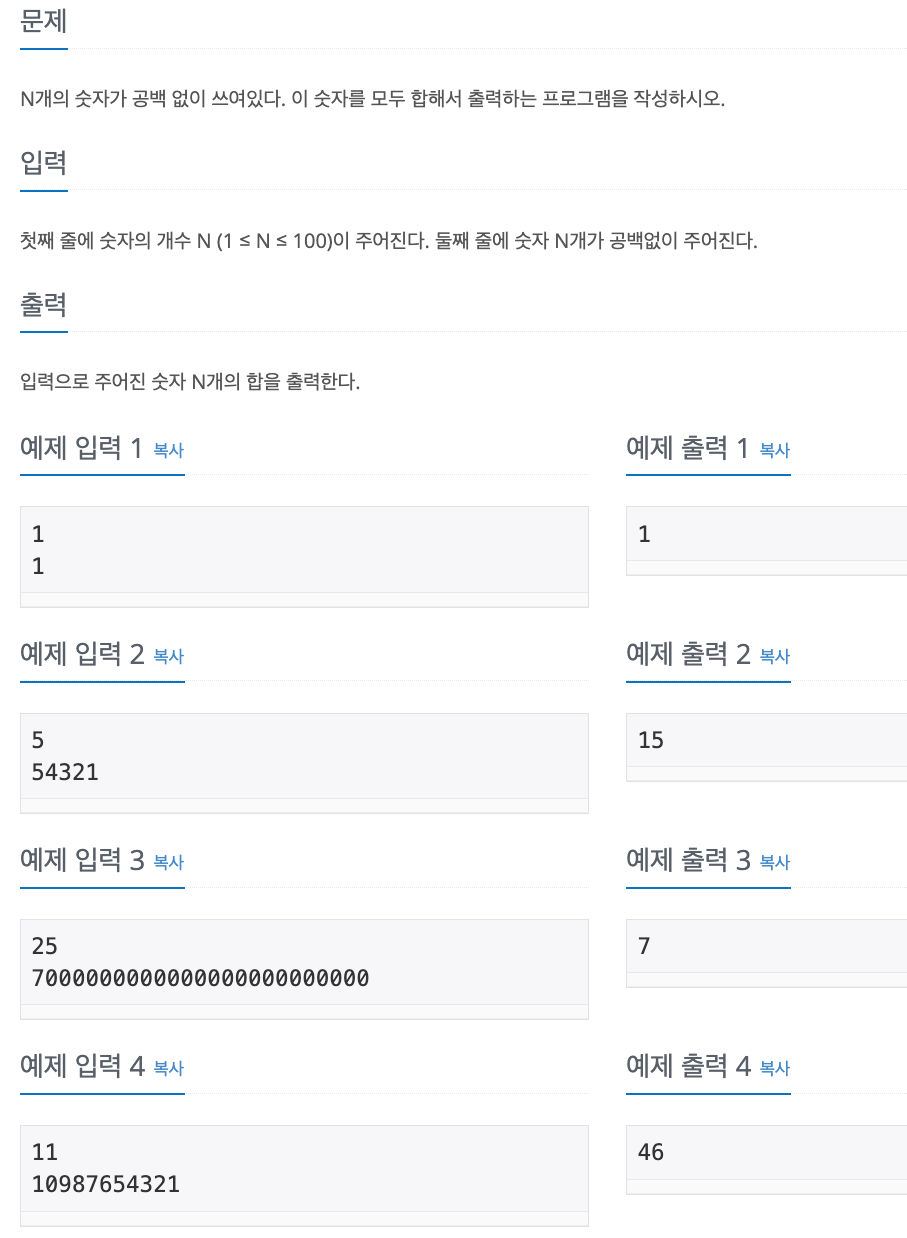
No. 11720
1. Problem
2. My Solution
- eval 함수를 이용하여 문자열 식을 수행함
import sys
n = sys.stdin.readline().strip()
result = eval('+'.join(sys.stdin.readline().strip()))
print(result)No. 10809
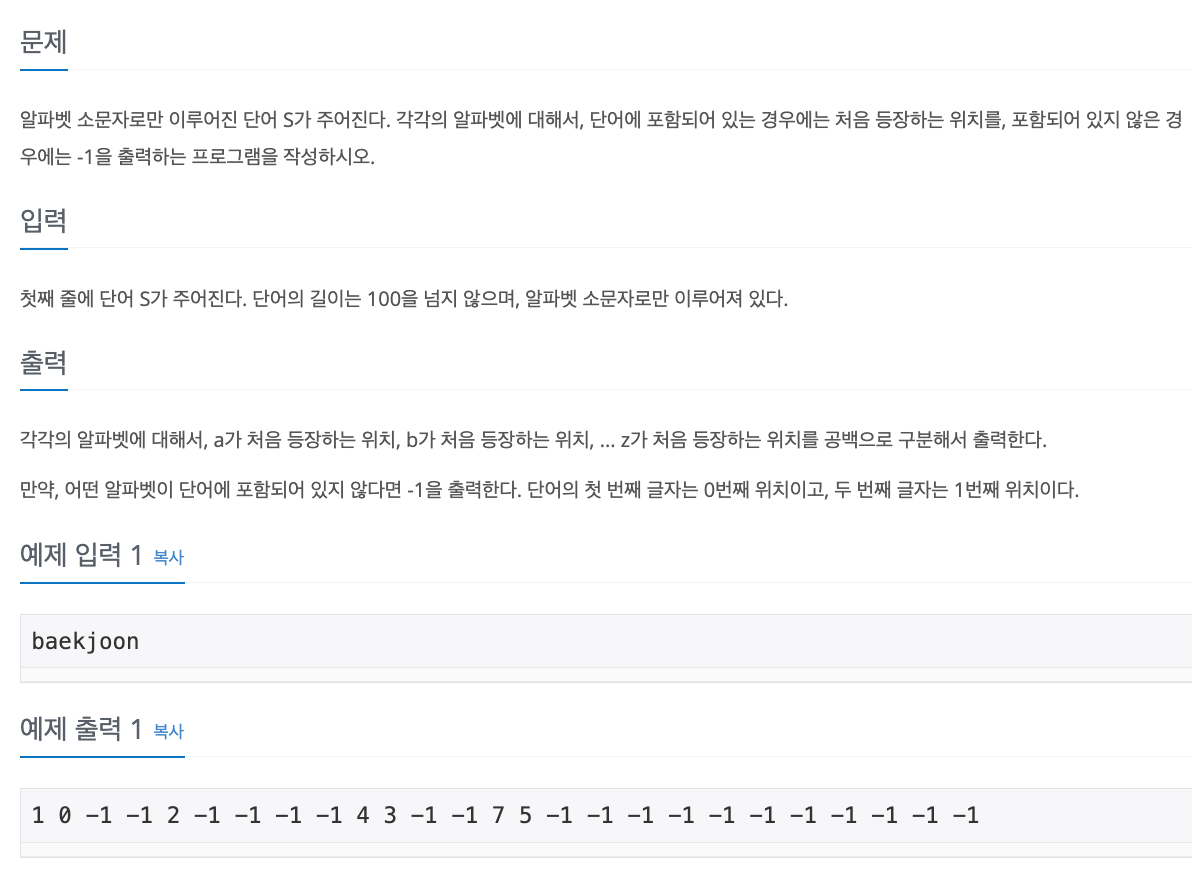
1. Problem
2. My Solution
- 알파벳 a~z 까지 범위를 설정하기 위해 ord() 함수 이용
- index() 함수 수행시 해당 요소가 없다면 ValueError 발생 -> try-except 문 이용
import sys
s = sys.stdin.readline().strip()
result = []
for i in range(ord('a'), ord('z')+1):
try:
result.append(s.index(chr(i)))
except:
result.append(-1)
for i in range(len(result)):
print(result[i], end=' ')- 다른 방법
