Colki Velog
*in Operator,
*배열 안에 key:value가 있으면 일어나는 일
*배열요소에 접근하는 방법
배열과 객체의 차이 및 접근 방식에 대해서는 의문이 많아서 포스팅을 많이 했었다. 중복되는 부분도 있지만 추가적인 요소가 있어서 읽어보면 도움이 될 것이다.
배열의 index
배열은 객체(object)이지만 접근 방식에 차이가 있다.
배열은 요소 인덱스로 정수만 허용하며, 객체 처럼 문자열이 인덱스에 올 수 없다.
콘솔에 배열과 객체를 출력해보면 다음과 같이 나타난다.
*------- Array ------*
const a=['a','b','c']
console.log(a);
// 0,1,2 ; 정수 형태의 index
["a", "b", "c"]
0: "a"
1: "b"
2: "c"
length: 3
*------- Object ------*
const person = {
name: 'hany',
age: 20,
address: 'namyangmju',
};
console.log(person);
// name, age, address ; 스트링형태의 index
{name: "hany", age: 20, address: "namyangmju"}
name: "hany"
age: 20
address: "namyangmju"즉 배열리터럴은 객체리터럴과 달리 프로퍼티명(key) 없이
각 요소의 값만이 배열내에서 존재한다고 생각하면 된다.
또한, 객체는 프로퍼티에 접근할 때 대괄호 표기법[] 와 Dot.Notation ( object.property ) 두 가지 방식으로 가능하지만,
배열은 대괄호 표기법[] 안에 인덱스를 넣어주는 방법으로만 접근할 수 있다.
배열의 메서드
Array Methods 중에서는 서로 비슷한 기능을 하는 것 처럼 보이지만, 차이는 극명하다. 그래서 두 챕터로 나눠서 말해보려고 한다.
🔹 원본 배열을 그대로 유지하는 메서드
Concat, Slice
🔸 원본 배열을 변경하는 메서드
Push, Pop, Shift, Unshift, Splice
원본 배열 유지 ( 복사본 생성 )
🔷 CONCAT
마지막 요소로 추가
원본 배열에 메서드의 인자로 전달된 배열/요소들을 추가한 새로운 배열을 리턴하고, 원본 배열은 유지한다.
- 원본 배열에 배열을 넣는 경우
[ [] ]로 삽입되는 것이 아니라 요소만 추가된다.
const first = [1, 2, 3];
const add = ['a', 'b', 'c'];
const newArr = first.concat(add)
**새로운 배열**
console.log(newArr);
// (6) [1, 2, 3, "a", "b", "c"]
0: 1
1: 2
2: 3
3: "a"
4: "b"
5: "c"
length: 6
** 원본 배열 first **
console.log(first);
// (3)[1, 2, 3]
** 추가됐던 배열 add **
console.log(add)
// (3)["a", "b", "c"]- 원본 배열에 요소를 넣는 경우
const first = [1, 2, 3];
const add = ['a', 'b', 'c'];
const newArr = first.concat(add, 'hello');
//매개변수에 여러개를 넣을 수도 있다.
**새로운 배열**
console.log(newArr);
//배열, 스트링 요소 순으로 추가된 걸 알 수 있다
//(7) [1, 2, 3, "a", "b", "c", "hello"]
0: 1
1: 2
2: 3
3: "a"
4: "b"
5: "c"
6: "hello"
length: 7
** 원본 배열 first **
console.log(first);
// (3)[1, 2, 3]
** 추가됐던 배열 add **
console.log(add);
// (3)["a", "b", "c"]
🔷 SLICE
인덱스 구간 추출
메서드의 인자로 지정된 배열의 구간을 복사한 배열로 반환하고, 원본 배열은 변경되지 않는다.
매개변수에는 index 정수값이 들어가며, end는 경우에 따라 생략할 수도 있기 때문에, 구문을 크게 두가지로 나눠 본다면 다음과 같다.
arr.slice ( begin index
)
===arr.slice(begin index, arr.length)
end index가 없다면 배열길이가 디폴트값이다.
arr.slice ( begin index, end index )
구문만 놓고 본다면 '시작~끝 인덱스까지 추출한다는 거네?' 라고 착각의 늪에 빠지기 쉬운데, 끝 인덱스 이놈이 조금 특이하다.
slice메서드의 특징들에 대해서 예제와 함께 나열해보겠다.
