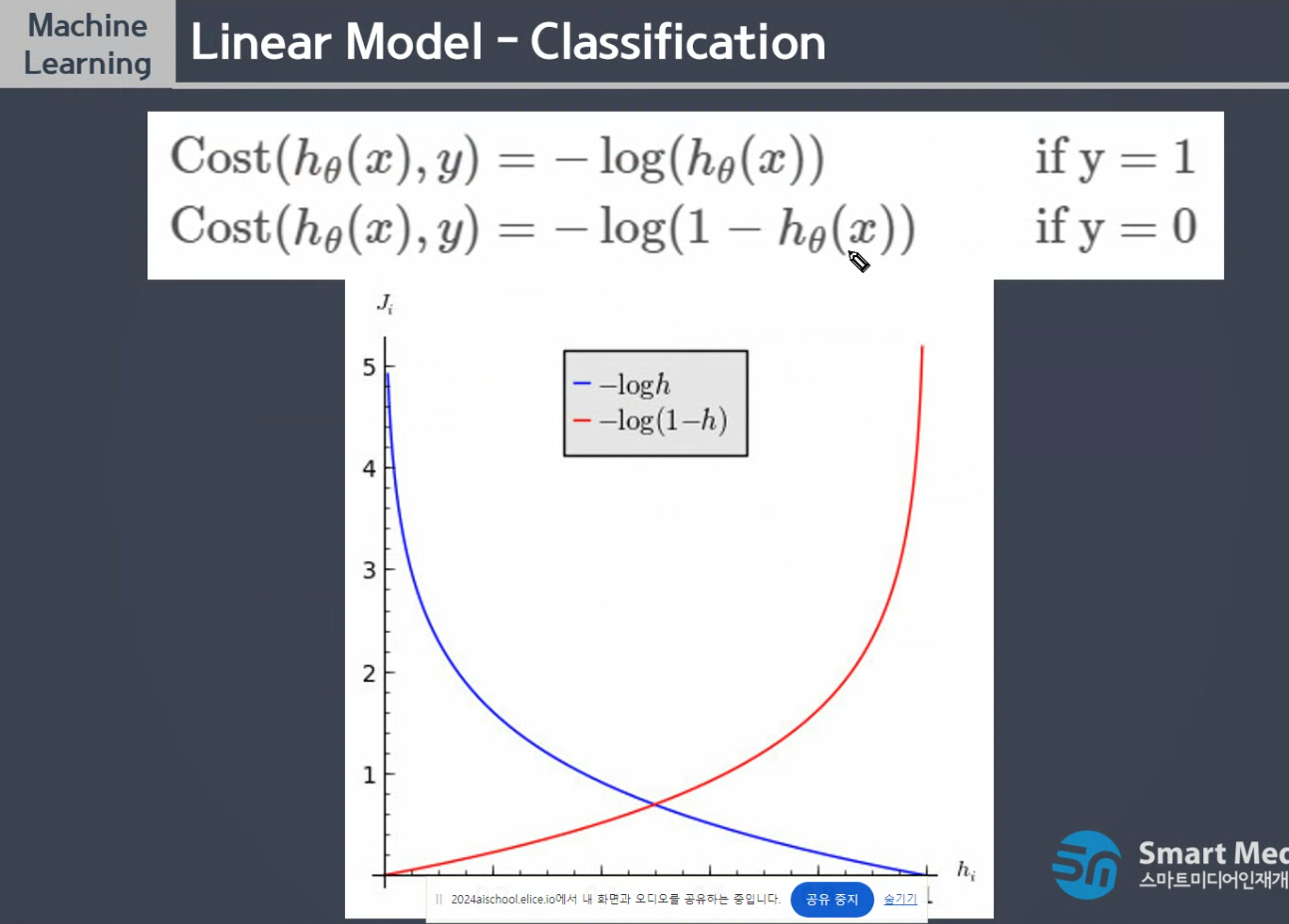
로그 값이 커질수록 완만 or 급격히 상승 효과줄떄 사용
뻥튀기나 값 줄일때
-값을 주면
