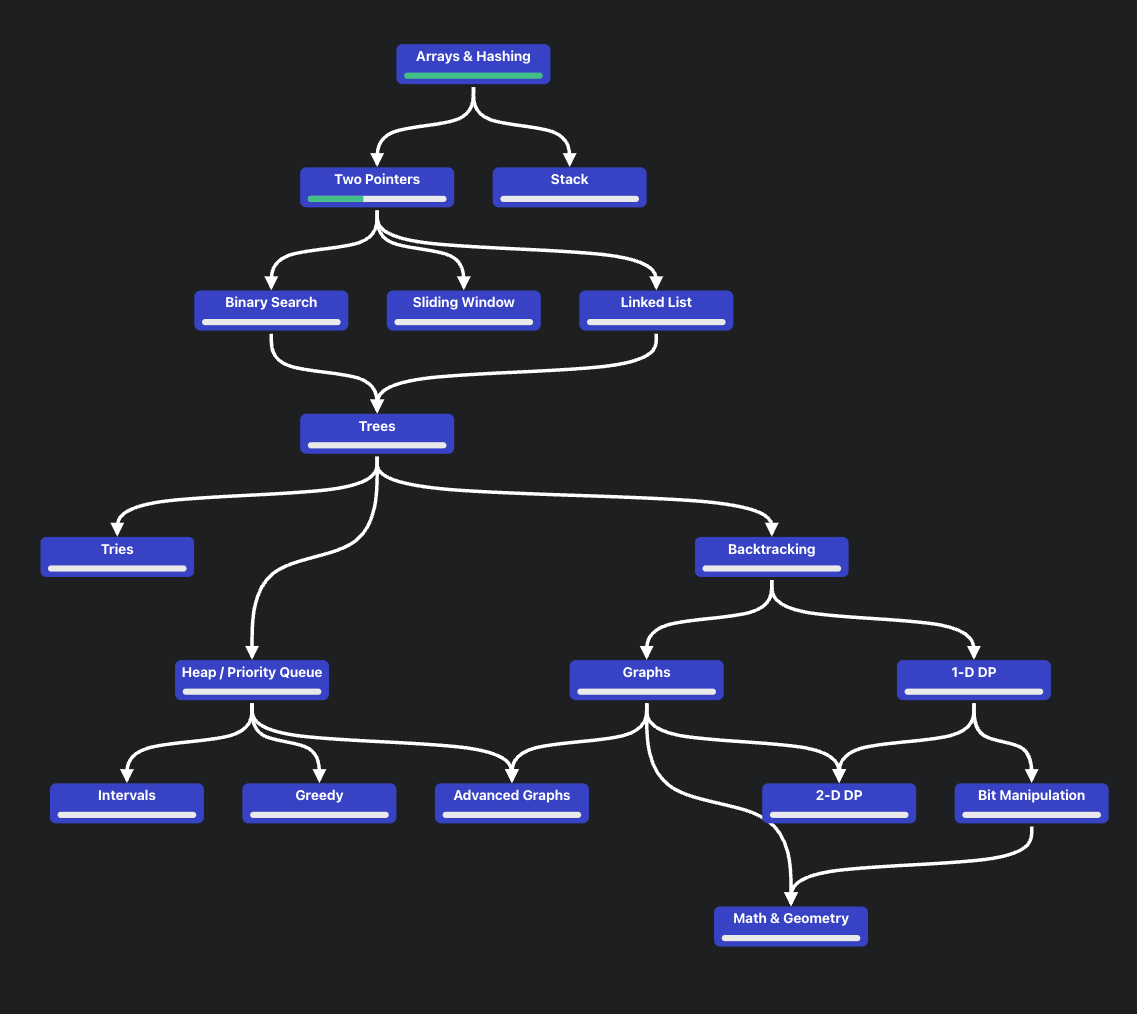
알고리즘 공부를 뭐부터 어떻게 시작 해야 할 지 막막하다..싶을 때는 needcode의 알고리즘 로드맵을 따라가면 좋다 !
근데, 내가 해보니.. 그래도 알고리즘과 자료구조의 기초?중의 기초가 좀 있어야 따라 갈만하다.. 아니면..... 첫문제부터 난관에 봉착한다..^^....(그게 나야나..)
그래서 첫문제 풀면서 여러 fundemental 및 스위프트 문법들을 찾아본다구.. 1문제 푸는데.. 오랜 시간이 걸리더라며...ㅎ 근데 시간이 지날수록 겹치고, 아는 fundemental 혹은 문법들이 보이니 점점 하면 할수록 시간이 조금씩? 단축 되는 느낌이다 !
Array(배열) : 같은 자료형을 갖는 여러 원소(데이터)를 하나의 변수 이름으로 모아 놓은 데이터 집합
1)<인덱스,원소값> 쌍의 집합
2)원소(데이터)의 논리적순서와 저장된 물리적 순서가 같음
3)인텍스를 이용, 빠른 임의 접근 가능(임의의 순서로 데이터를 처리하는 경우 유용하게 사용)
4)원소들의 순차적 저장, 데이터의 삽입,삭제가 발생하는 경우 시간적인 오버헤드가 발생하는 단점이 이씅ㅁ ! (이동대상이 되는 원소가 많을 경우 큰부담)
5)중복을 포함 할 수 있는 값 모음이 필요하거나 항목의 순서가 중요한 경우 배열을 사용
Hashing(해싱) : 탐색 키값을 기반으로 데이터의 저장 위치를 직접 계산함으로써 기본적인 상수시간내에 데이터를 탐색,삽입,삭제 할 수 있는 방법
1)해싱은 데이터를 해싱테이블로 관리
-해싱테이블 : 각 원소의 저장 위치를 직접 찾을 수 있도록 각 위치마다 주소가 부여 되어 있는 저장 공간 (배열과 유사)
2)키값을 주소로 바꾸기 위해 해시함수(hash funchion)을 사용
3)해싱은 키값을 주소로 가진 여러개의 데이터가 존재하는 응용에는 적용 할 수 없음.
4)해시 함수 (제산잔여법, 비닝,중간제곱법,문자열을 위한 함수)
5) 충돌 해결 방법법 1.개방해싱(or 연쇄법) 2.폐쇄해싱(or 개방 주소법),버킷해싱,선형탐사(1차클리스터링 문제) 3.이차탐사(2차 클리스터링).이중해싱
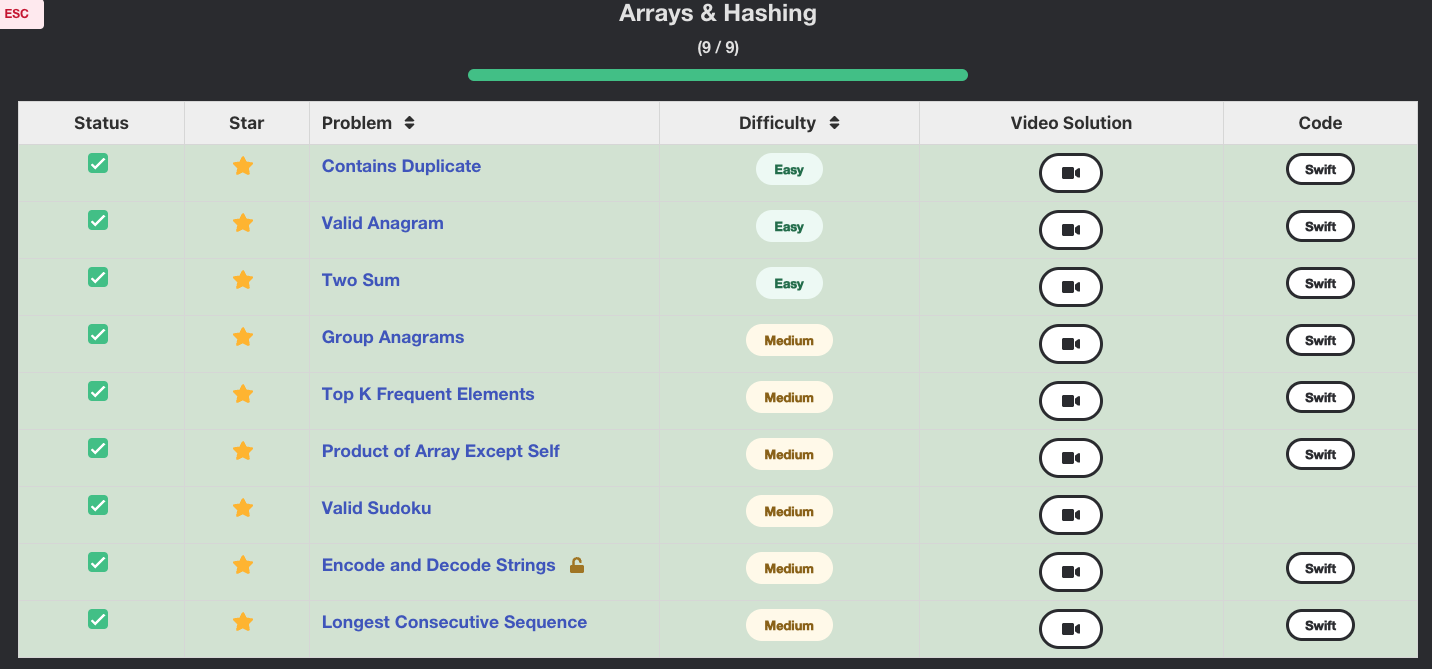
Array & Hashing 부터 시작 ! 해싱의 개념은 보통 알고리즘에서 뒷쪽에 배우는데.. 바로 앞쪽으로 땡겨서 있다.. 사실 개념 자체가 Array와 Hashing이 유사한 점들이 있어서 그런거 같다.