🔅 시작인덱스부터 끝 인덱스-1 까지만 요소를 추출해서 새로운 배열로 반환한다.
여기서 끝 인덱스(end index)는 자기 자신은 미포함시키고,
자신보다 하나 앞의 인덱스까지만 복사한다.
🔅 if ( 끝 인덱스를 설정하지 않고, 시작인덱스만 쓴다면 ) 자동으로 끝인덱스=배열의 길이로 설정된다. 끝 인덱스는 옵션이다.
=> arr.slice(begin index, arr.length)
const first = [1, 2, 3, 4, 5, 6, 7];
*----- 0인덱스에서 (3-1)인덱스까지 -----*
const secondArray = first.slice(0, 3);
console.log(secondArray);
// (3) [1, 2, 3]
*------- 3에서 (7-1)인덱스까지 --------*
const thirdArray = first.slice(3, 7);
console.log(thirdArray);
// (4) [4, 5, 6, 7]
*--- 인자에 끝 인덱스를 안 넣을 경우 ----*
const endNullArray = first.slice(2);
console.log(endNullArray);
// (5) [3, 4, 5, 6, 7]
*---------- 원본 배열 유지 -----------*
console.log(thirdArray);
// (7) [1, 2, 3, 4, 5, 6, 7]🔅 시작인덱스가 배열의 길이보다 크거나 or
끝 인덱스가 시작인덱스보다 작다면 빈배열[]을 반환한다.
const first = [1, 2, 3, 4, 5, 6, 7];
*------ 시작인덱스 >first.length ------*
const secondArray = first.slice(8, 0);
console.log(secondArray);
// []
*------- 시작인덱스 > end Index -------*
const thirdArray = first.slice(5, 2);
console.log(thirdArray);
// []🔅 시작인덱스가 음수일 경우, 배열의 끝에서의 인덱스를 세어 반환한다.
( array.indexOf에서도 똑같이 적용된다.)

const first = [1, 2, 3, 4, 5, 6, 7];
const secondArr = first.slice(-1);
console.log(secondArr);
// [7]
const thirdArr = first.slice(-4);
console.log(thirdArr);
// (4) [4, 5, 6, 7]
const fourthArr = first.slice(-4, -2);
console.log(fourthArr);
// (2) [4, 5]
const fifththArr = first.slice(-4, 6);
console.log(fifththArr);
// (3) [4, 5, 6]
헷갈린다..!원본 배열 변경 ( 복사본 생성 )
🔶 PUSH
마지막 요소로 추가
인자로 전달받은 모든 값을 배열의
마지막 요소로 추가하고 새롭게 변경된 배열의 length값을 리턴한다.
👹 push()와 concat() 마지막 요소로 추가하는 기능은 닮았지만, ()안에 배열이 들어갈 때 차이가 선명하게 드러난다.
- concat은 배열을 넣는 것이 아니라 요소를 추가하고, 원본배열은 유지되며 복사된 배열을 리턴한다.
- push는 배열을 통째로 추가하며, 변화된 길이를 리턴하고 원본배열을 직접 변경한다.
const first = [1, 2, 3];
const add = ['a', 'b', 'c'];
const pushedArray = first.push(add);
// ===first.push(['a', 'b', 'c'])
*- 업데이트 된 first.length 리턴 -*
console.log(pushedArray);
// 4
*-----배열을 통으로 넣는다 ------*
console.log(first);
// (4) [1, 2, 3, Array(3)]
0: 1
1: 2
2: 3
3: (3) ["a", "b", "c"]
length: 4
*- 추가하는 배열은 역시 변함 없다 -*
console.log(add);
//(3) ["a", "b", "c"]
*------ 요소를 넣었을 때 -------*
first.push('element','a');
console.log(first);
// (6) [1, 2, 3, Array(3), "element","a"]
push는 배열을 통으로 추가하기 때문에
배열리터럴이 요소로 들어가게 된다.
👹 원본 배열을 새롭게 변경하되, 모든 요소(들)만을 배열안에 넣으려면 apply 메서드를 이용하면 된다.
