학습할 것
- 람다식 사용법
- 함수형 인터페이스
- Variable Capture
- 메소드, 생성자 레퍼런스
먼저 알고가기
💡람다식이란?
int method() {
return (int) (Math.random()*5) + 1;
}- 위의 메소드를 아래와 같이 하나의 식으로 표현한 것
int[] arr = new int[5];
Arrays.setAll(arr, (i) -> (int)(Math.random()*5 + 1);- 람다식을 사용하지 않으면 메소드를 호출하기 위해 클래스를 새로 만들고 객체도 생성해야 했는데 람다식 자체만으로 메서드의 역할을 대신할 수 있게 되었다.
- 특정 람다식을 어떤 메서드의 매개변수 혹은 결과로 이용이 가능하다. => 메서드를 변수처럼 다룰 수 있게 되었다.
- 메소드를 람다식으로 표현하면 메소드의 이름과 반환값이 없으므로, 람다식을 '익명 함수(anonymous function)'이라고도 한다.
1. 람다식 사용법
람다식 작성방법
case 1.
<기존 메서드 작성 방법>
반환타입 메서드이름(매개변수 선언) {
문장들
}
<람다식>
(매개변수 선언) -> {
문장들
}- 메소드에서 이름과 반환타입을 제거하고 매개변수 선언부와 몸통{} 사이에 '->' 화살표를 추가한다.
case 2.
<반환값이 있는 메서드를 람다식으로 표현할 경우>
(int a, int b) -> {return a>b ? a : b;}
(int a, int b) -> a > b ? a: b- 반환값이 있는 메서드의 경우 return문 대신 식으로 대신 할 수 있다.
- 문장이 아닌 '식' 이므로 끝에 세미콜론(;)을 붙이지 않는다.
case 3.
(int a, int b) -> a > b ? a: b
(a, b) -> a > b ? a : b- 람다식에 선언된 매개변수의 타입은 추론이 가능한 경우는 생략할 수 있는데 대부분의 경우 생략가능하다.
case 4.
<매개변수가 하나뿐일 경우>
(a) -> a * a
a -> a * a
<매개변수의 타입이 있을 경우>
(int a) -> a * a- 선언된 매개변수가 하나뿐일 경우 괄호()는 생략할 수 있다. (단, 매개변수의 타입이 있으면 괄호는 생략할 수 없다.)
case 5.
<괄호{} 안의 문장이 하나일 경우>
(String name, int i) -> {
System.out.println(name + "="+i);
}
(String name, int i) -> System.out.println(name + "="+i);- 괄호{} 안의 문장이 하나일 때는 괄호{}를 생략할 수 있다. 이 때, 문장의 끝에 ';'를 붙이지 않아야 한다.
- 그러나 괄호{} 안의 문장이 return문일 경우 괄호{}를 생략할 수 없다.
2. 함수형 인터페이스
// 1
(int a, int b) -> a > b ? a : b
// 2
new Object() {
int max(int a, int b) {
return a > b ? a : b;
}
}람다식은 메소드와 동등한 것처럼 보이지만, 사실 람다식은 익명 클래스의 객체와 동등하다.
위의 익명 객체의 메소드를 어떻게 호출할 수 있을까?
참조변수가 있어야 객체의 메소드를 호출 할 수 있으니 일단 익명 객체의 주소를 f라는 참조변수에 저장하자.
타입 f = (int a, int b) -> a > b ? a : b; // 참조변수의 타입을 뭘로 해야 할까?참조변수 f의 타입은 어떤 것이어야 할까? 참조형이므로 클래스 또는 인터페이스가 가능하다.
그리고 람다식과 동등한 메소드가 정의되어 있는 것이어야 한다. 그래야 참조변수로 익명 객체(람다식)의
메소드를 호출할 수 있기 때문이다.
예를 들어 max()라는 메소드가 정의된 MyFunction 인터페이스가 있다고 가정하자.
interface MyFunction {
public abstract int max(int a, int b);
}위의 인터페이스를 구현한 익명 클래스의 객체는 아래와 같이 생성할 수 있다.
