싱글코어만으로 프로그램을 실행시키는 시대는 이제 저물고 있다. 최근에는 AMD, Intel 너나할거 없이 프로세서의 코어를 늘리고 있다. 코어의 클럭을 올리는데 한계에 도달했기 때문이다. 일반적으로 프로그램을 만들면, 프로그램은 싱글스레드로 작동한다. 즉, 프로세서가 수많은 코어를 가지고 있다 하더라도, 단 하나의 코어만 활용해서 동작할 수 있다는 뜻이다. 어떻게 하면 그 수많은 코어를 활용할 수 있을까? 여러 개의 쓰레드나 프로세스(가령 웹 서버라든지)를 사용하는 라이브러리를 통해 활용해볼 수 있다. 하지만 여기서 좀 더 깊이 들어가서, 그러한 라이브러리들은 또 어떻게 돌아가는지, CPU 레벨에서는 어떤 일이 일어나는지 간단히 알아보고자 한다. 또, 실제로 이러한 특성을 활용하여 어떻게 프로그래밍할 수 있는지 lock free 자료구조를 통해 소개할 예정이다.
언어는 Rust를 주로 활용하여 설명할 것이다. Rust를 전혀 모르더라도, 코드 상의 키워드를 보고 유추하거나 pseudo code로 생각하면 어렵지 않을 것이다. 어셈블리 레벨을 보여주려고 할 때에는 Compiler Explorer의 Rust disassembly가 영 좋지 않기 때문에 C++ 코드로 보여줄 것이다. 모든 벤치마크는 Macbook Air (M1, 2020)(ARM64, weak memory model) 또는 Ryzen 5 3600(Ubuntu 20.04, WSL 2 on Windows 10)(AMD64, strong memory model)에서 진행할 것이다. Rust 버전은 1.53.0 (2021-06-17)을 쓰며, 당연히 벤치마크에서는 --release로 컴파일하여 돌릴 것이다. M1 CPU는 빅리틀 구조를 가지기 때문에, 빅코어만 사용하도록 최대 4 쓰레드만 사용하도록 벤치마크를 설계할 것이다.
Concurrency vs Parallelism
멀티코어를 활용하는 프로그래밍을 알아보기 전에 간단하게 용어를 정리하고자 한다. 이러한 프로그래밍을 한다고 하면, concurrency(동시성)이나 parallelism(병렬성)이라는 용어가 자주 등장한다. concurrency는 논리적으로 동시에 실행시키는 것, parallelism은 물리적으로 동시에 실행시킨다고 생각하면 될 것 같다. 즉, 싱글코어 프로세서라 하더라도 concurrency는 가능하며, parallelism은 실제로 멀티코어에서 동작할 때 일어난다고 보면 된다. 프로그래밍을 할 때에는 concurrency하게 짜고 멀티코어에서 프로그램을 돌리면, OS단에서 스케줄러가 각 코어에 프로세스/쓰레드를 잘 할당해서 parallelism을 보여준다고 생각하면 될 거 같다. 따라서 앞으로는 concurrency을 바탕으로 설명하도록 하겠다.
Atomic은 무엇인가?
자, 이제 동시성 프로그래밍을 해보도록 하자. 먼저, 아주 간단한 사례를 살펴보면 좋을 거 같다. 하나의 변수에 두 개의 쓰레드가 1,000번씩 +1해주는 상황을 생각해보자. 코드로 짜보면 아래와 같다.
use std::thread;
struct Counter(*mut i32);
unsafe impl Send for Counter {}
fn main() {
let mut threads = Vec::new();
let mut counter = 0;
for _ in 0..2 {
let counter = Counter(&mut counter as *mut _);
threads.push(thread::spawn(move || {
for _ in 0..1_000 {
unsafe {
*(counter.0) += 1;
}
}
}));
}
for t in threads {
t.join().unwrap();
}
println!("{}", counter);
}일반적으로는 당연히 2000이 나올 것이라 생각하지만, 실제로 여러 번 돌려보면 2000보다 작거나 같은 수가 나온다. AMD/Intel CPU에서는 거의 대부분 2000이 나오고, ARM CPU에서는 꽤 많이 2000보다 작은 수가 나온다. 왜 이런 결과가 나오는 것일까? counter에 +1을 할 때 어떤 일이 일어나는지 자세하게 살펴보도록 하자. 덧셈하여 더하는 과정을 아래와 같이 나열해볼 수 있다.
- counter의 값을 읽어온다.
- 읽어온 counter의 값에 1을 더한다.
- 1을 더한 값을 counter에 저장한다.
단순히 코드 상으로는 1-3의 과정이 한 번에 일어날 것 같지만, 실제로 어셈블리를 까보면 그렇지 않다. 위의 코드에서 덧셈하는 부분(+=)만 C++로 작성해보면 아래와 같다.
int counter = 0;
void add()
{
counter += 1;
}어셈블리로 컴파일하면 아래와 같은 결과가 나온다.
x86-64 clang 12.0.1 -O0
add():
push rbp
mov rbp, rsp
mov eax, dword ptr [counter]
add eax, 1
mov dword ptr [counter], eax
pop rbp
ret위에 나열한 순서처럼 1, 2, 3이 나뉘어져 있음을 알 수 있다.
즉, 다음과 같은 일이 일어날 수 있다.
| Thread A | Thread B |
|---|---|
| 1. counter의 값을 읽어온다. 2. 읽어온 counter의 값에 1을 더한다. 3. 1을 더한 값을 counter에 저장한다. | 1. counter의 값을 읽어온다. 2. 읽어온 counter의 값에 1을 더한다. 3. 1을 더한 값을 counter에 저장한다. |
위의 상황에서 A-1, A-2, B-1, B-2, A-3, B-3의 순서로 실행된다면 A가 더했던 1은 날라가버리는 것이다. 이러한 상황을 막기 위해 atomic이라는 개념이 나온다. 돌턴의 원자설에서 원자는 쪼개질 수 없는 가장 작은 단위인 것처럼, atomic operation은 위의 과정과는 달리 쪼개지지 않는다는 의미이다.
잠시 하나를 짚고 넘어가보도록 하자. 위의 코드를 -O3로 컴파일하면 설명했던 것과는 달리 1개의 명령어로만 이뤄진다. 이때 설령 명령어가 1개일지라도 atomic하지 않기 때문에 결국 위에 설명한 것처럼 문제가 있다.
x86-64 clang 12.0.1 -O3
add():
add dword ptr [rip + counter], 1
ret실제로 add 명령어 문서를 살펴보면 아래와 같이 기술되어 있는 것을 확인할 수 있다.
Description
...
This instruction can be used with a LOCK prefix to allow the instruction to be executed atomically.
다시 Atomic 설명으로 넘어 오도록 하자. Rust에서는 AtomicI32로 i32 타입의 atomic을 사용할 수 있다. 위의 코드를 아래와 같이 고치면 항상 2000이 나오는 것을 확인할 수 있다.
use std::{sync::atomic::{AtomicI32, Ordering}, thread};
struct Counter(*mut AtomicI32);
unsafe impl Send for Counter {}
fn main() {
let mut threads = Vec::new();
let mut counter = AtomicI32::new(0);
for _ in 0..2 {
let counter = Counter(&mut counter as *mut _);
threads.push(thread::spawn(move || {
for _ in 0..1_000 {
unsafe {
(*counter.0).fetch_add(1, Ordering::Relaxed);
}
}
}));
}
for t in threads {
t.join().unwrap();
}
println!("{}", counter.load(Ordering::Relaxed));
}위의 코드에서 fetch_add는 현재 값에 주어진 값을 더하여 저장하는 atomic operation이다. 따라서 이전과는 달리 연산이 쪼개지지 않기 때문에 항상 2000이 나옴을 보장할 수 있다. 실제로 이에 대응되는 C++ 코드를 아래와 같이 작성하여 컴파일한 결과를 살펴보면 다음과 같다.
#include <atomic>
std::atomic_int counter(0);
void add()
{
counter.fetch_add(1, std::memory_order_relaxed);
}x86-64 clang 12.0.1 -O3
add():
lock add dword ptr [rip + counter], 1
ret위의 add 명령어 설명대로 lock(참고: 어셈블리의 lock은 우리가 일반적으로 말하는 lock과는 다른 것이다)이 추가되어 atomic하게 돌아가도록 하는 것을 확인할 수 있다.
이제 atomic을 활용하여 lock을 구현하거나 자료구조를 만들어 동시성 프로그래밍을 쉽게 할 수 있어 보인다. 그렇다면 이제 shared mutable memory에 atomic operation을 적용하면 모든 문제를 해결할 수 있을까? 아쉽게도 여기서 더 풀어가야 할 문제가 있다.
C++11 Memory Model
왜 필요한가?
위의 코드를 잘 살펴보면 Ordering::Relaxed라는 인자를 확인할 수 있다. 이것은 무엇을 의미하는 것일까? 그리고 왜 필요한 것일까? 간단한 예시를 통해 컴파일러와 CPU에서 일어나는 신비한 현상을 관찰해보도록 하자.
가령, 아래와 같이 두 쓰레드가 동시에 동작한다고 하자.
Init: a = 0, b = 0
| Thread A | Thread B |
|---|---|
| a.store(1) b.store(2) | x = b.load() y = a.load() |
이때 (x, y)의 값으로 가능한 경우는 어떤 게 있을까? 단순하게 생각해보면, (0, 0), (2, 1) (0, 1)가 나온다고 떠올릴 수 있다. 그런데 놀랍게도 (2, 0)도 가능하다. 쓰레드 A를 생각해보면 a에 1이 저장되고 나서 b에 2가 저장되기 때문에, 쓰레드 B에서는 이 순서가 보장되어야 한다고 생각할 수 있다. 하지만, 우리의 컴파일러와 CPU는 극단적인 최적화를 마다하지 않기 때문에 이런 일이 발생할 수 있다.
