SQL 개요
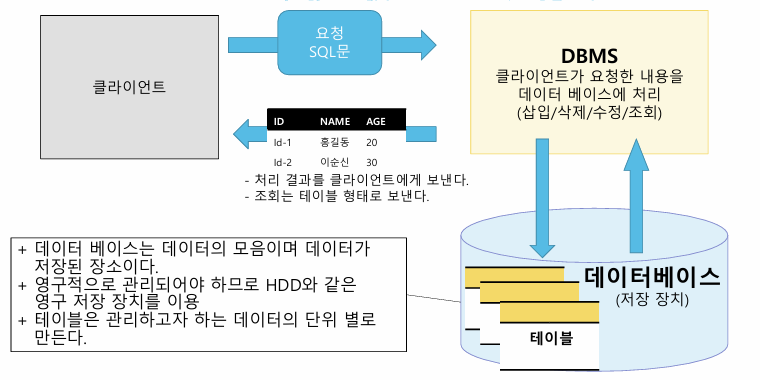
데이터베이스(DBMS)
가. 데이터베이스를 관리해 주는 시스템1. 지속적으로 유지, 관리해야하는 데이터의 집합
관계형 데이터 베이스(RDB)
가. 행과 열로 이루어진 2차원 표 형식 데이터를 관리하는 베이스
↓ 테이블 : 열 - 데이터를 구성 / 행 - 하나의 데이터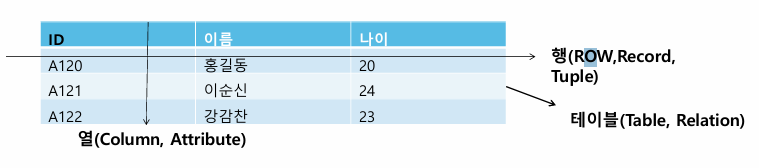
테이블(Table)
가. 데이터 베이스에서 데이터를 저장하는 단위
1. Entity - 시스템이 독립적으로 관리하길 원하는 데이터
2. Table - Entity를 물리적으로 데이터 베이스에 표현하는 방식
3. 열과 행의 2차원 표 형식으로 관리
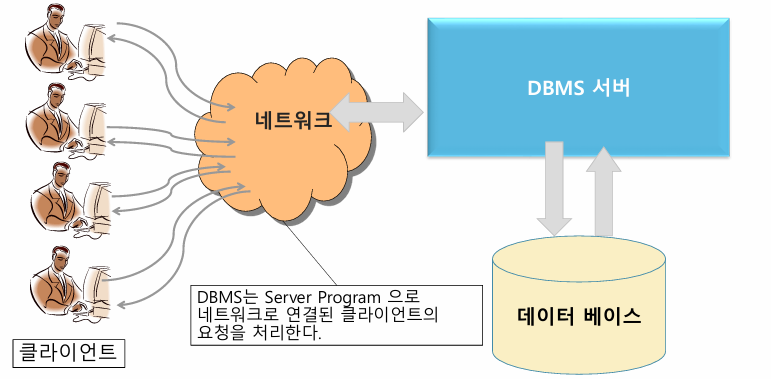
DBMS 처리흐름
SQL 기본
SQL
가. 데이터베이스에 데이터를 질의, 등록, 수정, 삭제 등을 요청하기 위한 표준 언어
1. DML(주로 사용) – INSERT, UPDATE, DELETE, SELECT
▪ 테이블 안에 값 수정할때(?)
2. DDL – CREATE, ALTER, DROP, TRUNCATE
▪ 테이블 만들 때(?)
3. DCL – GRANT, REVOKE
▪ 사용자에게권한을주거나권한을없애는것과같은Data 접근을제어하기위한언어.DDL
가. 주석 처리
1. # 한줄 주석
2. -- 한줄 주석 (--공백 으로 시작)
3. /* block 주석 */
나. 사용자 계정 생성
1. create user 'username'@'host' identified by 'password'
2. host
- localhost :로컬접속 계정
- % : 원격 접속 계정
다. 계정에 관한 부여
1. GRANT 부여할 권한 ON 데이터베이스.테이블 TO 계정@host
2. 데이터베이스와 테이블을 `*` 로 지정하면 모든 DB와 테이블에 적용된다.
