1. 데이터과학자가 판다스를 배우는 이유
- 판다스 라이브러리는 데이터를 수집하고 정리하는 데 최적화된 도구임. 오픈소스(open source)라서 무료라는 장점도 있고 파이썬을 기반으로 하기 때문에 컴퓨터과학이나 프로그래밍을 전공하지 않은 사람들도 쉽게 따라가며 배우는 것이 가능함. 판다스를 배우면 데이터과학의 80~90% 업무를 처리할 수 있고, 데이터과학자에게 필요한 기본적이면서도 아주 중요한 도구임.
2. 판다스 자료구조
- (판다스를 사용하는 목적)
다양한 소스(source)로부터 데이터를 수집하다 보면 데이터의 형태나 속성이 매우 다양하는 것을 알 수 있음. 이러한 다양한 다른 형식의 데이터를 컴퓨터가 이해할 수 있도록 동일한 형식을 갖는 구조로 통합할 필요가 있음.
→ 시리즈(Series) - 1차원 배열, 데이터프레임(DataFrame) - 2차원 배열
: 판다스에서 제공하는 구조화된 데이터 형식
/ 데이터를 한곳에 담는 그릇(컨테이너) 역할을 함.
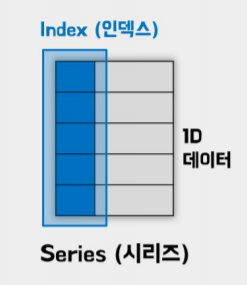
1) 시리즈
- 데이터가 순차적으로 나열된 1차원 배열의 형태를 가짐.
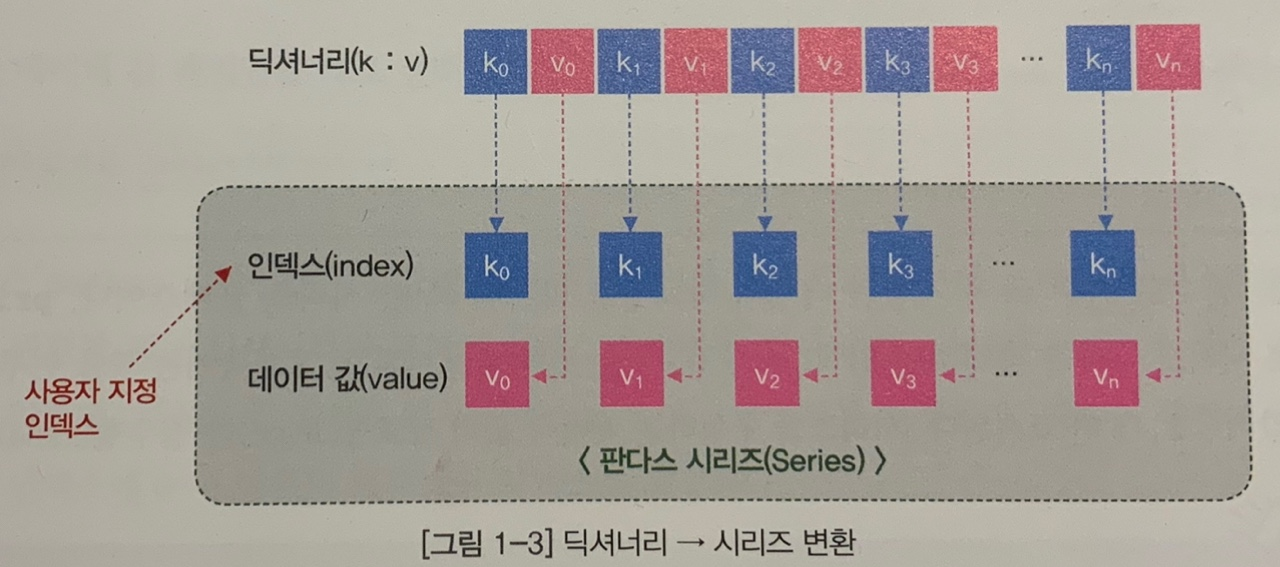
- 인덱스(index)는 데이터 값(value)과 일대일 대응이 된다는 점에서 키(k)와 값(v)이 '{k:v}' 형태로 짝을 이루는 파이썬 딕셔너리(dictionary)와 비슷한 구조를 갖음.
*인덱스 (index) : 데이터 값의 위치를 나타내는 이름표 (데이터 주소) 역할을 함. 자기와 짝을 이루는 데이터 값의 순서와 주소를 저장함. 인덱스를 잘 활용하면 데이터 값의 탐색, 정렬, 선택, 결합 등 데이터 조작을 쉽게 할 수 있음. 정수형 위치 인덱스 (integer position)와 인덱스 이름 (index name) or 인덱스 라벨 (index label) 2 종류가 있음.