여기서 푸는 문제는 leetcode.com에 일부 문제들을 발췌해서 그 알고리즘과 연관된 문제를 푼다..
Arrays & Hashing 을 위한 9가지 문제다 !
1)Contains Duplicate (중복포함)
2)Valid Anagram (유효한 아나그램)
3)Two Sum (두 합)
4)Group Anagrams (그룹 아나그램)
5)Top K Requent Elements (상위 K 빈도 요소)
6)Product of Array Except Self (자신을 제외한 배열의 곱)
7)Valid Sudoku (유효한 수도쿠)
8)Encode and Decode Strings (암호화 & 해독 문자열)
9)Longest Consecutive Sequence (가장 긴 연속된 수열)
1)Contains Duplicate
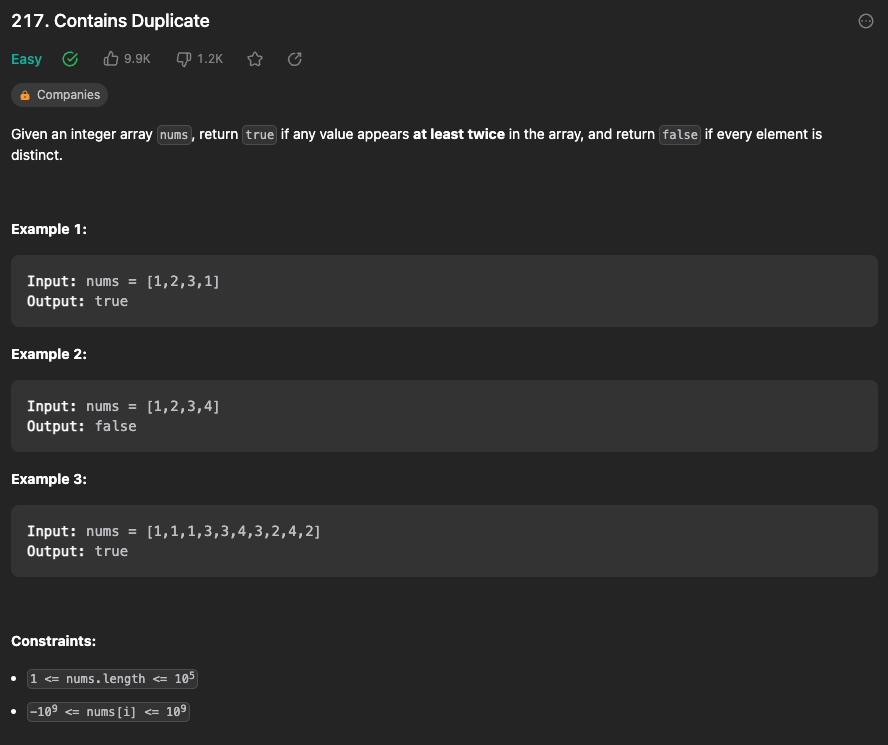
중복된 숫자가 배열안에 있으면 true 반환, 없으면 false 반환하는 문제 !
기본중의 기본문제인데.. 난 어렵더라며..ㅎ 코드 한줄 뭐라 적어야할지 막막하던..^^ 그 느낌 아실라나??

두가지 버전의 정답?을 가질 수 있음 ! 둘다 Set(집합)을 이용하는건데.. 스위프트에서 Set은 중복되지 않는 값을 저장하는 데이터 구조. 특히한 점은 순서를 가지지 않아, 배열과 달리 특정 항목에 인텍스로 접근이 불가능 하다 !
2)Valid Anagram
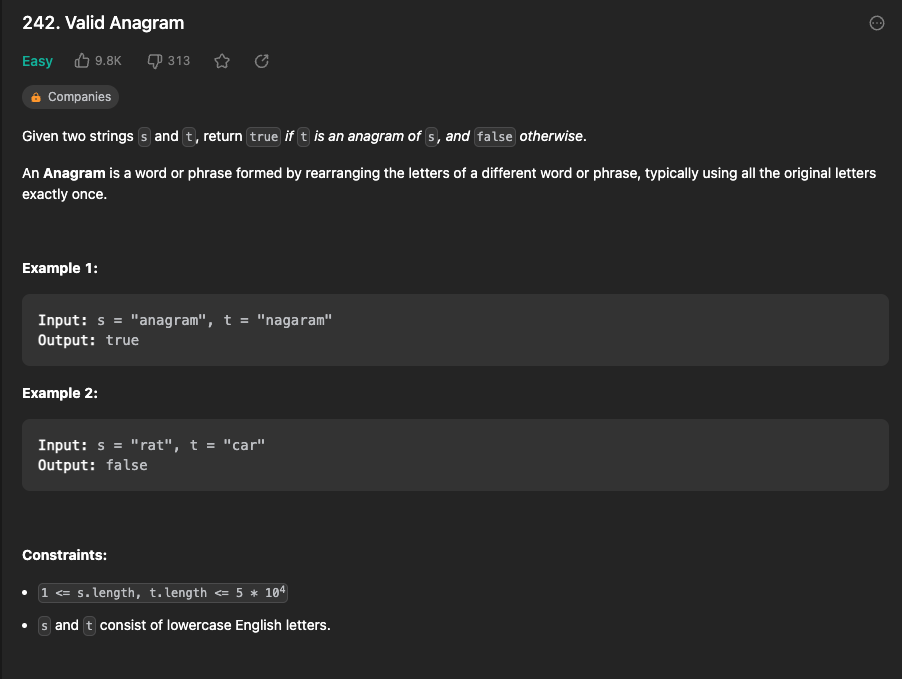
"Anagram"은 서로 다른 단어나 문구를 동일한 문자들로 재배열하여 새로운 단어나 문구를 만드는 것을 의미한다. 예) listen = silent 서로 아나그램이다.
둘다 l,i,s,t,e,n 각각 문자들이 순서만 다를 뿐 동일하게 되어 있다 !
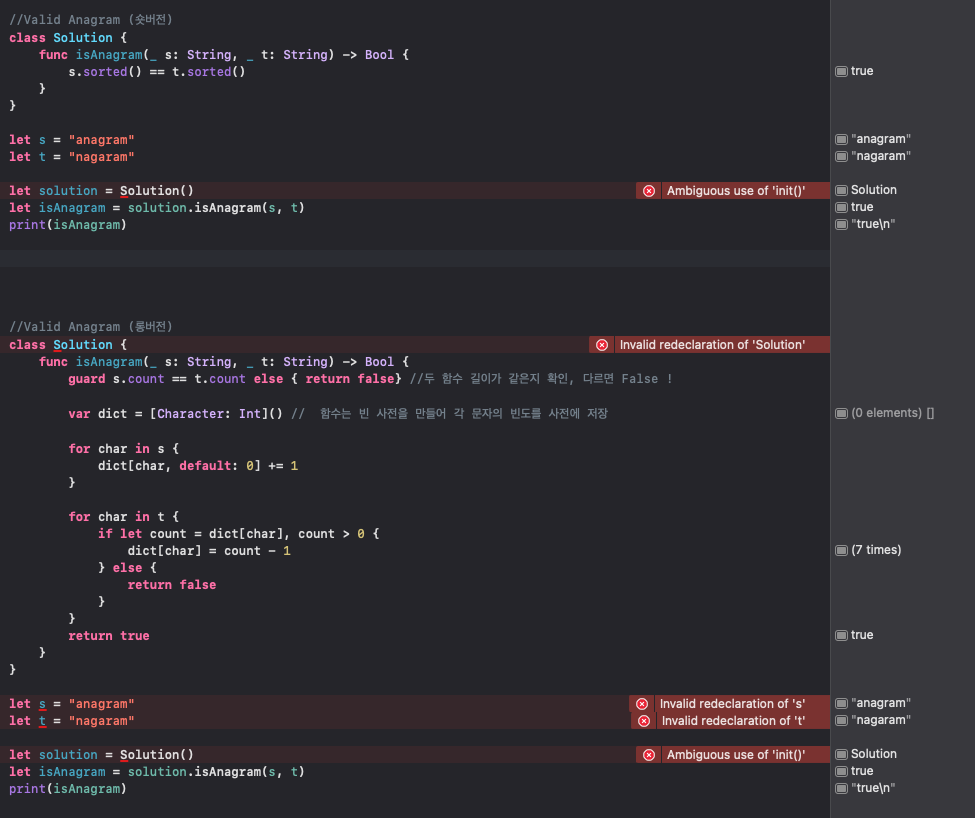
코드의 빨간 에러는 신경 안쓰셔도 된다..^^; 각각 맞는거다..