import sys
word = sys.stdin.readline().strip()
alphabet = [-1] * 26
for i in word:
alphabet[ord(i)-97] = word.index(i)
print(' '.join(map(str,alphabet)))
3. Learned
- ord() - 문자를 아스키 코드로 변환
- chr() - 아스키 코드를 문자로 변환
- 예외 발생 시 except 문 이용하자
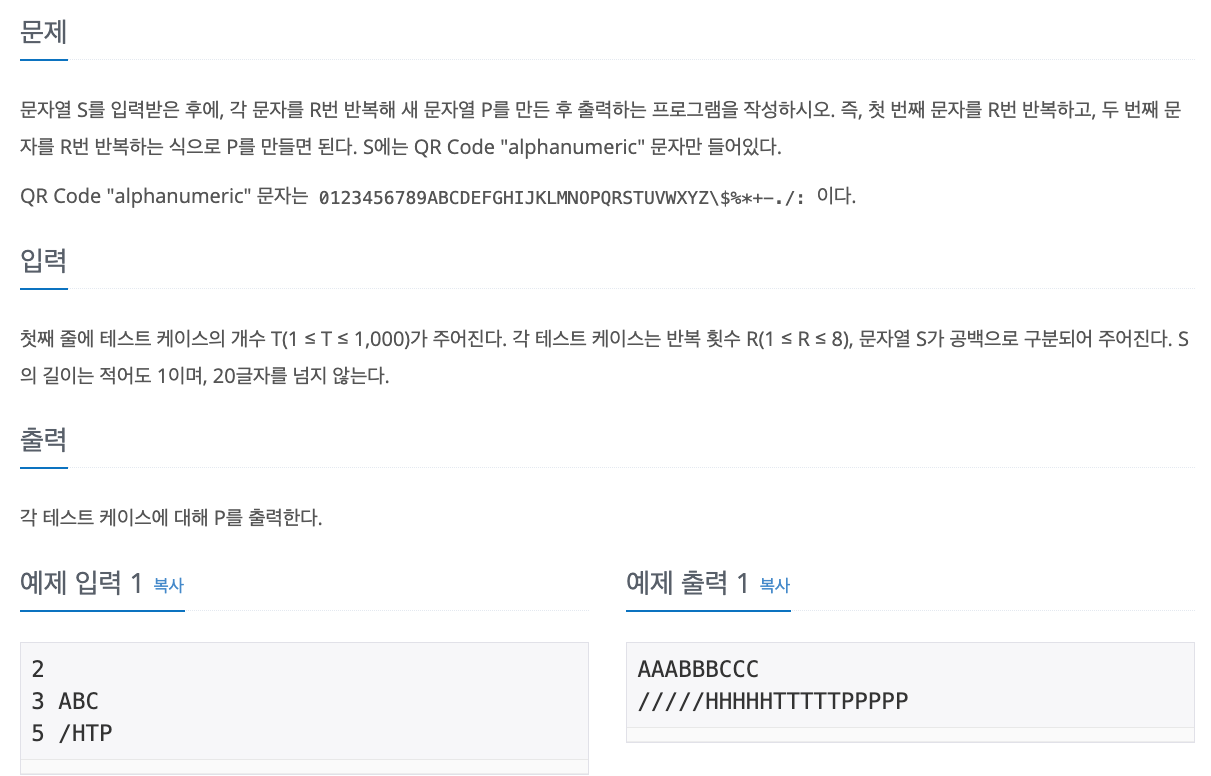
No. 2675
1. Problem
2. My Solution
import sys
n = int(sys.stdin.readline().strip())
for i in range(n):
rep, str = sys.stdin.readline().strip().split()
result = ""
for j in range(len(str)):
result += (str[j]* int(rep))
print(result)
3. Others' Solutions
- str 문자열의 각 문자를 [] 인덱스 연산자로 접근하지 않고 for in 문을 이용해서 바로 접근
import sys
