
함수형 프로그래밍 시리즈 내용으로 계속 이어서 내용이 진행되므로 처음 부터 포스팅을 확인해주세요.
range
숫자를 받아 그 크기만큼의 배열을 반환하는 함수
const range = l => {
let i = -1;
let response = [];
while(++i < l) {
response.push(i);
}
return response;
}
const list = range(4);
console.log(list); // [0, 1, 2, 3]
console.log(reduce(add, list)); // 6
L.range
L.range에서는 배열이 바로 반환되는게 아닌 Iterator가 반환된 것을 확인할 수 있습니다.
const L = {};
L.range = function *(l){
let i = -1;
while (++i < l) {
yield i;
}
};
const list = L.range(4);
console.log(list); //L.range {<suspended>}
console.log(reduce(add, list)); // 6
range, L.range 차이
일반 range함수는 함수 호출시점에 이미 배열로 평가가 되서 list에 대입되었지만, 느긋한 L.range는 함수 호출시점에는 실제 값이 대입되지 않습니다.
느긋한 L.range함수는 호출 시점에서는 내부의 어떤 로직도 동작하지 않습니다.
실제 호출되는시기는 이터레이터의 내부를 순회할 때마다 하나씩 값이 평가가됩니다.
즉, list.next()를 통해 순회를 할 때 결과가 꺼내집니다.
지연평가를 사용하는 이유
기존의 일반 range를 호출할 경우 즉시 배열이 생성되어 호출됩니다.
하지만, 해당 배열을 사용하는 실제 로직이 실행되기전까진 해당 배열의 필요성및 중요도는 높지 않습니다.
그 반면 지연평가는 배열을 생성하는 함수를 호출한시점에서 실제 배열을 반환하지는 않습니다.
실제로 Iterator가 순회를하며 next값을 꺼낼때 값을 생성하여 반환합니다.
이처럼 값을 실제 사용할 때까지 계산을 늦춰서 얻을 수 있는 이점은 불필요한 계산을 하지 않으므로 빠른 계산이 가능하고 무한자료 구조를 사용할수도 있습니다.
range와 L.range 성능 테스트
function test(name, time, f) {
console.time(name);
while (time --)f();
console.timeEnd(name);
}
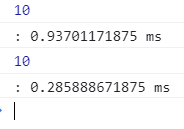
test('range', 10, () => reduce(add, range(1000000))); // 379.27294921875ms
test('L.range', 10, () => reduce(add, L.range(1000000))); // 268.756103515625mstake
Iterable에서 원하는 갯수만큼의 값을 얻어오는 함수.
const take = (l, iter) => {
let res = [];
for (const a of iter) {
res.push(a);
if (res.length === l) return res;
}
return res;
};
log(take(5, range(1000000)));//[0,1,2,3,4]
log(take(5, L.range(1000000)));//[0,1,2,3,4]
log(take(5, range(Infinity)));//에러 발생
log(take(5, L.range(Infinity)));//[0,1,2,3,4] 무한수열을 적용해도 동작한다. take - Currying 적용
const take = curry((l, iter) => {
let res = [];
for (const a of iter) {
res.push(a);
if (res.length === l) return res;
}
return res;
});
console.time('');
go(
range(10000),
take(5),
reduce(add),
console.log
);
console.timeEnd('');
console.time('');
go(
L.range(10000),
take(5),
reduce(add),
console.log
);
console.timeEnd('');- 위에서 설명한 지연평가를 사용하는 이유에 적합한 결과가 나왔다.
제너레이터/이터레이터 프로토콜로 구현하는 지연평가
지연평가(Lazy Evaluation)은 영리한 평가라고도 불리고 제때 계산법이라고도 불립니다.
평가를 최대한 미루다가 정말 필요할 때 평가를 하는 기법으로이다.
위 예제를 보면 실제로 reduce같은 함수에서 a,b같은 인자값을 받으려하는 그 시기에 2개의 값만 생성해서 전달하여 연산의 횟수를 줄이는 효율적인 방식을 볼 수 있다.
