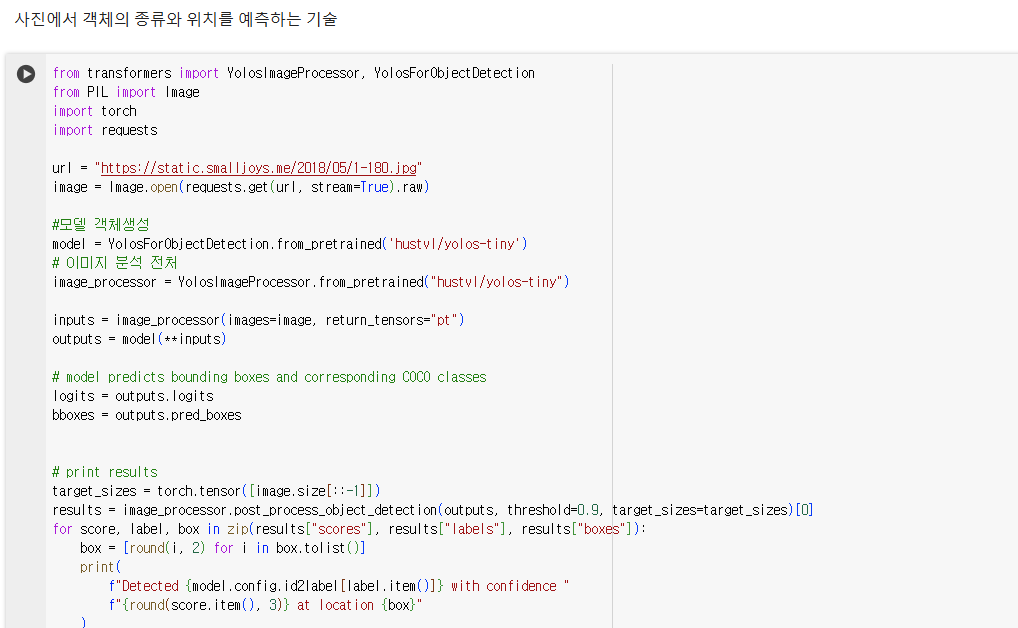
Computer Vision
코코데이터셋 을 학습시킨 yolos
[검증용]
https://cocodataset.org/
예시) orange
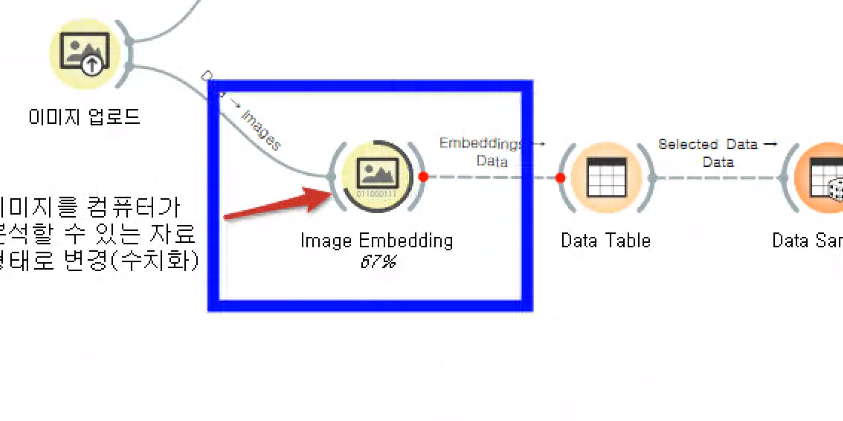
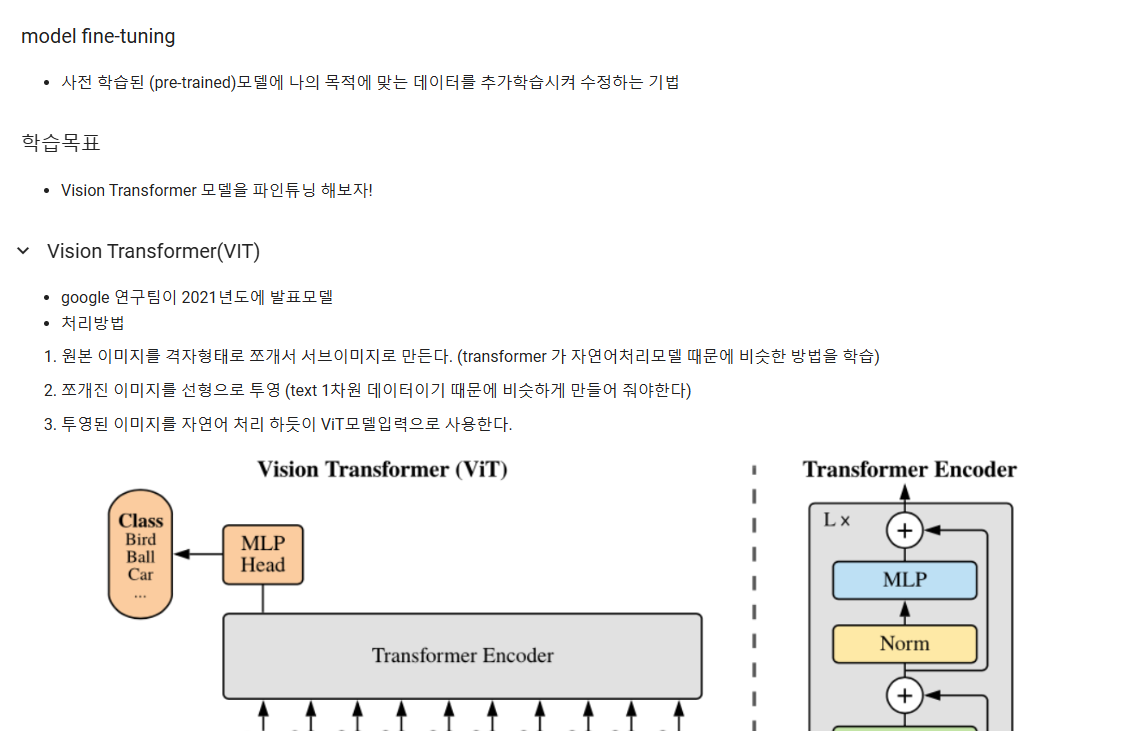
임베딩 : 컴퓨터가 학습할 수 있게 특성을 수치화한다.
!pip install transformers datasets
버전이 낮은 라이브러리 업데이트
!pip install accelerate -U
이 파일에 새로운 버전을 적용 해주기 위해서 세션 재시작
런타임 -> 새션다시시
모델과 데이터 셋도 다운 받을수 있는 사이트
https://huggingface.co/datasets/AI-Lab-Makerere/beans
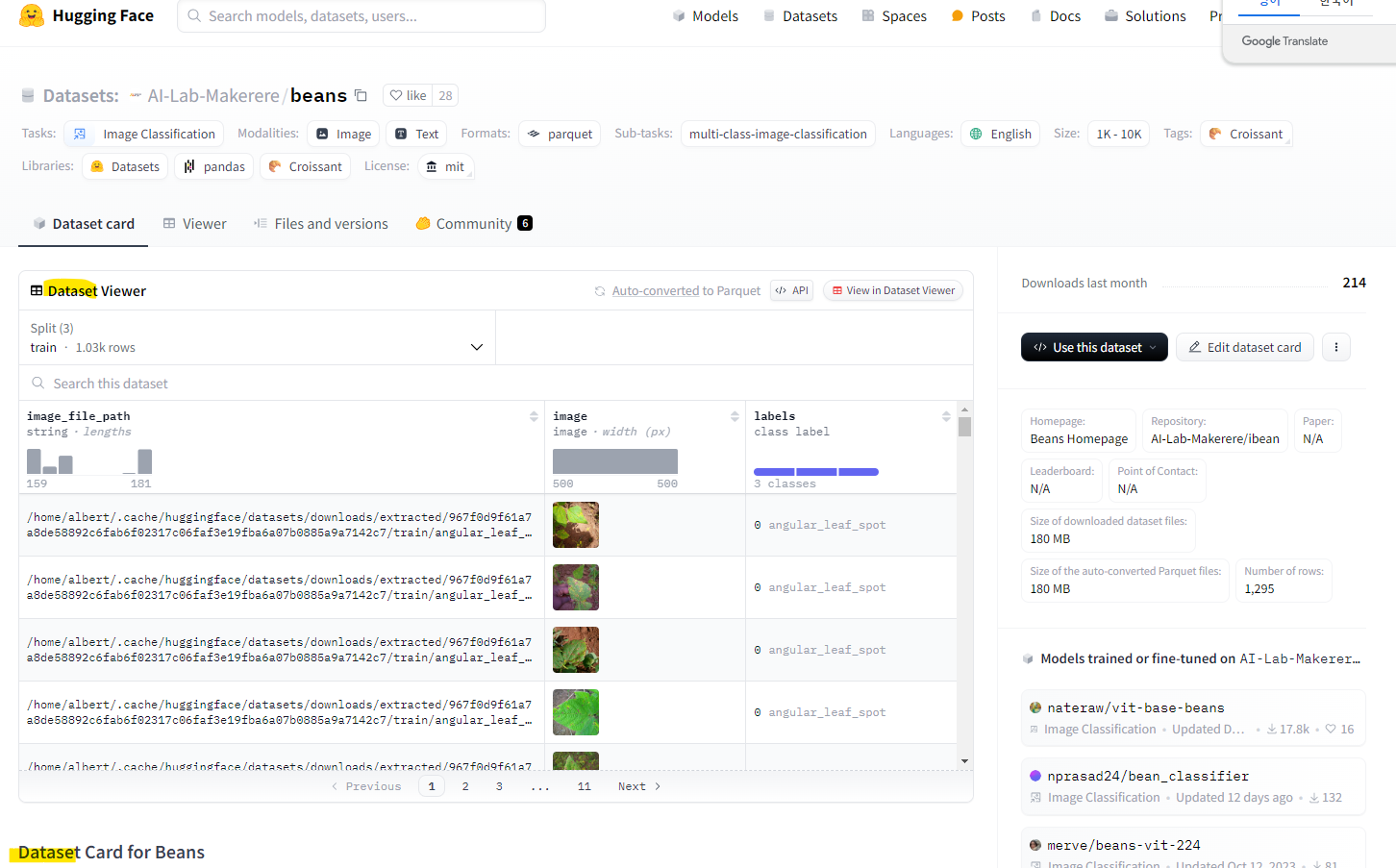
허깅페이스 저장소에 업로드된 데이터를 로딩
from datasets import load_dataset
dataset = load_dataset("beans")
from transformers import ViTFeatureExtractor
구글에서 사전에 만들어 놓은 특징추출기 사용
model_name = "google/vit-base-patch16-224-in21k" #모델이름
feature_extractor = ViTFeatureExtractor. from_pretrained(model_name)
위 모델에 맞춘 특징 추출기를 다운로드 해주세요~ |
