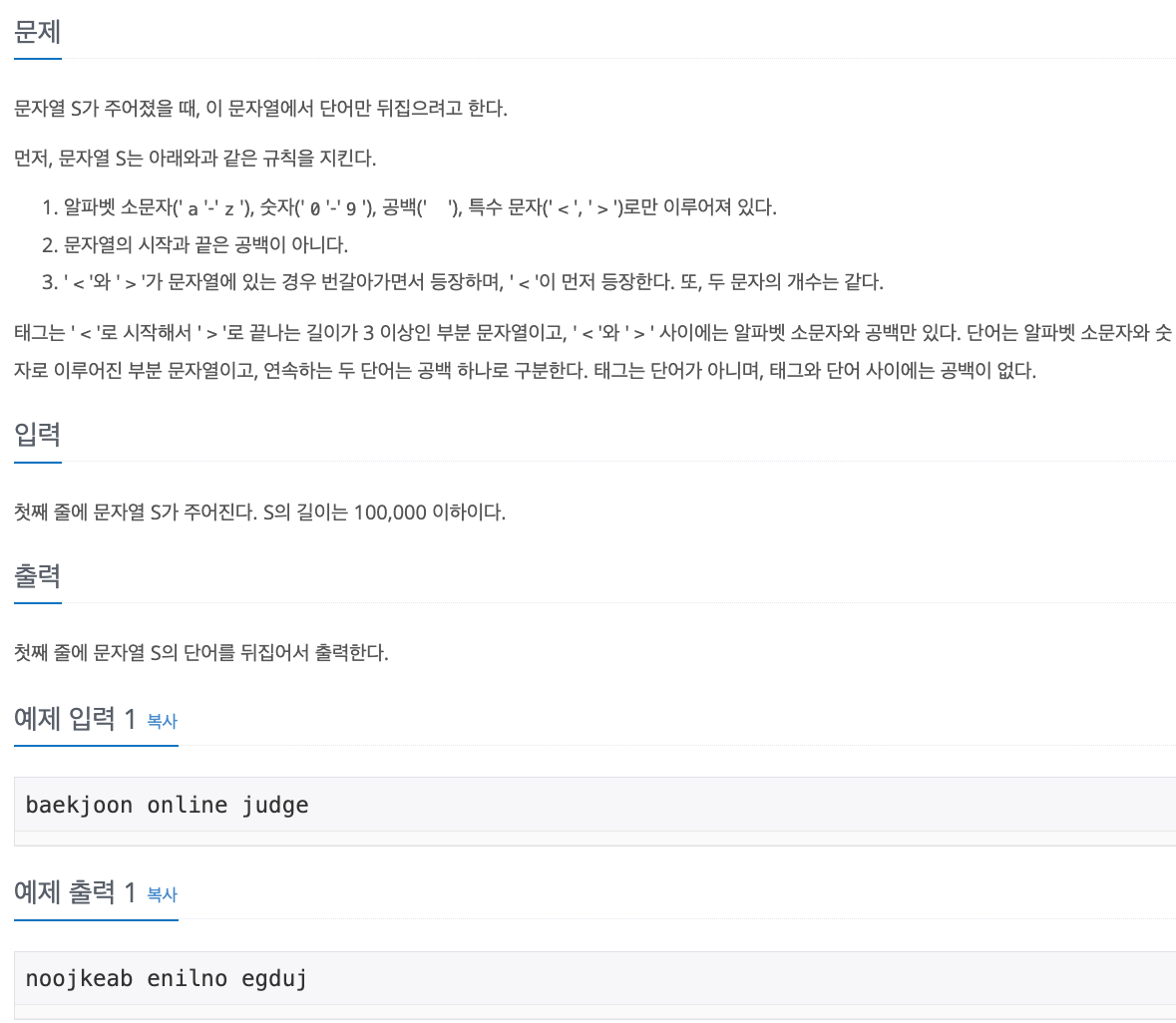
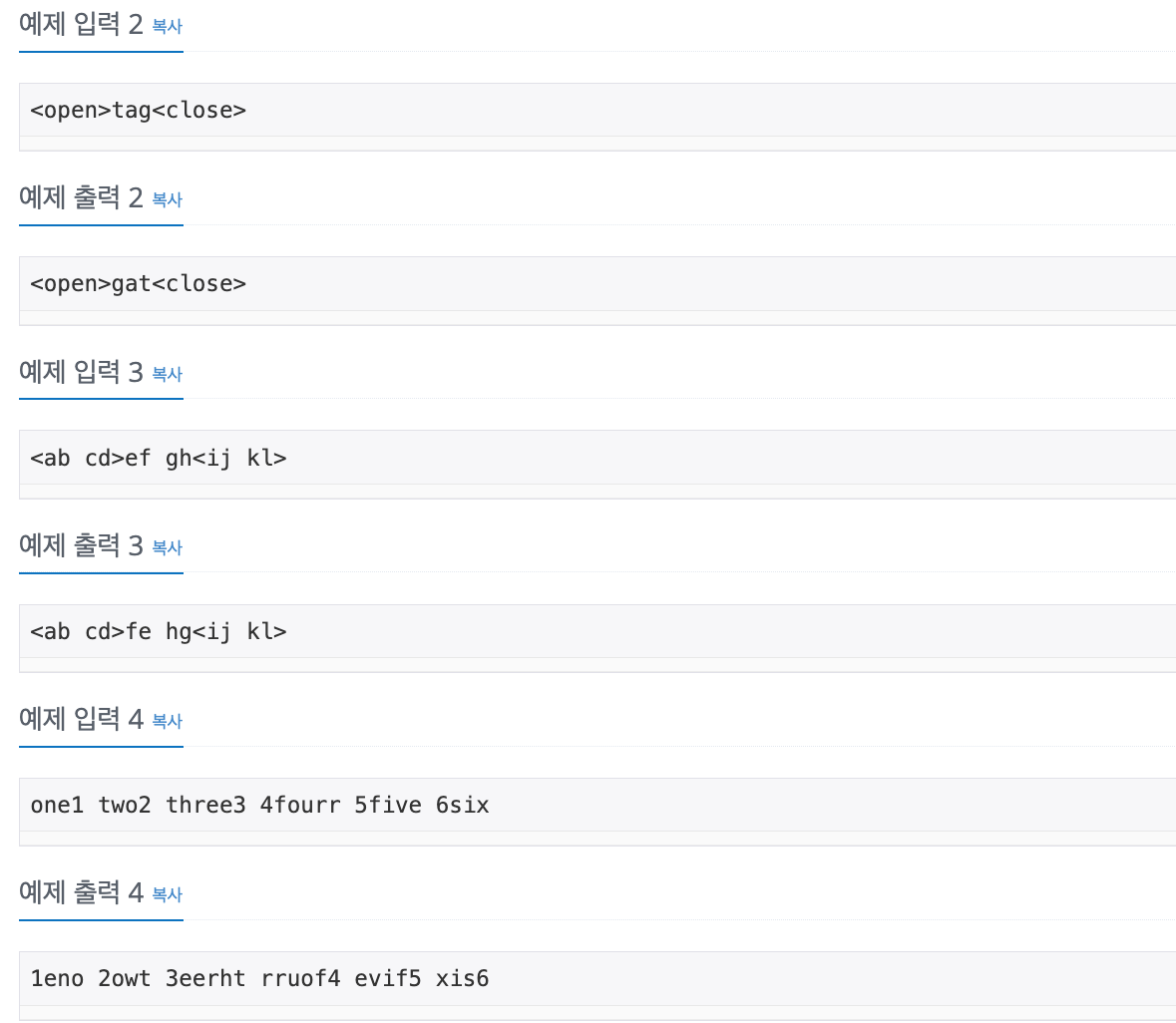
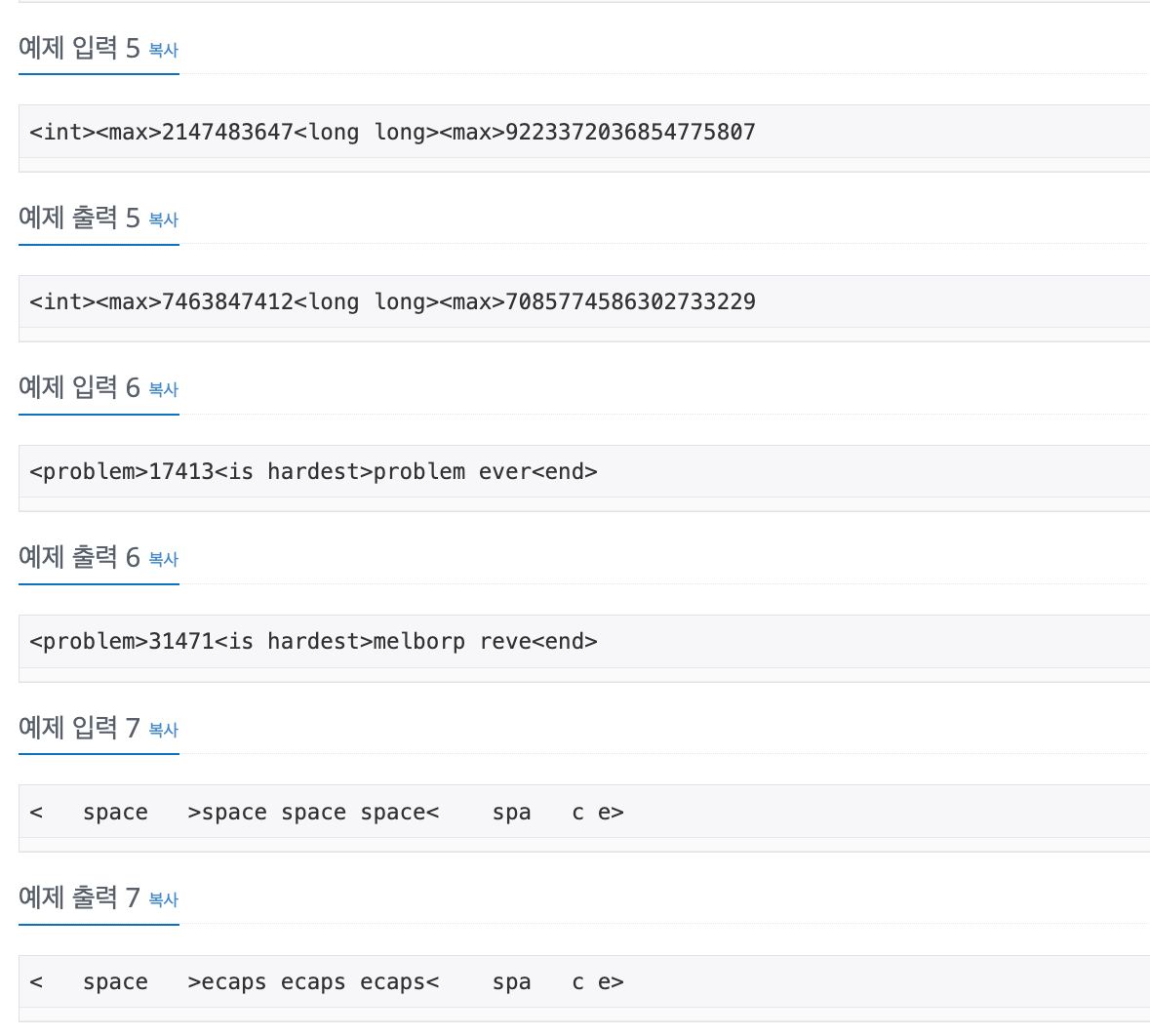
No. 17413
1. Problem
2. My Solution
- 태그인 구간과 일반 단어인 구간을 구별하기 위해 tag flag 사용
import sys
s = sys.stdin.readline().strip()
word =''
tag = False
for i in s:
if i == '<':
tag = True # 해당 부분부터 태그로 인식
print(word[::-1],end="") # 전에 단어가 존재했으면 역순으로 출력
word ='' # word 초기화
word += i
elif i == '>':
tag = False # 해당 부분부터 태그 해제
word += i
print(word,end="") # 태그 출력
word = '' # word 초기화
elif i == ' ' and tag == False: # 태그가 아닌 구간에서 ' ' 공백이면 단어의 끝을 의미
print(word[::-1]+" ",end ="") # 단어 역순으로 출력