n = int(sys.stdin.readline().strip())
for i in range(n):
rep, str = sys.stdin.readline().strip().split()
result = ""
for j in str:
result += j * int(rep)
print(result)
4. Learned
- 문자열의 각 요소는 for in 문을 사용하면 각각 접근 가능하다
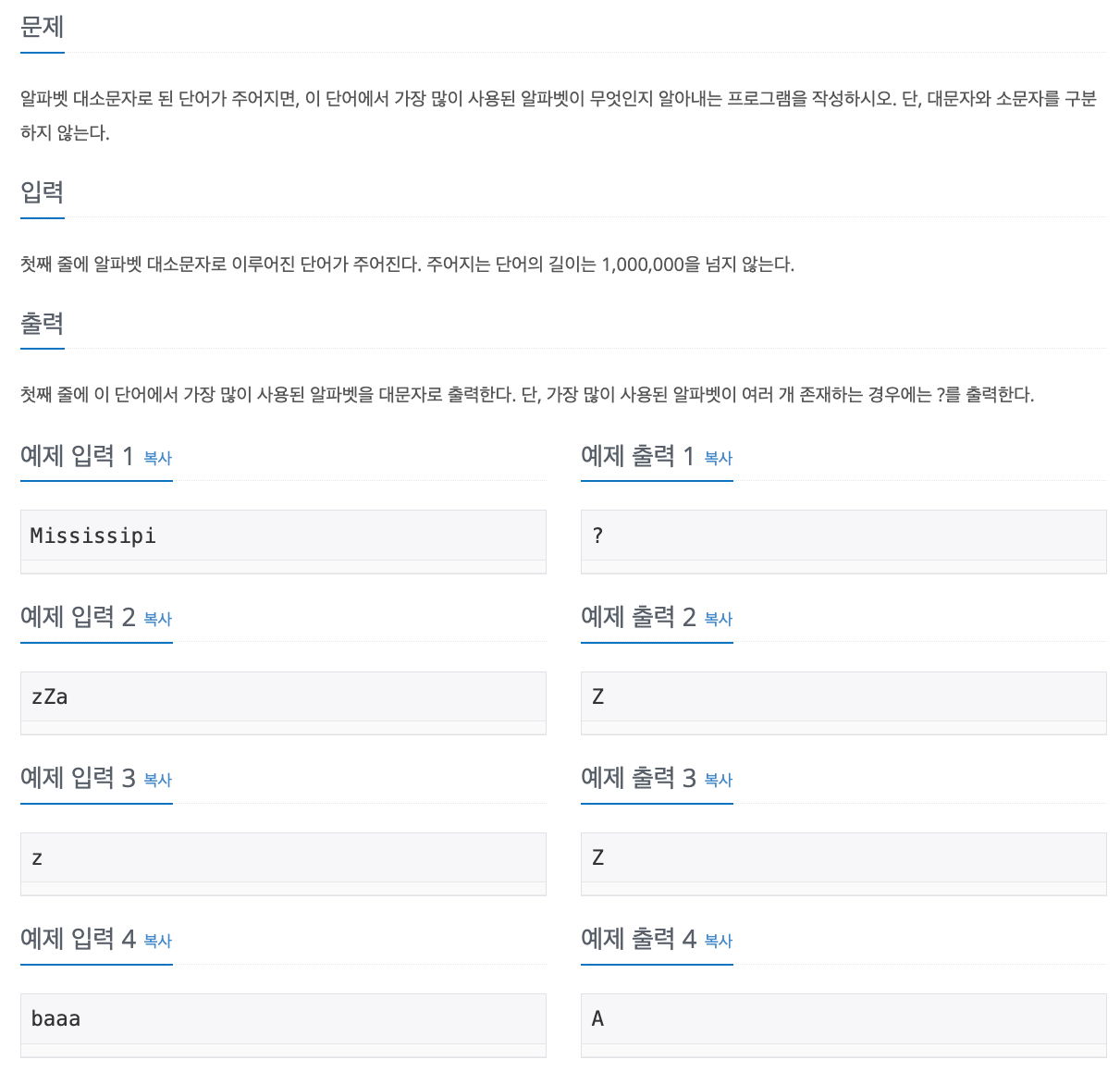
No. 1157
1. Problem
2. My Solution
- 시간이 너무 오래 걸림
import sys
word = [char.lower() for char in sys.stdin.readline().strip()]
alpha_count = []
for i in range(ord('a'), ord('z')+1):
alpha_count.append(word.count(chr(i)))
if alpha_count.count(max(alpha_count)) > 1 :
print("?")
else:
print(chr(alpha_count.index(max(alpha_count))+97).upper())
3. Others' Solutions
- 방법 1
- 입력 받은 문자열을 바로 .upper() 함수 적용
mport sys
word = sys.stdin.readline().upper()
alpha_count = []
for i in range(ord('A'), ord('Z')+1):
alpha_count.append(word.count(chr(i)))
if alpha_count.count(max(alpha_count)) > 1 :
print("?")
else:
print(chr(alpha_count.index(max(alpha_count))+65))- 방법 2
- set 자료형을 이용해서 중복되는 알파벳 제거한 후에 리스트로 다시 담아서 판단
- 개수가 가장 많은 알파벳의 수를 나타내는 인덱스를 이용
import sys
word = sys.stdin.readline().strip().upper()
char_list = list(set(word))
alpha_count = []
for char in char_list:
alpha_count.append(word.count(char))
if alpha_count.count(max(alpha_count)) > 1 :
print("?")