제너레이터/이터레이터 프로토콜로 구현한 이터러블 중심의 프로그래밍 기법은 앞서 구현한 map, filter, reduce, take 등등 이터러블을 활용한 프로그래밍을 말하며 앞으로 이터러블 프로그래밍 기법의 지연성 구현 방법을 알아보자.
L.map
기존 map에서 제너레이터/이터레이터기반의 지연성을 가진 L.map을 구현
L.map = function* (f, iter) {
for (const a of iter) {
yield f(a);
}
};
let it = L.map(a=>1+10, [1, 2, 3]);
console.log(it.next()); //{value: 11, done: false}
console.log(it.next()); //{value: 12, done: false}
console.log(it.next()); //{value: 13, done: false}
console.log(it.next()); //{value: undefined, done: true}
it = L.map(a=>1+10, [1, 2, 3]);
log([...it]) //[11,12,13]함수를 호출 할 당시에는 평가가 이루어지지 않고 호출 이후 여러 값에 대한 연산이 필요한 경우 값이 평가되어지는 것을 볼 수 있다. 그리고 map과 달리 새로운 배열을 반환하지도 않는다.
L.filter
L.filter = function* (f, iter) {
for (const a of iter) {
if(f(a)) yield a;
}
};
let it = L.filter(a => a % 2, [1, 2, 3, 4]);
console.log(it.next()); //{value: 1, done: false}
console.log(it.next()); //{value: 3, done: false}
console.log(it.next()); //{value: undefined, done: true}
console.log(it.next()); //{value: undefined, done: true}
it = L.filter(a => a % 2, [1, 2, 3, 4]);
log([...it]); // [1,3]value가 undefined이거나 done이 true가 될 때까지 값을 생성하여 반환한 것을 볼 수 있다.
지연성 여부에 따른 중첩 함수 비교
range, map, filter, take - 지연성 X
go(range(10),
map(n => n + 10),
filter(n => n % 2),
take(2),
console.log
); // [11,13]실행순서
- range => [ 0,1,2,3,4,5,6,7,8,9 ]
- map => [10,11,12,13,14,15,16,17,18,19]
- filter => [11,13,15,17,19]
- take => [11,13]
- console.log => 출력
L.range, L.map, L.filter, take - 지연성 O
const L = {};
L.range =function* (l) {
let i = -1;
while (++i < l) {
yield i;
}
};
L.map = curry(function* (f, iter) {
iter = iter[Symbol.iterator]();
let cur;
while (!(cur = iter.next()).done){
const a = cur.value;
yield f(a);
}
});
L.filter = curry(function* (f, iter) {
iter = iter[Symbol.iterator]();
let cur;
while (!(cur = iter.next()).done){
const a = cur.value;
if (f(a)) yield a;
}
});
const take = curry((l, iter) => {
let res = [];
iter = iter[Symbol.iterator]();
let cur;
while (!(cur = iter.next()).done){
const a = cur.value;
res.push(a);
if (res.length === l) return res;
}
return res;
});
go(L.range(10),
L.map(n => n + 10),
L.filter(n => n % 2),
take(2),
console.log
); // [11,13]실행순서
- take에서 값 저장을 위해 L.filter 호출
- L.filter에서 값 비교를 위해 L.map을 호출
- L.map에서 값 변경 함수를 실행 하기 위해 필요한 값을 받기 위해L.range 호출
- L.range에서 값 1개 생성 후 L.map에 전달
- L.map은 받은 값을 변경 함수 적용하여 L.filter에게 전달
- L.filter는 받은 값을 조건 검사하여 값을 take에 전달
- take는 값의 제한 숫자를 비교하며 값 저장
효율성 비교
지연성이 없는 중첩 함수의 경우 함수 첫 부분부터 평가를 끝내면서 모든 값이 생성되어진 상태의 요소들에 조건들을 검사하며 호출이 종료된다.
반면에 지연성이 있는 중첩 함수의 경우 평가가 필요한 호출에 의해서만 평가가 이루어지며 값 1개를 생성되어진 상태를 가지고 요소에 조건들을 검사하며 호출이 종료되어 진다.