숏버전과 롱버전 두개로 할 수 있다 !
숏버전은 sorted() 정렬 메서드를 이용하면, 아주 짧게 한줄로 만들 수 있음 !
그러나 조금 더 심도 있게 공부(?)하려면 롱버전을 이해 하는게 중요 하다.
이 함수의 작동 원리는 다음과 같다 !
guard s.count == t.count else { return false }:
이는 s와 t의 길이가 같아야만 아나그램이 될 수 있다는 사실을 기반으로함
guard 문은 특정 조건이 충족되지 않을 경우 코드의 실행을 중단하는 역할을 합니다. 여기서는 두 문자열의 길이가 다르면 함수는 바로 false를 반환하며 종료.
var dict = Character: Int: 이는 각 문자가 몇 번 등장하는지 저장하기 위한 딕셔너리를 생성하는 코드. 문자는 Character로 표현되며, 해당 문자의 등장 횟수는 Int로 표현.
for char in s { dict[char, default: 0] += 1 }: 이 코드는 s의 각 문자를 순회하며 딕셔너리 dict에 해당 문자의 등장 횟수를 저장. dict[char, default: 0] += 1는 char이 딕셔너리에 존재하지 않으면 0을 기본값으로 하여 char의 개수를 1 증가시키는 코드.
for char in t { ... }: 이 코드는 t의 각 문자를 순회하며 딕셔너리에서 해당 문자의 등장 횟수를 줄인다. 만약 해당 문자의 개수가 0이거나, 딕셔너리에 존재하지 않으면 false를 반환하고 함수를 종료. 이는 s와 t가 아나그램 관계에 있지 않음을 의미.
return true: 모든 문자에 대해 이상이 없으면 true를 반환. 이는 s와 t가 아나그램 관계에 있음을 의미.
따라서, 이 함수는 두 문자열이 아나그램인지 판단하는 알고리즘을 구현. 문자열의 길이, 문자의 등장 횟수 등을 체크하여 판단하며, 이 과정에서 guard문, 딕셔너리 등 여러 Swift의 기능들을 활용하고 있다 !
3)Two Sum (두 합)
정수 배열(nums)안에 숫자들을 이용하여 두 숫자의 합이 target의 숫자가 어떤건지 인덱스 값을 찾는 알고리즘 문제이다. 각 입력에 정확히 하나의 해결책이 있다고 가정, 동일한 요소를 두 번 사용할 수 없음 ! 결과는 어던 순서로든 반환 할 수 있음 !
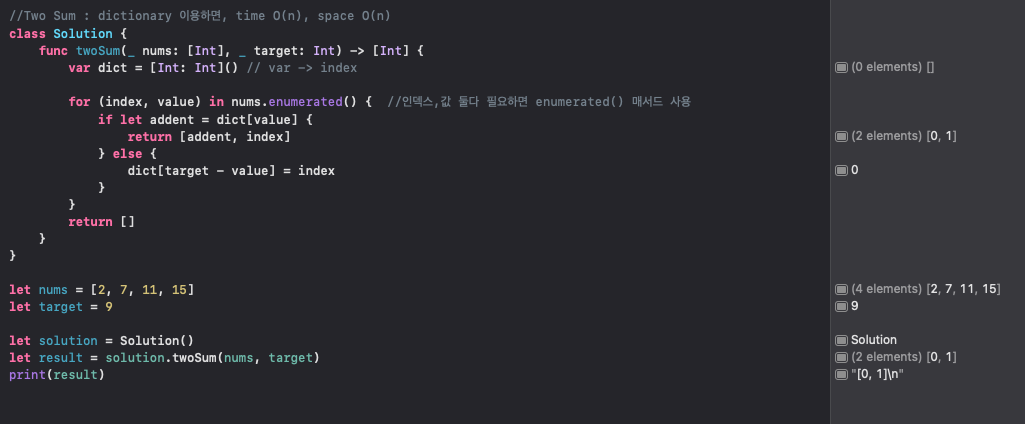
이 코드는 주어진 정수 배열에서 두 수를 더해서 목표값을 만드는 두 수의 위치(인덱스)를 찾는 함수이며, 자세한 설명은 다음과 같음 !
class Solution { ... }: Solution이라는 이름의 클래스를 정의하는 부분. 클래스는 관련된 변수와 함수를 묶어 관리하는 방법.
func twoSum( nums: [Int], target: Int) -> [Int] { ... }: Solution 클래스 내부에 twoSum이라는 이름의 함수를 정의. 이 함수는 두 개의 입력값을 받아오며, 입력값은 정수 배열(nums)과 목표값(target). _는 파라미터의 이름을 호출 시 생략하게 해줌. -> [Int]는 이 함수가 정수 배열을 반환함을 나타냄.
var dict = Int: Int: 빈 딕셔너리를 생성합니다. 여기서 '딕셔너리'는 키-값 쌍으로 데이터를 저장하는 자료구조입니다. 이 딕셔너리는 '숫자와 그 숫자의 위치'를 저장함.
for (index, value) in nums.enumerated() { ... }: nums 배열의 각 요소(value)와 그 요소의 위치(index)를 순회하는 반복문. enumerated() 함수는 배열의 각 요소와 그 요소의 인덱스를 함께 제공
if let addent = dict[value] { ... } else { ... }: 이 부분은 '현재 숫자(value)가 딕셔너리에 존재하는지'를 확인하는 조건문.
만약 존재한다면, addent에는 그 숫자의 위치(인덱스)가 저장되고, 그 때의 addent와 현재 index를 배열로 반환. 그렇지 않다면 else 절이 실행.
dict[target - value] = index: 목표값에서 현재 숫자를 뺀 결과를 딕셔너리의 키로, 현재 숫자의 위치를 값으로 딕셔너리에 저장. 이는 '이 키와 더했을 때 목표값이 되는 숫자'를 찾는 데 사용.
return []: 두 수를 찾지 못하고 배열의 모든 요소를 순회했다면, 빈 배열을 반환. 이는 입력된 배열에 목표값을 만들 수 있는 두 숫자가 없음을 나타냄.
결론적으로, 이 함수는 입력된 배열을 한 번만 순회하면서 '현재 숫자와 더했을 때 목표값이 되는 숫자'가 배열에 존재하는지 확인하고, 그 숫자의 위치를 반환. 이를 위해 딕셔너리라는 자료구조를 활용하여 각 숫자의 위치를 빠르게 찾아내는 알고리즘을 구현.
4)Group Anagrams (그룹 아나그램)
그룹 아나그램 문제이며, 주어진 문자열 배열 strs에 대해, 아나그램을 함께 그룹화, 결과는 어떤 순서로든 반환할 수 있음 !