MyFunction f = new Myfunction() {
public int max(int a, int b) {
return a > b ? a : b;
}
};
int big = f.max(5, 3); // 익명 객체의 메소드 호출- MyFunction 인터페이스에 정의된 메소드 max()는 람다식 '(a, b) -> a > b ? a : b'와 메소드 선언부가 일치한다.
따라서, 위 코드의 익명 객체를 아래와 같이 람다식으로 변경할 수 있다.
MyFunction f = (a, b) -> a > b ? a : b; // 익명 객체를 람다식으로 대체
int big = f.max(5, 3); // 익명 객체 메소드 호출👉 익명 객체를 람다식으로 대체 가능한 이유?
람다식도 실제로는 익명 객체이고, MyFunction 인터페이스를 구현한 익명 객체의 메소드 max()와
람다식의 매개변수 타입과 개수 그리고 반환값이 일치하기 때문이다.
위에서 봤듯이 하나의 메소드가 선언된 인터페이스를 정의해서 람다식을 다루는 것은 기존의 자바 규칙을
어기지 않으면서도 자연스럽다.
그래서 인터페이스를 통해 람다식을 다루기로 결정됐고, 람다식을 다루기 위한 인터페이스를
함수형 인터페이스(functional interface) 라고 부르기로 했다.
@FunctionalInterface
interface MyFunction { // 함수형 인터페이스 MyFunction을 의미
public abstract int max(int a, int b);
}- 함수형 인터페이스에는 오직 하나의 추상 메소드만 존재 해야 한다.
그래야만, 람다식과 인터페이스의 메소드가 1:1로 연결될 수 있음. - static 메소드와 default 메소드의 개수에는 제약이 없다.
💡 @FunctionalInterface를 붙이면, 컴파일러가 함수형 인터페이스를 올바르게 정의하였는지 확인하므로, 꼭 붙이자.
매개변수와 반환타입
@FunctionalInterface
interface MyFunction {
void myMethod(); // 추상메소드
}메소드의 매개변수가 MyFunction 타입이면, 이 메소드를 호출할 때 람다식을 참조하는 참조변수를
매개변수로 지정해야한다는 뜻이다.
void aMethod(MyFunction f) {
f.myMethod();
}
MyFunction f = () -> System.out.println("myMethod()");
aMethod(f);또는 참조변수 없이 아래와 같이 직접 람다식을 매개변수로 지정할 수도 있다.
aMethod() -> System.out.println("myMethod()");메소드의 반환타입이 함수형 인터페이스라면, 그 함수형 인터페이스의 추상메소드와 동등한 람다식을
가리키는 참조변수를 반환하거나, 람다식을 직접 반환 할 수 있다.
MyFunction myMethod() {
MyFunction f = () -> {};
return f; // 두 줄을 한 줄로 줆이면, return () -> {};
}다음은 위에서 설명한 것들을 사용한 함수형 인터페이스와 람다식 예제이다.
@FunctionalInterface
interface MyFunction {
void run(); // public abstract void run();
}
public class LambdaEx1 {
static void execute(MyFunction f) {
f.run();
}
static MyFunction getMyFunction () {
return () -> System.out.println("f3.run()");
}
public static void main(String[] args) {
MyFunction f1 = () -> System.out.println("f1.run()");
MyFunction f2 = new MyFunction() {
@Override
public void run() {
System.out.println("f2.run()");
}
};
MyFunction f3 = getMyFunction();
f1.run();
f2.run();
f3.run();
execute(f1);
execute(() -> System.out.println("run()"));
}
}// 결과
f1.run()
f2.run()
f3.run()
f1.run()
run()람다식 타입과 형변환
람다식은 익명 객체이고 익명 객체는 타입이 없다.
따라서, 대입 연산자의 양변의 타입을 일치시키기 위해 형변환 이 필요하다.
