[sk ai] Pandas 자료구조
Series
s = pd.Series([3.0, 5.0, 7.0, 9.0, 11.0], dtype=np.float32)
s[출력 결과]
0 3.0
1 5.0
2 7.0
3 9.0
4 11.0
dtype: float32
==
s = pd.Series(['가', '나', '다','라','마'])
s[출력 결과]
0 가
1 나
2 다
3 라
4 마
dtype: object
인덱싱 (indexing)
s = pd.Series([10,20,30,40,50], index = ['가', '나', '다','라','마'])
s[출력 결과]
가 10
나 20
다 30
라 40
마 50
dtype: int64
s[['나','라']][출력 결과]
나 20
라 40
dtype: int64
==
np.random.seed(20)
sample2 = pd.Series(np.random.randint(100, 200, size=(15,)))
sample2
sample2[sample2<=160][출력 결과]
2 115
4 128
6 109
7 120
9 122
11 134
13 140
dtype: int64
sample2[(sample2>=130) & (sample2<=170)][출력 결과]
11 134
13 140
dtype: int64
속성 (attribute)
s = pd.Series(['apple', np.nan, 'banana','kiwi','gubong'], index = ['가', '나', '다','라','마'])
s[출력 결과]
가 apple
나 NaN
다 banana
라 kiwi
마 gubong
dtype: object
==
sample = pd.Series(['IT서비스', np.nan, '반도체', np.nan, '바이오', '자율주행'])
sample
sample[sample.isna()][출력 결과]
1 NaN
3 NaN
dtype: object
sample[sample.notnull()][출력 결과]
0 IT서비스
2 반도체
4 바이오
5 자율주행
dtype: object
슬라이싱
np.random.seed(0)
sample = pd.Series(np.random.randint(100, 200, size=(10,)))
sample
sample[2:7][출력 결과]
2 164
3 167
4 167
5 109
6 183
dtype: int64
==
np.random.seed(0)
sample2 = pd.Series(np.random.randint(100, 200, size=(10,)), index=list('가나다라마바사아자차'))
sample2
sample2[5:][출력 결과]
바 109
사 183
아 121
자 136
차 187
dtype: int64
sample2[:3][출력 결과]
가 144
나 147
다 164
dtype: int64
sample2[1:6][출력 결과]
나 147
다 164
라 167
마 167
바 109
dtype: int64
DataFrame
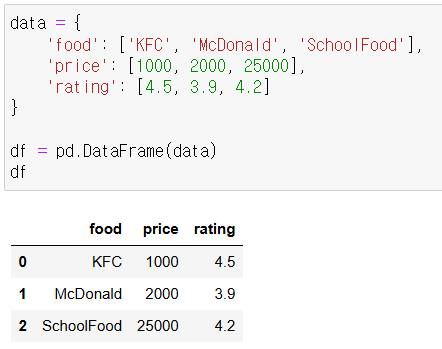
food 컬럼과 rating 컬럼만 선택하여 출력>
df[['food', 'rating']]food 컬럼명을 place로 컬럼명을 변경>
df.rename(columns={'food': 'place'}, inplace=True)
df최종
data = {
'name': ['Kim', 'Lee', 'Park'],
'age': [24,27,34],
'children': [2,1,3]
}
df = pd.DataFrame(data)
result_df = df