Introduction: Procedure
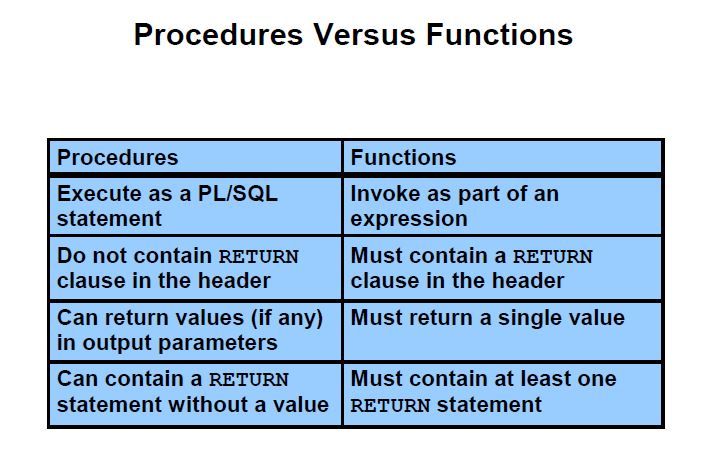
Procedure는 특정 동작을 수행하는 서브 프로그램이다. 사용자는 이를 호출하기 전에 반드시 procedure를 선언하고 정의해야 한다. 사용자는 선언과 정의를 동시에 할 수 있으며, 또는 먼저 선언한 후 같은 block 또는 서브 프로그램 내에서 이를 정의할 수 있다.
(A procedure is a subprogram that performs a specific action. You must declare and define a procedure before invoking it. You can either declare and define it at the same time, or you can declare it first and then define it later in the same block or subprogram. -Oracle Docs)
보충하여 이는 일련의 작업 절차를 저장, 호출하여 재사용 하는 것이 가능하다. Procedure에는 리턴값이 존재하지 않고, 매개변수 in/out을 통해 호출부로 값 전달이 가능하다. 일반 SQL문에서는 이용할 수 없기에 PL/SQL 구문에서 사용해야 하고, 다른 Procedure (e.g. Anonymous Block) 또는 다른 Client Program에 의해 호출되는 구조이다.
Syntax: Creat and Invoke a Procedure
<<Create a Procedure>>
creat or replace procedure PROC-NAME(Val1, Val2 ...add'l)
IS
<FIELD-VALS ON HERE>
BEGIN
<EXECUTE-STATEMENT ON HERE>
end;
/
<<Invoke a Procedure>>
BEGIN
PROC-NAME
END;
/--CERATE A PROCEDURE create or replace procedure proc_delete_emp( p_emp_id emp_test1.emp_id%type ) IS BEGIN delete from emp_test1 where p_emp_id = emp_id; dbms_output.put_line(p_emp_id || 'successfully deleted.'); END; / --INVOKE A PROCEDURE BEGIN proc_delete_emp(&number) dbms_output.put_line(SQL%ROWCOUNT || ' rows successfully deleted.') END; /
create procedure의 경우 역시 create or replace 구문을 지원하므로, 이를 가급적 활용하는 것이 권장된다. 상기했듯 Procedure는 일반 SQL문에서 사용이 불가능하므로, 이를 호출할 때 역시 PL/SQL 구문 내에서 호출하여야하며 이 때 DECLARE절은 생략이 가능하다.
Syntax: Upsert(Update + Insert) with Procedure
<<Upsert (Update + Insert) with Procedure>>
create or replace procedure PROC_NAME(
Val1 in Tab.Col%type,
Val2 in Tabl.Col%type(add'l)
)
IS
Val-On-Field DataType;
BEGIN
select Col
into Val-On-Field
from Tab
where Condition
if Val-On-Field Num then
insert into Tab values(Val1, Val2);
else
update Tab set Col2 = Val2
where Col1 = Val1
end if;
commit; (add'l)
END:
/--CREATE UPSERT-PROCEDURE create or replace procedure proc_upsert_job( p_job_code in job.job_code%type, p_job_name in job.job_name7type ) IS cnt number; BEGIN select count(*) into cnt from job where job_code = p_job_code; if cnt = 0 then insert into job values(p_job_code, p_job_name); else update job set job_name = p_job_name where job_code = p_job_code; end if; commit; END; / --INVOKE THE UPSERT-PROCEDURE execute proc_upsert_job('J8', 'Intern'); select * from job;
Upsert란 Update와 Insert의 합성어로, 특정 값등이 존재하지 않는다면 Insert(즉 CRUD의 Create, 생성), 해당 값이 이미 존재한다면 Update(갱신)함을 의미한다. 해당 Procedure를 생성할 때에 가장 중요한 것은 변수에 의한 분기 처리이다. 어떤 값을 기준으로 생성과 갱신을 나눌 것인가? 어떠한 개체를 생성하고 갱신할 것인가?