원본배열.push.apply(원본배열, 추가하는 배열);
const first = [10, 20, 30];
const add = ['x', 'y'];
const newArray = first.push.apply(first, add);
*- 리턴값은 동일하게 first.length 값 -*
console.log(newArray);
// 5
*- 요소로 추가된 걸 확인할 수 있다 -*
console.log(first);
// (5) [10, 20, 30, "x", "y"]
0: 10
1: 20
2: 30
3: "x"
4: "y"
length: 5
*- 추가하는 배열은 역시 변함 없다 -*
console.log(add);
// (2) ["x", "y"]단, 함수가 사용할 수 있는 매개변수의 개수에는 제한이 있기 때문에, 추가하는 배열의 길이가 만 단위를 넘어간다면 메소드를 사용하는 건 위험하다.
🔶 POP
마지막 요소를 제거
배열의 마지막 요소를 제거하고 요소값을 리턴하며,
원본 배열을 직접 변경한다.
만약 원본 배열이 빈배열[]이라면 undefined를 리턴한다.
const first = [1, 2, 3, 4, 5];
const afterPop = first.pop();
console.log(first);
// (4) [1, 2, 3, 4]
*-- 마지막 요소인 5를 리턴한다 --*
console.log(afterPop);
// 5
-------------------------------
first.length = 0;
console.log(first);
// []
*--- 원본배열이 빈 배열일 경우 ---*
console.log(first.pop());
// undefinedpush와 pop메서드를 함께 쓰면
가장 마지막에 넣은 요소를 가장 먼저 꺼내는
후입선출 방식의 STACK자료구조를 구현할 수 있다.
const first = ['A', 'B', 'C'];
first.push(100, 200);
console.log(first);
// (5) ["A", "B", "C", 100, 200]
first.pop();
console.log(first);
// (4) ["A", "B", "C", 100]🔶 SHIFT
첫 요소 제거
배열의 첫 요소를 제거하고 제거한 요소를 리턴하고, 원본 배열을 직접 변경한다.
만약 원본 배열이 빈배열[]이라면 undefined를 리턴한다.
🔶 UNSHIFT
첫 요소로 추가
첫요소에 추가하고 변경된 새로운 원본의 길이를 리턴하고, 원본 배열을 직접 변경한다.
👹 Shift 와 Unshift 예제<const first = ['A', 'B', 'C'];
const afterShift = first.shift();
*----- shift 첫 요소 'A'제거 및 리턴 -----*
console.log(afterShift, first);
// A ["B", "C"]
*-- unshift 첫 요소 1,2 추가 및 길이 리턴 --*
const afterUnshift = first.unshift(1, 2);
console.log(afterUnshift, first);
// 4 [1, 2, "B", "C"]❗ Shift와 Unshift는
처리속도가 굉 장 히 느리다!!
배열의 구조는 쉽게 복도식 아파트라고 생각하면 된다.
push & pop을 이용해서 뒤에서부터 인자를 넣고 빼는 것은 데이터 맨 뒤의 빈공간에서 일어나는 일이고, 앞쪽에 있는 데이터가 이동할 일이 없기 때문에 수행 속도가 빠르다.
하지만 shift/ unshift는 맨 앞에 추가할 때는 앞에서부터 데이터들이 한 칸씩 옆집 인덱스로 이동했다가, 제거하면 다시 한 칸씩 당겨서 앞집으로 이동하기 때문에 굉장히 수고스럽고 수행속도가 느리다. 데이터 전체를 움직이는 동작은 프로그래밍에 있어서 효율적이지 못하다. 특히 배열의 길이가 길다면 .......?!
그래서 가능하다면 push, pop을 사용하는 것이 좋다.