word ='' # word 초기화
else:
word += i
print(word[::-1]) # 태그가 아닌 word 가 남았다면 역순으로 출력
3. Learned
- while 문을 이용하여 '>' 문자를 만날 때까지 수행해도 될 것 같다
- flag 기능을 잘 사용하자
No. 10799
1. Problem

2. Others' Solutions
- '(' 이면 스택에 push
- ')' 인데 앞에가 '(' 라면 '()' 이므로 레이저 (스택의 요소 개수(=막대개수) 만큼 +)
- ')' 인데 앞에가 ')' 라면 막대의 끝 (+1)
- 또는 앞에가 raser 였는지 아니였는지 판단하는 raser flag 사용
import sys
p = sys.stdin.readline().strip()
stack = []
raser = False
count = 0
for i in p:
if i == '(':
stack.append(i)
raser = False
elif raser == False:
stack.pop()
count += len(stack)
raser = True
else:
stack.pop()
count += 1
print(count)
3. Learned
- 문제 이해 -> 문제 해결에 필요한 핵심 원리 파악 및 정의 -> 알고리즘 구현
- 참고 유튜브
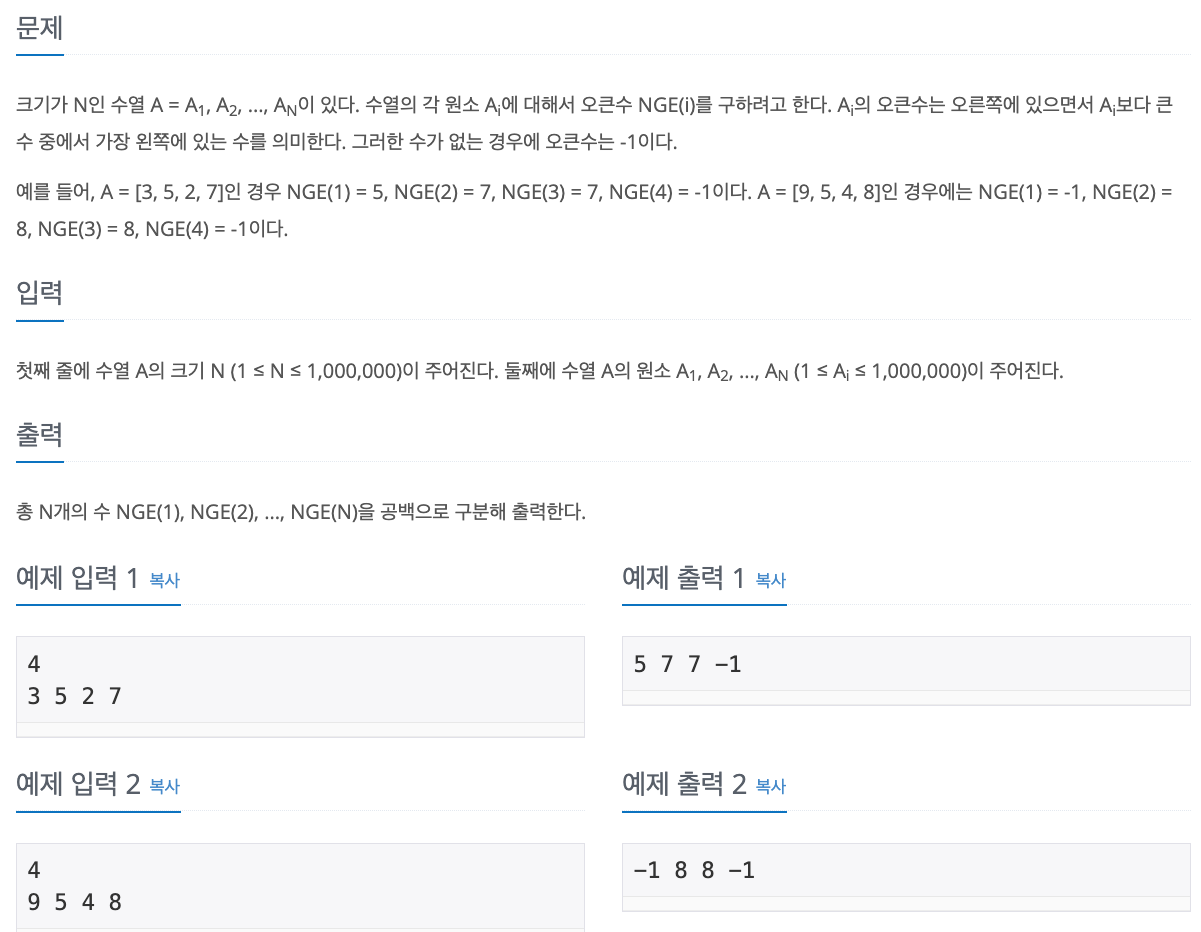
No. 17298
1. Problem
2. My Solution
- 수열을 역순으로 하고 pop 하여 나머지 원소들과 모두 비교 -> 시간초과
- 입력 n이 1,000,000 까지 이므로 최악의 경우 비교 연산이 1+2+3+...+999,999+1,000,000번 수행되어 시간복잡도 O(n^2)
import sys
n = int(sys.stdin.readline().strip())
sequence = list(reversed(list(map(int,sys.stdin.readline().strip().split()))))
result = []
while(len(sequence) > 1):
found = False
i = sequence.pop()
for j in range(len(sequence)-1,-1,-1):
if i < sequence[j]:
found = True
result.append(sequence[j])
break
if found == False:
result.append(-1)