먼저, 컴파일러는 코드가 홀로 동작하는 경우에 있어 semantics을 어기지 않는 한, 꽤 많은 최적화를 할 수 있다. 위의 경우에서는 쓰레드 A의 입장에서는 a, b에 값을 저장하는 명령어의 순서가 바뀐다고 하더라도 semantics을 어기진 않기 때문에 순서를 바꿀 수 있다. 또한, CPU도 dependency를 어기지 않는 한 CPU 내부적으로 명령어들을 순서를 바꿔서 실행할 수 있다. CPU가 superscalar가 되고 out-of-order execution을 채용하기 시작하면서 이러한 최적화를 할 수 있게 된 것이다. 단순히 싱글 쓰레드 프로그램의 경우에서는 성능이 높아지고 semantics을 어기지 않지만, 멀티 쓰레드에서는 이러한 것이 semantics을 어길 수 있기 때문에 문제가 된다.
또한, 컴파일러와 CPU가 reordering을 하지 않는다고 하더라도 역시 문제가 있다. 대표적인 lock인 spinlock을 예시로 들어보자. 아래는 Rust로 간단히 spinlock을 구현한 모습이다.
use std::sync::atomic::{AtomicBool, Ordering};
use std::sync::Arc;
use std::thread;
struct SpinLock {
flag: AtomicBool,
}
impl SpinLock {
fn new() -> Self {
Self { flag: AtomicBool::new(false) }
}
fn lock(&self) {
while self.flag.compare_exchange(false, true, Ordering::Relaxed, Ordering::Relaxed).is_err()
{}
}
fn unlock(&self) {
self.flag.store(false, Ordering::Relaxed);
}
}
struct Counter(*mut i32);
unsafe impl Send for Counter {}
fn main() {
let mut threads = Vec::new();
let lock = Arc::new(SpinLock::new());
let mut counter = 0;
for _ in 0..8 {
let lock = Arc::clone(&lock);
let counter = Counter(&mut counter as *mut _);
threads.push(thread::spawn(move || {
for _ in 0..1_000_000 {
lock.lock();
unsafe {
*(counter.0) += 1;
}
lock.unlock();
}
}));
}
for t in threads {
t.join().unwrap();
}
println!("{}", counter);
}원리는 아주 간단하다. compare_exchange로 false를 true로 바꾸려고 시도하고, 이때 여러 쓰레드가 동시에 시도하면 단 하나의 쓰레드만 성공하여(atomic operation이니까) lock을 얻는다. lock을 가진 동안에는 다른 쓰레드들은 계속 compare_exchange를 시도하고, lock이 풀릴 때까지 실패하면서 while문을 돈다. 이를 spin한다고 하기 때문에 spin lock이다. lock을 가진 동안에는 안전하게 counter의 값을 증가시켜준다. 이전 예시에서는 이 구간이 상호 배제가 되지 않았고, atomic operation이 아니었기 때문에 data race가 발생하여 정상적으로 counter에 값이 저장되지 않았으나, 이번에는 lock을 통해 상호 배제를 구현하였기 때문에 이렇게 non-atomic에 대해서도 잘 작동할 것이다. 실제로 AMD64 아키택쳐의 CPU에서 코드를 돌려보면 결과값으로 8000000이 잘 나온다. '어, 이러면 그냥 단순 atomic으로도 lock을 잘 구현할 수 있는 거 아닌가?'라고 생각할 수도 있다. 하지만 ARM 같은 머신에서 돌려보면 실제로 8000000보다 더 작은 값이 나온다. 이러한 문제가 발생하는 이유는, 실제로 atomic으로 처리한다고 하더라도, atomic 말고 다른 변수(여기서는 counter)가 항상 최신값이 되는 것을 보장하지는 않기 때문이다. 이러한 문제는 CPU를 극단적으로 효율적으로 사용하려고 하기 때문에 발생한다. 이후에 하드웨어 이야기를 하면서 좀 더 다뤄볼 예정이다.
결론적으로 예전에는 이 문제를 해결하려면, 컴파일러가 reordering을 하는 것을 막는 소프트웨어 memory barrier나 CPU가 reordering을 하는 것을 막는 하드웨어 memory barrier을 넣어줘야 했었다. 그리고 spinlock 같은 예시의 문제를 해결하기 위해 동기화에 관한 명령어를 사용해줘야 했었다. 이는 비표준이며 각 컴파일러/아키택쳐에 맞는 특수한 명령어를 때려 박아야 했다. 왜냐하면 그 당시 표준에서 멀티 쓰레딩을 고려하지 않았었기 때문이다.
C++20 Memory Model은 어떻게 동시성을 고려하는가?
멀티쓰레드 사이에서 일어나는 load/store의 순서는 어떻게 정의되는가?
따라서 C/C++11부터 멀티 쓰레드를 고려하는 memory model 개념이 새로 정립됐다. C/C++11 이후로 약간의 수정을 가해졌다는 것 같은데, 여러 버전을 보면 힘만 드니 Rust가 채용했다는 C++20의 memory model만 샅샅이 살펴보도록 하겠다. 먼저, C++20에서는 쓰레드에서 값을 읽는 것을 어떻게 이야기하고 있는지 살펴보도록 하자.
6.9.2.2 Data races
1 The value of an object visible to a thread T at a particular point is the initial value of the object, a value assigned to the object by T, or a value assigned to the object by another thread, according to the rules below.
2 An atomic operation A that performs a release operation on an atomic object M synchronizes with an atomic operation B that performs an acquire operation on M and takes its value from any side effect in the release sequence headed by A.
3 The library defines a number of atomic operations (Clause 31) and operations on mutexes (Clause 32) that are specially identified as synchronization operations. These operations play a special role in making assignments in one thread visible to another. ...
4 All modifications to a particular atomic object M occur in some particular total order, called the modification order of M.
5 A release sequence headed by a release operation A on an atomic object M is a maximal contiguous subsequence of side effects in the modification order of M, where the first operation is A, and every subsequent operation is an atomic read-modify-write operation.
13 A visible side effect A on a scalar object or bit-field M with respect to a value computation B of M satisfies the conditions:
(13.1) — A happens before B and
(13.2) — there is no other side effect X to M such that A happens before X and X happens before B.
The value of a non-atomic scalar object or bit-field M, as determined by evaluation B, shall be the value stored by the visible side effect A.
1번은 너무 당연한 이야기이고, 2, 3번에서는 synchronization operation(동기화 연산)을 통해 다른 쓰레드에 값이 보이도록 한다고 적혀 있다. 핵심은 13번이다. 13번에서는 visible side effect라는 것을 엄밀하게 정의하고 있다. write A와 read B가 있을 때, A가 B에 대해 happens before이고, 그 둘 사이에 어떠한 side effect(write)가 없어야 B는 A의 값을 읽도록 한다고 명시하고 있다. 그렇다면 happens before은 무엇일까? 관련된 모든 용어들을 보면 아래와 같다.
6.9.1 Sequential execution
8 Sequenced before is an asymmetric, transitive, pair-wise relation between evaluations executed by a single thread (6.9.2), which induces a partial order among those evaluations. Given any two evaluations A and B, if A is sequenced before B (or, equivalently, B is sequenced after A), then the execution of A shall precede the execution of B. If A is not sequenced before B and B is not sequenced before A, then A and B are unsequenced.
6.9.2.2 Data races
6 Certain library calls synchronize with other library calls performed by another thread. For example, an atomic store-release synchronizes with a load-acquire that takes its value from the store (31.4).
9 An evaluation A inter-thread happens before an evaluation B if
(9.1) — A synchronizes with B, or
(9.2) — A is dependency-ordered before B, or
(9.3) — for some evaluation X
(9.3.1) — A synchronizes with X and X is sequenced before B, or
(9.3.2) — A is sequenced before X and X inter-thread happens before B, or
(9.3.3) — A inter-thread happens before X and X inter-thread happens before B.
10 An evaluation A happens before an evaluation B (or, equivalently, B happens after A) if:
(10.1) — A is sequenced before B, or
(10.2) — A inter-thread happens before B.
The implementation shall ensure that no program execution demonstrates a cycle in the “happens before” relation.
11 An evaluation A simply happens before an evaluation B if either
(11.1) — A is sequenced before B, or
(11.2) — A synchronizes with B, or
(11.3) — A simply happens before X and X simply happens before B.
[Note 10 : In the absence of consume operations, the happens before and simply happens before relations are identical. — end note]
간략하게 하위 조항들을 가져왔고, consume operation을 고려하지 않을 것이기 때문에 이에 관련된 내용은 빼거나 취소선을 쳤다. 잘 살펴보면 알 수 있겠지만, 이 용어들의 정의에 가장 기본이 되는 요소는 크게 두 가지이다.
- sequenced before: 어떤 두 evaluation이 이루는 쌍에 대해서 서로에 대해 순서를 가진다면, execution(실행)에 있어 누가 먼저 앞선다는 것을 보일 수 있다는 것을 정의한다. 일반적으로 싱글 쓰레드에서 돌아가는 코드들은 이러한 관계를 서로 가진다는 것을 쉽게 알 수 있다.
- synchronizes with: store-release operation은 load-acquire operation과 동기화된다. 즉, 이 둘이 쌍을 이뤄 작동한다는 것이다.
어떤 두 evaluation에 대해서는 쌍으로서 관계를 정의하고 있다. 그렇다면, 여러 evaluation들에 대해서는 어떻게 '순서'를 정해볼 수 있을까? 위의 정의대로 분석을 하면, 단순히 simply happens before을 따라서, 서로 간에 sequenced before 또는 synchronizes with 관계만 가지면 줄줄이 이을 수 있다는 것을 알 수 있다. 앞으로 이러한 관계는 happens before로만 칭하도록 하겠다.
자 이제, 위에서 언급한 reordering이 문제를 일으키는 예시를 다시 보도록 하자.