else:
print(char_list[alpha_count.index(max(alpha_count))])
4. Learned
- 문자열 전체에 바로 upper / lower 함수 적용 가능
- 중복되는 값을 제거하기 위해 set 자료형 이용
- 인덱스를 잘 이용하자
No. 2908
1. Problem
2. My Solution
- 각 수를 직접 비교했음
import sys
a,b = sys.stdin.readline().strip().split()
a,b = a[::-1], b[::-1]
if int(a) > int(b):
print(a)
else:
print(b)
3. Others' Solutions
- 각 수를 리스트에 담고 max 함수를 이용함
print(max(input()[::-1].split()))
4. Learned
- 문자열을 역순으로 출력하기 위해선 문자열[::-1] 이용
- 큰 수 또는 작은 수 구할 때는 max / min을 이용해보자
No. 2908
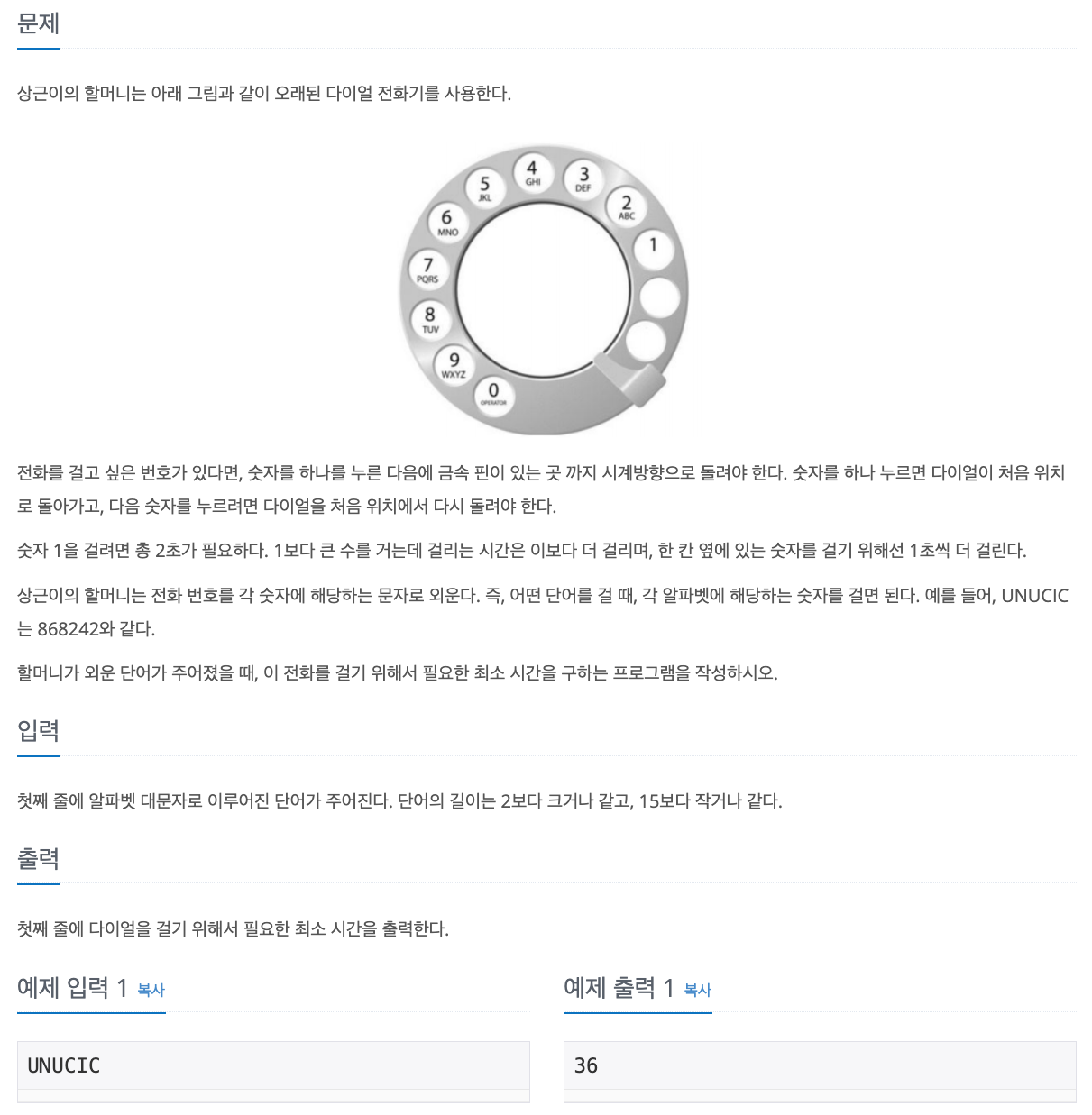
1. Problem
2. My Solution
import sys
alpha_num = [['A','B','C'],['D','E','F'],['G','H','I'],['J','K','L'],['M','N','O'],['P','Q','R','S'],['T','U','V'],['W','X','Y','Z']]
word = list(sys.stdin.readline().strip())
total_time = 0
for i in word:
for j in range(len(alpha_num)):
if i in alpha_num[j]:
total_time += j+3
print(total_time)
4. Learned
- VScode 상에서는 아래 코드가 제대로 수행되지만 백준에서는 런타임 에러 발생
- 개행을 할 때 ' \ ' 추가하기
import sys
alpha_num = [['A','B','C'],['D','E','F'],['G','H','I'],['J','K','L'],
['M','N','O'],['P','Q','R','S'],['T','U','V'],['W','X','Y','Z']]
word = list(sys.stdin.readline().strip())
total_time = 0
for i in word:
for j in range(len(alpha_num)):
if i in alpha_num[j]:
total_time += j+3
print(total_time)