- 파이썬 딕셔너리와 시리즈의 구조가 비슷하여 딕셔너리를 시리즈로 변환하는 방법을 많이 사용함.
→ HOW? 판다스 내장 함수인 Series()이용하고, 딕셔너리를 함수 인자로 전달함.
딕셔너리 → 시리즈 : pandas.Series(딕셔너리)
- type() : 변수에 저장된 객체의 자료형을 확인해줌.
→ Ex. 시리즈를 구성하는 데이터 값의 자료형 (dtype)은 정수형(int64)입니다. - print() : 시리즈의 객체 출력
- import pandas as pd : 'pandas' 대신 'pd'라는 약칭으로 부르겠다는 의미. (실용적임)
2) 데이터프레임
- [그림]에서 여러 개의 시리즈들이 한데 모여서 데이터프레임을 이루는 구조가 만들어진 것을 볼 수 있음. (데이터프레임의 열은 각각 시리즈 객체임.) 데이터프레임은 2차원 배열로 시리즈를 열벡터(vector)라고 하면, 데이터프레임은 여러 개의 열벡터들이 같은 행 인덱스를 기준으로 줄지어 결합된 2차원 벡터 또는 행렬(matrix)임.
- 행 인덱스 (row index) = 레코드(record)이자 관측값(observation), 열 이름(column name 또는 column label) = 변수(variable)

- 딕셔너리에서의 리스트가 데이터프레임의 하나의 시리즈가 되고, 딕셔너리에서의 키가 데이터프레임의 열 이름이 됨.
딕셔너리 → 데이터프레임 : pandas.DataFrame(딕셔너리 객체)

- 데이터프레임에서 rename() 메소드를 적용하면 행 인덱스 또는 열 이름의 일부를 선택하여 변경할 수 있는데 원본 객체를 직접 수정하는 것이 아니라 새로운 데이터프레임 객체를 반환하므로 원본 객체를 변경하려면 'inplace=True' 옵션을 사용해야됨.
- 데이터프레임에서 drop() 메소드를 적용하면 행 또는 열을 삭제하는 명령임. 반면, 축 옵션으로 axis=1을 입력하면 열을 삭제함.(행을 삭제랗 때는 축 옵션을 입력하지 않거나 axis=0과 같이 축 옵션을 설정함.) 또, 동시에 여러 개의 행 또는 열을 삭제하려면 리스트 형태로 입력함. rename() 메소드와 마찬가지로 원본 객체를 변경하려면 'inplace=True'옵션을 사용해야되고, 'inplace=False'로 설정하면 새로운 객체가 생성됨.
- 데이터프레임의 행 데이터를 선택하기 위해서 loc과 iloc 인덱서를 사용함.
→ loc : 탐색 대상) 인덱스 이름(index label) / 범위 지정) 기능(범위의 끝 포함) ex)['a':'c'] =>'a','b','c'
→ iloc : 탐색 대상) 정수형 위치 인덱스(integer position) / 범위 지정) 기능(범위의 끝 제외) ex)[3:7] => 3, 4, 5, 6 (*7제외) - 데이터프레임의 열 데이터를 선택하기 위해서
DataFrame 객체["열 이름"] 또는 DataFrame 객체.열 이름
`열 n개 선택(데이터프레임 생성): DataFrame 객체[[열1, 열2, ... , 열n]]
3. 인덱스 활용
4. 산술연산
1) 시리즈 연산
2) 데이터프레임 연산
- 클라우드 컴퓨팅이 무엇인지 정리해놓기
- (여름방학 필수) 알고리즘 공부 및 코테 준비해보기
- (여름방학 필수) 데이터 구조 공부 및 코테 준비해보기
- 파이썬 딕셔너리(dictionary)/리스트/리스트 슬라이싱(slicing)/파이썬 투플(tuple)
- 함수 인자

Majoring in Computer Science