Init: a = 0, b = 0
| Thread A | Thread B |
|---|---|
| a.store(1) ··· (a) b.store(2) ··· (b) | x = b.load() ··· (c) y = a.load() ··· (d) |
이 예시에서는 (a)와 (b)가 happens before 관계를 가지고, 마찬가지로 (c)와 (d)도 같은 관계를 가짐을 알 수 있다. 그렇다면 실제로 컴파일러가 (a)와 (b)를 reordering하는 것은 semantics을 어기는 게 아니냐(순서가 바뀌면 happens before 관계가 뒤집히기 때문에)라는 의문도 들 수 있다. 하지만, happens before 관계는 정말 이 프로그램이 실제 기계에서 실행될 때 그 순서대로 동작하라는 것을 보장하는 것이 아니라 abstract machine에서 그러한 semantics이 유지된다는 것을 의미하기 때문에, reordering이 가능하다고 약식으로 설명할 수 있을 것 같다. 정반대로, 실제로 순서대로 동작하는 것이 꼭 happens before을 보장하는 것도 아니다. (참고: The Happens-Before Relation)
실제로 일어나는 reordering에 대해서는 이정도로 설명할 수 있을 것 같고, 이제 추상적인 semantics에서도 살펴보도록 하자. 위에서 말한 것처럼, (a)-(b), (c)-(d)에 happens before이 있지만, (a)-(d)나 (b)-(c)에 대해서는 같은 변수를 읽어온다는 것 말고는 어떠한 관계도 없다는 것을 알 수 있다. 따라서, semantics 상으로도 (c), (d)는 6.9.2.2의 1에서 말하고 있는 초기값 또는 저장된 값 중에서 아무거나 읽어와도 문제가 없다.
동기화를 위한 memory order
자 그렇다면, 멀티 쓰레드에서 happens before 관계를 보장하기 위해 남은 방법은 synchronizes with이다. 이는 store-release와 load-acquire operation으로 보장할 수 있으니, 이런 걸 가능하게 하는 atomic operation과 fence의 memory order를 살펴보도록 하자. C++ memory order에는 총 6개가 있으나, 아까 말한 것처럼 consume operation은 고려하지 않을 것이기 때문에 5가지를 살펴 보도록 하자.
memory_order::relaxed
어떠한 동기화도 수행하지 않고, 단순히 atomic하게만 작동한다.memory_order::acquire
load operation에서 acquire operation을 수행한다. 변수와 상관없이 어떤 memory operation이든 이 acquire operation 이전으로 reordering은 불가능하다.memory_order::release
store operation에서 release operation을 수행한다. 변수와 상관없이 어떤 memory operation이든 이 release operation 이후로 reordering은 불가능하다.memory_order::acq_rel
read-modify-write(이하 RMW) operation에서 acquire과 release operation을 동시에 수행한다.memory_order::seq_cst
load operation에서는 acquire을, store operation에서는 release를, RMW operation에서는 acquire과 release operation을 동시에 수행한다. 또한, 모든 쓰레드가 같은 순서로 관찰할 수 있도록 하는 single total order를 만든다.
먼저, acquire과 release를 보면 각각 자신을 기준으로 이전/이후로 명령어의 reordering이 불가능하다고 적어두었다. 왜 그런가를 살펴 보기 위해 atomic synchronization을 통해 non-atomic 변수들을 다루는 예시를 살펴보도록 하자.
Init: a = 0, sync = false
| Thread A | Thread B |
|---|---|
| a = 1 ··· (a) sync.store(true, release) ··· (b) | if (sync.load(acquire)) ··· (c) x = a ··· (d) |
이전의 예시와 마찬가지로, (a)-(b), (c)-(d)는 서로 happens before 관계를 가진다. 이번에는 synchronization operation을 사용했기 때문에, (b)-(c)가 synchronizes with가 된다. 따라서 (c)에서 읽어온 값이 true라면 (d)에서 읽어오는 값은 1임을 보장할 수 있다. 이러한 관계를 가지기 때문에, (a)는 (b)를 넘어서, (d)는 (c)를 넘어서 reordering될 수 없다.
seq_cst에서 밑줄 친 이야기는 아래 표준문서를 통해 알아볼 수 있다.
6.9.2.2 Data races
4 All modifications to a particular atomic object M occur in some particular total order, called the modification order of M.
[Note 3 : There is a separate order for each atomic object. There is no requirement that these can be combined into a single total order for all objects. In general this will be impossible since different threads might observe modifications to different objects in inconsistent orders. — end note]
12 An evaluation A strongly happens before an evaluation D if, either
(12.1) — A is sequenced before D, or
(12.2) — A synchronizes with D, and both A and D are sequentially consistent atomic operations (31.4), or
(12.3) — there are evaluations B and C such that A is sequenced before B, B simply happens before C, and C is sequenced before D, or
(12.4) — there is an evaluation B such that A strongly happens before B, and B strongly happens before D.
[Note 11 : Informally, if A strongly happens before B, then A appears to be evaluated before B in all contexts. Strongly happens before excludes consume operations. — end note]
31.4 Order and consistency
3 An atomic operation A on some atomic object M is coherence-ordered before another atomic operation B on M if
(3.1) — A is a modification, and B reads the value stored by A, or
(3.2) — A precedes B in the modification order of M, or
(3.3) — A and B are not the same atomic read-modify-write operation, and there exists an atomic modification X of M such that A reads the value stored by X and X precedes B in the modification order of M, or
(3.4) — there exists an atomic modification X of M such that A is coherence-ordered before X and X is coherence-ordered before B.
4 There is a single total order S on all memory_order::seq_cst operations, including fences, that satisfies the following constraints. First, if A and B are memory_order::seq_cst operations and A strongly happens before B, then A precedes B in S. Second, for every pair of atomic operations A and B on an object M, where A is coherence-ordered before B, the following four conditions are required to be satisfied by S:
(4.1) — if A and B are both memory_order::seq_cst operations, then A precedes B in S; and
(4.2) — if A is a memory_order::seq_cst operation and B happens before a memory_order::seq_cst fence Y , then A precedes Y in S; and
(4.3) — if a memory_order::seq_cst fence X happens before A and B is a memory_order::seq_cst operation, then X precedes B in S; and
(4.4) — if a memory_order::seq_cst fence X happens before A and B happens before a memory_order::seq_cst fence Y , then X precedes Y in S.
먼저, 6.9.2.2의 4의 Note 3를 보면 모든 객체가 single total order를 이룰 필요는 없다고 말을 한다. 이것이 의미하는 바는 release/acquire을 통해 특정 atomic object에 동기화를 했다 하더라도, 이러한 store/load는 특정 atomic object의 자신만의 시간선에서만 굴러가고 전체적으로 일관된 시간선은 없을 수 있다는 것이다. 시간은 각 쓰레드별로 상대적이다.
따라서 모든 객체를 위한 single total order를 이루기 위한 새로운 제약이 필요하다. 표준문서에서는 coherence-ordered before와 strongly happens before을 통해 제약을 명시하였다. 조항들을 구체적으로 분석해볼 필요는 없을 거 같고, seq_cst를 쓰면 모든 객체들이 single total order를 이룬다고 생각만 하면 충분할 것으로 보인다. 여기서 single total order를 이루는 것이 왜 필요한지, 즉 seq_cst가 왜 필요한지 의문을 가질 수도 있다. seq_cst가 필요한 다음 예제를 보도록 하자.
Init: x = false, y = false, z = 0
| Thread A | Thread B | Thread C | Thread D |
|---|---|---|---|
| x.store(true, seq_cst) | y.store(true, seq_cst) | while (!x.load(seq_cst)); if (y.load(seq_cst)) ++z | while (!y.load(seq_cst)); if (x.load(seq_cst)) ++z |
총 4개의 쓰레드가 있다. 두 개는 각각 x, y에 true를 저장하고 나머지 2개는 각각 x, y가 true가 될 때까지 기다리다가, y, x의 값이 true면 z의 값을 1씩 증가시킨다. 이때 z가 0일 수 있을까? seq_cst일때는 불가능하다. single total order를 가지기 때문에 아래와 같이 시간선을 그려볼 수 있다.

일반성을 잃지 않고 생각하면, x-y 순서로 true가 저장되면 쓰레드 D에서는 무조건 z의 값이 증가할 수밖에 없다. 하지만 아래와 같이, release/acquire synchronization을 하면 어떻게 될까?
Init: x = false, y = false, z = 0
| Thread A | Thread B | Thread C | Thread D |
|---|---|---|---|
| x.store(true, release) | y.store(true, release) | while (!x.load(acquire)); if (y.load(acquire)) ++z | while (!y.load(acquire)); if (x.load(acquire)) ++z |
일단, semantics을 살펴보면 쓰레드 A, B의 release operation이 C, D의 acquire operation과 동기화되는 것과 C와 D 내부에서 happens before 관계를 가지는 것 말고는 딱히 다른 순서 관계는 없다. release/acquire의 경우에는 모든 객체가 동일한 single total order을 가지는 것이 아니기 때문에, 놀랍게도 아래와 같이 각 쓰레드 별로 관찰하는 순서가 달라질 수 있다.
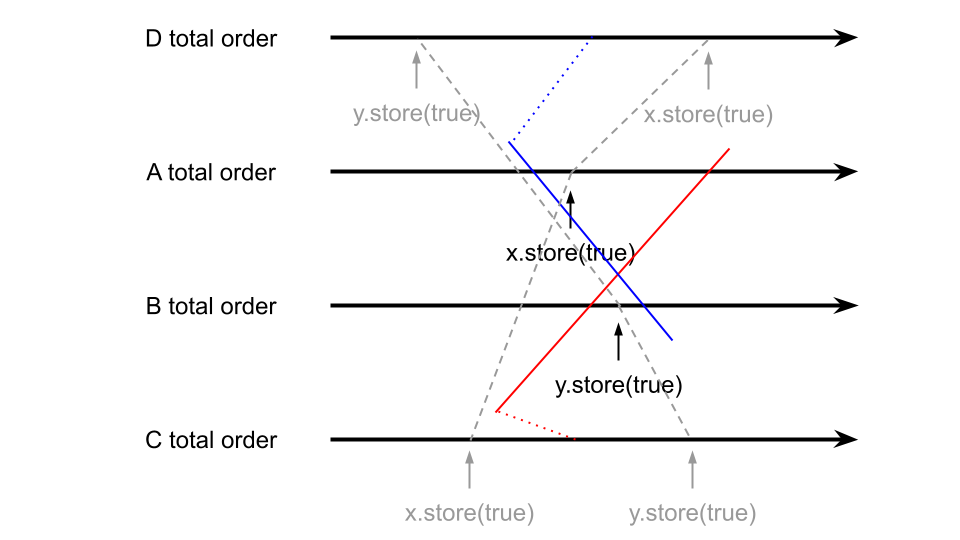
즉, C에서는 x, y 순서로 store가 일어나고, D에서는 y, x 순서로 store가 일어났다고 관찰할 수 있다는 것이다. 이러면, 두 store의 사이에 쓰레드 C와 D의 코드가 실행된다면 z는 0이 될 수 있다. 헷갈린다면 이것만 알고 있으면 된다. seq_cst를 쓰지 않는 이상 절대시간선이란 존재하지 않는다.
fence로 넘어가서 설명하기 전에 잠깐 두 가지를 보도록 하자. 위에서 설명했던 것처럼 relaxed operation이라면 어떠한 동기화도 일어나지 않기 때문에, 과거의 값을 읽어올 수 있다고 하였다. 그렇다면, RMW operation에 문제가 생기지 않을까? 가령, counter 예시에서 보여줬던 것처럼 fetch_add에서 memory order로 relaxed를 줘버리면 과거의 값을 통해 변수를 이상하게 업데이트할 수 있다는 의심을 할 수 있다. 이를 막기 위해서인지 표준문서에는 아래와 같이 기술되어 있다.
