변수
가. 변수명 = 값
1. "="을 기준으로 왼쪽은 변수, 오른쪽은 대입할 값
나. 대입 연산자
다. 변수를 메모리에서 제거
1. "del" 이용 -> del b연산자
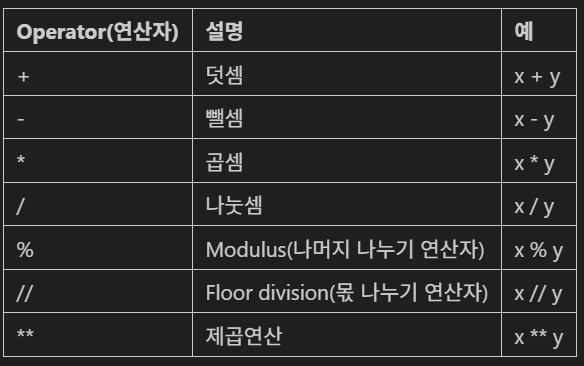
10 / 4
10 % 3 # 나머지
10 // 3 # 몫
3 ** 4 # 3^4논리형(bool)
가. True와 false를 표현하는 데이터 타입 # 제어문에서 많이 사용
1. 0글자의 문자열, 숫자 0, None, 원소가 하나도 없는 자료구조는 False로 변환되고 그 이외는 True로 변환
문자열(str)
가. 0 글자 이상의 문자열 표현
나. 문자열 표현식
1. "" or '' 표현
2. 여러줄 표현 시 """ or ''' 따옴표 3개
다. Escape 문자
1. 표현 : \문자
2. \\ 사용 시 \ 표현
- 문자열 앞에 r 접두어 사용 가능(경로 표현)
- ex) r"c:\\test\\example\\a.txt"
- ex) r"c:\test\example\a.txt"a = "안녕하세요.\n 반갑습니다.\n ~~~~"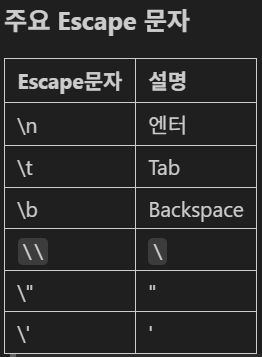
문자열 연산자
가. 문자열 + 문자열
1. 숫자를 문자열로 변환 후 합침age = 30
"나이:" + str(age)나. 문자열 * 정수
1. 문자열을 정수번 반복해서 합친다."hello" * 5
"hello"+"hello"+"hello"+"hello"+"hello다. in, not in
1. 문자열 a in 문자열 b
2. 문자열 a not in 문자열 baddress = "서울시 금천구 독산동"
print("금천구" in address)
print("종로구" not in address)
#True
#True라. len(문자열)
1. 공백도 문자 수 ex) len(" ") # 1인덱싱과 슬라이싱
가. Indexer 연산자
1. 집합형태[식별자]
-
나. indexing과 slicing
1. indexing: 집합내에서 하나의 값을 조회하는 방법
2. slicing: 집합내에서 여러개의 값들을 범위로 지정해 조회하는 방법
다. 문자 조회
1. indexing: [3] or [-10]
2. slicing: [3 : 9] # 3 ~ 8

라. Slicing
1. 기본 : 문자열[시작 : 종료 : 간격]
- 0부터 조회 할 경우 [ : 4] # 0 ~ 3까지 조회
2. 시작과 종료 음수로 해도 상관 없음
- [1 : -1] # '녕하세요. 반갑습니다.'
# -1 == 12번째 글자
3. 간격
- [ : : 3] # '안세 습.' ?????????????
- [10:1:-1] # 역순 조회
# 시작 > 종료, 간격: 음수
# 10 ~ 2
마. Format string(형식 문자열)name = "홍길동"
age = 30
tall = 170.5
template = "이름: {}, 나이: {}, 키: {}"
info = template.format(name, age, tall)
template.format("이순신", 40, 180)
info2 = f"이름: {name}, 나이: {age}, 키: {tall}" #f-str
info3 = "이름: %s, 나이: %d, 키: %f" % (name, age, tall)
# %f 실수는 최소 6자리로 맞춤 ex) 170.5000000
# %.2f 2자리까지 ex) 170.50 1. % value 사용 
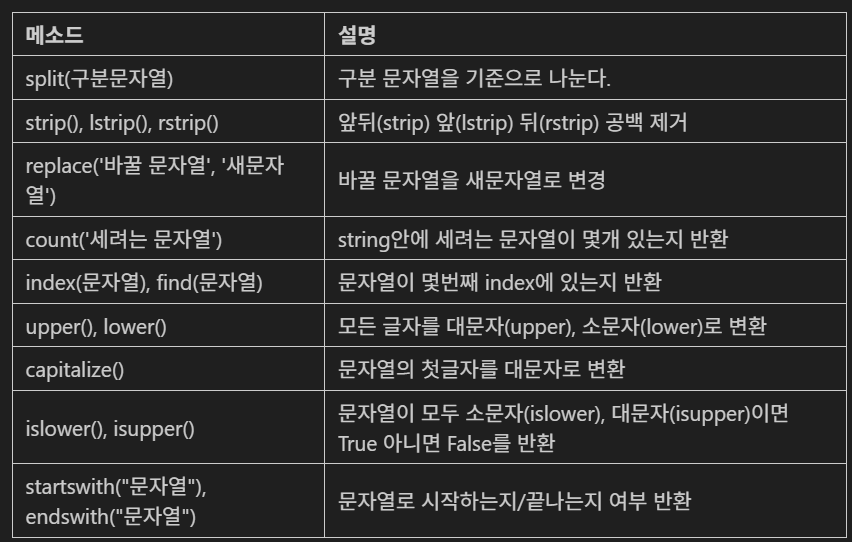
str 주요 메소드
데이터 타입 변환 함수