아나그램이란 다른 단어나 문구의 문자를 재배열하여 만든 단어나 문구를 말함 ! (위에 valid anagram에서 설명함)
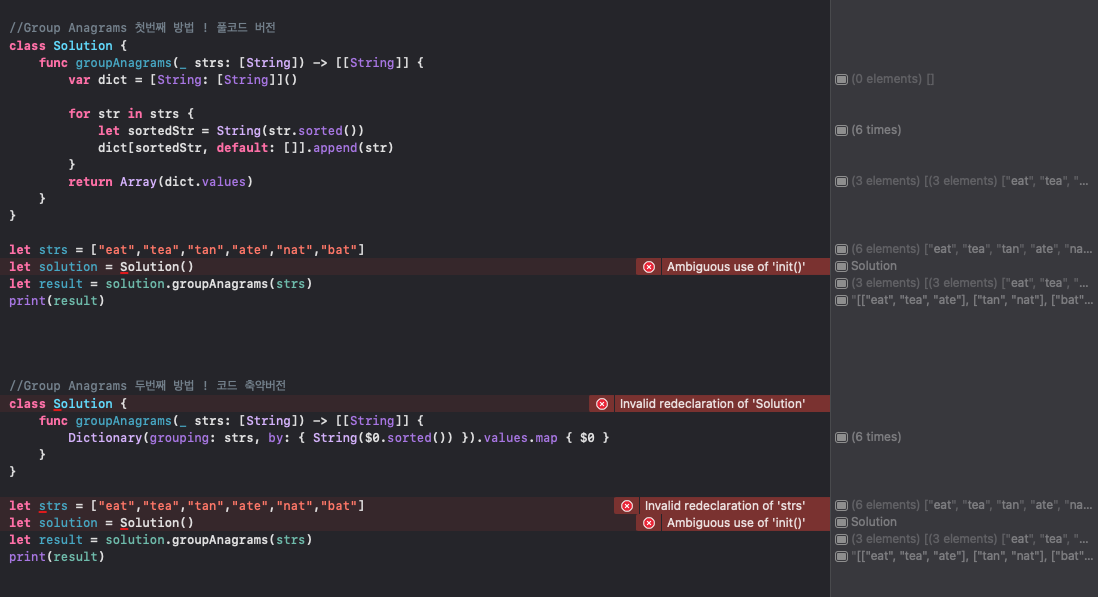
코드는 롱버전, 숏버전 둘다 있음 ! (물론, 내가 쓴 코드 말고도 다른 걸로도 만들 수도 있지.. 이게 무조건적인 정답은 아님^^)
<롱버전 설명>
이 함수는 주어진 문자열 배열에서 아나그램(문자의 순서에 상관없이 구성 문자가 동일한 단어나 구)을 찾아 같은 아나그램끼리 묶는 역할을 함.
class Solution { ... } - 이 부분은 Solution이라는 클래스를 선언하는 부분. 클래스는 Swift 언어에서 사용하는 개념으로, 관련된 데이터와 기능을 함께 묶는 방법.
func groupAnagrams(_ strs: [String]) -> [[String]] { ... } - 이 부분은 groupAnagrams라는 이름의 함수를 선언하는 부분입니다. 이 함수는 문자열의 배열을 입력으로 받고(strs), 이 문자열들을 묶은 2차원 배열을 출력으로 내보.
var dict = String: [String] - 이 부분은 빈 사전을 생성하는 부분. 이 사전의 키는 문자열(String)이고, 값은 문자열의 배열([String])
for str in strs { ... } - 이 부분은 입력으로 받은 strs 배열의 각 원소에 대해 반복을 수행하는 부분
let sortedStr = String(str.sorted()) - 이 부분은 현재 문자열의 문자를 정렬한 결과를 다시 문자열로 만드는 부분. 문자를 정렬하면, 아나그램들은 동일한 문자열을 갖게됨
dict[sortedStr, default: []].append(str) - 이 부분은 정렬된 문자열을 키로 갖는 사전의 값에 원래 문자열을 추가하는 부분. 만약 해당 키로 값이 없으면, 기본 값으로 빈 배열을 사용.
return Array(dict.values) - 이 부분은 사전의 모든 값을 배열로 만들어 반환하는 부분. 각 값은 아나그램 그룹을 나타내는 문자열의 배열.
따라서, 이 함수는 주어진 문자열 배열에서 아나그램을 찾아 같은 아나그램끼리 묶어 2차원 배열로 반환하는 역할.
<숏버전 설명>
이 코드는 주어진 문자열 배열에서 같은 문자를 사용하는 단어들을 모아 그룹화하는 함수를 구현한 것. 이 코드는 Swift 언어의 Dictionary, grouping 함수, 클로저, sorted 함수, 그리고 map 함수를 사용함.
class Solution { ... }: Solution이라는 이름의 클래스를 정의하는 부분. 클래스는 객체 지향 프로그래밍에서 사용하는 개념으로, 관련된 데이터와 함수를 하나로 묶어 관리하는 방법
func groupAnagrams( strs: [String]) -> [[String]] { ... }: Solution 클래스 내부에 groupAnagrams라는 이름의 함수를 정의함. 이 함수는 하나의 입력값(strs)을 받으며, 이는 문자열의 배열. 는 파라미터의 이름을 호출 시 생략하게 해줌. -> [[String]]는 이 함수가 문자열의 배열의 배열을 반환함을 나타냄
Dictionary(grouping: strs, by: { String($0.sorted()) }): Swift의 Dictionary(grouping:by:) 초기화자를 사용하여 strs의 각 문자열을 그룹화. 이 때, by:에 전달된 클로저 { String($0.sorted()) }에 의해 그룹화의 기준이 결정. 클로저는 문자열의 모든 문자를 정렬한 결과를 반환, 이 결과가 같은 문자열끼리 그룹화하게 됨.
.values.map { $0 }: Dictionary의 values 속성은 Dictionary의 모든 값들을 담은 컬렉션. map { $0 }는 이 컬렉션의 각 요소를 그대로 반환하는 함수를 적용한 결과를 배열로 만듬. 이렇게 함으로써 Dictionary의 값들을 배열로 변환하여 반환 하게 됨
따라서 이 함수는 주어진 문자열 배열에서 같은 문자를 사용하는 문자열끼리 묶은 그룹들의 배열을 반환하는 역할. 이를 위해 문자열의 문자들을 정렬하여 그룹화의 기준으로 사용.
5)Top K Requent Elements (상위 K 빈도 요소)
정수 배열 'nums'와 정수 'k'가 주어졌을때, 가장 빈도가 높은 상위 'k'개의 요소를 반환 하는 문제 !
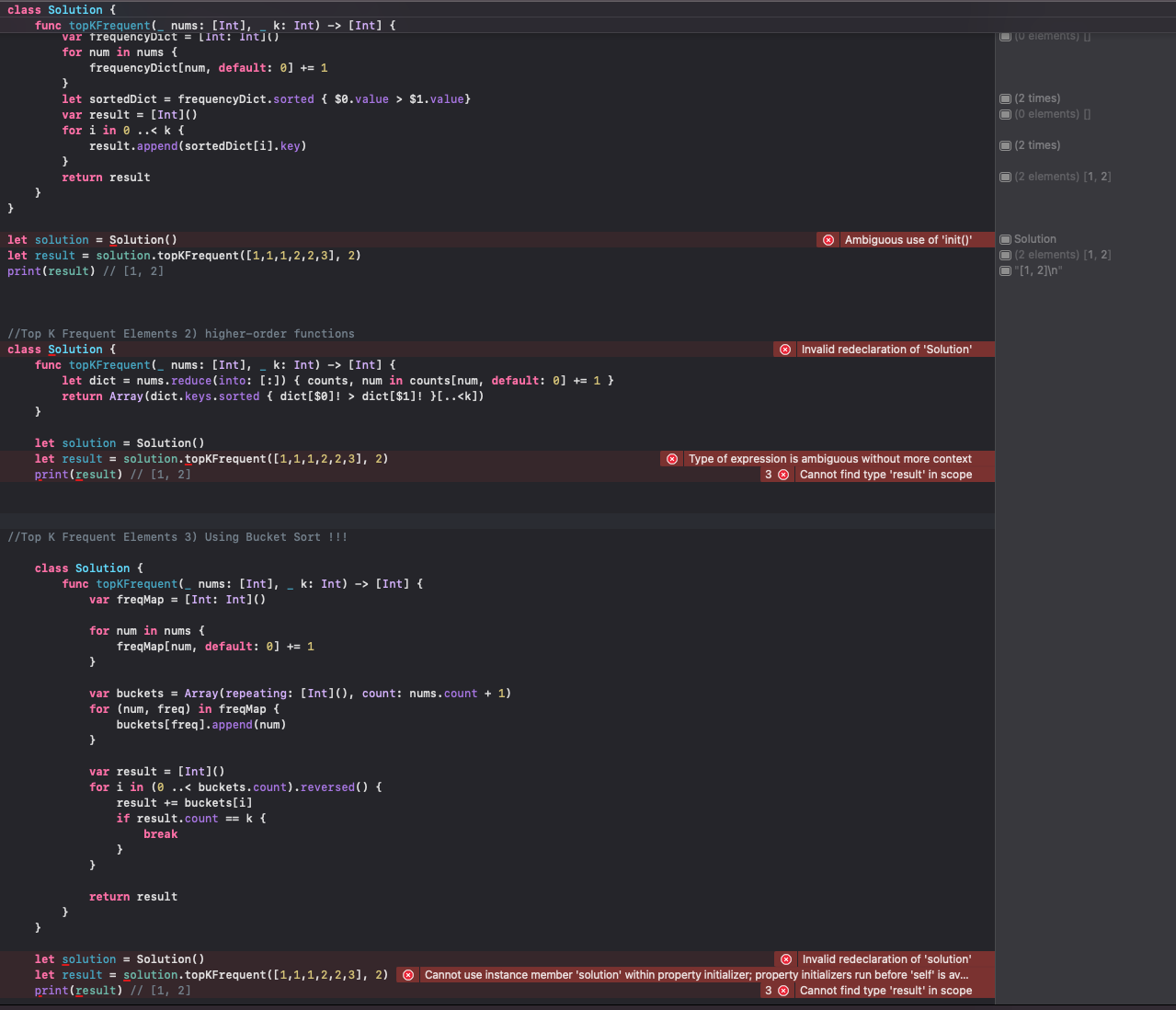
이 코드는 주어진 정수 배열에서 가장 자주 등장하는 숫자들을 뽑아내는 함수를 구현한 것.