31.4 Order and consistency
10 Atomic read-modify-write operations shall always read the last value (in the modification order) written before the write associated with the read-modify-write operation.
RMW operation은 항상 최신값을 읽어서 write하도록 보장하고 있다.
또, C++11에서 여러 사소한 문제가 있어서 일부 수정이 있었다고 한다. 그 중에서 재미있는 거 하나가 보여서 이걸 소개해보려고 한다. C++11에는 없고, C++14에 추가된 조항이 아래의 것이다.
31.4 Order and consistency
8 Implementations should ensure that no “out-of-thin-air” values are computed that circularly depend on their own computation.
[Note 6 : For example, with x and y initially zero,
// Thread 1:
r1 = y.load(memory_order::relaxed);
x.store(r1, memory_order::relaxed);
// Thread 2:
r2 = x.load(memory_order::relaxed);
y.store(r2, memory_order::relaxed);
this recommendation discourages producing r1 == r2 == 42, since the store of 42 to y is only possible if the store to x stores 42, which circularly depends on the store to y storing 42. Note that without this restriction, such an execution is possible. — end note]
9 [Note 7 : The recommendation similarly disallows r1 == r2 == 42 in the following example, with x and y again
initially zero:
// Thread 1:
r1 = x.load(memory_order::relaxed);
if (r1 == 42) y.store(42, memory_order::relaxed);
// Thread 2:
r2 = y.load(memory_order::relaxed);
if (r2 == 42) x.store(42, memory_order::relaxed);
— end note]
코드를 보면 되게 웃기다. 두 예제는 의존성의 사이클을 이룬 load/store 코드를 보이고 있다. 놀랍게도, 저렇게 적어두지 않으면 실제로 가능한 작동이었다고 한다. 이쪽 문제에 관심이 있다면 이 논문을 읽어보면 좋을 거 같다.
fence는 무엇인가?
이제까지 atomic object의 load/store와 RMW operation에 대해 자세하게 설명하였다. 그 중에서 acquire/release operation을 통해 동기화를 구현할 수 있었다. 그런데, 동기화는 단순히 load/store할 때 memory order를 넣어주는 것 말고도 다른 방법으로도 구현할 수 있다. fence가 바로 그것이다. 이름에서 알 수 있다시피, 울타리를 쳐주는 역할을 할 수 있다. fence는 아래와 같이 단순히 memory order만 넣어서 작성할 수 있다. 당연하겠지만, 이는 동기화를 위한 것이기 때문에 relaxed는 넣을 수 없다.
use std::sync::atomic::fence;
fence(Ordering::Acquire);fence는 어떻게 작동하도록 되어 있을까? 표준문서의 명세를 살펴보도록 하자. 조항이 한 문장으로 서술되어 있어서, 약간 나눠두었다.
31.11 Fences
1 This subclause introduces synchronization primitives called fences. Fences can have acquire semantics, release semantics, or both. A fence with acquire semantics is called an acquire fence. A fence with release semantics is called a release fence.
2 A release fence A synchronizes with an acquire fence B if:
- there exist atomic operations X and Y, both operating on some atomic object M
- such that A is sequenced before X,
- X modifies M,
- Y is sequenced before B, and
- Y reads the value written by X or
- a value written by any side effect in the hypothetical release sequence X would head if it were a release operation.
3 A release fence A synchronizes with an atomic operation B that performs an acquire operation on an atomic object M if:- there exists an atomic operation X
- such that A is sequenced before X,
- X modifies M, and
- B reads the value written by X or
- a value written by any side effect in the hypothetical release sequence X would head if it were a release operation.
4 An atomic operation A that is a release operation on an atomic object M synchronizes with an acquire fence B if:- there exists some atomic operation X on M
- such that X is sequenced before B and
- reads the value written by A or
- a value written by any side effect in the release sequence headed by A.
예시를 통해 atomic operation와 fence의 동기화를 쉽게 비교해볼 수 있다. 이전의 예시에서 load/store의 acquire/release는 아래와 같이 보였었다.
Init: a = 0, sync = false
| Thread A | Thread B |
|---|---|
| a = 1 sync.store(true, release) | if (sync.load(acquire)) x = a |
여기서 fence를 쓴다고 하면 아래와 같이 작성할 수 있다.
Init: a = 0, sync = false
| Thread A | Thread B |
|---|---|
| a = 1 fence(release) sync.store(true, relaxed) | if (sync.load(acquire)) fence(acquire) x = a |
사실 둘의 차이는 아주 미묘하다. 먼저, 아까 봤던 표준문서 상의 release/acquire synchronization을 다시 보도록 하자.
6.9.2.2 Data races
2 An atomic operation A that performs a release operation on an atomic object M synchronizes with an atomic operation B that performs an acquire operation on M and takes its value from any side effect in the release sequence headed by A.
fence와는 달리, 그저 release/acquire이 서로 동기화된다는 것만 명시해두었다. 하지만 위의 fence쪽을 보면 조건이 많이 붙어있다. fence-fence 동기화를 살펴보면, 아예 특정 atomic operation을 바탕으로 동기화가 일어남을 명시하고 있다. 이런 이유는 fence는 load/store 같은 operation이 아니라, memory barrier 명령어이기 때문이다. 실제로 fence가 어떻게 해석되어 구현되는지 살펴보면서 이해를 해보도록 하자.
먼저, memory barrier의 종류에 대해 알아보도록 하자. memory barrier는 memory operation의 reordering을 막기 위한 것이기 때문에 load, store의 reordering 종류에 따라 나눠볼 수 있다. 따라서 아래와 같이 네 가지가 있다.
-
#LoadLoad
Load와 Load 사이의 reordering을 막는다. 위의 fence의 예시를 살펴보도록 하자.Init: a = 0, sync = false
Thread A Theread B a = 1
sync.store(true)if (sync.load())
x = aThread B에서는 sync의 load와 a의 read가 reordering되지 않도록 해야 한다. 따라서 아래와 같이 loadload fence(#LoadLoad)를 둔다면 문제를 해결할 수 있다.
Thread B if (sync.load())
#LoadLoad
x = a -
#LoadStore
Load와 Store 사이의 reordering을 막는다. 이 fence가 필요한 이유는 아래와 같은 코드로서 보일 수 있을 거 같다.Thread A if (a)
b = 666이 코드에서 a 또는 b 둘 중에 하나만 atomic이라 보면, 그 atomic이 동기화되기 위해 reordering이 되지 않으려면 loadstore fence(#LoadStore)가 필요함을 알 수 있다.
-
#StoreLoad
Store와 Load 사이의 reordering을 막는다. fence 이전의 모든 store 명령어들은 이후의 load보다 무조건 먼저 일어나도록 하기 때문에, #StoreLoad를 통해 sequential consistent를 보장할 수 있다.
-
#StoreStore
Store와 Store 사이의 reordering을 막는다. #LoadLoad 예시를 보면, Thread A에서 a의 write와 sync의 store는 reordering 되어서는 안 된다. 따라서 아래와 같이 storestore fence(#StoreStore)를 두면 예방할 수 있다.Thread A a = 1
#StoreStore
sync.store(true)
잘 살펴보면, 위의 네 가지 속성 중에 acquire fence는 #LoadLoad + #LoadStore, release fence는 #StoreStore + #LoadStore 속성을 가짐을 알 수 있다. 그리고 seqcst fence는 위의 네 가지 속성을 다 가진다고 볼 수 있다.
그렇다면 fence와 memory ordering이 동반된 atomic operation은 얼마나 다른 것일까? 어셈블리로서도 다르긴 하지만, 가장 큰 차이점은 아래의 예시를 통해 설명할 수 있다.
| fence(Release) | atomic operation(Release) |
|---|---|
| a = 1 fence(release) sync.store(true, relaxed) b = 2 | a = 1 sync.store(true, release) b = 2 |
fence에서는 b = 2가 fence를 넘어 reordering되지 않지만(#StoreStore barrier), atomic operation에서는 b = 2가 store을 넘어서 reordering되더라도 전혀 문제가 되지 않는다. 즉, fence와 atomic operation은 서로 비슷하면서도 fence가 좀 더 강력하다. 이 링크를 읽어보면 도움이 될 거 같다. 참고로 atomic operation 없이 fence 혼자만으로는 동기화할 수 없다. 아마도 memory barrier 역할 정도로밖에 못 쓰지 않을까 싶다.
컴파일러와 CPU에서는 어떻게 처리하는가?
이제까지 추상적인 코드 레벨에서 설명을 하였다. 그렇다면, 이 코드를 컴파일하는 컴파일러에서는 어떻게 처리되는지, 이 코드를 실행하는 CPU에서는 어떤 일이 일어나는지 알아보도록 하자. LLVM(Rust의 backend이기도 하다) 컴파일러와 AMD64, ARM, Power 등의 CPU 아키택쳐를 살펴보도록 하겠다.