tf-idf 도 로그씀
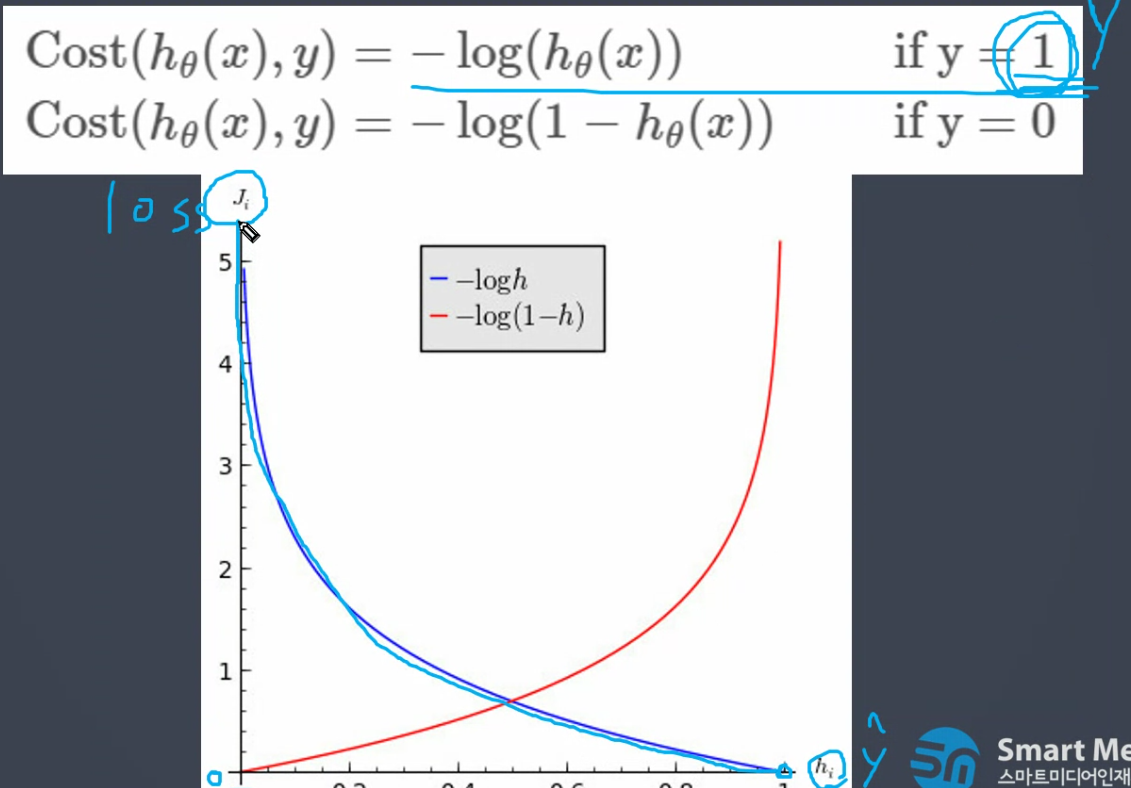
실제정답은 y - 1 일때 0에 가까울수록 폭발적으로 뻥튀기됩니다.
