CS224n - lecture 01 (wordvecs1)
Objective
Word2vec의 소개와 간단한 내용들을 다룬다.
Body
컴퓨터에서 어떻게 단어의 뜻을 표현할건가? 의 고민이 이뤄졌다.
이는 일반적으로는 WordNet 등의 유의어 사전 을 이용했었다.

위 이미지 처럼 WordNet은 특정 단어의 유의어(synonym), 상위어 (hypernym) 등의 배열을 hard-coding 해놓은 유의어 사전이다. (위 예시는 "Good" 에 대한 예시)
WordNet 같은 이러한 유의어 사전을 사용하는데는 당연히 여러 문제가 있다.
- 단어에 대한 좋은 자료(resource)는 있지만 단어의 뉘앙스(nuance) (문맥) 을 파악할수는 없다. (ex. "proficient" 와 "good" 이 유의어 이기는 하지만 특정 문맥에서만 대체 가능하다)
- 신조어 대응이 어렵다. (ex. wicked, badass 등... )
- 사람 노동력이 너무 많이 들어간다.
- 단어의 유사성을 계산하기 어렵다
이러한 단점을 개선하기 위해 단어를 discrete symbol(localist representation)로 표현하기 시작했다 (traditional NLP)
이러한 표현법이 잘 알려진 one-hot vector 표현법

당연하게도 이런 방식은 다루려는 단어의 개수가 많아질수록 vector dimension이 똑같이 늘어난다는 단점이 있다.
하지만 이런 문제점보다 더 큰 문제점이 있는데,

"Seattle motel" 이라는 단어와 "Seattle hotel" 이라는 단어가 one-hot vector로 표현되기 때문에 두 vector가 orthogonal (수직) 하다는 것이다! => 단어의 유사도가 표현될 수 없다.
이를 위한 해결법으로 vector의 유사성을 학습 하게 된다.
그럼 단어 vector의 유사성을 어떻게 학습할거냐?
Distribution semantics 라는 아이디어를 알아야하는데
이는 단어의 의미가 단어 자체로 정의되는것이 아니라 앞 뒤의 다른 단어 (문맥) 로 인해 단어의 의미를 정의한다는 것이다.

