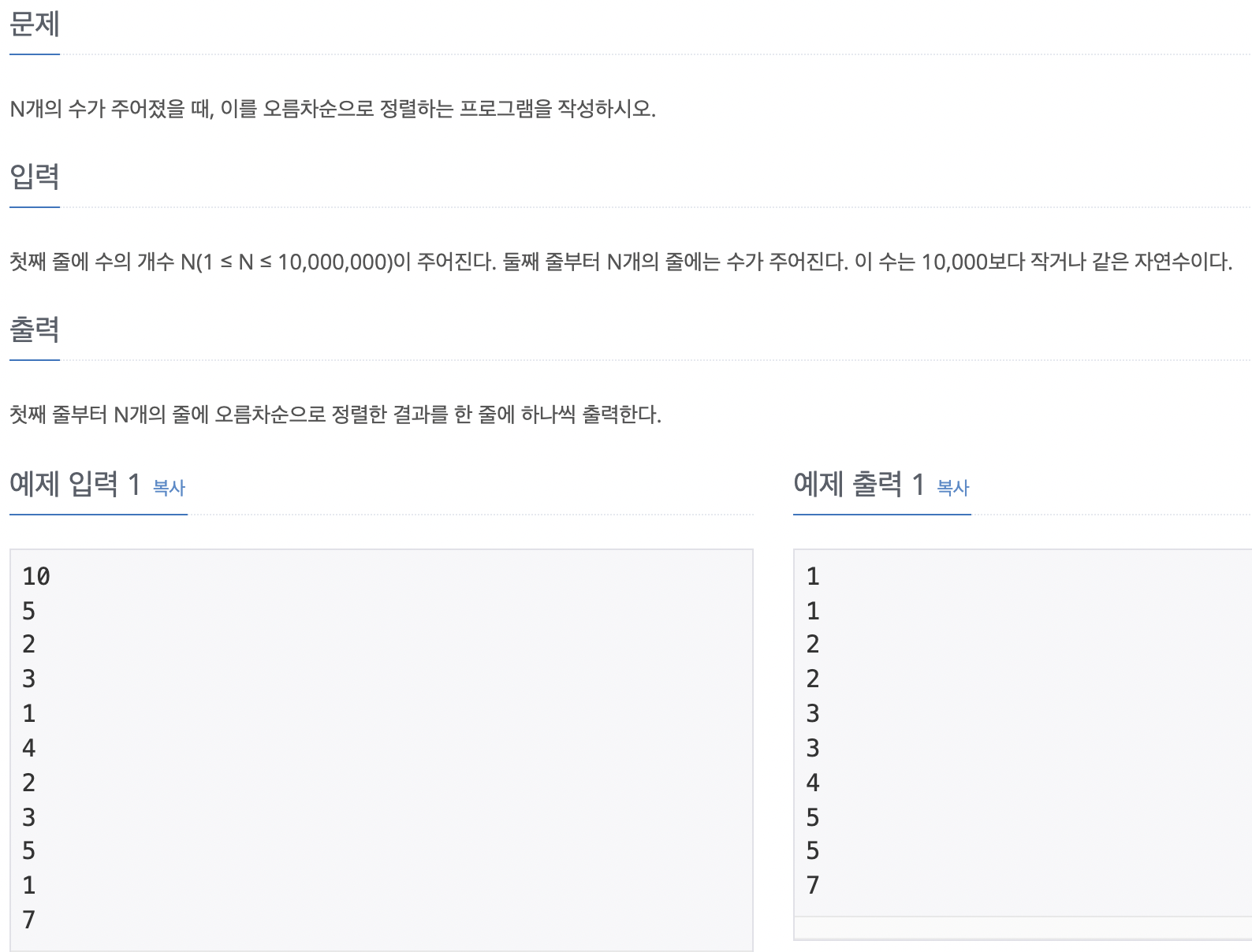
No. 10989
1. Problem
2. My Solution
- 입력 n 의 크기가 10,000,000 이므로 O(n^2) 알고리즘을 사용하면 시간초과가 일어날 수 가 있음
- 정렬될 수의 최대 크기 10000이 주어짐
- O(n) 알고리즘인 계수(Counting) 정렬 사용
import sys
n = int(sys.stdin.readline().strip())
count_list = [0 for _ in range(10001)]
for i in range(n):
num = int(sys.stdin.readline().strip())
count_list[num] += 1 # count
for i in range(len(count_list)):
for _ in range(count_list[i]):
print(i)
3. Learned
- 보통 입력의 크기가 1억이면 1초로 간주하므로 해당 문제를 해결하는 알고리즘의 복잡도를 신경쓰자
- 계수 정렬 알고리즘 참고 동영상
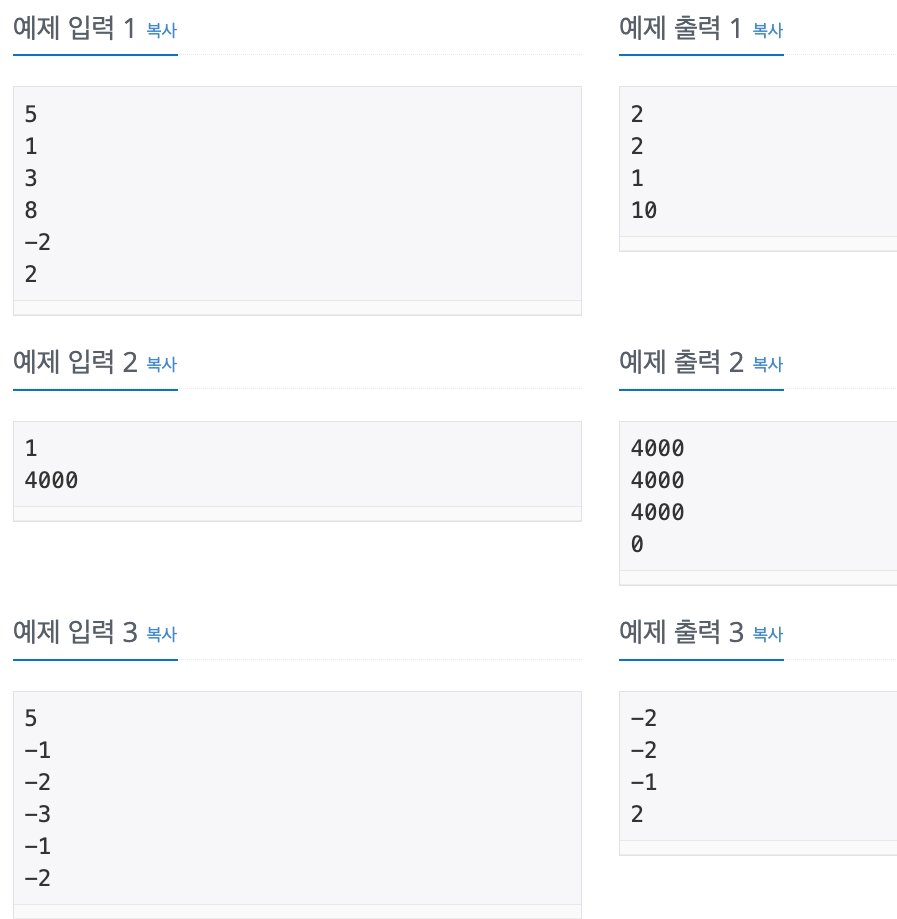
No. 2108
1. Problem

2. My Solution