print(' '.join(map(str,result)), -1)
3. Others' Solutions
- 첫 번째 방법
- notFound 스택의 top 부분부터 i 번째 수열 요소와 비교하여 top 부분이 더 클 때까지 pop 수행
- 마지막에 notFound 스택에 남아있는 인덱스에 -1 을 삽입
import sys
test_n = int(sys.stdin.readline().strip())
sequence = list(map(int,sys.stdin.readline().strip().split()))
notFound = []
notFoundIndex = []
result = [0 for i in range(test_n)]
for i in range(len(sequence)):
if len(notFound) > 0:
for j in range(len(notFound)-1,-1,-1):
if notFound[j] < sequence[i]:
result[notFoundIndex[j]] = sequence[i]
notFound.pop()
notFoundIndex.pop()
else:
break
notFound.append(sequence[i])
notFoundIndex.append(i)
for i in notFoundIndex:
result[i] = -1
print(' '.join(map(str,result)))- 두번째 방법
- 처음부터 result 를 -1 로 초기화
- notFound 스택에 i 번째 요소의 인덱스 값(i)을 push
- 비교할 때 sequence 스택으로 비교
import sys
n = int(sys.stdin.readline())
sequence = list(map(int,sys.stdin.readline().strip().split()))
notFound = []
result = [-1] * n
for i in range(n):
while len(notFound) > 0 and sequence[notFound[-1]] < sequence[i]:
result[notFound.pop()] = sequence[i]
notFound.append(i)
print(' '.join(map(str,result)))
4. Learned
- A and B 논리 연산자의 경우 A 부분이 False 라면 B 부분은 수행하지 않고 바로 넘어감
- B 부분에 예외 발생 가능성이 있을 경우 순서를 뒤로 넣던지 try-catch 문 수행
- 문제 해결 핵심 원리 참고 유튜브