컴파일러 자체에서는 크게 살펴볼 것은 없다. C++에서 한 가지 알아두면 좋은 점은 이것이다.
Acquire
Relevant standard
This corresponds to the C++11/C11memory_order_acquire. It should also be used for C++11/C11memory_order_consume.
LLVM에서도 consume operation은 그거보다 강력한 acquire로 처리하고 있음을 확인할 수 있다. consume은 너무 복잡하기 때문에 컴파일러 측면에서 이러한 편의성을 가지고 있는 듯하다.
LLVM에서 atomic을 어떻게 다루는지도 간단히 짚고 넘어가도록 하자. LLVM에서는 일곱 가지(non-atomic 포함)로 atomic level을 구분하고 있다. acquire과 release를 제외하고, 아래로 내려갈수록 더 강력한 ordering이다.
- NotAtomic: C++에서 shared variable로 쓰이는 일반적인 non-atomic이다.
- Unordered: Java의 shared variable에 쓰인다. 이 level의 핵심은 한 명령어를 여러 개로 쪼개지 않는다는 것이다. 예를 들어, 8byte store 명령어를 두 개의 4byte store 명령어로 쪼개는 것을 방지한다. 사실상 atomic이라기 보단, partial-atomic 정도로 생각하면 좋을 거 같다.
Atomic Memory Ordering Constraints
unordered
The set of values that can be read is governed by the happens-before partial order. A value cannot be read unless some operation wrote it. This is intended to provide a guarantee strong enough to model Java’s non-volatile shared variables. This ordering cannot be specified for read-modify-write operations; it is not strong enough to make them atomic in any interesting way. - Monotonic: C++에서 relaxed로 다루는 것과 같다.
- Acquire: C++에서 acquire로 다루는 것과 같다.
- Release: C++에서 release로 다루는 것과 같다.
- AcquireRelease: C++에서 acq_rel로 다루는 것과 같다.
- SequentiallyConsistent: C++에서 seq_cst로 다루는 것과 같다. Java의 volatile variable가 이 속성을 가진다.
이외로, x86/AMD64에서 제공하는 CAS(compare-and-swap)이 없는 CPU(ARM 등)에서는 CAS 함수가 native로 존재하지는 않기 때문에 loop 형식으로 ll(load-linked), sc(store-conditional)를 활용하도록 codegen을 한다고 한다. 아래의 인용문을 훑어보면 어떻게 LLVM이 코드를 어셈블리로 codegen하는지 살펴볼 수 있을 것이다.
On x86, all atomic loads generate a
MOV. SequentiallyConsistent stores generate anXCHG, other stores generate aMOV. SequentiallyConsistent fences generate anMFENCE, other fences do not cause any code to be generated.cmpxchguses theLOCK CMPXCHGinstruction.atomicrmw xchgusesXCHG,atomicrmw addandatomicrmw subuseXADD, and all otheratomicrmwoperations generate a loop withLOCK CMPXCHG. Depending on the users of the result, someatomicrmwoperations can be translated into operations likeLOCK AND, but that does not work in general.
On ARM (before v8), MIPS, and many other RISC architectures, Acquire, Release, and SequentiallyConsistent semantics require barrier instructions for every such operation. Loads and stores generate normal instructions.cmpxchgandatomicrmwcan be represented using a loop with LL/SC-style instructions which take some sort of exclusive lock on a cache line (LDREXandSTREXon ARM, etc.).
It is often easiest for backends to use AtomicExpandPass to lower some of the atomic constructs. Here are some lowerings it can do:
- cmpxchg -> loop with load-linked/store-conditional by overriding
shouldExpandAtomicCmpXchgInIR(),emitLoadLinked(),emitStoreConditional()- large loads/stores -> ll-sc/cmpxchg by overriding
shouldExpandAtomicStoreInIR()/shouldExpandAtomicLoadInIR()- strong atomic accesses -> monotonic accesses + fences by overriding
shouldInsertFencesForAtomic(),emitLeadingFence(), andemitTrailingFence()- atomic rmw -> loop with cmpxchg or load-linked/store-conditional by overriding
expandAtomicRMWInIR()- expansion to _atomic* libcalls for unsupported sizes.
- part-word atomicrmw/cmpxchg -> target-specific intrinsic by overriding
shouldExpandAtomicRMWInIR,emitMaskedAtomicRMWIntrinsic,shouldExpandAtomicCmpXchgInIR, andemitMaskedAtomicCmpXchgIntrinsic.
이제 CPU를 살펴보도록 하자. CPU는 memory model에 있어, 크게 두 종류로 분류할 수 있다. reordering을 거의 하지 않는 strong memory model과 아주 많이 하는 weak memory model이 있다. strong memory model에 속하는 CPU 아키택쳐로는 x86, AMD64 등이 있고, weak에는 ARM, Power 등이 있다. 각 아키택쳐에서 어떤 reordering을 허용하고 안 하는지 살펴보면 아래와 같다. 출처
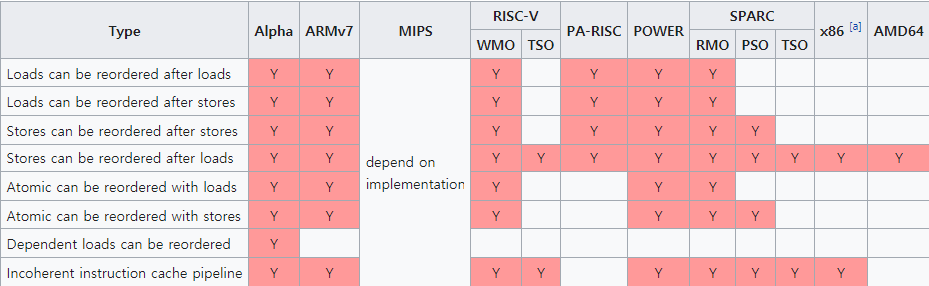
대표적으로 우리가 가장 접하기 쉬운 AMD64와 ARM을 비교해보도록 하자. ARM은 LoadLoad, LoadStore, StoreStore, StoreLoad 모두 reordering 가능하다고 나타나있다. 그러나 AMD64는 StoreLoad만 reordering한다고 적혀 있다. 이전에 SpinLock 예시를 들어 설명할 때 AMD64에서는 잘 되지만, ARM에서는 잘 안 된다는 것을 보여준 적이 있었다. 그 이유가, AMD64에서는 원래부터 LoadLoad, StoreStore, LoadStore reordering을 막고 있기 때문에, atomic operation을 relaxed로 둔다 하더라도 항상 acquire 또는 release로 작동하기 때문이다.
그렇다면 "strong과 weak 중에 어떤 것이 더 성능이 좋을까?"라는 질문을 던져볼 수 있을 것이다. 단순한 추정으로는 weak가 더 최적화할 요소가 많아서 정말 같은 CPU에 대해서는 더 좋을 수 있겠으나, 현실적으로 같은 CPU인데 weak, strong이 따로 있는 모델은 아마 없는 듯하다. 따라서 이 질문을 변형하여, "ordering에 따른 성능 변화폭은 weak와 strong에서 어떻게 나타날까?"로 비슷하게 던져볼 수 있을 것이다. 성능폭이 잘 드러나는 여러 예시를 찾다가, 생각보다 위의 counter가 꽤 잘 나와서 counter의 fetch_add의 memory ordering을 바꿔가면서 테스트를 해보았다. memory_ordering_counter.rs
| ordering | AMD64 | ARM64 |
|---|---|---|
| Relaxed | 52 ms | 65 ms |
| AcqRel | 52 ms | 170 ms |
| SeqCst | 52 ms | 170 ms |
counter는 그냥 1씩 더하기만 하는 것이라 그런지, AcqRel과 SeqCst는 큰 차이가 드러나지 않은 거 같다. 반면에 Relaxed가 AcqRel보다 weak한 ARM64에서는 Relaxed로 하였을 때 2배 이상 빠른 것을 확인할 수 있었다. 이외에 자료구조에서의 memory ordering의 차이를 보여주려고 하였으나, 자료구조 그 자체의 알고리즘에 비해 memory ordering이 영향을 크게 주지 못하는지 오히려 SeqCst가 살짝 빠르거나 그러한 경향을 보이기도 하여, 가져오진 않았다.
Rust의 동시성
이제까지 C++20 memory model의 명세와 세부적인 하드웨어 특성까지 살펴보았다. 이 글은 Rust를 바탕으로 설명할 것이기 때문에, Rust에서 어떻게 동시성을 다룰 수 있는 지를 이야기해보고자 한다.
Rust에는 crossbeam이라는 concurrency library가 있다. 여러 가지 도구를 제공하는데, 여기서 EBR(Epoch-Based Reclaimation)을 구현해둔 crossbeam-epoch를 간단하게 살펴보도록 하자. crossbeam-epoch는 크게 Atomic과 Shared을 제공한다. Atomic은 heap-allocated object에 대한 shared atomic pointer이다. 이전까지는 간단히 primitive한 int(i32) 따위를 다뤘지만, 실제 lock-free 자료구조를 만든다고 하면 여러 복잡한 객체도 다룰 수 있어야 하기 때문에 pointer가 있다. atomic은 계속 살펴 본 것과 같으니 익숙할 것이고, 그렇다면 Shared는 뭘까?
