JPA - save() 와 saveAndFlush() 의 차이
JPA Entity 저장
- 영속성 전이 테스트 중에 saveAndFlush() 와 save() 의 차이점에 대해 궁금증이 생김
JPA 동작 원리
- save 기능을 살펴보기전에 JPA 동작 원리 (영속성 컨텍스트) 참고
save 기능
객체지향 설계 중심에서의 Entity 객체를 ORM 을 이용하여 데이터베이스에 저장하는 기능
save() 메소드

이름에서도 알 수 있듯이, save() 메소드는 엔티티를 DB에 저장하는 기능을 수행한다.
save() 메소드는 Spring Data 에서 정의한 CrudRepository 인터페이스의 메소드이다.
보통 하이버네이트는 메모리에 영속 가능한 상태를 유지한다. 이 상태를 DB 에 동기화(적용)하는 것을 "flushing" 이라고 한다.
우리가 save() 메소드를 수행할 때, 처리되는 데이터는 flush() 또는 commit() 메소드가 실행되기 전까지 DB로 flush 되지 않는다.
즉, 우리가 하이버네이트로 구현한 JPA 를 사용할 때, 특정 구현체? 객체? 가 flush() 또는 commit() 동작을 관리한다.
한 가지 알아야 할 점은, commit 을 수행하지 않고 직접 flush를 수행한다면 트랜잭션 외부에서 알 수가 없다.- save() 메소드는 바로 DB 에 저장되지 않고 영속성 컨텍스트에 저장되었다가 flush() 또는 commit() 수행 시 DB에 저장됨
saveAndFlush() 메소드

save() 메소드와는 다르게 saveAndFlush() 메소드는 실행중(트랜잭션)에 즉시 data를 flush 한다.
saveAndFlush() 메소드는 Spring Data JPA 에서 정의한 JpaRepository 인터페이스의 메소드이다.
saveAndFlush() 메소드가 주로 사용되는 상황은, 아직 commit 되지 않은 같은 트랜잭션 내에서 먼저 처리된 결과를 후에 사용할 때 사용된다.
예를 들어, 우리가 저장할 예정인 entity 의 속성을 기대하는(참조할 예정인) 스토어드 프로시저가 실행되어야 될때
save() 메소드는 db에 동기화 시키지 않았기 때문에 스토어드 프로시저는 변견 사항을 알 수가 없고, 이로인해 제대로 동작하지 않는다.- saveAndFlush() 메소드는 즉시 DB 에 변경사항을 적용하는 방식
동작 비교
1. save() 메소드 디버깅
- orderRepository.save() 수행 후
- DB 로 보내는 쿼리가 없음 -> 아직 DB에 저장되지 않음
- order 객체에 id = 4 지정됨 -> 영속성 컨텍스트에는 저장됨
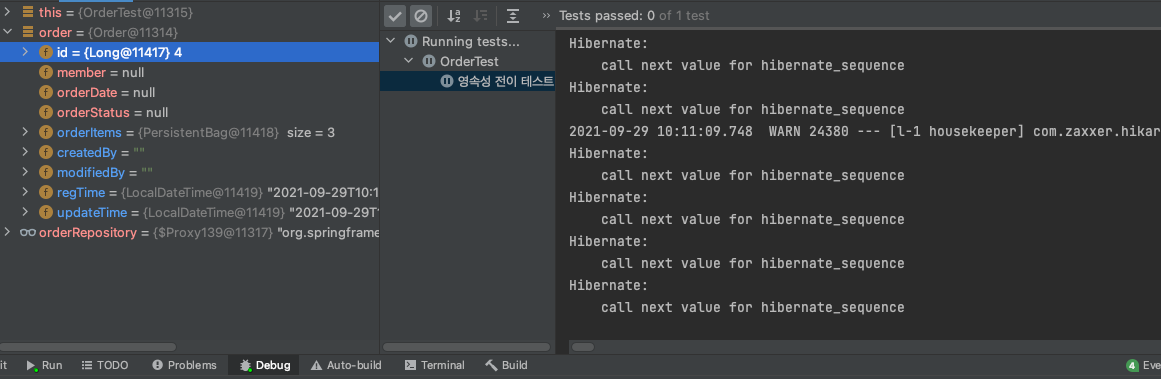
- 쿼리 조회를 DB 가 아닌 영속성 컨텍스트 내의 Cache 를 먼저 찾기 때문에 Test 통과

- 하지만 em.clear(); 코드를 수행한다면 영속성 컨텍스트가 초기화되기 때문에 영속성 컨텍스트에도 데이터가 없고, DB 에도 없으므로 EntityNotFoundException 발생
2. saveAndFlush() 메소드 디버깅
- orderRepository.saveAndFlush() 수행 후
- 실제로 insert 문이 실행되어 DB 에 저장됨

- em.clear(); 코드 수행으로 인해 영속성 컨텍스트에 데이터가 존재하지 않더라도 DB 에 존재하기 때문에 테스트 통과
결론
-
save() 메소드는 영속성 컨텍스트에 저장하는 것이고 실제로 DB 에 저장은 추후 flush 또는 commit 메소드가 실행될 때 이루어짐
-
saveAndFlush() 메소드는 즉시 DB 에 데이터를 반영함