3. 주요 권한 목록
- all privileges: 모든권한
- 테이블의 데이터 관리: select, insert, update, delete
- DB 객체 관리: create, drop, alter
- 사용자관리: create user, drop user, grant option

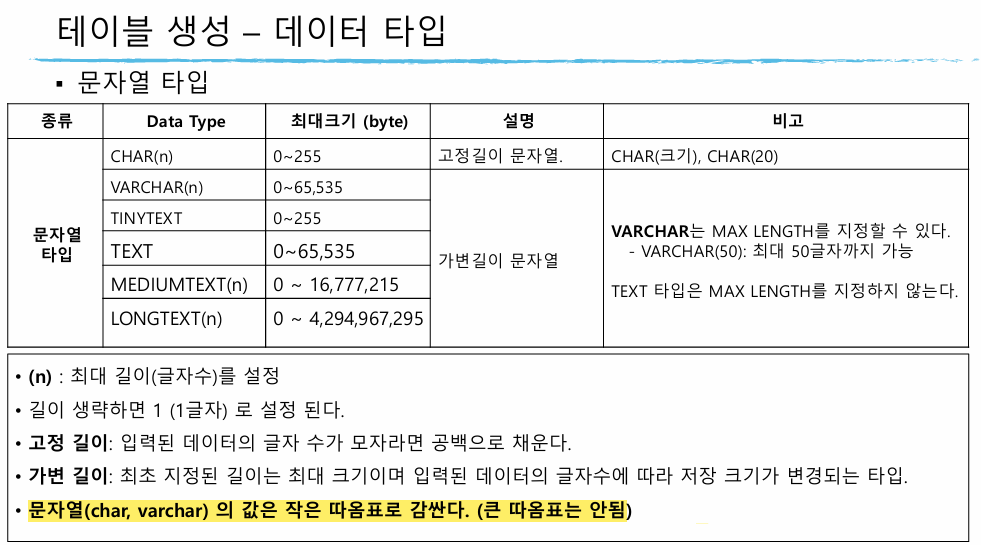
테이블 생성
create table 테이블 이름 (컬럼명 데이터타입 [제약조건]) # 컬럼명, 데이터 타입은 필수
테이블: 회원 (member)
속성
id: varchar(10) primary key
password: varchar(10) not null (필수)
name: varchar(30) not null
point: int nullable
email: varchar(100) unique key
gender: char(1) not null, check key - 'm', 'f' 만 값으로 가진다.
age: int check key - 양수만 값으로 가진다.
join_date: timestamp not null, 기본값-값 저장시 일시
----------------------------------------------------------
create table member(
id varchar(10) primary key,
password varchar(10) not null,
name varchar(30) not null,
point int,
email varchar(100) unique key,
gender char(1) not null check(gender in ('m','f')),
age int check(age > 0),
join_date timestamp not null default current_timestamp -- insert 시점의 일시를 저장
);1020
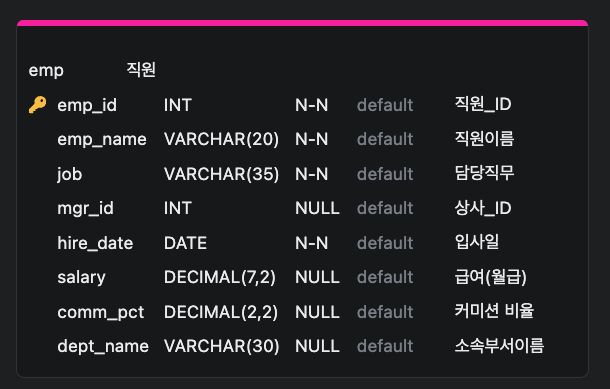
한글 - 주석(설명)
열쇠 - PRIMARY KEY 대표키
varchar(20) 20글자수까지 제한
decimal(7,2) / (2,2) * 0000.00 / .00DML
가. INSERT (데이터 삽입)
1. INSERT INTO 테이블이름 (컬럼명, 컬럼명 [,….]) VALUES (값1, 값2 [,....]
– 예) INSERT INTO DEPTARTMENT (DEPARTMENT_ID, DEPARTMENT_NAME, LOCATION) VALUES (100, ‘기획부’, ‘서울’)
나. SELECT (조회)
1. 기본구문
- SELECT 조회컬럼 [별칭][, 조회컬럼,...]