MyFunction f = (MyFunction)(() -> {});- 위의 람다식은 MyFunction 인터페이스를 직접 구현하지 않았지만, 인터페이스를 구현한 클래스의
객체와 동일하기 때문에, 위와 같은 형변환을 허용한다.
- 그리고 이 형변환은 생략가능하다.
Object obj = (Object)(() -> {}) // ERROR. 함수형 인터페이스로만 형변환 가능- Object 타입으로는 형변환 할 수 없다.
- 오직 함수형 인터페이스로만 형변환 가능한다.
굳이 Object 타입으로 형변환하려면, 먼저 함수형 인터페이스로 변환해야 한다.
Object obj = (Object)(MyFunction)(() -> {});
String str = ((Object)(MyFunction)(() -> {})).toString();java.util.function 패키지
- java.util.function 패키지에 일반적으로 자주 쓰이는 형식의 메소드를 함수형 인터페이스가 미리 정의되어 있다.

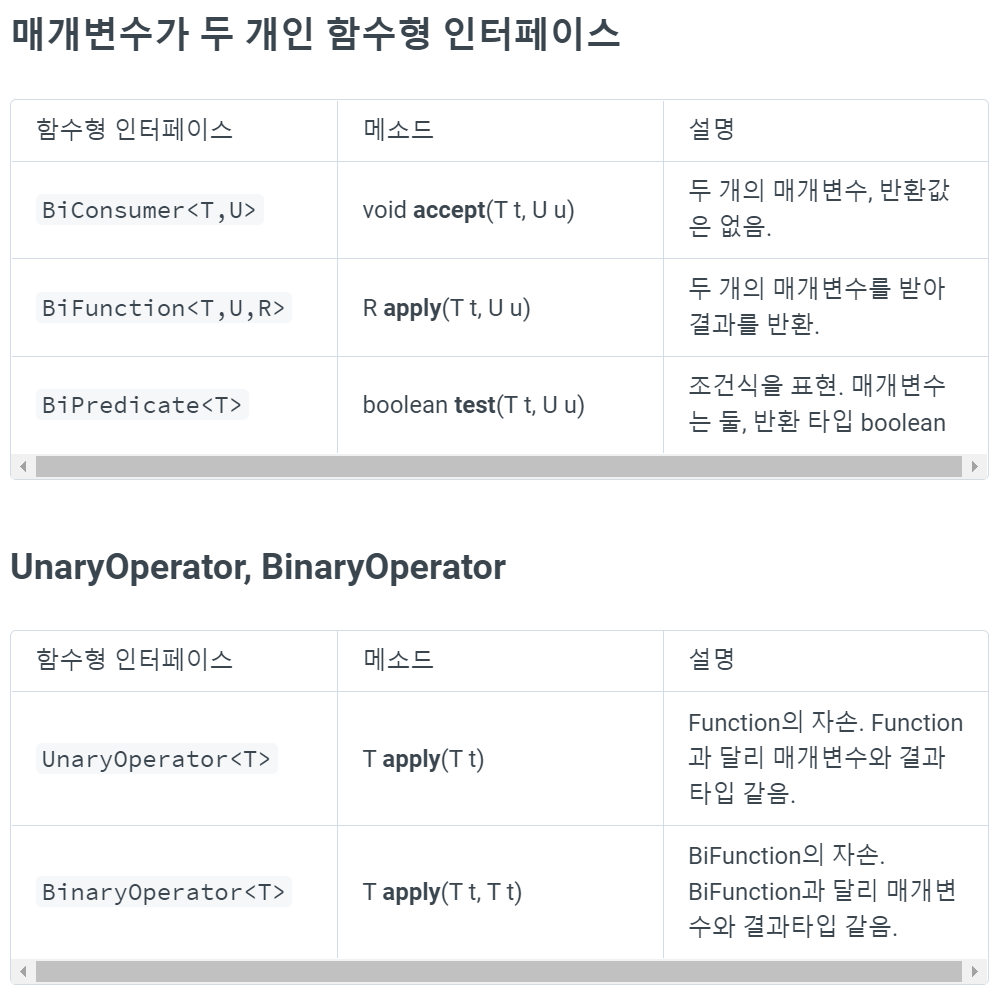
- 매개변수의 타입과 반환타입의 타입이 모두 일치한다는 점을 제외하고는 function과 같다.