class Solution { ... }: Solution이라는 이름의 클래스를 정의하는 부분. 클래스는 객체 지향 프로그래밍에서 사용하는 개념, 관련된 데이터와 함수를 하나로 묶어 관리하는 방법.
func topKFrequent( nums: [Int], k: Int) -> [Int] { ... }: Solution 클래스 내부에 topKFrequent라는 이름의 함수를 정의하고 있음. 이 함수는 두 개의 입력값(nums와 k)을 받음.
nums는 정수 배열이며, k는 정수입니다. _는 파라미터의 이름을 호출 시 생략하게 해줍니다. -> [Int]는 이 함수가 정수 배열을 반환함을 나타냅니다.
var frequencyDict = Int: Int: 빈 딕셔너리를 생성. 이 딕셔너리의 키는 nums 배열의 각 정수이고, 값은 해당 정수가 배열에 등장하는 횟수.
for num in nums { ... }: nums 배열의 모든 요소에 대해 반복하면서, 각 숫자가 등장하는 횟수를 세어 frequencyDict에 저장.
let sortedDict = frequencyDict.sorted { $0.value > $1.value}: frequencyDict의 각 항목을 값의 크기에 따라 내림차순으로 정렬.
var result = Int: 결과를 저장할 빈 배열 result를 생성.
for i in 0 ..< k { ... }: 가장 빈도수가 높은 k개의 숫자를 뽑아내기 위해, k번 반복하면서 sortedDict의 key를 result 배열에 추가.
return result: 가장 자주 등장하는 k개의 숫자가 저장된 result 배열을 반환.
따라서 이 함수는 주어진 배열에서 가장 자주 등장하는 k개의 숫자를 찾아내어 반환하는 역할. 이를 위해 배열의 숫자들의 빈도수를 세고, 빈도수에 따라 숫자들을 정렬하는 과정을 거침.
이를 5살 아이에게 설명을 한다고 가정하고 설명 !!!
"우리가 동물원에 있는 동물들을 생각해봐. 동물들은 각기 다른 종류가 있어. 각각의 동물을 생각하면서, 우리가 가장 많이 본 동물이 무엇인지 찾아보고 싶어. 예를 들어, 사자를 5번, 호랑이를 3번, 펭귄을 7번 본다면, 우리는 펭귄을 가장 많이 봤다고 할 수 있어.
그래서 우리는 frequencyDict라는 동물 이름표를 만들어. 동물을 볼 때마다, 우리는 그 동물 이름표에 동물의 이름과 본 횟수를 적어둬. 예를 들어, 사자를 볼 때마다, 사자 이름표에 본 횟수를 1 증가시켜.
이제 우리는 동물 이름표를 가장 많이 본 동물부터 가장 적게 본 동물 순서로 정렬해. (let sortedDict = frequencyDict.sorted { $0.value > $1.value })
그 다음, 가장 많이 본 동물부터 순서대로 우리가 원하는 개수(k)만큼 동물 리스트(result)에 넣어. 이게 for i in 0 ..< k 부분이야.
마지막으로, 이 동물 리스트를 돌려주면 돼. 이 리스트에는 우리가 가장 많이 본 동물들이 들어 있을거야!"
따라서 이 함수는 주어진 숫자들 중에서 가장 빈번히 등장하는 숫자들을 찾아서 리스트로 반환 !!
6)Product of Array Except Self (자신을 제외한 배열의 곱)

정수 배열 nums가 주어졌을 때, answer 배열을 반환, answer[i]는 nums 배열에서 nums[i]를 제외한 모든 요소의 곱과 같음 !
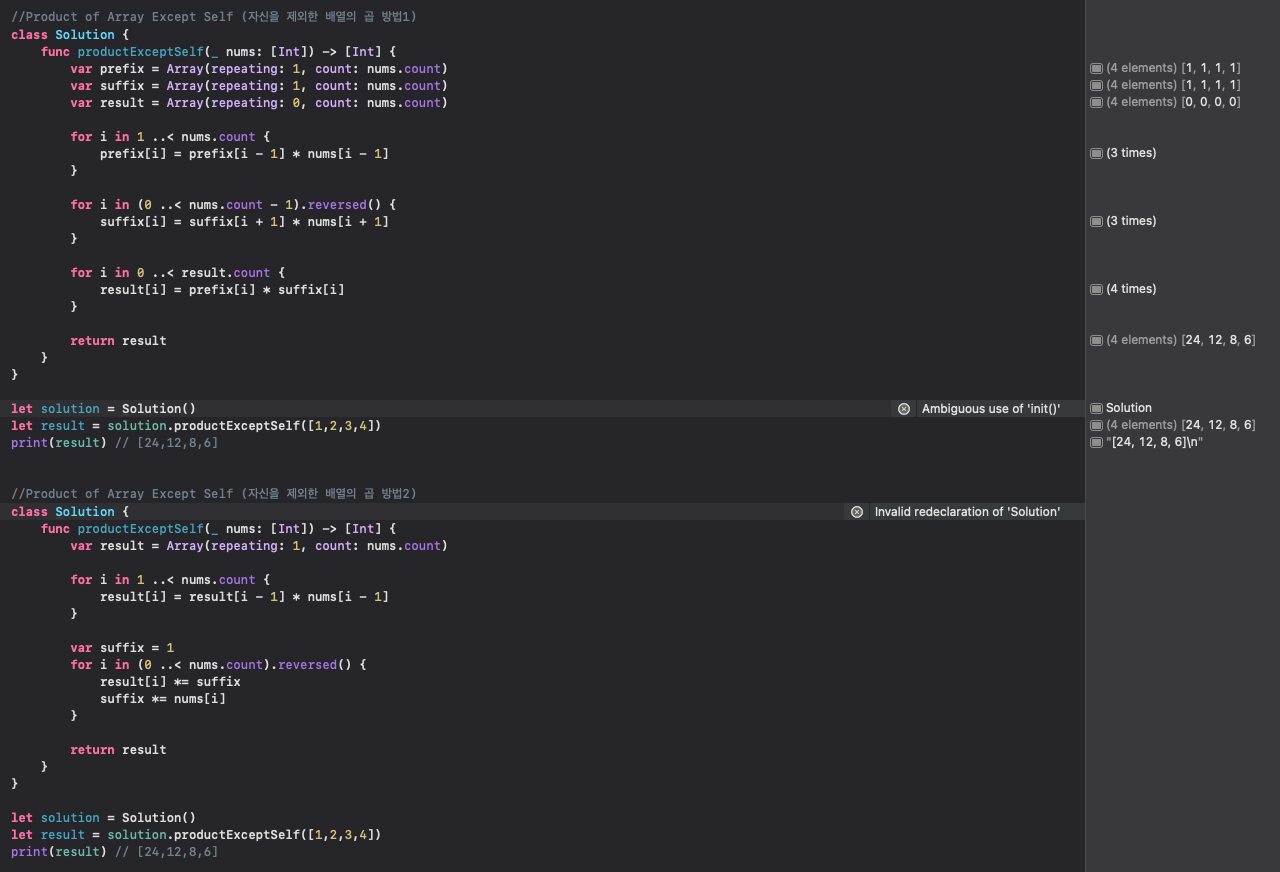
자신을 제외한 배열의 곱 : 이 함수의 목적은 주어진 숫자들의 배열에서, 각 위치의 숫자를 제외한 모든 다른 숫자들의 곱을 계산하는 것. 즉, 각 위치에 대해 그 위치에 있는 숫자를 제외한 모든 다른 숫자들의 곱을 얻는 것이 목표.