예를 들어 range에 주어진 값이 엄청 나게 커지게 된다면 지연성이 없는 경우는 엄청 큰 범위의 모든 값을 생성하고 또 모든 값의 조건을 비교하며 실행이 되어지지만 지연성이 있는 경우에는 좀 더 빠른 평가가 이루어진다.
map, filter계열 함수들의 결합 법칙
map, filter 계열 함수에는 특정한 방식으로 다르게 평가 순서를 바꾸어도 똑같은 결과를 만든다는 결합 법칙이 있다.
-
사용하는 데이터가 무엇이든지
-
사용하는 보조함수가 순수 함수라면 무엇이든지
-
map(a⇒a+10)에서a⇒a+10이 보조함수 -
순수함수 ?
- 동일한 입력에 대해 항상 동일한 출력을 반환하는 함수
- 외부의 상태를 변경하거나 영향을 받지 않는 함수
- 데이터 추출, for문 순회
-
ES6의 기본 규약을 통한 지연 평가의 장점
이러한 지연 평가 방식이 이전의 자바스크립트에서는 굉장히 복잡하거나 지저분한 방식으로 구현할 수밖에 없었다.
왜냐하면 공식적인 자바스크립트에 있는 값이 아니라 전혀 다른 형태의 규약들을 만들어, 해당하는 라이브러리 안에서만 동작할 수 있는 방식으로 구현해야 했기 때문이다.
ES6 이후에는 자바스크립트의 공식적인 값을 통해서, 함수와 리턴되는 실제 자바스크립트의 값을 통해서 지연 여부를 확인하고 원하는 시점에 평가하겠다 등의 자바스크립트와 개발자가 약속된 규약을 가지고 만들어갈 수 있도록 개선되었다.
ES6 이후에는 지연성을 다루는 데에 있어서 자바스크립트의 고유한, 약속된 값을 통해 구현, 합성, 동작이 가능해졌다.
이러한 방식으로 구현된 지연성은 서로 다른 라이브러리 또는 서로 다른 사람들이 만든 함수 등 어디에서든지 자바스크립트의 기본 값과 기본 객체를 통해 소통하기 때문에 조합성이 높다.
결과를 만드는 함수 reduce, take
map, filter 같은 함수들은 배열이나 이터러블한 값의 안쪽에 있는 원소들에게 함수들을 합성해놓는 역할을 한다. 그러나 reduce나 take와 같은 함수들은 그 안에 있는 값들을 꺼내서 더해버린다. 즉, 최종적으로 어떤 결과를 만드는 함수이다.
a, b, c, d 이렇게 값을 가지고 있는 배열이 있다면 a와 b를 꺼내어 더해버리는 것과 같은 방식으로, 배열이나 이터러블 형태의 값을 유지시키는 것이 아니라 실제로 그 안에 있는 값을 꺼내서 깨뜨려야 하기 때문이다.
map, filter 같은 함수들은 지연성을 가질 수 있다. 그러나 reduce 같은 함수는 실제로 연산의 시작을 알리는 함수이다. 함수들을 만들 때 map 계열 함수를 연속적으로 사용하다가 특정 지점에서 reduce 같은 함수를 통해 안에 배열이나 이터러블 형태를 깨뜨려 함수를 종료하거나 그 다음 로직을 만드는 등의 역할을 한다.
함수형 프로그래밍을 할 때도 a로부터 b라는 값을 만들고자 할 때, a를 받아서 map, filter 등을 반복하다가 reduce로 최종적으로 값을 만들어 리턴하겠다고 사고하면서 프로그래밍을 하면 좋다.
take도 값을 두 개만 yield하기로 약속하는 식으로 지연성을 줄 수는 있다. 그러나 실제로 몇 개로 떨어질지 모르는 배열에서 특정 개수의 배열로 축약하고 완성을 짓는 성질을 가지고 있기 때문에, take 자체가 지연성을 가지기보다는 take를 한 시점에서 연산이 이루어지는 것이 프로그래밍을 할 때에 보다 확실하고 편리하다. 또, 변수를 여러 군데에 할당할 때에도 더 용이하다.
queryStr 함수 만들기
결과를 만드는 함수 reduce를 응용해서 객체로부터 url의 queryString을 만드는 함수 queryStr을 구현하자.