Shared는 EBR이라는 GC(Garbage Collector)가 관리하는 pointer이다. 동시성을 다루는데 왜 생뚱 맞게 GC가 나오느냐 싶을 수 있겠지만, 당장은 ABA 문제라는 것을 해결하기 위해 있다라고 생각해주면 편할 거 같다. 아무튼 이 Shared는 thread 간에 shared된 pointer로서 Rust에서 안전하게 객체를 다루도록 도와준다. 즉, atomic shared pointer인 Atomic을 통해 직접 접근하는 것이 아니라, Shared를 통해 접근할 수 있도록 한다는 것이다. 간단하게 Atomic과 Shared를 사용하는 아래의 예시를 살펴보고 넘어가도록 하자.
use std::sync::atomic::Ordering;
use crossbeam::epoch::{pin, Atomic, Guard, Shared};
struct Point {
x: i32,
y: i32,
}
fn main() {
let pin: Guard = pin();
let p: Atomic<Point> = Atomic::new(Point { x: 0, y: 0 });
let shared_p: Shared<Point> = p.load(Ordering::Relaxed, &pin);
let ref_p: &Point = unsafe { shared_p.as_ref().unwrap() };
println!("({}, {})", ref_p.x, ref_p.y);
}pin()은 shared pointer가 thread에서 사용 중일 때(pinned) free되지 않도록 해주는 장치이다. Atomic pointer를 통해 heap-allocated object를 다루고, pointer를 load(이전의 load와 같은 것이다)해서, 안전한 shared pointer로 만들고, 그것을 reference로 바꾸는 콜을 통해 Point의 reference 타입(&Point)로 불러오는 과정을 살펴볼 수 있다. 구체적인 활용 방안은 아래에서 좀 더 심도있게 다뤄볼 예정이다.
실제로 만들어보는 Lock과 Lock-Free 자료구조
심도있게 C++ memory model을 살펴봤다. 이제 이를 바탕으로 Lock을 만들어 보고, Lock이 필요없는 Lock-Free 자료구조를 만들어 보도록 하자.
Lock
SpinLock
먼저, 가장 간단한 SpinLock이다. 위에서 살펴본 것과 거의 같은데, 이전에 지적했던 것처럼 동기화를 도입하여 수정한 버전이다.
use std::sync::atomic::{AtomicBool, Ordering};
use std::sync::Arc;
use std::thread;
struct SpinLock {
flag: AtomicBool,
}
impl SpinLock {
fn new() -> Self {
Self { flag: AtomicBool::new(false) }
}
fn lock(&self) {
while self.flag.compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed).is_err()
{}
}
fn unlock(&self) {
self.flag.store(false, Ordering::Release);
}
}
unsafe impl Send for SpinLock {}
unsafe impl Sync for SpinLock {}Rust의 compare_exchange의 인자는 (이전값, 새로운 값, 성공했을 때의 ordering, 실패했을 때의 ordering)이다. 즉, 성공했을 때만 acquire로 unlock했을 때의 release와 동기화하는 것이다.
SeqLock
이번에는, fence를 사용하는 seqlock(sequence lock)이다. 이게 무엇인지 설명하려면, 먼저 readers-writer lock에 대해 알면 좋을 듯하다. readers-writer lock은 read-read끼리는 서로 방해하지 않는다는 특성을 이용해, read-write, write-write, write-read일 때만 lock을 걸고, read-read일 때는 lock을 풀어둠으로써 write 대비 read 작업이 많은 경우에 효율적인 lock이다. 여기에 optimistic한 점을 추가하여, write할 때만 lock을 걸고, read는 먼저 시도를 해보고 작업이 끝났을 때 그 사이에 값이 변경되었는지를 체크하는 방식을 이용한다. 즉, read를 시작하고 끝날 때까지 값의 변경이 있으면 fail 처리를 하여 처음부터 다시 시도하는 방식인 것이다. 기존의 readers-writer lock이랑 다른 점이라면, read는 write를 blocking하지 않는다는 것이다. 아래의 코드를 살펴보자.
use core::sync::atomic::{fence, AtomicUsize, Ordering};
pub struct RawSeqLock {
seq: AtomicUsize,
}
impl RawSeqLock {
fn new() -> Self {
Self {
seq: AtomicUsize::new(0),
}
}
fn write_lock(&self) -> usize {
loop {
let seq = self.seq.load(Ordering::Relaxed);
if seq & 1 == 0
&& self
.seq
.compare_exchange(
seq,
seq.wrapping_add(1),
Ordering::Acquire,
Ordering::Relaxed,
)
.is_ok()
{
fence(Ordering::Release);
return seq;
}
}
}
fn write_unlock(&self, seq: usize) {
self.seq.store(seq.wrapping_add(2), Ordering::Release);
}
fn read_begin(&self) -> usize {
loop {
let seq = self.seq.load(Ordering::Acquire);
if seq & 1 == 0 {
return seq;
}
}
}
fn read_validate(&self, seq: usize) -> bool {
fence(Ordering::Acquire);
seq == self.seq.load(Ordering::Relaxed)
}
}seqlock에서 write_lock을 호출하여 seq를 받은 후 write_unlock할 때 넣어주는 방법으로 write lock을 이용할 수 있다. read는 조금 복잡한데, lock이 아니기 때문에 read_begin을 통해 seq를 받은 후 read_validate에 넣어야 한다. 이때 validation이 true이면 read가 성공한 것이고, false면 실패한 것이기 때문에 read_begin부터 다시 시도해야 한다.
여기서 동기화가 조금 더 복잡하다. 크게 세 가지의 동기화가 되어야 한다.
write_unlock과write_lock간의 동기화
둘은 spinlock과 마찬가지로 atomic operation의 release/acquire로서 동기화가 이뤄지고 있다.write_unlock과read_begin간의 동기화
위와 마찬가지로 atomic operation의 release/acquire로서 동기화가 이뤄지고 있다.write_lock과read_validate간의 동기화
처음 말한 것처럼,write_lock이read_validate이전에 일어났다면, read는 fail한 것이다. 위의 코드를 좀 더 펼쳐봐서 각 쓰레드별로 돌아가는 코드를 적어보면 다음과 같다. seqlock으로 보호하고 있는 것을 DATA라고 칭하도록 하겠다.
| Write Thread | Read Thread |
|---|---|
| self.seq.cas(seq, seq + 1, _) fence(release) DATA.write(666) ... | ... DATA.read() fence(acquire) seq == self.seq.load(relaxed) |
여기서 동기화의 목적은 fence-fence 간에 happens before을 보장하여, DATA가 write되고 read되면 seq == self.seq.load(relaxed)가 false이도록 하는 것이다.
fence-fence 동기화는 위에서 설명했던 것처럼, 여기에서 DATA가 atomic write/read라면 보장이 된다. 그렇다면 이를 어떻게 보장하고 있을까? 전체 코드를 살펴보면 이해하기 쉬울 것이다. 실제로 SeqLock을 구현할 때는, 위의 구조체를 한 번 더 wrapping해서 실제 lock으로 보호해야 하는 데이터를 함께 묶어서 구현하였다. 이때 이 데이터를 변경하려면 write_lock을 호출하여 WriteGuard를 통해서 해야 한다. 이때 WriteGuard를 살펴보면, variable을 직접 변경할 수 있는(non-atomic) DerefMut이 아니라, reference만 읽어올 수 있는 Deref만 구현되어 있다. 즉, 변경이 불가능한 reference만 받을 수 있는데, Rust에서 변경 불가능한 것을 변경할 수 있는 것이 일반적으로 atomic의 write이기 때문에 위의 DATA.write와 DATA.read는 atomic으로 구현할 수밖에 없는 상황을 만들어 두었다. 겉으로 보는 safe rust에서는 이를 보장할 수 있을 것이라 생각된다.
Lock-Free 자료구조
Treiber's Stack
간단하게 Stack을 Lock-Free로 만든 Treiber's Stack을 알아보도록 하자. 먼저, 코드부터 보도록 하자.
use std::{mem::ManuallyDrop, ptr, sync::atomic::Ordering};
use crossbeam_epoch::{Atomic, Guard, Owned};
pub struct TreiberStack<V> {
head: Atomic<Node<V>>,
}
struct Node<V> {
value: ManuallyDrop<V>,
next: Atomic<Node<V>>,
}
impl<V> Node<V> {
fn new(value: V) -> Self {
Self {
value: ManuallyDrop::new(value),
next: Atomic::null(),
}
}
}
impl<V> TreiberStack<V> {
pub fn new() -> Self {
Self {
head: Atomic::null(),
}
}
pub fn push(&self, value: V, guard: &Guard) {
let mut node = Owned::new(Node::new(value));
loop {
let head = self.head.load(Ordering::Relaxed, guard); // 1
node.next.store(head, Ordering::Relaxed); // 2
match self.head.compare_exchange(
head,
node,
Ordering::Release, // 3
Ordering::Relaxed, // 4
guard,
) {
Ok(_) => break,
Err(e) => node = e.new,
}
}
}
pub fn pop(&self, guard: &Guard) -> Option<V> {
loop {
let head = self.head.load(Ordering::Acquire, guard); // 5
if let Some(h) = unsafe { head.as_ref() } {
let next = h.next.load(Ordering::Relaxed, guard); // 6
if self
.head
.compare_exchange(
head,
next,
Ordering::Relaxed, // 7
Ordering::Relaxed, // 8
guard,
)
.is_ok()
{
unsafe { guard.defer_destroy(head) };
return unsafe { Some(ManuallyDrop::into_inner(ptr::read(&(*h).value))) };
}
} else {
return None;
}
}
}
}먼저, 알고리즘부터 분석해보도록 하자. 여기서 말하는 'pointer를 읽어온다'의 정의는, pointer를 dereference(pointer의 * 연산)하지 않고, 단순히 variable이 가지고 있는 값을 읽어온다는 이야기이다.
- push
value를 받아다가 node를 만든다. 현재 stack의 head pointer만 읽어오고, 새로운 node의 next에 head pointer를 넣어 연결시킨다. 이후, 현재 stack의 head variable에 대해 CAS를 시도하여 head를 새로운 node의 pointer로 갈아끼우도록 한다. 실패하면 재시도한다. - pop
현재 stack의 head pointer를 읽어온다. 이 pointer가 null이 아니라면 그 node의 next pointer를 읽어온다. 그리고 현재 stack의 head variable에 대해 CAS를 시도하여 next pointer로 갈아 끼우도록 한다. 실패하면 재시도 한다. 성공하면, 이전 head의 node에서 값을 빼서 넘겨주고 node의 free를 요청한다.
알고리즘 자체는 단순하다. 알고리즘을 이해했다면, 이를 바탕으로 memory ordering을 제외하고 코드를 작성해볼 수 있다. 이제 어떤 memory ordering이 들어가야 올바를 지를 분석해보도록 하자. Stack의 기본적인 동기화 전략은 'push한 값을 pop할 때 받아올 수 있어야 한다'이다. 이를 생각해보면서 주석에 적어둔 각 번호별로 어떤 ordering이 적합할 지 분석할 것이다. 물론, Ordering::SeqCst을 넣어주면 잘 돌아가지만, 성능을 위하여 가장 적합한 ordering을 찾아보도록 하자.