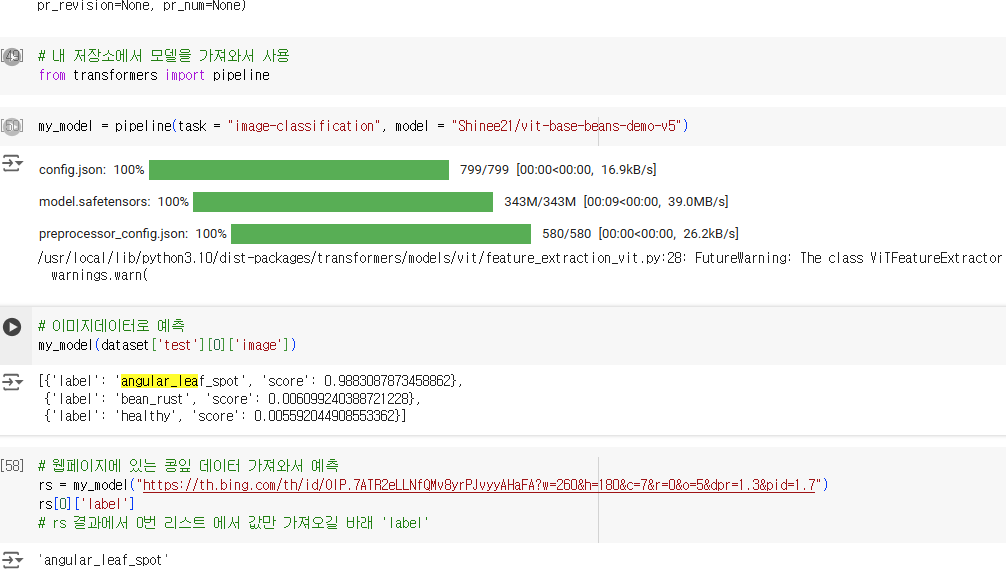
한장의 이미지 처리
feature_extractor(dataset['train'][0]['image'])

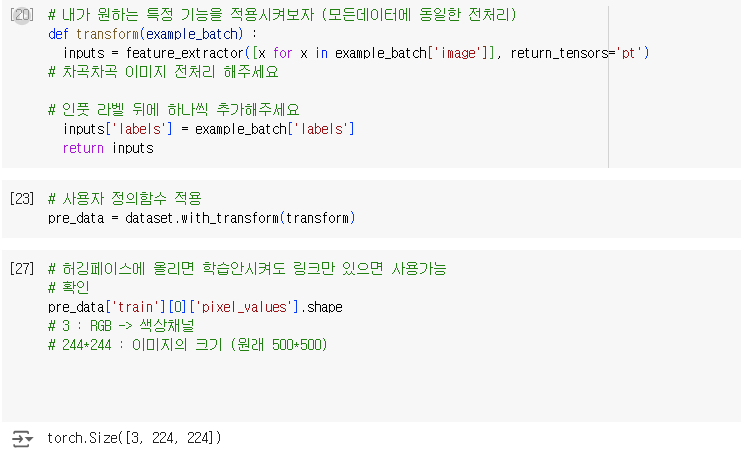

데이터를 넣어주는 함수
import torch
def collate_fn(batch):
return {
'pixel_values': torch.stack([x['pixel_values'] for x in batch]),
'labels': torch.tensor([x['labels'] for x in batch])
}
# 정확도를 계산하는 함수import numpy as np
from datasets import load_metric
metric = load_metric("accuracy")
def compute_metrics(p):
return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)
# 사전학습된 모델from transformers import ViTForImageClassification
labels = dataset['train'].features['labels'].names
model = ViTForImageClassification.from_pretrained(
model_name,
num_labels=len(labels),
id2label={str(i): c for i, c in enumerate(labels)},
label2id={c: str(i) for i, c in enumerate(labels)}
)
학습에 사용되는 파라미터(속성)