먼저 세 개의 배열을 만듭니다: prefix, suffix, result. 이 배열들은 각각, 주어진 위치 이전의 모든 숫자들의 곱, 주어진 위치 이후의 모든 숫자들의 곱, 그리고 최종 결과를 저장할 배열.
첫 번째 for loop에서는 prefix 배열을 채움 ! 각 위치에 대해 그 위치 이전의 모든 숫자들의 곱을 계산해서 저장. 이 때, 곱셈을 빠르게 하기 위해 이전 위치까지의 곱에 현재 위치의 숫자를 곱하는 방식을 사용.
두 번째 for loop에서는 suffix 배열을 채움 ! 이번에는 각 위치에 대해 그 위치 이후의 모든 숫자들의 곱을 계산해서 저장. 이 때도 마찬가지로 이전 위치까지의 곱에 현재 위치의 숫자를 곱하는 방식을 사용하되, 이번에는 배열의 끝에서부터 시작해서 역순으로 진행.
세 번째 for loop에서는 최종 결과를 계산. 각 위치에 대해 prefix와 suffix를 곱해서 result 배열에 저장. 이렇게 하면, 각 위치에 대해 그 위치를 제외한 모든 숫자들의 곱을 계산한 결과를 얻게됨
마지막으로, 계산한 결과인 result 배열을 반환 !
이런 방식을 사용하면, 모든 위치에 대해 나머지 모든 숫자들의 곱을 계산할 때, 각 숫자를 직접 곱하는 것보다 훨씬 빠르게 계산할 수 있음. 이는 prefix와 suffix 배열을 사용해서 이전에 계산한 결과를 재사용하기 때문
++ 조금 더 부연 설명!!!
prefix: prefix[i]는 nums 배열의 첫 번째 요소부터 nums[i]까지의 모든 요소들의 곱을 저장하는 배열.
초기 값 1을 설정하는 이유는 누적 곱을 계산할 때, 처음부터 해당 위치까지의 모든 요소들을 곱하는 것을 시작하는 값으로 사용하기 위해서.. 예를 들어, prefix[3]은 nums[0] nums[1] nums[2] nums[3]과 같이 계산됨.
이때, prefix[3]을 계산하기 위해 초기 값으로 1을 설정하여 prefix[3] = 1 nums[0] nums[1] nums[2] * nums[3]과 같이 계산할 수 있음.
suffix: suffix[i]는 nums 배열의 마지막 요소부터 nums[i]까지의 모든 요소들의 곱을 저장하는 배열.
초기 값 1을 설정하는 이유도 마찬가지로 누적 곱을 계산하기 위해서.
예를 들어, suffix[3]은 nums[3] nums[4] nums[5] nums[6]과 같이 계산됩니다. 이때, suffix[3]을 계산하기 위해 초기 값으로 1을 설정하여 suffix[3] = nums[3] nums[4] nums[5] nums[6] * 1과 같이 계산할 수 있음.
따라서, 누적 곱을 계산하기 위해 prefix와 suffix 배열의 초기 값을 1로 설정. 이러한 초기 값 설정을 통해 누적 곱을 간편하게 계산할 수 있음 !
이를 5살 아이에게 설명을 한다고 가정 하고 설명!!!
먼저, 우리는 3개의 마법의 상자를 가지고 있어. 이 상자들의 이름은 'prefix', 'suffix', 'result'이야. 이들 각각에는 동일한 개수의 작은 상자들이 들어있고, 각각의 작은 상자에는 처음에는 1 ('prefix'와 'suffix') 또는 0 ('result')이 들어있어.
다음, 'prefix' 상자를 채워봐. 이 상자에는 각각의 숫자가 얼마나 중요한지를 알려줄 '마법의 숫자'를 넣을거야. 첫 번째 작은 상자는 그대로 둬. 다음 작은 상자부터 시작해, 각 작은 상자에는 그 앞의 상자의 숫자와 같은 위치에 있는 'nums' 상자의 숫자를 곱한 숫자를 넣어.
이제 'suffix' 상자를 채우는 순서야. 이번에는 마지막 작은 상자부터 시작해, 각 작은 상자에는 그 뒤의 상자의 숫자와 같은 위치에 있는 'nums' 상자의 숫자를 곱한 숫자를 넣어. 여기서는 거꾸로 뒤에서부터 채워나가는 거야.
이제 마지막으로, 'result' 상자를 채울 차례야. 각 작은 상자에는 같은 위치에 있는 'prefix' 상자와 'suffix' 상자의 숫자를 곱한 숫자를 넣어. 이렇게 하면, 각 위치에 대해 그 위치를 제외한 모든 다른 숫자들의 곱을 계산한 결과를 얻게 되는 거야.
마지막으로, 이렇게 채워진 'result' 상자를 가져와. 이게 바로 우리가 원했던 결과야!
그러니까, 이 함수는 각 숫자를 각 숫자가 들어있는 상자를 제외한 모든 다른 상자의 숫자들과 곱한 후, 이를 모두 합한 것을 반환하는 것이죠!
7)Valid Sudoku (유효한 수도쿠)
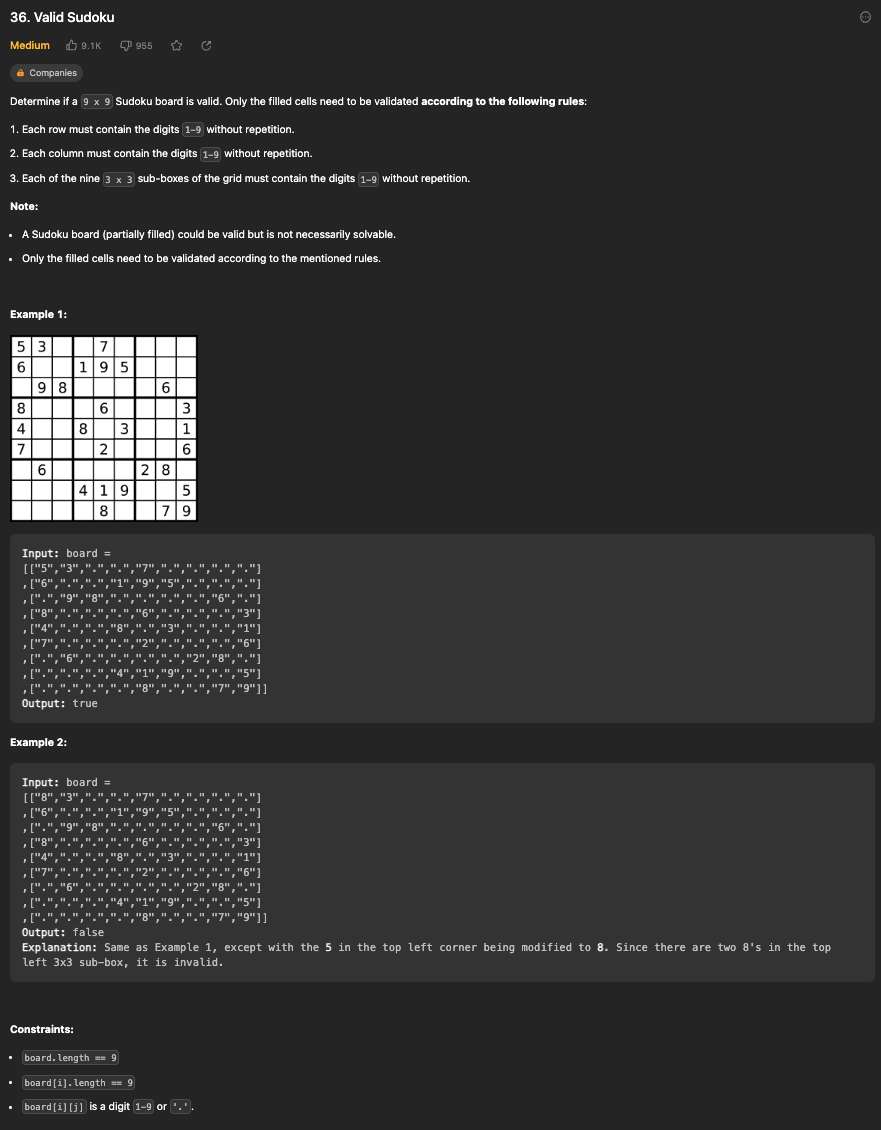
9x9 스도쿠 보드가 유효한지 확인하는 알고리즘. 오직 채워진 셀들만 다음 규칙에 따라 유효성을 검사해야함
1)각 행은 1부터 9까지의 숫자가 중복되지 않고 포함 되어야함.