- 1: 이때 load한 head pointer값은 node의 next에 저장되고, CAS에서 현재 stack의 head가 이 값인지 체크하는데 사용된다. head가 가리키고 있는 node(head를 dereference했을 때의 node)의 값을 사용하거나, 관련된 객체들과 동기화가 필요한 것이 아니기 때문에
Ordering::Relaxed로 둘 수 있다. - 2: 새로운 node의 next에 이전 head를 연결시키는 부분이다. 역시 동기화를 하는 것도 아니기 때문에
Ordering::Relaxed로 둘 수 있다. 만약, 잘못된 head pointer가 들어갔다 하더라도, 그 잘못된 head pointer는 CAS를 무조건 실패할 것이기 때문에 문제도 없다. - 3: CAS가 성공했을 때 이후에 호출되는 pop에서는 head의 value를 읽을 수 있어야 한다. 따라서
Ordering::Release로 두어 5번과 동기화되도록 한다. - 4: CAS가 실패할 때는 어떠한 동기화도 필요없다.
Ordering::Relaxed로 둔다. - 5: push의 3번과 동기화되는 부분이다. head pointer와 연관된, head를 dereferene했을 때의 node 데이터를 pop해야 하기 때문에
Ordering::Acquire로 둔다. - 6: pop하고 head에 갈아 끼울 next pointer를 읽어오는 부분이다. 1번과 마찬가지로
Ordering::Relaxed로 둘 수 있다. - 7, 8: CAS가 성공하든 실패하든 어떠한 동기화 작업도 필요가 없다.
자, 이렇게 하면 Treiber's Stack을 만들어 볼 수 있다. 이러면 완벽하게 잘 작동하는 Lock-Free Stack을 만들 수 있는 것인가? 귀찮게도 하나 더 고려해야 할 문제가 있다. 이전에 언급했던 ABA 문제가 여기서 발생한다.
Lock-Free 자료구조의 위험성 - ABA 문제
자료구조는 객체들을 저장하거나 삭제하는 등의 관리가 가능한 객체이다. 이때, 객체를 저장하려면 메모리를 할당받아야 하고, 객체를 삭제하려면 메모리 누수를 막기 위해서라도 할당받은 메모리를 free하여 OS에 반환해야 한다. 일반적인 자료구조에서는 이러한 메모리 자원 관리를 간단하게 구현할 수 있지만, Lock-Free 자료구조에서는 조금 더 세심하게 다룰 필요가 있다.
위에서 설명한 Lock-Free Stack을 예시로 보도록 하자. 두 쓰레드 T1, T2가 stack에 작업을 하고 있다고 하자. 마침, stack에는 A(head), B, C가 들어가 있다. T1, T2, T1 순으로 작동하는 것을 살펴보자.
- T1
pop을 시도하다가 CAS를 하기 직전에 쓰레드가 멈추었다. 현재 local head에는 A의 pointer가, local next에는 B의 pointer가 들어가 있다. - T2
pop을 두 번 시도하여 A와 B를 꺼내오는 것을 완료하였다. A, B에 할당된 메모리는 free되었고, OS에 반환은 되지 않았다. 새로운 A'을 stack에 넣는데, 이때 A에 할당됐던 메모리를 재사용하여 push를 성공했다. stack에는 A'(head), C가 들어가 있는 상황이다. - T1
CAS를 시도한다. A'의 pointer 값은 A의 pointer와 같기 때문에 CAS는 성공하고 이미 pop되었고 메모리까지 free된 B의 pointer가 head에 저장된다. 실제로 stack에는 C만 있어야 하고, head도 C여야 하지만, stack의 head에는 C의 pointer가 아닌 B의 pointer가 저장되어 있다.
이렇게 stack이 박살나버린다. 어떻게 문제를 해결할 수 있을까? 조금만 고민해본다면, 결국 메모리 재사용이 핵심이라는 것을 알 수 있다. 따라서 안전할 때 메모리를 free해준다면 문제가 없을 것이다. 이것이 동시성 프로그래밍에 GC가 필요한 이유이다. GC가 있으면 해결이 되기 때문에, 위의 Lock-Free Stack은 Java로 구현하면 ABA 문제가 발생하지 않는다.
이전에 Rust의 crossbeam-epoch를 사용하여 ABA 문제를 막을 수 있다고 하였다. crossbeam-epoch에서는 Atomic이 Shared로 load할 때 pin을 이용하여 EBR이 메모리를 안전하게 관리할 수 있도록 한다. 간단하게 설명하면, 메모리 free를 요청한 Shared에 pin을 했던 쓰레드들이 일을 끝마치면, 더 이상 Shared pointer를 가지고 있는 쓰레드가 없기 때문에, 이때 메모리를 free할 수 있도록 해준다. 다시 Treiber's Stack 코드로 돌아가 살펴보면, guard.defer_destroy(head)를 확인할 수 있다. 이것이 EBR에 head node의 메모리 free를 요청하는 부분이다.
이외에 여러가지 해결책이 존재한다.
- pointer에 tag 달기
메모리 주소 중에서 실제로 사용하지 않는 비트를 tag로서 사용하는 것이다. tag로는 unique한 무언가를 저장해주면 좋을 것이다. 예를 들어 지금까지 stack에 발생한 push 횟수를 저장해놓는 등의 방법을 취할 수 있을 것이다. 64bit 아키택쳐에서는 실제로 메모리 주소로 52bit만 사용하고, 메모리 할당 시에 8byte나 16byte로 정렬하기 때문에 15~16bit 정도를 이러한 tag로 활용할 수 있다. 32bit 아키택쳐나 tag로는 부족할만큼 크기가 큰 unique한 tag를 붙여야 한다면 double check CAS 등을 활용해볼 수도 있다. 다만, 성능이 매우 안 좋아질 것이다. - CAS를 사용하지 않기
다시 생각해보면, 실제로 head variable에 저장된 값은 변경되었는데(A→B→C→A') 원래대로 돌아왔기 때문에 문제가 생겼다고도 볼 수 있다. 즉, CAS는 variable이 다르다는 비교만 가능하지 실제 variable의 메모리 변경을 관찰할 수 없어서이기도 하다. AMD64, x86 등의 아키택쳐에서는 CAS를 명령어로 가지고 있지만, 위에서 말했다시피 ARM 등은 CAS가 아닌 ll, sc를 사용한다고 했다. 이러한 아키택쳐에서는 메모리 변경 자체를 관찰할 수 있기 때문에 ABA 문제를 원천적으로 해결할 수 있기도 하다.
동시성 프로그래밍의 최적화
이제까지 실질적인 동시성 프로그래밍의 구현체를 살펴보았다. 구현을 이렇게 할 수 있다면, 어떻게 더 최적화할 수 있을까? 간단하게 여러가지 기법을 소개해보고자 한다.
더 나은 SpinLock
위에서 다뤘던 spinlock의 lock 부분을 다시 살펴보도록 하자.
fn lock(&self) {
while self.flag.compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed).is_err()
{}
}수많은 쓰레드들이 동시에 lock을 시도한다고 하면, 아주 심한 경쟁(contention)이 있을 것이다. 그리고 어떤 쓰레드가 critical section에 들어가있다면, 사실상 매우 실패할 확률이 높음에도 실패한 다음 바로 즉시 CAS를 재시도할 것이다. 이때 true임에도 매번 CAS를 호출하는 것은 꽤 비효율적일 것이다. 따라서 아래와 같이, 일단 true인지 체크하다가 false이면 CAS를 시도하도록 만들어 볼 수 있다. 이를 TTAS(TestTestAndSet)이라 부른다. 이때는 true라면 이전에 캐시에 불러온 값을 그대로 쓸 수 있기 때문에 효율적일 수 있다.
fn lock(&self) {
loop {
if self.flag.load(Ordering::Relaxed) {
continue;
}
if self.flag.compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed).is_ok()
{
break;
}
}
}또한, 실패한 CAS와 다음 시도할 CAS 사이에 아주 작은 sleep을 둔다면 전반적인 성능을 개선해볼 수 있다. crossbeam에서는 Backoff를 통해 이러한 기능을 제공한다. 아래와 같이 적용해볼 수 있다.
use crossbeam::utils::Backoff;
fn lock(&self) {
let backoff = Backoff::new();
while self.flag.compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed).is_err()
{
backoff.snooze();
}
}Backoff는 아주 짧은 시간을 몇 번 exponential하게 쉬다가 그래도 계속 실패하여 호출된다면, OS의 스케줄러에 요청을 하여 일정 시간 이후에 다시 시도하도록 만든다.
Backoff에는 snooze와 spin이 있다. 문서에 따르면, snooze는 blocking 구간에서(다른 쓰레드가 작업을 마칠 때까지 기다려야 하는 경우) 사용하고, spin은 lock-free loop에서 사용한다고 한다. 이제까지 소개한 구현체에서 loop가 있는 경우 적절하게 Backoff를 사용하여 성능을 개선할 수 있다.
compare_exchange도 아키택쳐에 따라 최적화 해볼 여지가 있다. 이전에 CAS는 ARM 등의 아키택쳐에서 ll/sc로 구현된다고 말했었다. ll/sc의 특성상 똑같은 값을 rewrite하더라도 sc를 실패하기 때문에, 강력한 compare_exchange(무조건 똑같은 값이면 바꾸도록)을 구현하는 것은 다소 비용이 든다. 이때, 설령 같더라도 실패하도록 약하게 만든다면, 이러한 아키택쳐에서는 좀 더 효율적인 기계어가 나올 수 있다. CAS를 아래와 같이 C++로 짜 보고, ARM64에서 strong과 weak가 어떻게 다른지 확인해보도록 하자.