위의 보라색 부분 단어들이 "banking" 이라는 단어의 뜻을 정의하게 된다는 것!
그래서 특정 단어의 vector 표현을 만들때 같은 문맥에서 등장하는 단어들을 비슷한 vector로 표현하게 된다!
(단어의 vector : 단어의 의미, 뜻 을 표현하는 것 + 단어의 의미 : 해당 단어가 등장하는 문맥 => 비슷한 문맥에서 등장하는 단어는 비슷한 vector를 가져야 한다!)
Word vector = word embedding = word representation
위 세 표현 모두 같은 표현이며 단어를 distributed representation 으로 표현한것.
반대로 one-hot encoding은 localist representation
위 내용들이 기본적인 word meaning representation 에 대한 내용들이다.
Word2Vec
word vector 학습 프레임워크의 한 종류
Idea
- 많은 말뭉치가 있을때
- 단어 사전의 각 단어들이 vector 로 표현됨.
- 각 문장의 t 위치에서, 중심단어를 , 주변단어 (문맥)를 로 표현
- 단어 벡터의 유사도를 사용해서 (중심단어가 주어졌을때 주변단어 o 가 나올 확률) 을 계산, 반대 도 계산
: n-gram , : CBOW - 각 단어 벡터를 계속 조정해 나가면서 위 확률을 최대화 시킴
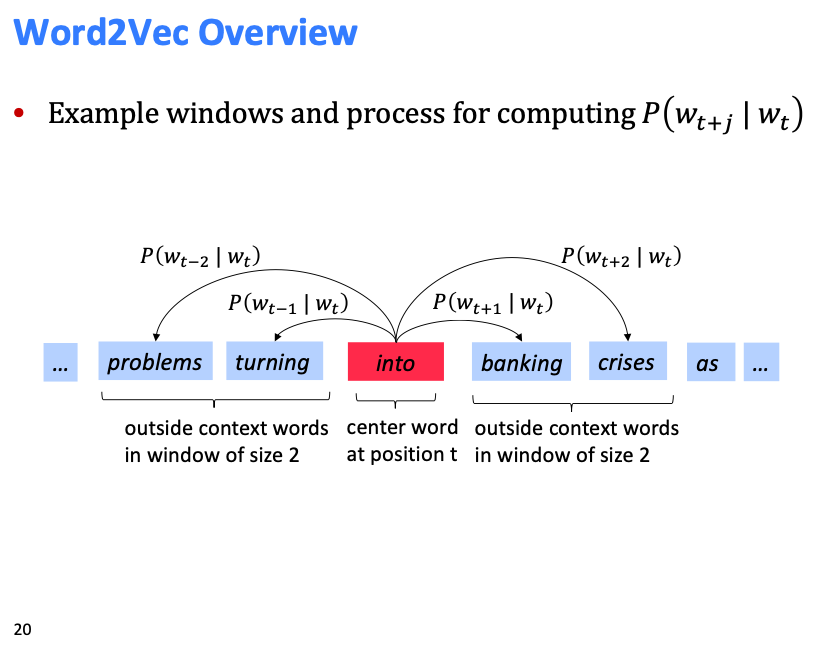
중심단어 가 주어졌을때 주변단어 를 예측.
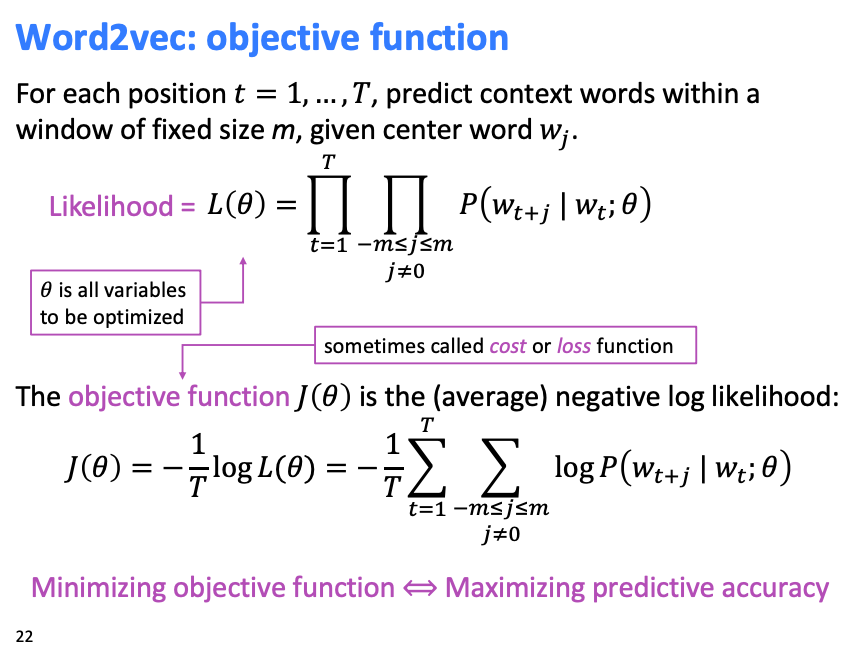
위 내용들을 조합해 objective function을 정의.
윈도우 (중심 단어 앞 뒤로 m개의 단어를 context로 사용), 길이 문장을 가정했을때, Likelihood는 위와 같다.
각 확률을 모두 곱한것. 간단!
일반적인 최적화 알고리즘은 "최소화" 문제를 다루므로, 위 likelihood를 최대화 하기 위해 objective function은 likelihood에 (-)를 곱해준다. (T 로 나누는거는 weighting 인듯? 평균.. log를 취하는건 작은 값의 scaling을 위해)
자 그래서 어떻게 확률을 구할거냐? ?
우선, 각 단어에 대해 두 vector를 정의한다.
- : 단어 c에 대한 중심단어 vector (단어 c가 중심단어일때 사용할 벡터)
- : 단어 c에 대한 문맥 vector (단어 c가 문맥 단어일때 사용할 벡터)
로 정의.
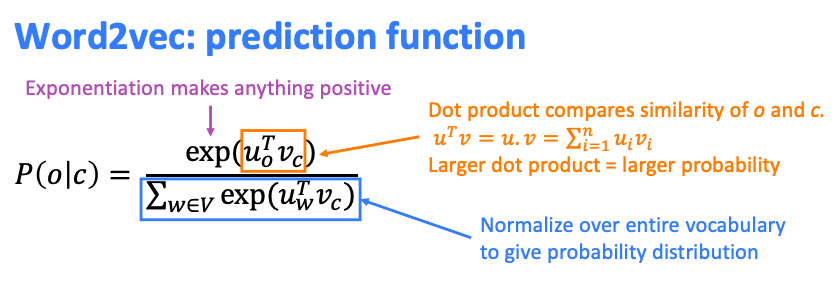
각 항을 자세히 뜯어보면,
-
: 와 의 유사도 (내적이니까 비슷한 방향에 위치하면 값이 커진다)
즉, 중심단어 c와 주변단어 o가 얼마나 유사한지 -
: normalization term.
위 유사도 계산은 자체의 크기가 커버리면 방향이 달라도 값이 커져버림. 그래서 normalization이 필요한데, 다른 단어들 에 비해 가 얼마나 와 유사한지 상대적으로 유사도를 계산하기 위해 다른 모든 단어들 와 현재 단어 의 유사도를 계산한 값으로 나눠버림. (상대적 유사도 계산)
다른식으로 생각할 수도 있음, 확률론적으로 생각하면
, (law of total probability)
위 가정이 성립하나...?
이는 softmax function으로 생각 가능.

본 수업에서는 위 objective function의 gradient vector 유도과정도 다루지만 나는 pytorch를 쓸거니 굳이 필요 없을듯...
끝.
Reference
- CS224n Youtube Lecture ( https://www.youtube.com/watch?v=kEMJRjEdNzM&list=PLoROMvodv4rOhcuXMZkNm7j3fVwBBY42z&index=2 )
- CS224n Homepage ( https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/ )