2)각 열은 1부터 9까지의 숫자가 중복되지 않고 포함 되어야함.
3)그리드의 아홉 개의 3x3 서브 박스는 1부터 9까지의 숫자가 중복되지 않고 포함 되어야함.
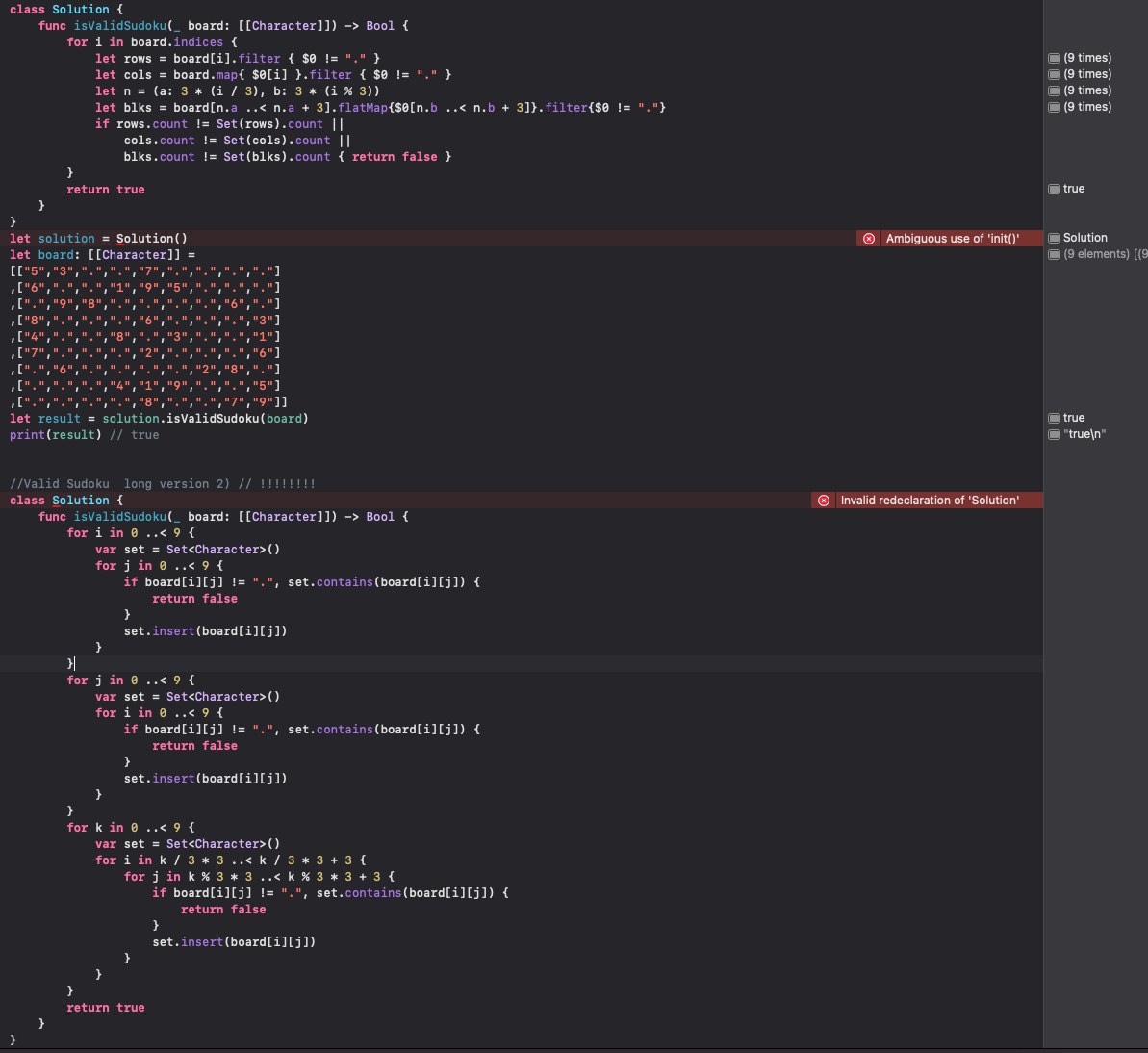
이 코드는 9x9 크기의 스도쿠 보드가 유효한지 검사하는 함수인 isValidSudoku가 구현되어 있음.
isValidSudoku 함수 설명:
입력으로 9x9 크기의 문자열 배열 board를 받음 !
함수는 board가 유효한 스도쿠 보드인지 검사하고, 유효하다면 true를 반환하고, 그렇지 않으면 false를 반환
스도쿠 보드가 유효하다는 것은 다음 세 가지 규칙을 모두 만족하는 경우:
1)각 행에는 숫자 1에서 9까지 중복 없이 등장
2)각 열에는 숫자 1에서 9까지 중복 없이 등장
3) 3x3 크기의 각 서브그리드(작은 3x3 칸)에는 숫자 1에서 9까지 중복 없이 등장합니다.
코드 설명:
for i in 0..<9와 for j in 0..<9를 사용하여 보드의 모든 행과 열을 순회.
var set = Set()는 현재 검사하는 행, 열 또는 서브그리드의 문자들을 담을 Set 자료구조를 생성.
Set은 중복을 허용하지 않는 자료구조로, 각 숫자가 중복되지 않도록 검사하는데 사용.
board[i][j] != "."는 현재 위치의 문자가 점(.)이 아닌 경우를 검사함.
점은 비어있는 칸을 나타내는데, 비어있는 칸은 유효성 검사에서 제외됨 !
set.contains(board[i][j])는 현재 문자가 Set에 이미 존재하는지를 검사. 이미 존재한다면 중복된 숫자가 있음을 의미하므로, 유효성을 만족하지 않음
set.insert(board[i][j])는 현재 문자를 Set에 추가. 이렇게 함으로써 Set에 중복되지 않은 문자들만 포함되도록함
모든 행과 열에 대해서 유효성 검사를 마친 후, 3x3 크기의 서브그리드에 대한 검사를 진행 !
3x3 크기의 서브그리드를 순회하는 부분은 for k in 0..<9로 시작.
이렇게 함으로써 각 서브그리드의 시작 위치를 결정 !
서브그리드 내부를 검사하기 위해 for i in k / 3 3..<k / 3 3 + 3와 for j in k % 3 3..<k % 3 3 + 3를 사용.
이렇게 함으로써 각 서브그리드의 모든 위치를 순회함 ! 나머지 부분은 행과 열의 검사와 동일. 현재 문자가 점이 아니고, Set에 이미 존재한다면 유효성을 만족하지 않으므로 false를 반환.
모든 검사를 마치고 여전히 함수가 실행중이라면,스도쿠 보드는 유효하다는 뜻이므로 true를 반환.
이 코드를 사용하면 주어진 스도쿠 보드가 유효한지를 빠르게 확인할 수 있으며,스도쿠 퍼즐을 푸는데 유용한 함수일 수 있음
8)Encode and Decode Strings (암호화 & 해독 문자열)
참고로, 이건 leetcode에서 유료로 돈주고 구독해야 풀 수 있는 문제인데.. 인터넷 검색하면.. 짝퉁사이트? 나옴..ㅋㅋㅋ 중국에서 만든거 같은데.. 거기서 풀수 있음 !
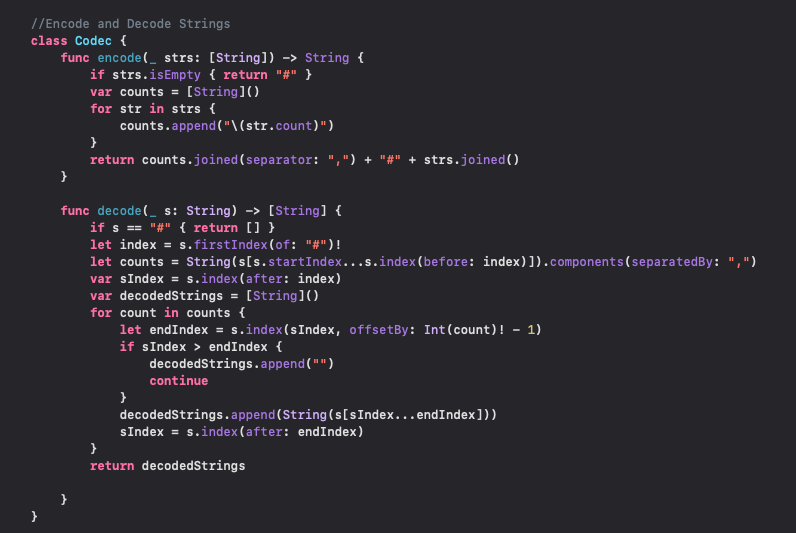
이 코드는 문자열 배열을 인코딩하고 디코딩하는 기능을 제공하는 클래스인 Codec을 정의한 것. 이 클래스는 주어진 문자열 배열을 압축하여 하나의 문자열로 인코딩하고, 다시 원래의 문자열 배열로 디코딩하는 기능을 수행.
encode 함수:
encode 함수는 문자열 배열 strs를 인자로 받아서 인코딩된 문자열을 반환.