동적타입 언어
가. 변수를 선언할 때 그 변수에 저장할 수 있는 값의 타입을 고정시킨다.
자료구조
가. 여러 개의 값들을 모아서 관리
- list: 순서 O, 중복된 값 O, 구성 값 변경 O
- tuple: 순서 O, 중복된 값 O, 구성 값 변경 X
- dictionary: key-value
- set: 순서 X, 중복된 값 X
* len(자료구조) - 개수 반환
List(리스트)
가. 각각의 원소가 어떤 값인지 index(순번)을 가지고 식별
* 순서가 매우 중요
- 생성 구문 : [값, 값, 값]원소 조회 및 변경 - 튜플은 조회만 가능
가. Indexing
1. 하나의 원소를 조회하거나 값 변경
2. 리스트[index] : 조회
3. 리스트[index] = 값 : 변경
나. Slicing
1. 범위로 조회하거나 값 변경
List 연산자 - Tuple 동일
가. 리스트 + 리스트
나. 리스트 * 정수
다. in, not in 연산자
- 값 in/not in 리스트
라. len(리스트)중첩 리스트(Nested List)
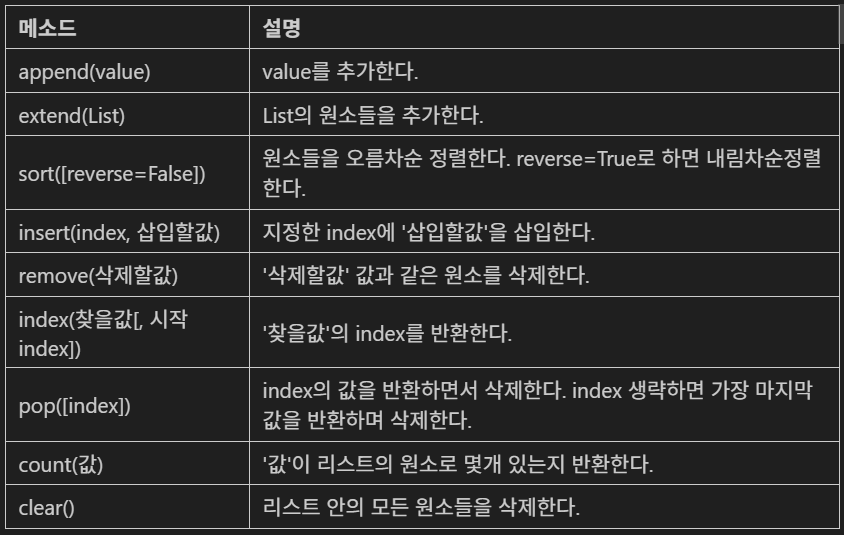
가. 리스트 안에 리스트를 가지는 것List 주요 메소드
Tuple
가. 리스트와 같지만 원소 변경 불가능
- 소괄호 생략가능 ex) t3 = 100, 200, 300, "가"
- 원소가 하나인 튜플 표현식
- (값, ) or 값,Tuple 주요 메소드
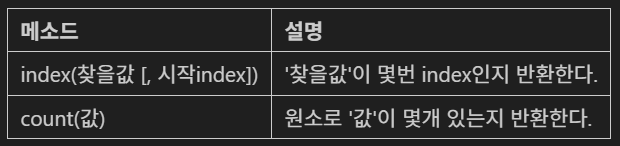
Dictionary
가. 값을 키 - 값 쌍으로 묶어서 저장
- key 중복 X, Value 중복 O
나. { 키 : 값, 키 : 값, 키 : 값 }
- dict() 함수를 사용 시 key는 변수로 정의한다.d1 = {"이름":"홍길동", "나이":20, "주소":"서울"}
d2 = dict(이름="이순신", 키=190, 나이=20)Set
가. 중복되는 값 X, 순서 신경 X
1. index와 slice를 지원하지 않는다.
나. 표현
1. {값, 값, 값}
2. info = {}
다. 연산자
1. in, not in 연산자
2. len()
3. 집합연산자
라. Set의 주요 메소드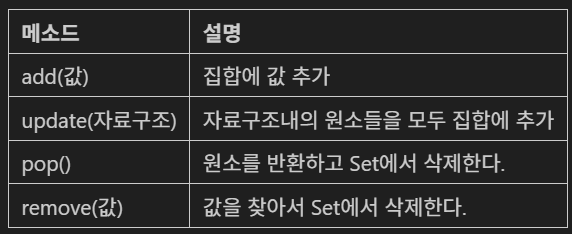
s2.add(6) #리스트 안됨, 튜플 가능
s2.update([1,1,1,7,8,8,8])
s2.pop() # 앞에서부터 삭제
s2.remove(7)마. 집합연산자 및 메소드
1. 합집합
- a | b
- a.union(b)
2. 교집합
- a & b
- a.intersection(b)
3. 차집합
- a - b
- a.difference(b)s10 = {1,2,3,4}
s20 = {3,4,5,6,7}
s10|s20자료구조를 이용한 대입
a,b,c = 10,20,30 # 튜플대입
a,b,c = {1,2,3} #셋 대입
a,b,c = ["가", "나", "다"] #리스트 대입
a,b,c = {"k1":"v1", "k2":"v2", "k3":"v3"}자료구조 변환 함수


파이팅...