- 파이썬 통계 관련 라이브러리 statistics 사용
import sys
import statistics
n = int(sys.stdin.readline().strip())
num_list = []
for _ in range(n):
num_list.append(int(sys.stdin.readline().strip()))
num_list.sort()
count = statistics.multimode(num_list)
print(round(statistics.mean(num_list)))
print(statistics.median(num_list))
if len(count) == 1:
print(count[0])
else:
print(count[1])
print(num_list[-1]-num_list[0])
3. Others' Solutions
- 계수 정렬을 이용하기 위해 -4000 ~ 4000을 위한 리스트 선언해서 사용
4. Learned
- 통계 관련 처리를 구현할 때는 statistics 라이브러리 이용
- multimode() 함수 - 빈도수 높은 요소를 반환
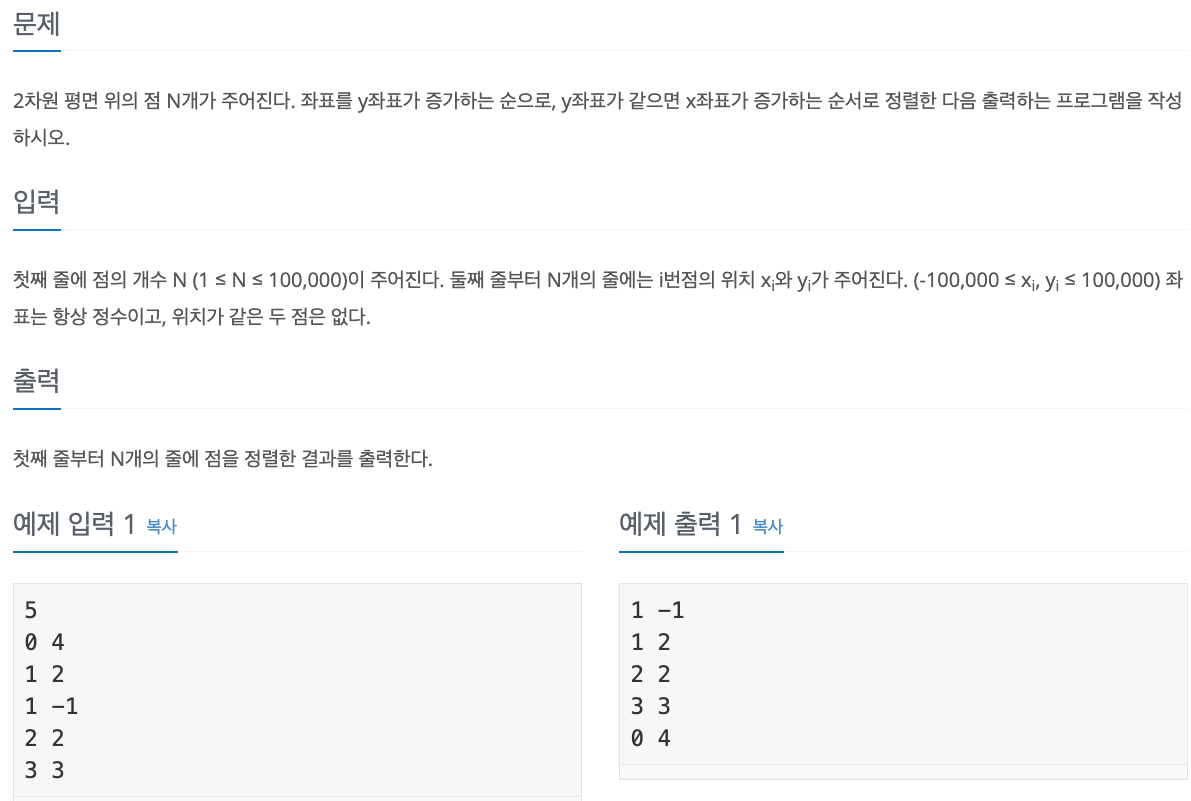
No. 11651
1. Problem
2. My Solution