우리는 주로 여기 하이퍼파라미터를 조정해서 모델의 성능을 변경해줌
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./vit-base-beans-demo-v5", # 결과물이 저장될 폴더
per_device_train_batch_size=16, # 한번에 학습시킬 데이터(이미지) 수
evaluation_strategy="steps",
num_train_epochs=4, # 반복횟수 1000장씩 4번 할꺼야 결국은 1000장을 다 학습하면 1epoch가 종료 총 4번 거치겠다.
fp16=True,
save_steps=100,
eval_steps=100,
logging_steps=10,
learning_rate=2e-4,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=False,
report_to='tensorboard',
load_best_model_at_end=True,
)
학습을 시켜주는 클래스
from transformers import Trainer
trainer = Trainer(
model=model, # 사전에 학습된 모델
args=training_args, # 학습 파라미터(속성 값)
data_collator=collate_fn, # 배치 크기만큼 데이터를 모아서 넣어주는 역할
compute_metrics=compute_metrics, # 정확도를 계산하는 함수
train_dataset=pre_data["train"], # 훈련용 데이터
eval_dataset=pre_data["validation"], # 검증용 데이터
tokenizer=feature_extractor # 전처리 정보연결
)
train_results = trainer.train() # 학습실시 -> 학습결과를 변수에 저장
trainer.save_model() # 학습된 모델을 자동으로 저장
trainer.log_metrics("train", train_results.metrics) # 학습결과를 계산
trainer.save_metrics("train", train_results.metrics) # 학습결과 저장
trainer.save_state() # trainer의 상태 저장
새로운 데이터를 넣어 예측 및 평가 해보기
rs = trainer.evaluate(pre_data)
trainer.log_metrics("eval", rs)
trainer.save_metrics("eval", rs)
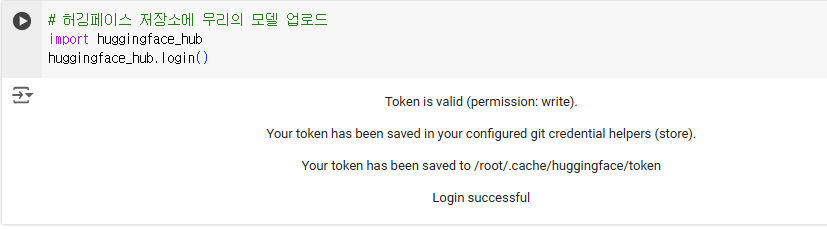
허깅페이스 저장소에 우리의 모델 업로드
import huggingface_hub
huggingface_hub.login()
저장소에 업로드시 함께 기입할 정보 작성
kwargs = {
"finetuned_from" : model.config._name_or_path, # 파인튜닝에 활용한 사전학습 모델 이름 또는 경로
"tasks" : "image-classification", # task 종류
"dataset" : 'beans', # 활용한 데이터셋 표기
"tags" : ["image-classification","ViT"]
}
토큰 받아서 넣기
학습시킨 모델을 다시 가져와서 사용
모델 위치 (허깅페이스)