#include<atomic>
std::atomic_bool flag(false);
void exchg() {
bool temp = false;
auto a = flag.compare_exchange_strong(temp, true, std::memory_order_relaxed, std::memory_order_relaxed);
}compare_exchange_strong일 때:
armv8-a clang 11.0.1 -O2
exchg(): // @exchg()
adrp x8, flag
add x8, x8, :lo12:flag
mov w9, #1
.LBB0_1: // =>This Inner Loop Header: Depth=1
ldxrb w10, [x8]
cbnz w10, .LBB0_4
stxrb w10, w9, [x8]
cbnz w10, .LBB0_1
ret
.LBB0_4:
clrex
ret
flag:
.zero 1compare_exchange_weak일 때:
armv8-a clang 11.0.1 -O2
exchg(): // @exchg()
adrp x8, flag
add x8, x8, :lo12:flag
ldxrb w9, [x8]
cbz w9, .LBB0_2
clrex
ret
.LBB0_2:
mov w9, #1
stxrb w10, w9, [x8]
ret
flag:
.zero 1여기서 ll/sc에 해당하는 어셈블리 명령어는 ldxrb, stxrb이다. 보다시피, compare_exchange_strong에서는 읽은 값이 false인데 여기에 true(w9)를 쓰는 것을 실패하면, 재시도하는 더 강력한 제약을 가진 것을 확인할 수 있다.
위에서 설명한 것을 적용하여 AMD64와 ARM64에서 벤치마크를 돌려보면 다음과 같다. SpinLock에 위에서 예시로 든 counter를 적용하여 평균시간을 재보았다. 여기서 소스코드를 확인해볼 수 있다.
| 최적화 | AMD64 | ARM64 |
|---|---|---|
| None | 154 ms | 205 ms |
| TTAS | 141 ms | 188 ms |
| Backoff | 92 ms | 60 ms |
| CAS_weak | 150 ms | 201 ms |
Backoff 말고는 크게 체감될 정도의 성능향상은 없다. CAS_weak는 사실 컴파일러가 조금만 똑똑하더라도 SpinLock에서 CAS_strong과 비슷하게 최적화할 수 있기 때문에 오차 범위에서 동등한 성능을 보이는 듯하다. TTAS는 소폭의 성능 향상이 있긴 하지만, 만약에 모든 쓰레드가 동시에 if 구간을 체크하고 한꺼번에 CAS를 시도하면 역시 contention이 있기 때문에 그런 듯 하다. 특히, 이 counter의 경우에는 lock/unlock이 아주 빈번하기 때문에 큰 효과가 없는 것이 아닐까 싶다.
더 나은 Lock-Free Stack
SpinLock과 같은 방법으로 Backoff를 추가하여 Treiber's Stack을 개선해볼 수 있다. 여기서 어떻게 더 개선해볼 수 있을까? 이를 변형하여 개선한 Elimination-Backoff Stack을 소개해보고자 한다.
Treiber's Stack의 push/pop을 다시 살펴보도록 하자.
pub fn push(&self, value: V, guard: &Guard) {
let mut node = Owned::new(Node::new(value));
let backoff = Backoff::new();
loop {
let head = self.head.load(Ordering::Relaxed, guard); // 1
node.next.store(head, Ordering::Relaxed); // 2
match self.head.compare_exchange(
head,
node,
Ordering::Release, // 3
Ordering::Relaxed, // 4
guard,
) {
Ok(_) => break,
Err(e) => node = e.new,
}
backoff.spin();
}
}
pub fn pop(&self, guard: &Guard) -> Option<V> {
let backoff = Backoff::new();
loop {
let head = self.head.load(Ordering::Acquire, guard); // 5
if let Some(h) = unsafe { head.as_ref() } {
let next = h.next.load(Ordering::Relaxed, guard); // 6
if self
.head
.compare_exchange(
head,
next,
Ordering::Relaxed, // 7
Ordering::Relaxed, // 8
guard,
)
.is_ok()
{
unsafe { guard.defer_destroy(head) };
return unsafe { Some(ManuallyDrop::into_inner(ptr::read(&(*h).value))) };
}
} else {
return None;
}
backoff.spin();
}
}Treiber's Stack의 문제는, self.head의 CAS에만 의존적이라는 것이다. 즉, 수많은 쓰레드가 push/pop을 동시에 실행하려 하면, 수많은 CAS가 실패할 것이고 이것이 곧 throughput 하락의 원인이 된다. 아무리 lock-free라 하더라도 근본적인 contention을 분산시키지 못한다면 scalability는 만족스럽지 않을 수 있다. Elimination Backoff Stack에서는 push와 pop의 쌍을 제거하면 stack을 변형하지 않아도, LIFO의 Stack 특성을 만족시킬 수 있는 전략으로 contention을 분산시켰다.
Elimination Backoff Stack은 다음과 같이 push/pop에 대해 구현할 수 있다.
- lock-free stack에 push/pop을 시도한다. 성공하면 끝.
- 실패하면, elimination array에서 임의의 칸을 고른다.
- 고른 칸이 비어 있으면 칸을 push/pop 연산으로 채우고, 칸이 push/pop으로 채워져있다면 pop/push가 쌍을 이루도록 시도한다.
- 살짝 기다린다.
- 다시 칸을 체크하여 칸이 쌍을 이루거나 비어 있으면 연산이 정상적으로 처리된 것으로 끝낸다. 아니라면, 처음부터 재시도한다. 이때 쌍을 이룬 것을 free하는 책임은 pop 연산쪽에서 진다.
즉, 기존에 self.head에만 걸렸던 contention을 array의 random access를 통해 분산시키는 전략이다. Treiber's Stack을 기초로 하여 다음과 같이 구현해볼 수 있다. 소스코드, 이외에 elimination-backoff-stack에서 벤치마크와 함께 다른 구현체를 살펴볼 수 있다.
얼핏 생각해보면, elimination array를 쓰기 때문에 Stack의 가장 중요한 특성인 LIFO가 깨질 수 있지 않나 싶다. 구체적인 linearizability(선형화가능성)에 대한 증명은 논문에 나와 있으니 살펴보면 좋을 거 같다. 약식으로 개인적인 생각을 말해보자면, 어차피 멀티쓰레드에서 시간 상으로 겹쳐있는 수많은 연산에 대해서는 간단한 규칙(push가 된 것만 pop을 할 수 있다, 1개의 push는 1개의 pop에만 대응된다)만 지켜지면, linearlizable하게 연산의 순서를 배치할 수 있을 거 같다는 직관이 있다.
정리
이 글을 통해서 동시성 프로그래밍은 어떻게 해야 하는지, 해야 한다면 지켜야할 것과 고려해야할 부분을 살펴보았다. 또한, 이를 적용해보면서 실사례에서 어떻게 바라볼 수 있을지 알아보았다. 원래 이렇게 길게 쓸 생각은 없었는데, 동시성 프로그래밍에 대해서 인터넷에서 찾아볼 수 있는 정보는 심각하게 파편화되어 있고, 다 영어고, 정리가 전혀 되어 있지 않은 거 같아서 이번 기회에 각 잡고 정리를 해보았다. 특히, C++ memory model에 대한 내용은 https://preshing.com/ 블로그를 많이 참고하고 정리하였으니, 필자가 이상하게 썼다 싶거나 이해가 안 간다면 저쪽 글을 읽어보는 것을 추천한다. 더불어 실제로 동시성 프로그래밍을 잘 해보고 싶다면 https://github.com/kaist-cp/cs431 강의를 듣고 숙제를 직접 해보는 것을 추천한다.
이외에 다른 동시성 자료구조를 살펴보고 싶다면 필자가 직접 구현하고 있는 Concurrent Data Structure for Rust를 참고해보면 좋을 거 같다. 글의 내용이 애매모호하거나, 잘못됐거나, 코드가 틀렸다면 댓글 등으로 알려주면 정말 좋을 거 같다.
Reference
- https://github.com/kaist-cp/cs431
- https://github.com/crossbeam-rs/crossbeam
- The Art of Multiprocessor Programming
- memory_order reference: https://en.cppreference.com/w/cpp/atomic/memory_order
- https://en.wikipedia.org/wiki/Memory_ordering
- C++20 표준문서: http://open-std.org/jtc1/sc22/wg21/docs/papers/2020/n4868.pdf
- 관련 QnA 찾아본 것들
- https://stackoverflow.com/questions/6319146/c11-introduced-a-standardized-memory-model-what-does-it-mean-and-how-is-it-g
- https://stackoverflow.com/questions/19965076/gcc-memory-barrier-sync-synchronize-vs-asm-volatile-memory
- https://stackoverflow.com/questions/52606524/what-exact-rules-in-the-c-memory-model-prevent-reordering-before-acquire-opera
- https://stackoverflow.com/questions/55079321/atomic-operation-propagation-visibility-atomic-load-vs-atomic-rmw-load
- https://www.gamedev.net/forums/topic/686183-stdatomic-memory-ordering-question/
- LLVM 문서: https://llvm.org/docs/Atomics.html
- https://preshing.com/20130702/the-happens-before-relation/
- https://preshing.com/20170612/can-reordering-of-release-acquire-operations-introduce-deadlock/
- https://preshing.com/20121019/this-is-why-they-call-it-a-weakly-ordered-cpu/
- https://preshing.com/20120625/memory-ordering-at-compile-time/
- https://preshing.com/20120710/memory-barriers-are-like-source-control-operations/
- https://preshing.com/20131125/acquire-and-release-fences-dont-work-the-way-youd-expect/
- https://preshing.com/20120930/weak-vs-strong-memory-models/
- https://preshing.com/20130922/acquire-and-release-fences/
- https://preshing.com/20120710/memory-barriers-are-like-source-control-operations/
- https://github.com/CppKorea/CppConcurrencyInAction
- https://www.modernescpp.com/index.php/fences-as-memory-barriers
- Treiber's Stack: https://dominoweb.draco.res.ibm.com/58319a2ed2b1078985257003004617ef.html
- Elimination-Backoff Stack: https://people.csail.mit.edu/shanir/publications/Lock_Free.pdf
- 다른 Elimination-Backoff Stack 구현체: https://github.com/mxinden/elimination-backoff-stack


좋은글 감사합니다! 정말 재미있게 읽었습니다🙏