- FROM 테이블이름[별칭] * 여기까지 필수로 넣어야함
- [WHERE 제약조건]
- [GROUP BY 그룹화할 기준컬럼]
- [HAVING 조건]
- [ORDER BY 정렬기준컬럼 [ASC | DESC]]
예시)
1) EMP 테이블의 업무(job) 어떤 값들로 구성되었는지 조회. - 동일한 값은 하나씩만 조회되도록 처리.select distinct job from emp;
select distinct job, emp_name from emp; 2) EMP 테이블에서 emp_id는 직원ID, emp_name은 직원이름, hire_date는 입사일, salary는 급여, dept_name은 소속부서 별칭으로 조회결과를 출력 한다.select emp_id as 직원ID, #emp_id 컬럼의 조회결과를 직원 ID 컬럼으로~ / **"as(별칭)", as 생략가능**
upper(emp_name) as 직원이름,
hire_date as 입사일,
salary as 급여,
dept_name as 소속부서
from emp; 3) EMP 테이블의 직원의 이름(emp_name), 급여(salary)를 조회하는데 급여 앞에 '$'를 붙여서 조회한다.select emp_name, concat('$', salary, '원')
from emp;다. where
예시)
1) EMP 테이블에서 직원_ID(emp_id)가 110인 직원의 이름(emp_name)과 부서명(dept_name)을 조회select emp_name, dept_name
from emp
where emp_id = 110; 2) EMP 테이블에서 커미션비율(comm_pct)이 0.2~0.3 사이인 직원의 ID(emp_id), 이름(emp_name), 커미션비율(comm_pct)을 조회.select emp_id, emp_name, comm_pct
from emp
where comm_pct between 0.2 and 0.3;
# where comm_pct not between 0.2 and 0.3; # not 위치 3) EMP 테이블에서 업무(job)가 'IT_PROG' 거나 'ST_MAN' 인 직원의 ID(emp_id), 이름(emp_name), 업무(job)을 조회.select emp_id, emp_name, job
from emp
# where job = 'IT_PROG' or 'ST_MAN';
# where job in ('IT_PROG', 'ST_MAN'); # in
where job not in ('IT_PROG', 'ST_MAN'); # not 위치 4) EMP 테이블에서 직원 이름(emp_name)이 S로 시작하는 직원의 ID(emp_id), 이름(emp_name)을 조회.select emp_id, emp_name
from emp
where emp_name like 'S%'; # % 글자수와 문자가 뭐가 오든 상관없다, ~로 시작하는
# where emp_name like '%en'; ~로 끝나는
# where emp_name like '%are%'; ~를 포함한 5) EMP 테이블에서 직원의 이름에 '%' 가 들어가는 직원의 ID(emp_id), 직원이름(emp_name) 조회-- %나 _ 를 검색하는 값으로 사용할 경우.
select emp_id, emp_name
from emp
where emp_name like '%!%%' escape '!'; #아무 특수 문자가 와도 됨 6) EMP 테이블에서 2004년에 입사한 직원들의 ID(emp_id), 이름(emp_name), 입사일(hire_date)을 조회.
-- 참고: date/datatime에서 년도만 추출 함수: year(컬럼명)
select emp_id, emp_name, hire_date
from emp
where year(hire_date) = 2004; # year 함수
-- where hire_date between '2004-01-01' and '2004-12-31';
-- where hire_date between > '2004-05-31'; 이후 입사한 직원 조회 7) EMP 테이블에서 업무(job)에 'MAN'이 들어가는 직원들 중에서 부서(dept_name)가 'Shipping' 이고 2005년이후 입사한 직원들을 조회.select * from emp
where job like '%MAN%'
and dept_name = 'Shipping'
and hire_date >= '2005-01-01'; # year(hire_date) >= 2005;라. order by
1. order by절은 select문의 마지막 구문으로 온다.
2. 정렬방식
- ASC : 오름차순(ascending), 기본방식(생략가능)
- DESC : 내림차순(descending)
3. null은 오름차순일 때 가장 먼저 나온다.