먼저, strs가 비어있는지 확인하여 비어있다면 빈 문자열을 나타내는 "#"을 반환함.
counts라는 빈 배열을 만들고, strs에 있는 각 문자열의 길이를 문자열로 변환하여 counts 배열에 추가.
counts 배열의 요소들을 쉼표(,)로 연결하여 하나의 문자열로 만듬
인코딩된 문자열은 counts 문자열 뒤에 "#"를 붙이고, 그 뒤에 strs 배열을 모두 이어붙인 문자열
decode 함수:
decode 함수는 인코딩된 문자열 s를 인자로 받아서 원래의 문자열 배열을 디코딩하여 반환. 먼저, s가 "#"인지 확인하여 빈 배열을 반환함.
s에서 "#"를 기준으로 분리하여 counts 배열에 저장 !
sIndex 변수를 만들어서 디코딩된 문자열의 시작 인덱스로 초기화 !
decodedStrings라는 빈 배열을 만들어서 디코딩된 문자열들을 저장할 준비
counts 배열을 순회하면서 각 문자열의 길이만큼 문자열을 잘라서 decodedStrings 배열에 추가 ! 디코딩이 끝나면 decodedStrings 배열을 반환 !
이렇게 encode 함수는 문자열 배열을 하나의 문자열로 압축하고, decode 함수는 압축된 문자열을 다시 원래의 문자열 배열로 복원. 이러한 기능을 활용하면 문자열 배열을 보다 효율적으로 전송하거나 저장할 수 있음 !
9)Longest Consecutive Sequence (가장 긴 연속된 수열)
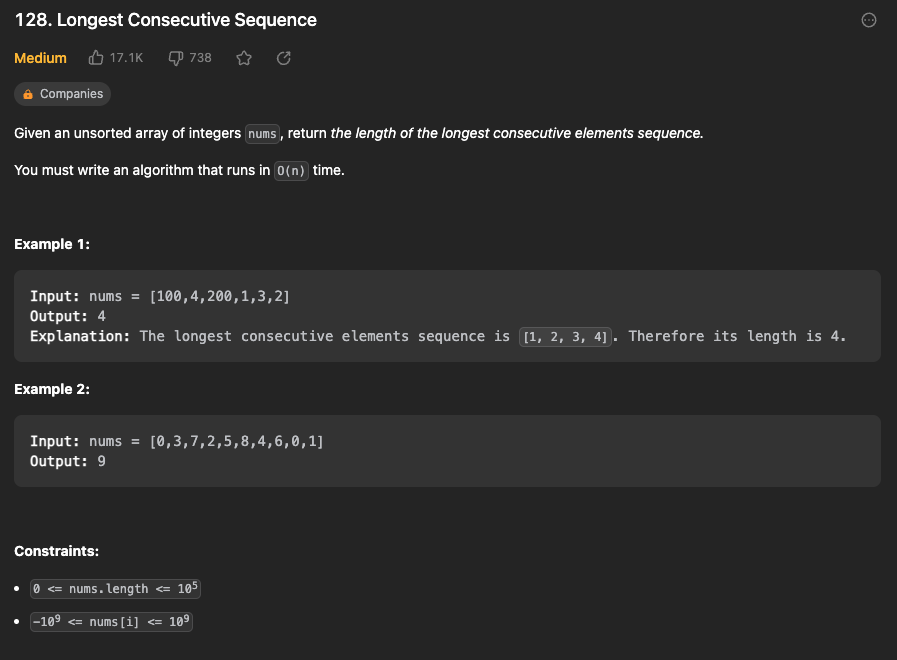
정렬되지 않은 정수 배열 nums가 주어지며, 연속된 요소들의 가장 긴 시퀀스의 길이를 반환.
O(n) 시간 내에 실행되는 알고리즘을 작성해야함 !
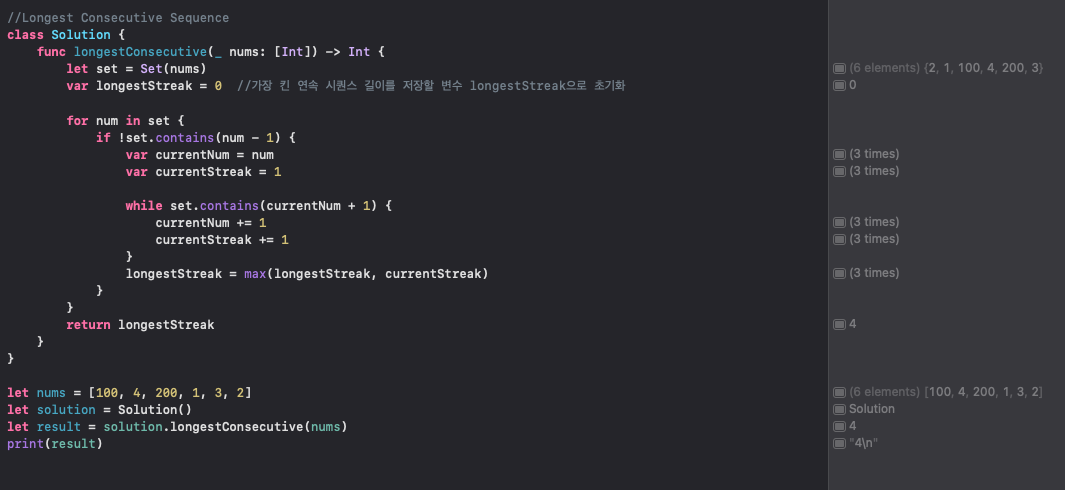
먼저, longestConsecutive 함수는 정수 배열 nums를 입력받고, 배열에서 가장 긴 연속된 숫자들의 길이를 반환하는 함수
먼저 set이라는 변수에 nums 배열을 Set으로 변환하여 저장. Set은 중복된 요소를 허용하지 않으므로, set에는 nums 배열의 중복되지 않은 모든 요소들이 저장.
longestStreak이라는 변수를 0으로 초기화. 이 변수는 현재까지 찾은 가장 긴 연속된 숫자들의 길이를 저장 할 예정
이제 set을 순회하면서 가장 긴 연속된 숫자들을 찾음 !
우선, num이라는 변수에 set의 각 요소를 하나씩 저장.
만약 set에 num보다 1 작은 숫자가 존재하지 않으면(즉, num - 1이 set에 없으면), 이 숫자는 연속된 숫자들의 시작점이 될 수 있음 !
그런 경우, currentNum이라는 변수에 num을 저장하고, currentStreak이라는 변수를 1로 초기화.
여기서 currentStreak은 현재 연속된 숫자들의 길이를 저장할 변수. num이 연속된 숫자들의 시작점이기 때문에, 우선 길이 1로 시작 !
그리고 currentNum + 1이 set에 존재하는 동안, 연속된 숫자들을 계속 탐색.
currentNum을 1씩 증가시키고, currentStreak도 1씩 증가시킴. 이렇게 하면 연속된 숫자들을 차례대로 탐색하면서 currentStreak이 증가.
currentNum + 1이 set에 존재하지 않으면, 연속된 숫자들의 끝점을 찾은 것.
이제 longestStreak과 currentStreak 중에서 더 큰 값을 longestStreak에 저장. 이렇게 하면 현재까지 찾은 가장 긴 연속된 숫자들의 길이가 업데이트됨 !
다음 숫자를 탐색하러 돌아가서, 위의 과정을 반복 !
set의 모든 요소를 순회하면서 가장 긴 연속된 숫자들의 길이를 찾게 되고, 최종적으로 longestStreak의 값을 반환 !
이렇게 하면 함수가 실행될 때, 입력된 nums 배열에서 가장 긴 연속된 숫자들의 길이를 찾아서 반환하게 됨 !
그리고 참고로.. !는 논리부정자, 주어진 조건이 거짓(false)인 경우 참(true) 반환, 반대로 주어진 조건이 참(true)인 경우 거짓(false)로 반환 ! 좀 헷갈릴 수 있음..;;;