빨간색도 y - 0일때 1에 가까울수록 뻥튀기
로그함수적용
잘못된 예측시 오차가 거대하고 보이게
페널티를 더 많이 줄 수 있도록 하는 함수
y 1,0 함쳐서 만든게

시그마 바로 뒤가 파란색 , 뒤가 빨간색

y값
1 x 파란함수(동작함) + 0 x 빨간함수(동작안함)
y값
0 x "(동작x) + 1 x " (동작o)
- 해당하는것만 동작
2진분류 손실함수
시그마는 평균제곱오차와 동일
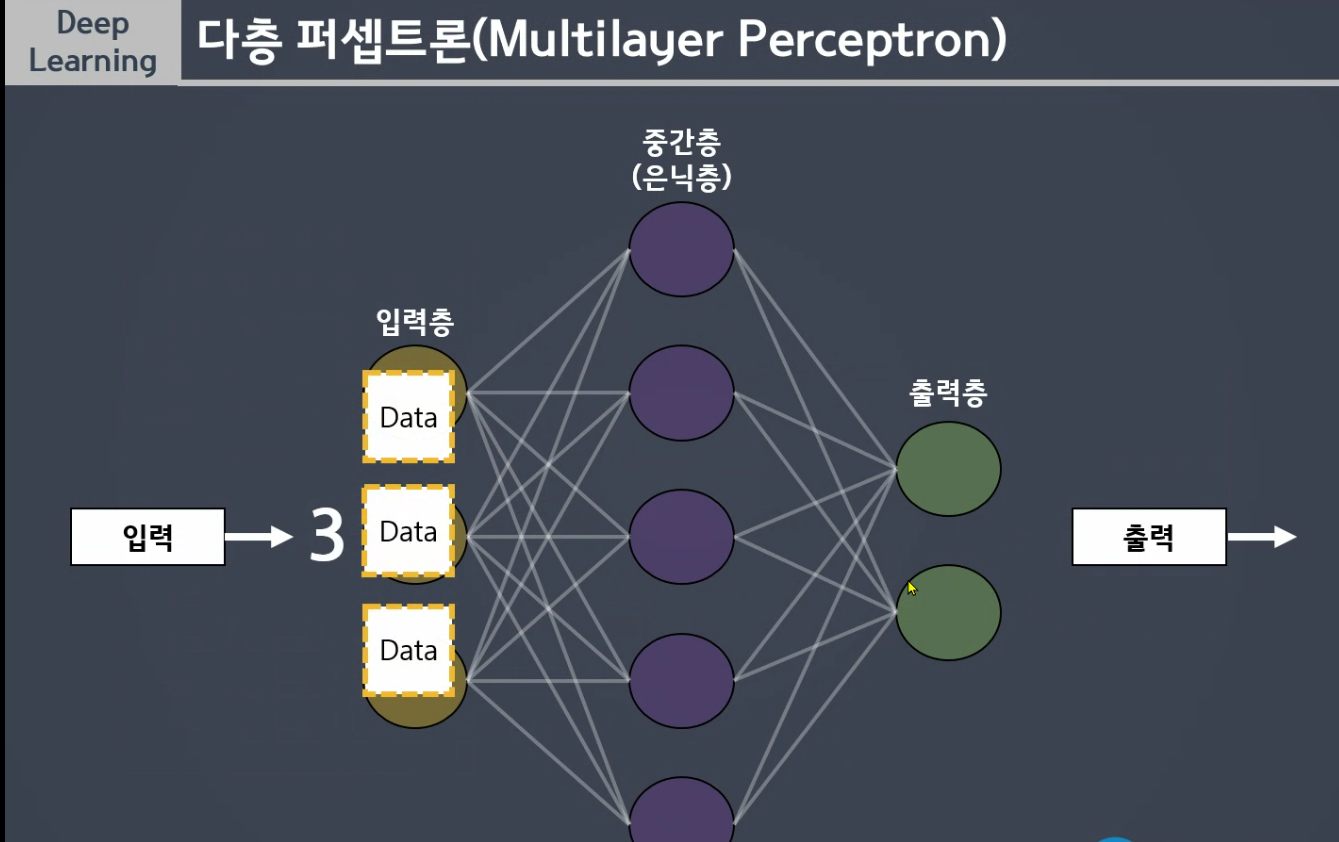