const queryStr = pipe(
Object.entries,
map(([k,v])=>`${k}=${v}`),
reduce((a,b)=>`${a}&${b}`)
);
console.log(queryStr({limit: 10, offset:10, type: 'notice'}));
// limit=10&offset=10&type=noticeArray.prototype.join보다 다형성 높은 join 함수 만들기
이 함수에서 reduce가 하는 연산은 Array.prototype.join함수와 비슷하다.
join은 Array.prototype에만 있는 함수이지만, reduce는 이터러블 객체를 모두 순회하면서 축약할 수 있기 때문에 더 다형성이 높은 join 함수를 만들 수 있다.
좀더 간결하고, 재사용 가능한 join함수를 reduce를 통해 만들어보자.
const join = curry((sep = ',', iter) =>
reduce((a, b) => `${a}${sep}${b}`, iter));
const queryStr = pipe(
Object.entries,
map(([k, v]) => `${k}=${v}`),
join('&')
)
// limit=10&offset=10&type=notice
console.log(queryStr({limit: 10, offset:10, type: 'notice'}));원래의 join은 배열에 특정 seperator를 줘서 문자열로 만들 수 있는 메서드이다. 다만, 앞에 있는 객체가 반드시 배열이어야 사용이 가능하다.
그러나 우리가 만든 join은 배열이 아니어도 사용 가능하다. 받는 값을 reduce를 통해 축약하기 때문이다.
function *a() {
yield 10;
yield 11;
yield 12;
yield 13;
}
console.log(join(' - ', a())); // 10 - 11 - 12 - 13이 join 함수는 훨씬 조합성이 높다. 또한 reduce를 통해 만들었기 때문에, 이터러블 프로토콜을 따른다.
즉, join에게 가기 전의 값들을 지연시킬 수 있다. join연산 전의 객체를 출력해보면 이미 다 계산을 마치고 만들어진 배열이다.
L.map을 사용하여 아직 연산이 되지 않은 상태의 이터레이터를 join에게 주어, join이 안쪽에서 next를 통해 결과를 필요한 상황에 연산하는 식으로 미룰 수도 있다.
또, 앞의 entries 메서드 역시 지연성을 가지도록 할 수 있다.
L.entries = function *(obj) {
for (const k in obj) yield [k, obj[k]];
};
const join = curry((sep = ',', iter) =>
reduce((a, b) => `${a}${sep}${b}`, iter));
const queryStr = pipe(
L.entries,
map(([k, v]) => `${k}=${v}`),
join('&')
)
// limit=10&offset=10&type=notice
console.log(queryStr({limit: 10, offset:10, type: 'notice'}));이렇게, Array.prototype.join보다 훨씬 다형성이 높은 join함수를 만들었다. 이는 객체지향의 클래스 기반 추상화보다 훨씬 유연한 방식이라고 할 수 있다.
find 함수 만들기
join은 reduce 계열, 즉 reduce로 만들 수 있는 함수이다. 반면 L.entries는 map 계열의 함수이다.
함수형 프로그래밍은 어떤 계열 혹은 계보를 가지는 식으로 함수를 만들 수 있다. 이번에는 find 함수를 take를 통해 만들어볼 것이다.
const users = [
{ age: 32 },
{ age: 31 },
{ age: 37 },
{ age: 32 },
{ age: 28 },
{ age: 25 },
{ age: 32 },
{ age: 31 },
{ age: 37 }
]
const find = curry((f, iter) =>
go(
iter,
L.filter(f),
take(1),
([a])=>a
));
go(
users,
L.map(u => u.age),
find(n => n < 30),
console.log
) // 28
인자값으로 받은 iter값을 L.filter로 이터러블객체를 take에 전달하면 take함수에서 실제로 결과를 만들어내기위해 값들을 호출하게되고 filter 조건에 부합하는 값을 찾으면 반환하며 전달 후 구조분해하여 반환합니다.