위의 예제 코드에서 전자에 해당하는 분기는 if cnt = 0 then 및 where job_code = p_job_code 에서 나뉘었으며, 후자는 insert into job values(p_job_code, p_job_name)에서 나뉘었다. job 테이블 안에서 job_code와 job_name은 분류상 대응되는 값이다. 다시 말해, 부정한 데이터가 존재하지 않는다는 전제 하에 job_code과 job_name은 직급이라는 같은 기준에 의해 분할되어 있기 때문에 job_code 또는 job_name 중 열의 한 값이 존재하지 않는다면 반대 열의 상응 값도 존재하지 않는 것이 된다. if 조건절에서 cnt는 바로 이 점을 이용하여 해당 직급이 존재하는지 그 여부를 수를 세어 확인한다. 즉, 해당 프로시져의 첫 번째 파라미터로 받은 직급 코드가 존재하지 않는다면, 이와 더불어 2번째 파라미터로 받은 직급명 데이터를 함께 생성하는 것이다.
이러한 분기 구조는 매우 유용하다. 다양한 활용이 가능하니 눈여겨 봐두자.
Introduction: DML Trigger
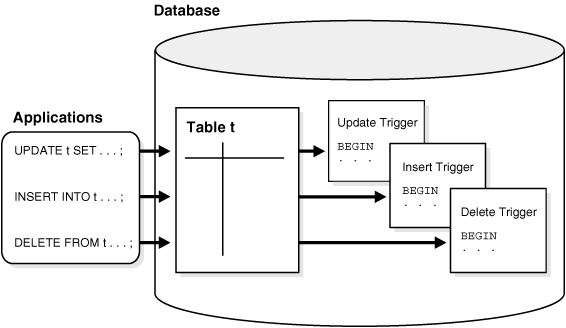
일종의 방아쇠. 특정 이벤트가 실행되면 저장된 코드가 실행된다. 예를 들어 Trigger 내부에 선언한 특정 테이블에 insert, update, delete와 같은 DML 코드가 실행되게 되면 또 다른 테이블에 전자 테이블의 변동 사항을 저장하는 등의 처리가 가능하여 일종의 Bridge 역할을 수행한다. 또한 Trigger 내부에서는 Transaction 처리가 불가능하다. 때문에 One-DML-Statement의 앞 또는 뒤에서 실행할 수 있으며 before/after 설정이 가능하다. for each Option을 통해 Statement Level Trigger, Row Level Trigger로 나뉜다.
Syntax: Basic DML Trigger(Row Level)
<<DML Trigger - Basic>>
create or replace trigger Trigger-Name
before/after
insert/update/delete on Tab
for each row
BEGIN
Execute-Statement
END;
/create or replace trigger trg_member_insert before insert on member for each row BEGIN insert into member_insert values (:new.member_name, :new.member_password) END; / --TESTCODE insert into member values ('park', '1234');
해당하는 문법은 실행문에 별도로 trigger와 연결하는 문법 또는 구문을 설정해 주지 않아도 자동으로 Trigger가 작동하게 된다. Trigger를 생성할 때에 해당 Table에 Trigger를 달아두었기 때문에 해당 Table에 새로운 값을 insert into하게 되면 자동으로 Trigger가 실행되어 새로운 테이블(여기서는 member_insert)에 값이 대입되는 것이다.
이는 해당 구문 내부에서 Transaction 처리가 불가능하므로, One DML Statement와 함께 trigger 내부의 DML 또한 commit/rollback된다. One DML Statement를 여러 번 실행하게 되면 기록은 총 합계가 아닌 log의 형태로 기록되므로, 실행 단위대로 새로운 row가 추가되는 형태로 반영된다.