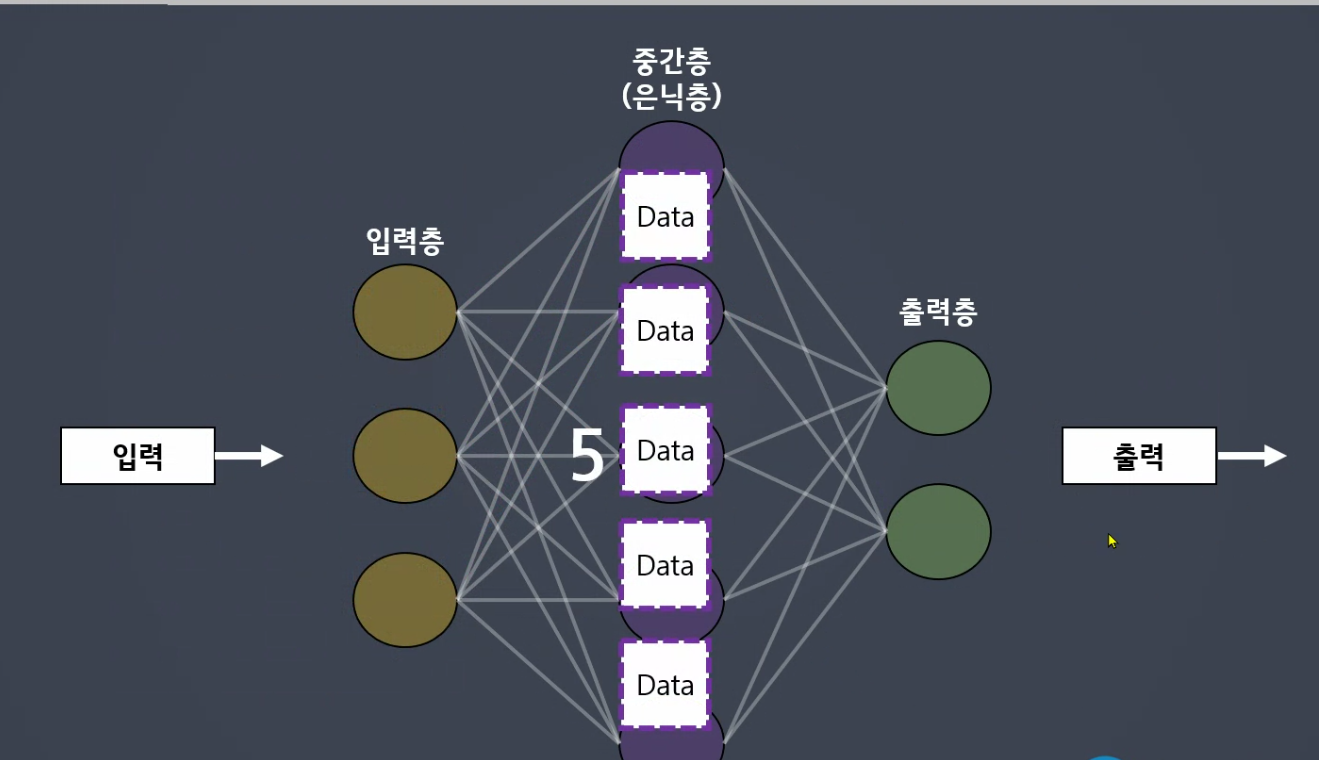
해석해서 5개의 정보로 분할
층에 여러개 할수록 더 많이 요약 , 분해
중간층이 층을 겹칠수록 예로 3, 5, 3 데이터 해석하는 관점을 많이 넣어줍니다.
활성함수가
한층을 넘어가면 데이터를 변환합니다.
다음층에서 다시 요약, 분해 > 데이터 변환합니다.
반복
항아리 모양 차츰 분해해서 원하는걸로 얻게끔 쌓습니다.
