
병합 정렬(Merge Sort)
- 병합 정렬 혹은 합병 정렬이라고 불리며 데이터들을 잘게 쪼갠 다음에 하나로 합치는 과정에서 정렬하는 방식의 분할 정복 알고리즘.
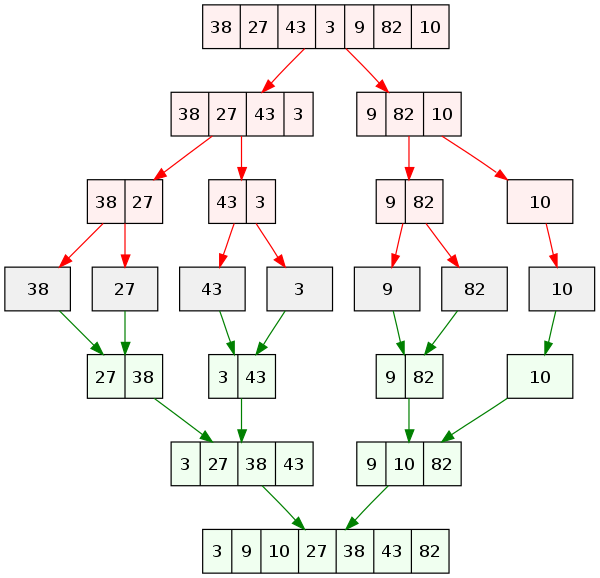
- 배열을 쪼개는 과정이 분할단계(빨간 배열)에 해당하며 합치는 과정이 정복단계(초록 배열)에 해당한다.
시간복잡도
-
최선의 경우 : O(nlog₂n)
-
최악의 경우 : O(nlog₂n)
-
병합 정렬은 데이터를 분할하는 단계와 다시 병합하는 단계로 나눌 수 있는데, 분할하는 단계는 시간복잡도에 포함되지 않는다.
-
데이터를 분할한 후 병합하는 단계에서 재귀 호출의 길이는 log₂n이다. 왜냐하면 1/2씩 쪼개진 배열을 합치기 때문이다. 그리고 그 각각의 단계에서 데이터의 개수만큼 크기를 비교하는 연산이 필요하기 때문에 최대 n번의 비교 연산을 하게 된다. 그러므로 병합 정렬의 시간 복잡도는 O(nlog₂n)이며 이는 최선의 경우이든 최악의 경우이든 동일하게 적용된다.
-
병합 정렬은 최선의 경우와 최악의 경우가 모두 O(nlog₂n)의 시간을 가지기 때문에 최악의 경우에 O(n^2)의 시간을 가지는 퀵 정렬보다 빠른 정렬이라고 생각하기 쉽다. 그러나 항상 그런 것은 아니다. 그 이유는 퀵 정렬이 병합 정렬보다 더 작은 상수 시간을 가지기 때문이다.
-
퀵 정렬과 병합 정렬의 경우에 두 정렬의 소요시간은 최선의 경우에 모두 O(nlog₂n)이라고 표현되지만 퀵 정렬이 병합 정렬보다 작은 상수값을 가지므로 최악의 경우가 아닌 경우엔 퀵 정렬이 병합 정렬보다 좀 더 빠르다.
장점
- 병합 정렬은 최선의 경우에도, 최악의 경우에도 O(nlog₂n)의 시간이 소요되기 때문에 데이터 분포에 영향을 덜 받는다. 항상 동일한 시간이 소요되므로 어떤 경우에도 좋은 성능을 보장받을 수 있다.
단점
- 병합 정렬은
in place알고리즘이 아니기 때문에 별도의 메모리 공간이 필요하다. 만약에 정렬할 데이터의 양이 많은 경우에는 그만큼 이동 횟수가 많아지므로 시간적인 낭비도 많아지게 된다.
구현
'use strict';
function MergeSort(arr) {
if (arr.length < 2) return arr;
const mid = parseInt(arr.length / 2);
const leftArr = arr.slice(0, mid);
const rightArr = arr.slice(mid);
return Merge(MergeSort(leftArr), MergeSort(rightArr));
}
function Merge(leftArr, rightArr) {
const sortArr = [];
let leftIdx = 0;
let rightIdx = 0;
while (leftIdx < leftArr.length && rightIdx < rightArr.length) {
if (leftArr[leftIdx] < rightArr[rightIdx]) {
sortArr.push(leftArr[leftIdx]);
leftIdx++;
} else {
sortArr.push(rightArr[rightIdx]);
rightIdx++;
}
}
return sortArr.concat(leftArr.slice(leftIdx), rightArr.slice(rightIdx));
}
console.log(MergeSort([38, 27, 43, 3, 9, 82, 10]));
꾸준히 성장하는 개발자를 목표로 합니다.