- .sort() 함수의 key 인자를 이용해서 단계별 정렬 구현
- 1차적으로 x[1] 의 요소를 기준으로 정렬하고 거기서 x[0] 요소로 다시 정렬
import sys
test_n = int(sys.stdin.readline().strip())
xy_list = []
for _ in range(test_n):
xy_list.append(list(map(int,sys.stdin.readline().strip().split())))
xy_list.sort(key=lambda x: (x[1],x[0]))
for i in xy_list:
print(' '.join(map(str,i)))
3. Learned
- .sort() 함수의 key 인자(정렬 기준)를 람다식으로 지정하자
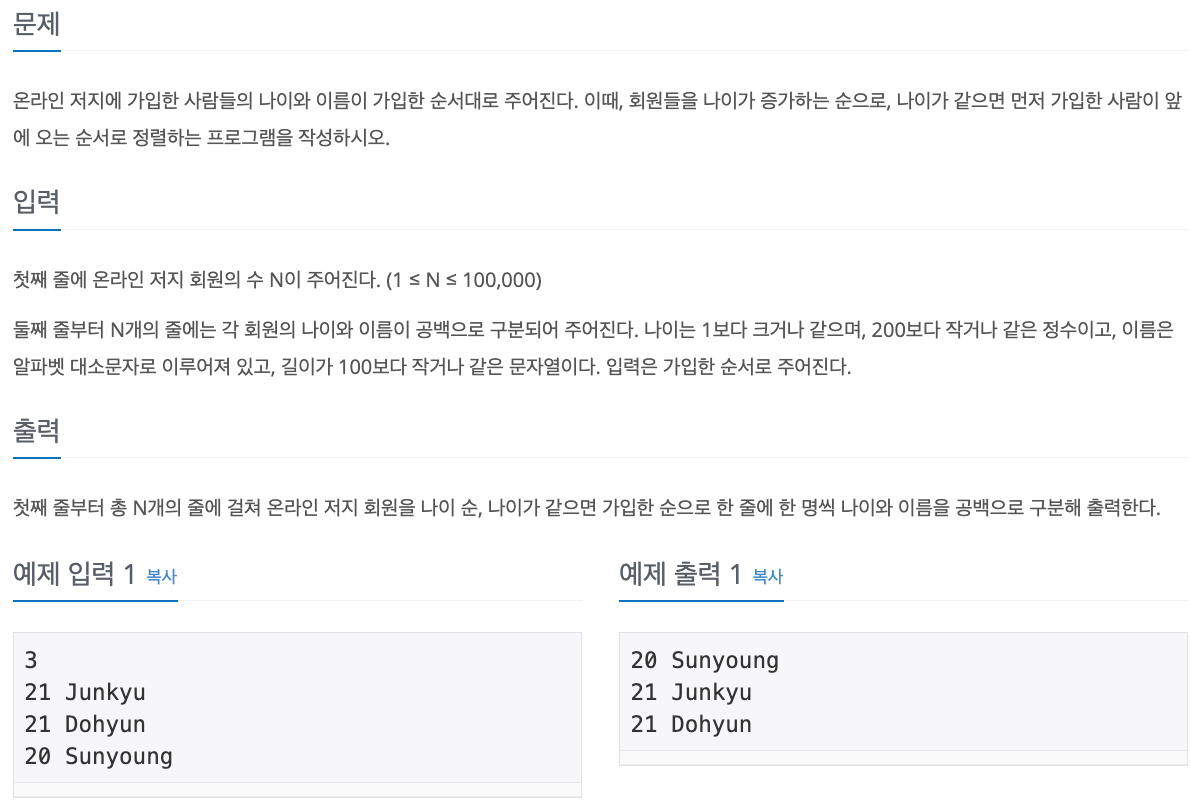
No. 10814
1. Problem
2. My Solution
- "틀렸습니다" -> 나이를 문자열로 인식하여 100이 20보다 더 작게 처리됨
import sys
test_n = int(sys.stdin.readline().strip())
user_info = []
for _ in range(test_n):
user_info.append(sys.stdin.readline().strip().split())