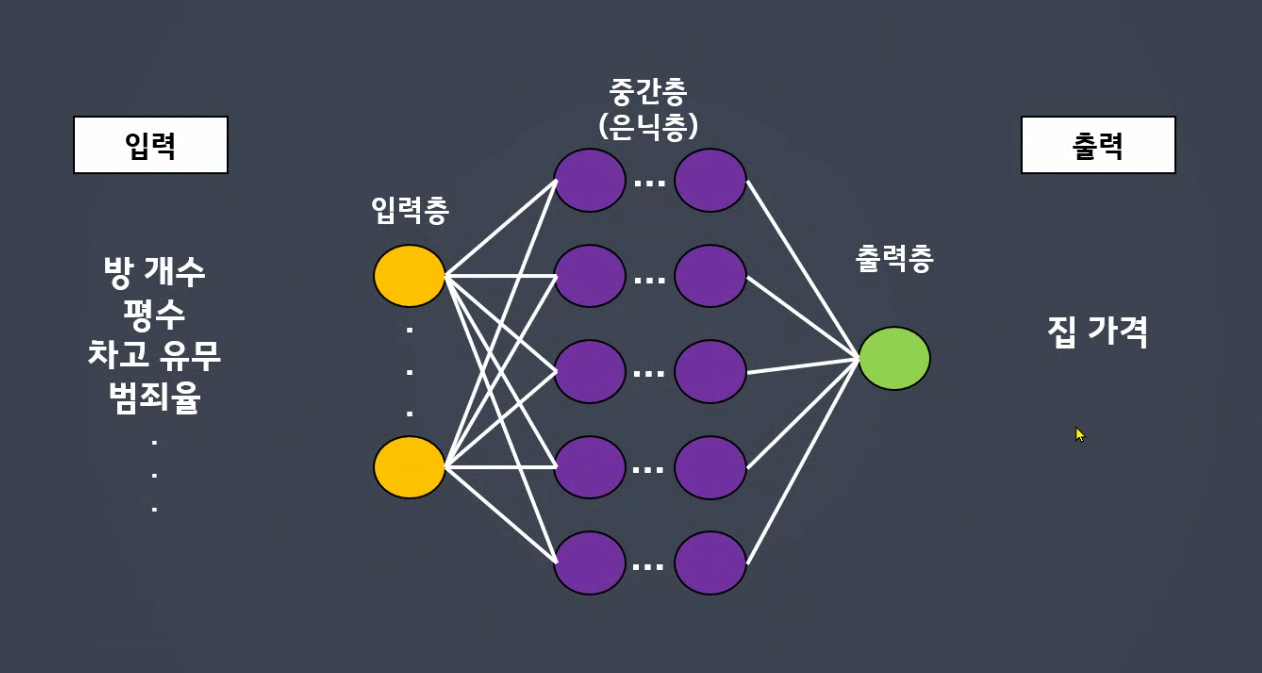
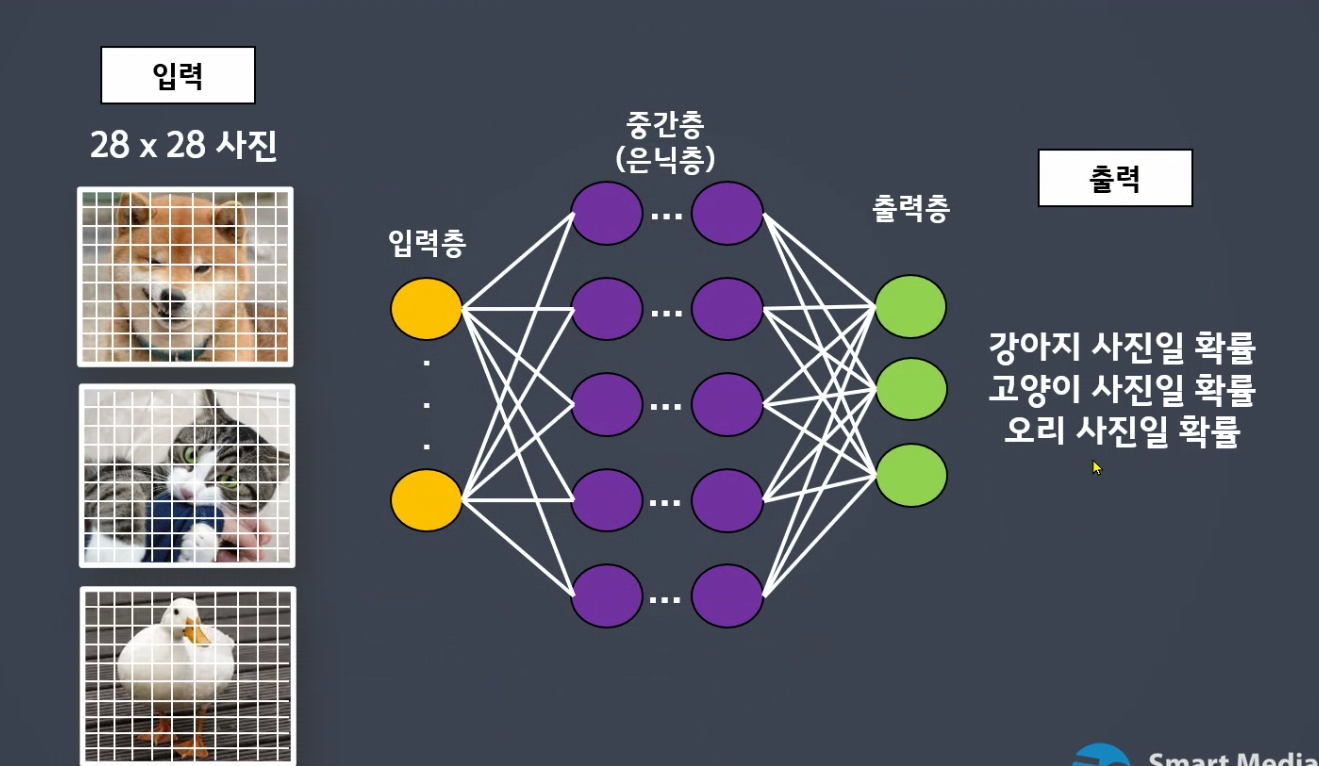
28*28개를 나열하면됩니다.