Syntax: Stock Management with Trigger + Conditional Expression
<<Stock Management with Trigger + Conditional Expression>>
create or replace trigger Trigger-Name
before/after
insert on Tab2
for each row
BEGIN
if :new.StatusCol = Val1 then
update Tab1 set StockCol = StockCol+ :new.AmountCol
where ProductCodeCol = :new.ProductCodeCol;
else
update Tab2
set StockCol = StockCol - :new.AmountCol
where ProductCodeCol = :new.ProductCodeCol;
end if;
END;
/create table product( pcode number primary key, pname varchar2(30), brand varchar2(30), price number, stock number default 0 );--IN & OUT TABLE - FOR STOCK MANAGEMENT create table product_io( iocode number primary key, pcode number, iodate date default sysdate, amount number, status char(1) check (status in ('I', 'O')), constraints fk_product_io foreign key (pcode) references product(pcode) );create sequence seq_product; create sequence seq_product_io; insert into product(pcode, pname, brand, price) values (seq_product.nextval, '갤럭시20', '삼성', 1200000); insert into product(pcode, pname, brand, price) values (seq_product.nextval, '아이폰11', '애플', 1500000); insert into product(pcode, pname, brand, price) values (seq_product.nextval, 'LG 벨벳', 'LG', 1000000); commit;--trigger, insert -> stock update create or replace trigger trg_product_stock after insert on product_io for each row BEGIN if :new.status = 'I' then update product set stock = stock + :new.amount where pcode = :new.pcode; else update product set stock = stock - :new.amount where pcode = :new.pcode; end if; END; /insert into product_io values (seq_product_io.nextval, 1, default, 10, 'I'); insert into product_io values (seq_product_io.nextval, 2, default, 5, 'O'); commit; select * from product; --Product Stock - Constraint alter table product add constraints ck_product_stock check (stock >= 0);
위의 코드는 Trigger와 Conditional Expression을 활용하여 재고 관리 DB를 자동화한 예시이다. 이는 1. 상품 관리 테이블과 2. Identifier로 활용할 Sequence를 생성하여 이에 대입하고 3. 상품의 입출고 내역을 기록할 별도의 테이블을 생성한 후 4. 1의 상품 관리 테이블에 변동사항이 발생하면 Trigger가 발동하여 3의 테이블에 그 내역을 자동으로 저장하는 구조이다.
해당 Trigger를 작성할 때에 가장 주의해야 하는 부분은 if Statement를 통한 분기처리와 그 조건부의 설정이다. 상기한 코드에서는 식별자 'I' 및 'O'를 받아 입/출고의 경우로 분기하며, Pseudo :new를 활용하여 [기존수량] [+/-] [신규 입고/출고 수량]의 수식으로 새로운 테이블에 저장하고 있다.
Remark: Virtual Record - PSEUDO in DML Trigger
<<Virtual Record - PSEUDO in DML Trigger>>
PSEUDO: :old.
PSEUDO: :new.
w.Insert Statement: :old. = null, :new. = newly inserted
w.Update Statement: :old. = row before the update :new. = row after the update
w.Delete Statement: :old. = row before the delete, :new. null
상기했듯 Trigger는 해당 Table에 대한 변경사항을 감지하고 사용자가 설정한 동작을 수행한다. 이 때, 기존 내역/변동 내역에서 추출할 값을 특정하기 위해 Virtual Record(의사레코드), 즉 Pseudo :old와 :new를 활용하고 있다. 이 의사레코드는 어떠한 DML문과 조합하느냐에 따라 가리키는 바가 다르다:
1. insert문/ :old = null, :new = 새로 입력된 행
2. update문/ :old = 변경 이전 행, :new = 변경 이후 행
3. delete문/ :old = 삭제 이전 행 :new = null
Remark: SQL%ROWCOUNT
<<Count - SQL%ROWCOUNT>>
--e.g. --CREATE A TABLE FOR TEST create table employee as select * from employee; --COUNT THE ROW-COUNT WITH CONDITIONAL UPDATE STATEMENT BEGIN update employee set salary = salary * 1.05 where salary < 2000000; dbms_output.put_line('Updated'|| SQL%ROWCOUNT||' salaries'); END; /
얼마나 많은 행이 DML구문에 의해 영향을 받았는지 찾기 위해서는 SQL%ROWCOUNT의 값을 확인하면 된다고 Oracle Docs는 설명하고 있다. (To find out how many rows are affected by DML statements, you can check the value of SQL%ROWCOUNT -Oracle Docs) 변수를 별도로 선언하여 이 SQL%ROWCOUNT를 대입하여 사용하여도 되지만, PL/SQL블럭 내의 출력 구문에 바로 대입해도 해당 구문으로 인해 영향을 받은 행의 수를 결과로 확인할 수 있다.
