
Spring 기반의 애플리케이션에서 개발하다 보면, @Scheduled 어노테이션을 사용해 다양한 배치성 작업을 구현하게 된다. 단일 인스턴스 환경에서는 문제가 없지만, 애플리케이션이 클러스터 환경에서 운영될 수 있음을 간과한 채 사용한다면, @Scheduled 작업은 각 인스턴스에서 동시에 실행되는 문제가 발생하게 된다.
실무를 접하면서 이와 같은 문제를 겪었으나, 그때 당시 빠르게 문제를 해결하기 위해 DB 기반의 분산락 방식을 사용하게 되었다. 직접 구현하면서 문제를 해결하려다 보니 Heartbeat 체크, Master 인스턴스 선정 로직 등 많은 고려사항이 있었고 실무에서 버그 없이 안정적으로 운영하기에는 꽤 까다로운 구조였다. 실제로도 실무에서 직접 구현하다보니 빈틈이 많다고 생각이 들기도 했다..😥
이후 Quartz 클러스터링 기능이 있다는 것을 알게되면서, "이 기능을 활용하면 안정성있게 문제를 해결할 수 있지 않을까?" 생각이 들어 글을 작성하게 되었다.
기존 방식과 Quartz 클러스터 비교
기존 방식
실무에서 @Scheduled 중복 실행 문제를 빠르게 해결하기 위해, DB 기반의 분산 락 방식을 직접 구현한 적이 있었다. 문제를 해결하기 위한 요구사항은 간단했다.
"서버 중 한 대만 스케줄러를 실행하도록 하고, 나머지는 실행하지 않는다."
해당 요구사항을 구현하기 위해 다음과 같은 방식을 사용했다.
- DB에 Lock 테이블을 두고, 현재 Master 인스턴스의 정보를 저장
- 각 인스턴스들은 주기적으로 DB에 저장된 Master 정보를 통해 Heartbeat API를 날려 생존 유무 확인
- 기존 Master 인스턴스가 응답하지 않으면, 다른 인스턴스가 Master로 승격
당시에는 외부 시스템(Redis, Zookeeper 등)을 도입하기 어려운 상황이었기 때문에 애플리케이션 수준에서 구현하는 방식이 현실적인 대안이었다. 다만, 직접 구현하다 보니 다음과 같은 한계가 있었다.
- 예외 케이스가 많음: Master 전환 중 동시 insert, heartbeat 지연 등 다양한 문제를 수동으로 방어해야 했다.
- 디버깅 어려움: 실무에서 어떤 인스턴스가 Master 인지 빠르게 판단하거나 로그로 추적하기 어려운 경우가 많았다.
Quartz 클러스터링
이후 Quartz 클러스터링 기능을 알게 되었고, 문서를 보면서 다음과 같은 특징을 확인할 수 있었다.
- DB 테이블을 통한 분산 락 관리: Quartz 자체적으로 Job 상태, 트리거 상태 등을 관리하기 위한 테이블 스키마 제공
- 자동화된 동기화: 클러스터 모드를 활성화하면, 여러 인스턴스 중 하나만 작업을 실행
개인적으로 느낀 큰 차이는 "신뢰성"이었다. 직접 구현하는 방식은 빠르게 도입할 수 있었지만, Quartz는 이미 많은 프로젝트에서 쓰이고 있고, 검증된 방식이라 안정적이다.
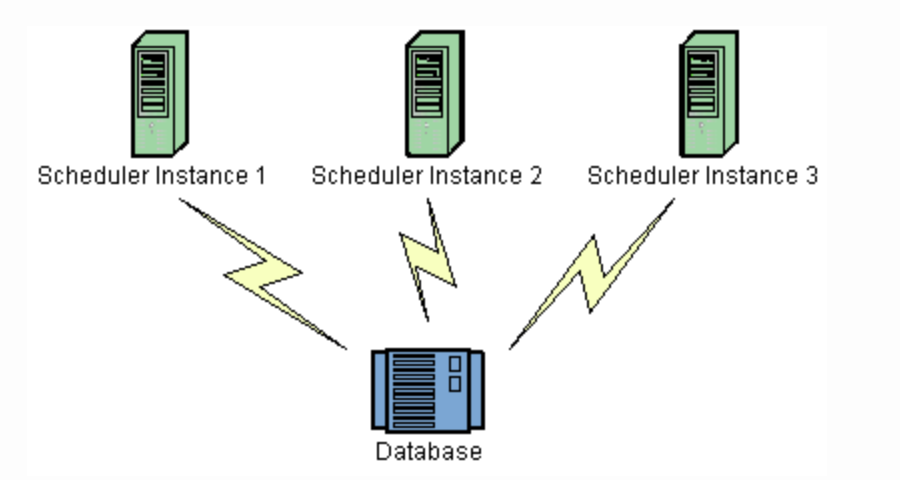
Spring Boot 기반에서 Quartz 클러스터 구축하기
실습 환경
- Java 21
- Spring Boot 3.5.0
- MacOS
properties 설정
spring:
application:
name: quartz-demo
quartz:
job-store-type: jdbc
jdbc:
initialize-schema: never
properties:
org:
quartz:
scheduler:
instanceId: AUTO
instanceName: clustered-scheduler
jobStore:
class: org.springframework.scheduling.quartz.LocalDataSourceJobStore
isClustered: true // 클러스터 모드 활성화
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_
clusterCheckinInterval: 10000
datasource:
url: jdbc:mariadb://localhost:3306/kinopio
driver-class-name: org.mariadb.jdbc.Driver
username: root
password: VMware1!