3. Variable Capture
람다식에서 외부 지역변수를 참조하는 행위를 Lambda Capturing(람다 캡쳐링)이라고 한다.
람다에서 접근가능한 변수는 아래와 같이 세가지 종류가 있다.
- 지역 변수
- static 변수
- 인스턴스 변수
- 지역변수만 변경이 불가능하고 나머지 변수들은 읽기 및 쓰기가 가능하다.
- 람다는 지역 변수가 존재하는 스택에 직접 접근하지 않고, 지역 변수를 자신(람다가 동작하는 쓰레드)의 스택에 복사한다.
- 각각의 쓰레드마다 고유한 스택을 갖고 있어서 지역 변수가 존재하는 쓰레드가 사라져도 람다는 복사된 값을 참조하면서 에러가 발생하지 않는다.
그런데 멀티 쓰레드 환경이라면, 여러 개의 쓰레드에서 람다식을 사용하면서 람다 캡쳐링이 계속 발생하는데
이 때 외부 변수 값의 불변성을 보장하지 못하면서 동기(sync)화 문제가 발생한다.
이러한 문제로 지역변수는 final, Effectively Final 제약조건을 갖게된다.
인스턴스 변수나 static 변수는 스택 영역이 아닌 힙 영역에 위치하고, 힙 영역은 모든 쓰레드가 공유하고 있는 메모리 영역이기 때문에, 값의 쓰기가 발생하여도 별 문제가 없는 것이다.
💡 Effectively Final
람다식 내부에서 외부 지역변수를 참조하였을때 지역 변수는 재할당을 하지 않아야 하는 것을 의미한다.
다음 예제로 살펴보자.
@FunctionalInterface
interface MyFunction3 {
void myMethod();
}
class Outer {
int val = 10;
class Inner {
int val = 20;
void method(int i) { // void method(final int i)
int val = 30; // final int val = 30;
// i = 10; // ERROR. 상수의 값은 변경할 수 없다.
MyFunction3 f = () -> {
System.out.println(" i : " + i);
System.out.println(" val : " + val);
System.out.println(" this.val : " + ++this.val);
System.out.println("Outer.this.val : " + ++Outer.this.val);
};
f.myMethod();
}
} // End Of Inner
} // End Of Outer
public class LambdaEx3 {
public static void main(String[] args) {
Outer outer = new Outer();
Outer.Inner inner = outer.new Inner();
inner.method(100);
}
}// 결과
i : 100
val : 30
this.val : 21
Outer.this.val : 11- 람다식 내에서 참조하는 지역변수는 final이 붙지 않아도 상수로 간주된다.
- 람다식 내에서 지역변수 i와 val을 참조하고 있으므로 람다식 내에서나 다른 곳에서도 이 변수들의 값을 변경할 수 없다.
- 반면, Inner 클래스와 Outer 클래스의 인스턴스 변수인 this.val과 Outer.this.val은 상수로 간주되지 않아서 값을 변경해도 된다.
- 람다식에서 this는 내부적으로 생성되는 익명 객체의 참조가 아니라 람다식을 실행한 객체의 참조다.
따라서 위의 코드에서 this는 중첩 객체인 Inner이다.
4. 메소드, 생성자 레퍼런스
메소드 참조
람다식이 하나의 메소드만 호출하는 경우에는 '메소드 참조(method reference)'를 통해
람다식을 간략하게 작성할 수 있다.
메소드 참조를 작성하는 방법은 아래처럼 간단하다.
클래스이름::메소드이름
or
참조변수::메소드이름
Function<String, Integer> f = s -> Integer.parseInt(s);보통 위처럼 람다식을 작성하는데, 이 람다식을 메소드로 표현하면 아래와 같다.