user_info.sort(key=lambda x:x[0])
for i in user_info:
print(' '.join(map(str,i)))
3. Others' Solutions
import sys
test_n = int(sys.stdin.readline().strip())
user_info = []
for _ in range(test_n):
age, name = sys.stdin.readline().strip().split()
user_info.append([int(age),name])
user_info.sort(key=lambda x:x[0])
for i in user_info:
print(' '.join(map(str,i)))
4. Learned
- 천천히 하나 하나 생각해가면서 실수하지 않고 알고리즘을 구현하자
No. 18870
1. Problem
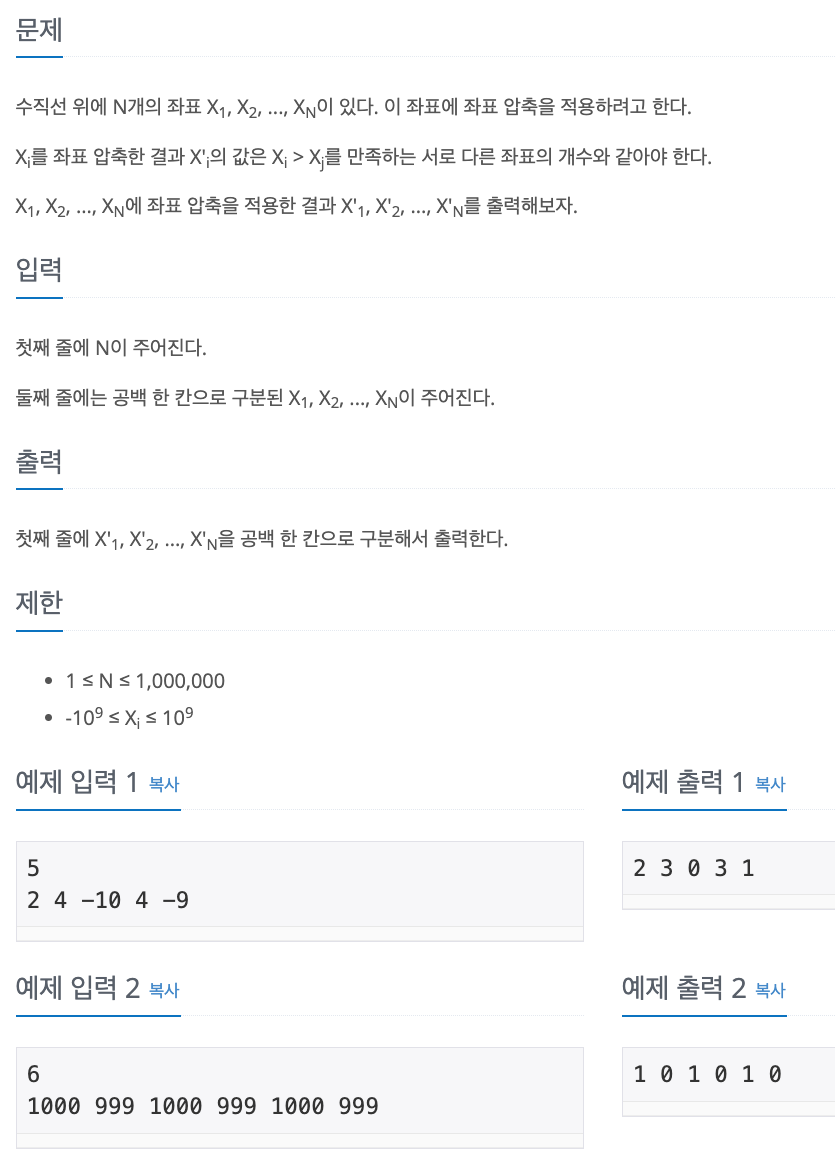
2. My Solution
- 해당 요소가 몇 번째로 작은 수 인지 판단하기 위해 set 자료형으로 중복을 없앤 뒤 index 로 판단
- index() 함수의 시간 복잡도는 O(n) -> 시간 초과
import sys
test_n = int(sys.stdin.readline().strip())
num_list = list(map(int,sys.stdin.readline().strip().split()))
set_list = sorted(list(set(num_list)))
count_list =[]
for i in num_list:
print(set_list.index(i), end=' ')
3. Others' Solutions
- index() 함수를 통해 몇 번째로 작은지 탐색하지 않고 dictionary 자료형 사용
- key (요소) : value (몇 번째 인지 나타내는 수)
import sys
test_n = int(sys.stdin.readline().strip())
num_list = list(map(int,sys.stdin.readline().strip().split()))
set_list = sorted(list(set(num_list)))
dic_list = {set_list[i]:i for i in range(len(set_list))}
for i in num_list:
print(dic_list[i], end=' ')
4. Learned
- 탐색을 할 때는 시간복잡도가 O(1)인 dict 자료형을 사용하자