- 색상데이터가 중요합니다.
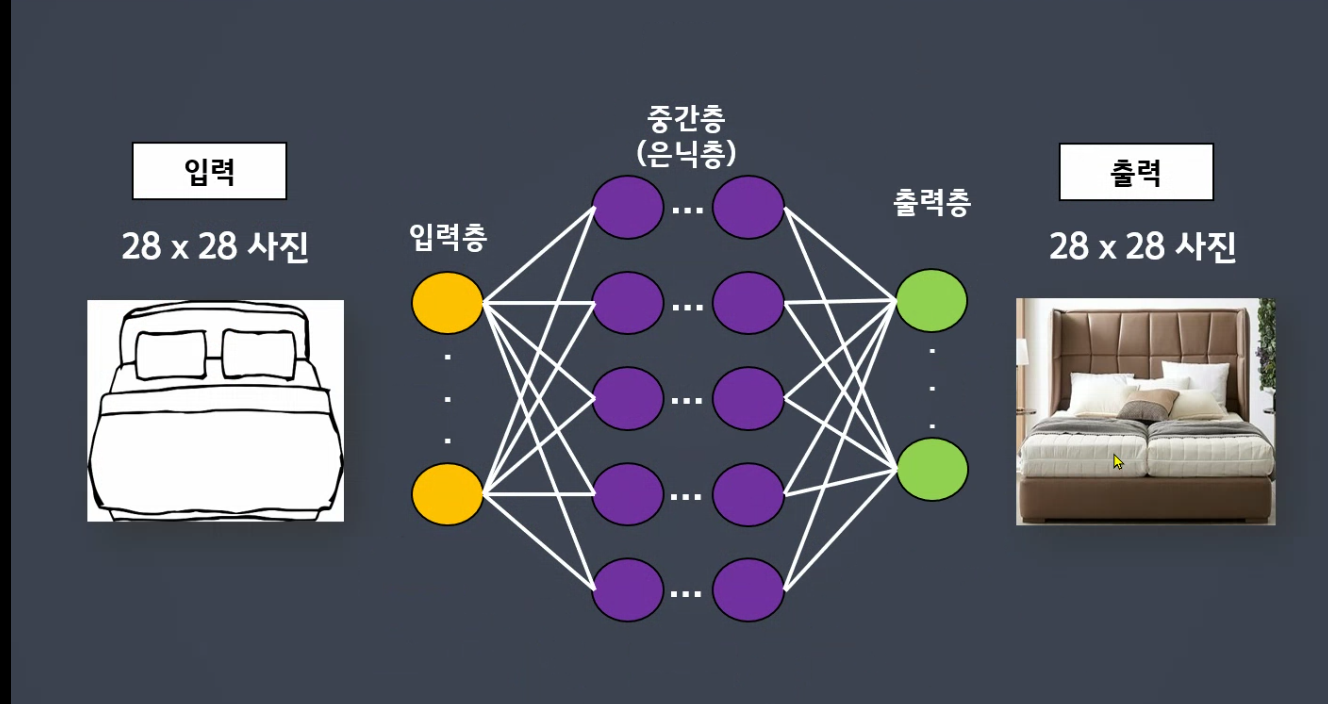
입력 : 28x28
출력 : 28x28
pix 1개 예측하는것
해상도 높이는 모델도 있습니다.