Integer wrapper(String s) { // 이 메소드의 이름은 의미없음. 테스트용
return Integer.parseInt(s);
}이 wrapper 메소드는 별로 하는 일이 없다. 값을 받아서 Integer.parseInt()에게 넘겨줄 뿐.
차라리 Integer.parseInt()를 직접 호출하는게 낫지 않을까???
Function<String, Integer> f = s -> Integer.parseInt(s);
// 메소드 참조
Function<String, Integer> f = Integer::parseInt;메소드 참조를 이용하면 더 간략하게 작성할 수 있다.
위 메소드 참조에서 람다식 일부가 생략되었지만, 컴파일러는 생략된 부분을 우변의 parseInt 메소드의 선언부로부터,
또는 좌변의 Function 인터페이스에 지정된 제네릭 타입으로부터 쉽게 알아낸다.
또 다른 예를 보자.
BiFunction<String, String, Boolean> f = (s1, s2) -> s1.equlas(s2);위 람다식에서 어떤 부분을 변경할 수 있을까?
- 참조변수 f의 타입으로 유추하면 람다식이 두 개의 String 타입의 매개변수를 받는다. 따라서, 매개변수 생략가능.
- 매개변수를 생락하면, equals만 남는데, 두 개의 String을 받아서 Boolean을 반환하는 equals라는 메소드 이므로
String::equals로 변경한다.
BiFunction<String, String, Boolean> f = String::equals;메소드 참조로 변경한 결과이다.
MyClass obj = new MyClass();
Function<String, Boolean> f = x -> obj.equals(x); // 람다식
Function<String, Boolean> f2 = obj::equals; // 메소드 참조메소드 참조를 사용하는 경우가 한 가지 더 있는데, 이미 생성된 객체의 메서드를 람다식에서 사용한 경우에는
클래스 이름 대신 그 객체의 참조변수를 적어야 한다.
메소드 참조를 정리하면 다음과 같다.
생성자의 메소드 참조
생성자를 호출하는 람다식도 메소드 참조로 변환할 수 있다.
Supplier<MyClass> s = () -> new MyClass(); // 람다식
Supplier<MyClass> s = MyClass:new; // 메소드 참조매개변수가 있는 생성자라면, 매개변수의 개수에 따라 알맞은 함수형 인터페이스를 사용하면 된다.
Function<Integer, MyClass> f = i -> new MyClasS(i); // 람다식
Function<Integer, MyClass> f = MyClass:new; // 메소드 참조
BiFunction<Integer, String, MyClass> bf = (i, s) -> new MyClass(i, s); // 람다식
BiFunction<Integer, String, MyClass> bf = MyClass::new; // 메소드 참조만약 배열을 생성할 때는 다음과 같이 사용한다.
Function<Integer, int[]> f = x -> new int[x]; // 람다
Function<Integer, int[]> f2 = int[]::new; // 메소드 참조예제
메소드 참조를 연습하여 사용해보자.
처음에는 익숙하지 않아서 조금 헷갈릴 수 있지만 몇 번 사용하면 금방 손에 익는다.
public class MethodReferences {
public static void main(String[] args) {
// Function<String, Integer> f = s -> Integer.parseInt(s);
Function<String, Integer> f = Integer::parseInt;
System.out.println(f.apply("100") + 200);
// Supplier 입력 X, 출력 O
// Supplier<MyClass> s = () -> new MyClass();
Supplier<MyClass> s = MyClass::new;
System.out.println(s.get());
Function<Integer, MyClass> f2 = MyClass::new;
MyClass m = f2.apply(100);
System.out.println(m.iv);
System.out.println(f2.apply(200).iv);
Function<Integer, int[]> f3 = int[]::new;
System.out.println(f3.apply(10).length);
}
}
class MyClass {
int iv;
MyClass () {}
MyClass (int iv) {
this.iv = iv;
}
}// 결과
300
MyClass@5fd0d5ae
100
200
10