spring.quartz.job-store-type: jdbc: job, trigger 정보를 DB에 저장한다. 클러스터링 모드에서는 각 인스턴스가 같은 DB를 참조하여 Job 실행을 조율. default: memoryorg.quartz.scheduler.instanceId: AUTO: 클러스터 내 각 인스턴스를 구분하기 위한 ID를 Quartz가 자동으로 생성하도록 함org.quartz.scheduler.instanceName: Quartz 스케줄러의 이름, 같은 스케줄러 이름을 공유하는 인스턴스끼리 같은 클러스터로 인식org.quartz.jobStore.*
class: org.springframework.scheduling.quartz.LocalDataSourceJobStore: Spring Framework에서 제공하는 Quartz 확장 JobStore로 Spring의DataSource및 트랜잭션 매니저와 통합되도록 커스터마이징 됨 (다른 옵션: JobStoreCMT, JobStoreTX)clusterCheckinInterval: 10000: 인스턴스가 자신의 상태를 클러스터에 알리는 주기, 이 주기보다 오래 응답이 없으면 해당 인스턴스를 죽은 것으로 간주하고 다른 인스턴스가 Job을 takeover 함
Quartz 테이블
Quartz 스케줄러가 JDBC 기반 저장소를 사용할 때, Job/Trigger 실행 상태, 메타데이터를 저장하는 테이블이다.
클러스터링 모드에서는 인스턴스 간 동기화 및 Job 중복 실행 방지를 위해 테이블이 필수로 사용된다.
- 테이블 DDL 해당 링크에서 여러 데이터베이스의 DDL을 확인할 수 있다.
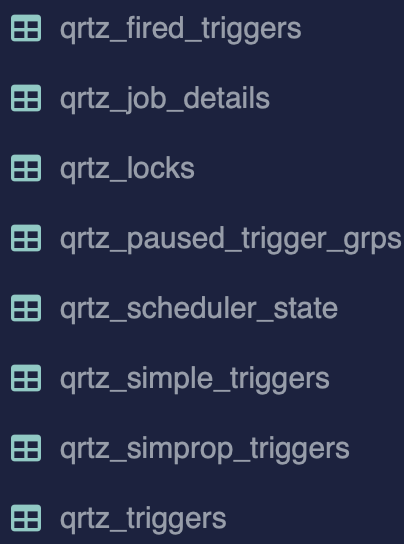
quartz.jdbc.initialize-schema: always로 설정하면 애플리케이션이 실행될 때 마다 테이블을 drop 후 다시 create 한다. (운영환경에서는 never 로 설정하기)
Quartz 테이블에 대한 정보는 테이블 정보 에서 확인 할 수 있다.
Quartz Bean 설정
@Configuration
@RequiredArgsConstructor
public class QuartzConfig {
private final QuartzProperties quartzProperties;
@Bean
public SchedulerFactoryBean schedulerFactoryBean(DataSource dataSource) {
SchedulerFactoryBean factory = new SchedulerFactoryBean();
Properties properties = new Properties();
properties.putAll(quartzProperties.getProperties());
factory.setQuartzProperties(properties);
factory.setDataSource(dataSource);
return factory;
}
}SchedulerFactoryBean: Quartz의 Scheduler를 Spring Bean으로 생성해주는 팩토리 클래스, 내부적으로 yml에서 설정한 properties와 Datasource를 연결한다.
Job 생성 및 Scheduler 실행
@Slf4j
public class SampleJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
try {
log.info("✅ SampleJob executed by instance: {}", jobExecutionContext.getFireInstanceId());
Thread.sleep(3000); // 특정 작업
log.info("✅ SampleJob ended");
} catch (Throwable e) {
throw new RuntimeException(e);
}
}
}- 실행되면 로그를 출력하는 간단한 Job
@Component
@RequiredArgsConstructor
public class SampleJobExecutor {
private final SchedulerFactoryBean schedulerFactoryBean;
@PostConstruct
void startJob() {
try {
Scheduler scheduler = schedulerFactoryBean.getScheduler();
Trigger trigger = TriggerBuilder.newTrigger()
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(10).repeatForever())
.build();
JobDetail jobDetail = newJob(SampleJob.class)
.withIdentity("sample-job", "sample-group")
.withDescription("Sample Job")
.build();
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start();
} catch (Exception e) {
throw new RuntimeException("Failed to start the scheduler", e);
}
}
}- Trigger: 10초마다 반복하는 Trigger 생성(Cron 설정도 가능하다.)