지연평가를 사용하였기에 filter 부분에서 모든 값을 다 조건과 비교하며 비교 후 완성된 값을 반환하는게 아닙니다. generator 호출을 계속 시도하여 filter 조건과 비교하며 부합된 값을 찾는데 take(1)이기에 하나의 값을 찾는 순간 로직은 종료되며, 만일, users의 목록이 1000만개인데 10만개쯤에서 결과를 찾는다면 그 뒤 990만번의 불필요한 연산을 막을 수 있습니다.
지연을 활용한 map과 filter 리펙토링
지연평가 L.map과 L.filter를 활용하여 즉시평가 map과 filter를 만드는 방법은 결과를 만들어내는 함수 take를 이용하면 간단하게 구현이 가능합니다.
take를 통해 지연성을 제공하는 이터러블객체를 실제 호출하여 값이 더이상 안나올때까지 꺼내게 됩니다.
const map = curry(pipe(L.map, take(Infinity)));
const filter = curry(pipe(L.filter, take(InfiL.flatten, flatten
이터레이터 객체(배열,맵,등..)에는 내부에 또 다른 이터레이터를 가지고 있을 수 있습니다.
flatten은 이런 이터레이터 안의 이터레이터를 평탄화해서 펼쳐주는 역할을 합니다.
L.flatten
// isIterable을 통해 이터러블객체인지 평가합니다.
const isIterable = a => a && a[Symbol.iterator];
L.flatten = function* (iter) {
for (const a of iter) {
if (isIterable(a)) {
for (const b of a) yield b;
} else {
yield a;
}
}
};flatten
이전에 만든 지연성 함수를 결과를 도출해내는 함수(take, reduce)를 통해 즉시평가가 가능하게 합니다.
const flatten = pipe(L.flatten, take(Infinity));L.flatMap, flatMap
flatMap은 flatten과 map을 동시에 작업해주는 함수인데, 최신 자바스크립트에서는 해당 기능이 추가되어있습니다.
하지만 자바스크립트가 기본적으로 지연평가가 아닌 즉시평가이기 때문에 우리는 지연성을 가지는 L.flatMap 함수를 만들 수 있다.
flatMap은 결국 map과 flatten 로직의 결합이기 때문에 아래와같이 사용해도 동일합니다.
//[1, 4, 9, 16, 25, 36, 49]
flatten([[1,2],[3,4],[5,6,7]].map(a=>a.map(a=>a*a))); 하지만 즉시평가 flatMap의 경우 불필요한 연산을 해야하는 경우가 있기 때문에 지연성을 제공하는 flatMap이 효율적이다.
L.flatMap = curry(pipe(L.map, L.flatten));
//즉시평가 flatMap
const flatMap = curry(pipe(L.flatMap, takeAll));2차원 배열 다루기
2차원 배열을 가지고 기존에 구현한 함수들을 응용해 로직을 수행할 수 있습니다.
const arr = [
[1, 2],
[3, 4, 5],
[6, 7, 8],
[9, 10]
];
// 홀 수만 꺼내기
go(arr,
L.flatten,
L.filter(a => a % 2),
takeAll,
console.log
) // [1, 3, 5, 7, 9]
// 홀 수의 합
go(arr,
L.flatten,
L.filter(a => a % 2),
reduce(add),
console.log
)//25
// 홀 수 3개만 꺼내 제곱하기
go(arr,
L.flatten,
L.filter(a => a % 2),
take(3),
map(a=>a*a),
console.log
)//[1, 9, 25]마치며
최신 javascript에서도 flatMap, map, foreach, reduce등 대부분의 기능을 기본적으로 제공하고 있습니다. 그런데 어째서 이렇게 사용자정의로 구현한 함수들을 사용할까요?
위의 코드들이 기본으로 제공되는 API 로직과 가장 큰 차이점은 지연평가로인한 불필요한 연산 및 결과도출의 생략입니다.
즉시평가로 할 경우 filter등에서 arr의 모든 값 1~10까지 다 꺼내어 조건 함수와 비교 후 참인 값들을 꺼냅니다. 하지만, 지연평가의 경우 필요한 수치까지 다 가져오면(ex:3개만 가져오는 take(3) 함수) 더이상의 결과도출을 하지 않고 로직이 종료됩니다.
이러한 이점들을 극대화하여 활용하는 방법들에 대하여 알아보았습니다.