예시)
1) 직원들의 id(emp_id), 이름(emp_name), 업무(job), 급여(salary)를 -- 업무(job) 순서대로 (A -> Z) 조회하고 업무(job)가 같은 직원들은 급여(salary)가 높은 순서대로 2차 정렬해서 조회.select emp_id, emp_name, job, salary
from emp
order by job, salary desc; #asc 생략가능 2) 급여(salary)가 $5,000을 넘는 직원의 ID(emp_id), 이름(emp_name), 급여(salary)를 급여가 높은 순서부터 조회select emp_id, emp_name, salary
from emp
where salary > 5000
order by salary desc;function
가. 단일행 함수
1. 행별로 처리하는 함수. 문자/숫자/날짜/변환 함수
2. 단일행은 select, where절에 사용가능
1) 함수
가) EMP 테이블에서 이름(emp_name)이 10글자 이상인 직원들의 이름(emp_name)과 이름의 글자수 조회select emp_name, char_length(emp_name) "글자수"
from emp
where char_length(emp_name) >= 10;
-- format
select format(salary,1) as salary
from emp; 2) 숫자관련 함수
select round(12345.12345, 2); # 자리 2 이하에서 반올림
select round(12345.12345, -2); # 자리 -2 이하에서 반올림
select round(12345.12345); # 자리 0 이하에서 반올림(정수)
# x x x x x xxxxx
#-4 -3 -2 -1 0.12345
가) 위의 SQL문에서 인상 급여(sal_raise)와 급여(salary) 간의 차액을 추가로 조회
(직원ID(emp_id), 이름(emp_name), 15% 인상급여, 인상된 급여와 기존 급여(salary)와 차액)select emp_id,
emp_name,
salary,
ceil(salary * 1.15) "SAL_RAISE", -- 정수로 올림
ceil(salary * 1.15) - salary "차액"
from emp; 3) 날짜관련 함수
가) 날짜 타입에서 년 월 일 조회select year(now()) "년도",
month(curdate()) "월",
day(curdate()) "일";
select date(now());
select time(now()); 나) 시간 타입에서 시 분 초 조회select hour(now()) "시간",
minute(curtime()) "분",
second(curtime()) "초";
select * from emp
where year(hire_date) = 2005; 다) 특정 기간 만큼 전,후의 일시를 조회select subdate(curdate(), interval 10 month), # 10개월 전
curdate(),
adddate(curdate(), interval 10 month); # 10개월 후
select adddate(now(), interval 3 week), # 3주 후
adddate(now(), interval 3 hour); # 3시간 후 라) 날짜/시간의 차이 계산select datediff(curdate(), '2025-10-01');
select timediff(curtime(), '10:10:20'); 마) EMP 테이블에서 부서이름(dept_name)이 'IT'인 직원들의 '입사일(hire_date)로 부터 10일전', 입사일, '입사일로 부터 10일 후' 의 날짜를 조회. select subdate(hire_date, interval 10 day) "입사일 10일 전",
hire_date "입사일",
adddate(hire_date, interval 10 day) "입사일 10일 후"
from emp
where dept_name = 'IT'; 바) ID(emp_id)가 200인 직원의 이름(emp_name), 입사일(hire_date)를 조회. 입사일은 yyyy년 mm월 dd일 형식으로 출력.select emp_name, date_format(hire_date, '%Y년 %m월 %d일')
from emp
where emp_id = 200; 4) 조건처리 함수
가) EMP 테이블에서 직원의 ID(emp_id), 이름(emp_name), 업무(job), 부서(dept_name)을 조회. 부서가 없는 경우 '배치 전'을 출력.select emp_id, emp_name, job, ifnull(dept_name, '--배치 전')
from emp
where dept_name is null;5) CASE문
가) EMP테이블에서 급여와 급여의 등급을 조회하는데 급여 등급은 10000이상이면 '1등급', 10000미만이면 '2등급' 으로 나오도록 조회select salary,
case when salary >= 10000 then '1등급' else '2등급' end
from emp; 나) EMP 테이블에서 업무(job)이 'AD_PRES'거나 'FI_ACCOUNT'거나 'PU_CLERK'인 직원들의 ID(emp_id), 이름(emp_name), 업무(job)을 조회.
나-1) 업무(job)가 'AD_PRES'는 '대표', 'FI_ACCOUNT'는 '회계', 'PU_CLERK'의 경우 '구매'가 출력되도록 조회select emp_id, emp_name,
case job when 'AD_PRES' then '대표'
when 'FI_ACCOUNT' then '회계'
when 'PU_CLERK' then '구매' end "job"
from emp
where job in ('AD_PRES', 'FI_ACCOUNT', 'PU_CLERK'); 다) EMP 테이블에서 업무(job)이 'AD_PRES'거나 'FI_ACCOUNT'거나 'PU_CLERK'인 직원들의 ID(emp_id), 이름(emp_name), 업무(job)을 조회.