- JobDetali: Job 클래스를 실행하기 위한 메타데이터를 제공함
scheduler.scheduleJob(jobDetail, trigger);
scheduler.start();- scheduler에 Job과 Trigger를 등록하고, 시작한다.
실습
위 demo 프로젝트를 build 하고 난 뒤 생긴 jar를 포트를 다르게 설정하여 2개의 인스턴스를 실행한다.
java -jar -Dsever.port=8080 demo.jar
java -jar -Dsever.port=8081 demo.jar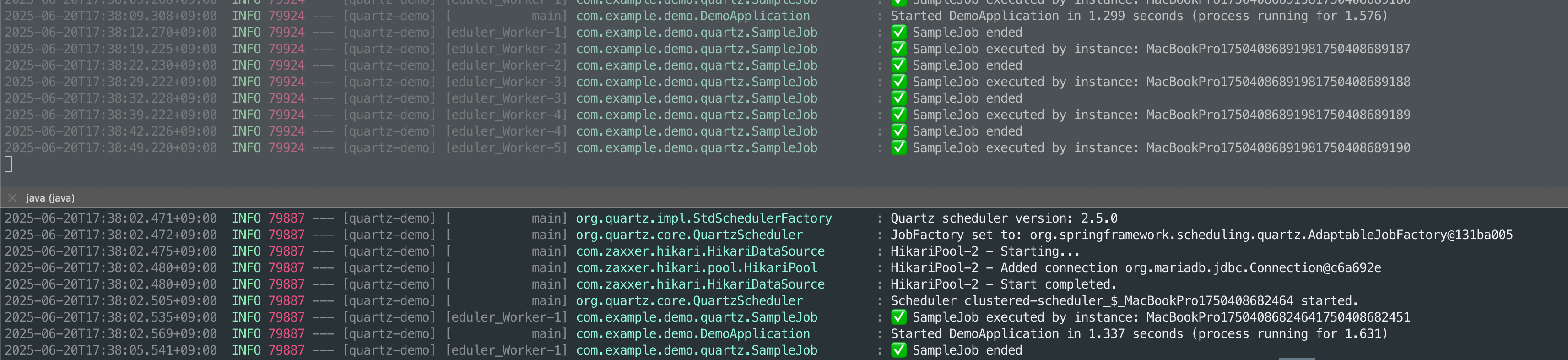
하나의 인스턴스에서만 Job이 실행되는 것을 확인할 수 있다.

인스턴스를 Shutdown 하고 나면 다른 인스턴스에서 Job이 실행된다. Job 실행 중에 중단된다면, ClusterManager에 의해 다른 인스턴스에서 다시 시작되는 모습을 확인할 수 있다.
주의사항 및 한계
- 클러스터 내에 모든 노드에 대해서 서로 1초 이내로 동기화되어야 한다.
- Quartz 내부에서 시스템 시간을 기준으로 트리거 실행 여부, misfire 판단, 락 획득 시점 등을 처리하기 때문이다.
- Quartz 클러스터링은 cluster-wide lock을 사용하는데, 이를 사용하면서 다음과 같은 문제가 발생한다.
- 노드 수가 많아질수록 락 경합으로 인해 I/O 병목 가능성이 증가한다.
- 1초 이내의 짧은 Job이 많이 실행되는 경우, 락 경합으로 인해 성능이 저하될 수 있다.
- 클러스터 간에 완벽한 부하 분산을 제공하지 않는다.
- Quartz는 로드 밸런싱을 위해 Random 알고리즘을 사용한다.
- 바쁜 스케줄러에서는 거의 무작위로 동작하지만, 트래픽이 적은 스케줄러에서는 직전에 활성화된 동일한 노드를 선호하는 경향이 있다.
- 현재 실행중인 Job에 대해서만 관리하며, Job 실행에 대한 이력(History)을 기본적으로 저장하지 않는다.
마무리
기존에는 DB 기반의 분산 락 방식으로 문제 상황을 해결했었다. 빠르게 대응할 수 있었던 건 맞지만, 직접 구현한 구조이다 보니 예외 상황에 대한 고려가 부족했고, 결국 운영 중 발생할 수 있는 다양한 케이스를 놓치는 빈틈이 많았던 것 같다.
반면 Quartz는 이미 잘 설계된 구조를 기반으로 하고 있어서, 별도 구현 없이도 설정만으로 중복 실행 문제를 해결할 수 있었고, 장애 상황에서도 자동으로 Failover가 동작하도록 설계되어 있어 실무 환경에서도 안정적으로 적용할 수 있다는 확신이 들었다.
이번 경험을 통해, 코드를 바로 구현하기보다는 문제 상황을 해결할 수 있는 적절한 기술을 고민하는 것이 중요하다는 것을 깨달았다. 이를 계기로 시스템을 더 넓은 시야에서 바라보는 태도를 갖추게 되었다.
참고
https://advenoh.tistory.com/56
Quartz cluster 공식문서
https://foojay.io/today/task-schedulers-in-java-modern-alternatives-to-quartz-scheduler/