🔶 UNSHIFT, SHIFT, PUSH, POP 비교
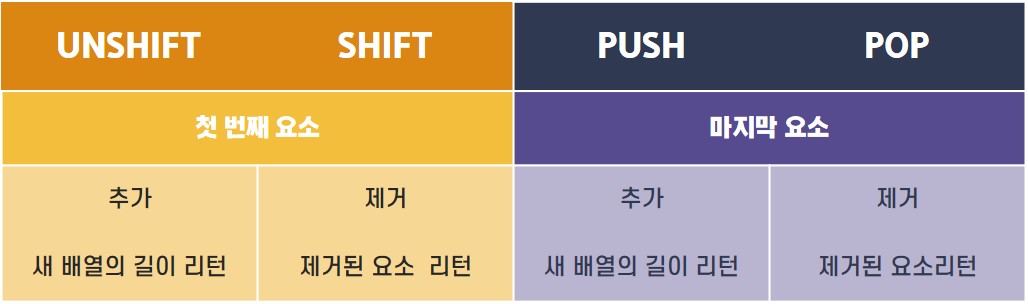
엑셀로 표를 만들어 봤는데,' 첫번째 요소 제거/추가' vs '마지막 요소 제거/추가'
에 해당하는 메서드들이 서로 미러링되는 것을 알 수 있다.
🔶 SPLICE
제거하고 요소 삽입
메서드 slice 와 이름이 비슷해서 내기준 많이 헷갈리는데 메서드이다.😥
splice의 영문 뜻은 '접착'이다. 자르고 다시 새로 붙인다는 맥락에서 가져온 단어 같다.
array.splice ( start[, deleteCount[, item1[, item2[, ...]]]] )
Splice 메서드는 시작인덱스부터 기존 요소를 제거하고, 그 위치에 새로운 요소를 추가한다.
또한 제거된 요소를 배열로 리턴하며 원본 배열은 당연히 변경된다. 위 구문을 직관적인 표현으로 바꿔 보았다.
원본배열.splice( 시작인덱스
, 제거할 요소 개수, 추가할 요소)
-
Start_시작인덱스
시작인덱스의 값만 존재한다면, 시작인덱스부터 모든 배열의 요소를 제거한다.
시작인덱스의 값이 없다면 아무런 요소도 제거되지 않는다. -
DeleteCount_제거할 요소의 수
옵션
0인 경우, 아무런 요소도 제거되지 않는다. -
item_추가할 요소
옵션
시작인덱스 앞에 요소 및 배열이 추가 된다.
요소를 지정하지 않고 array.splice ( start, deleteCount) 까지만 작성하면
추가 없이 제거까지만 실행된다.
const first = [1, 2, 3, 4];
const spliceArray = first.splice(1, 4, 'a');
*--- 제거된 요소를 배열로 리턴 ---*
console.log(spliceArray);
// (3) [2, 3, 4]
*-------- 원본 배열 변경 --------*
console.log(first);
// (2) [1, "a"]
----------------------------------
const init = ['a', 'b', 'c', 'd'];
*- 시작인덱스만 존재: 인덱스0부터 모든 요소가 삭제됨 -*
console.log(init.splice(0));
// ["a", "b", "c", "d"]
// === init.length = 0;
console.log(init);
// [] 👹 추가되는 item 요소는 2개 이상이 올 수 있다
const init = ['a', 'b', 'c', 'd'];
*- 인덱스 1부터 2개의 요소제거,인덱스 1앞에 10,100,1000 요소 추가 -*
const afterSplice = init.splice(1, 2, 10, 100, 1000);
*--- 제거된 요소를 배열로 리턴 ---*
console.log(afterSplice);
// ["b", "c"]
*--- 제거 후 추가되어 업데이트 된 원본 배열 ---*
console.log(init);
// ["a", 10, 100, 1000, "d"]👹 요소 뿐만 아니라 배열리터럴도 통째로 넣을 수 있다.
const init = [1, 2, 3, 4];
*- 인덱스2부터 0개 제거, 인덱스 2 앞에['X', 'Y', 'Z'] 추가 -*
const afterSplice = init.splice(2, 0, ['X', 'Y', 'Z']);
*------ 제거된 요소를 배열로 리턴 -------*
console.log(afterSplice);
// []
*- 제거 후 추가되어 업데이트 된 원본 배열 -*
console.log(init);
// [1, 2, Array(3), 3, 4]
👹 배열에서 추출한걸 다시 배열에 넣을 때는 []
const arr = [1, 2, 3, 4, 'a', 5, 6];
arr.splice(2, 0, arr.splice(4, 1)[0]);
console.log(arr);
// [1, 2, 'a', 3, 4, 5, 6]
// 복잡쓰