다-1) 업무(job)가 'AD_PRES'는 '대표', 'FI_ACCOUNT'는 '회계', 'PU_CLERK'의 경우 '구매'가 출력되도록 조회select emp_id, emp_name,
case job when 'AD_PRES' then '대표'
when 'FI_ACCOUNT' then '회계'
when 'PU_CLERK' then '구매'
else job -- 출력값에 칼럼명을 작성 -> 원래 값 출력
end "job"
from emp
where job in ('AD_PRES', 'FI_ACCOUNT', 'PU_CLERK', 'IT_PROG'); 라) EMP 테이블에서 부서이름(dept_name)과 급여 인상분을 조회.
라-1) 급여 인상분은 부서이름이 'IT' 이면 급여(salary)에 10%를 'Shipping' 이면 급여(salary)의 20%를 'Finance'이면 30%를 나머지는 0을 출력select dept_name,
salary,
case dept_name when 'IT' then salary * 0.1
when 'Shipping' then salary * 0.2
when 'Finance' then salary * 0.3
else 0 end '급여 인상분'
from emp;나. 다중행 함수
1. 여러행을 묶어서 한번에 처리하는 함수 => 집계함수, 그룹함수라고 한다.
2. 다중행은 where절에는 사용할 수 없다. (sub query 이용)
3. count(*) 를 제외한 모든 집계함수들은 null을 제외하고 집계한다.
- (avg, stddev, variance는 주의)
- avg(), variance(), stddev()은 전체 개수가 아니라 null을 제외한 값들의 평균, 분산, 표준편차값이 된다.=>avg(ifnull(컬럼, 0))
예시)
1) EMP 테이블에서 급여(salary)의 총합계, 평균, 최소값, 최대값, 표준편차, 분산, 총직원수를 조회 select sum(salary),
avg(salary),
min(salary),
max(salary),
stddev(salary),
variance(salary)
from emp;
select count(*) from emp; 2) EMP 테이블의 부서(dept_name) 의 개수를 조회select count(dept_name) from emp;
select count(distinct dept_name) from emp;
select count(distinct ifnull(dept_name, 'a')) from emp; 3) -- comm_pct 평균select avg(comm_pct), -- comm_pct가 있는 35명 기준 평균 (null을 제외하고 계산)
avg(ifnull(comm_pct, 0)) -- 전체 직원에 대한 평균 (null을 0으로 변경한 뒤 계산)
from emp;다. GROUP BY
예시)
1)업무(job)별 급여의 총합계, 평균, 최소값, 최대값, 표준편차, 분산, 직원수를 조회select job,
sum(salary),
avg(salary),
min(salary),
max(salary),
stddev(salary),
variance(salary),
count(*)
from emp
group by job; 2) 부서명(dept_name) 이 'Sales'이거나 'Purchasing' 인 직원들의 업무별 (job) 직원수를 조회. 직원수가 많은 순서대로 정렬.select job, count(*) "직원수"
from emp
where dept_name in ('Sales', 'Purchasing')
group by job; 3) 급여(salary)가 10,000 이하인 직원수와 10,000초과인 직원수 조회.select case when salary <= 10000 then '10000이하'
else '10000초과' end "급여기준",
count(*) "직원수"
from emp
group by case when salary <= 10000 then '10000이하'
else '10000초과' end; 4) 부서별(dept_name) 직원수 조회하는데 부서명(dept_name)이 null인 것은 제외하고 조회.select dept_name,
count(*) "직원수"
from emp
where dept_name is not null
group by dept_name;라. Having 절
1. group by 로 나뉜 그룹을 filtering 하기 위한 조건을 정의하는 구문.
2. group by 다음 order by 전에 온다.
예시)
1) 20명 이상이 입사한 년도와 (그 해에) 입사한 직원들의 평균 급여, 직원수를 조회.select year(hire_date),
avg(salary),
count(*)
from emp
group by year(hire_date)
having count(*) >= 20; 2) 평균급여가 $5,000 이상이고 소속직원수가 열명 이상인 부서의 이름은?select dept_name
from emp
group by dept_name
having avg(salary) >= 5000 and count(*) >= 10; 3) 커미션이 있는 직원들의 입사년도별 평균 급여를 조회. 단 평균 급여가 $9,000 이상인 년도분만 조회.select year(hire_date), avg(salary)
from emp
where comm_pct is not null
group by year(hire_date)
having avg(salary) >= 9000;
파이팅...