28x28 > 100x100
블랙박스모델
# 1. 모델설계
xor_model = Sequential() # 뼈대 생성
xor_model.add(InputLayer(input_shape=(2,))) # 입력층 x1, x2
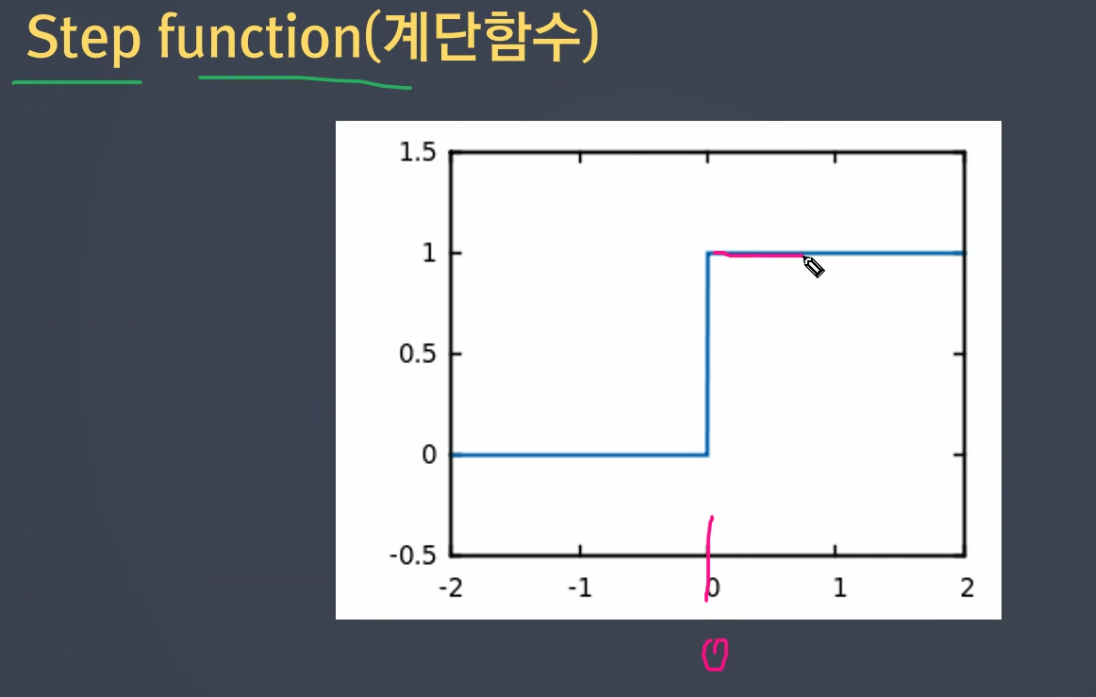
xor_model.add(Dense(units=2, activation='sigmoid')) # 은닉층 nand, or / step function 계단은 이제 쓰지않습니다. 오래되었습니다.
xor_model.add(Dense(units=1, activation='sigmoid')) # 출력층 and연산units = 16 상관없습니다.
뭐가 and연산인지 nand인지 모릅니다.
입력, 예측만 잘 만들면됩니다.


정확도가 100 나옵니다.
