
실습 코드: https://github.com/DAN-MU-ZI/study/tree/main/03_system/01_url_shortener
도입 및 목표 스펙
『가상 면접 사례로 배우는 대규모 시스템 설계 기초』에 등장하는 URL 단축 서비스를 직접 구현해 보았다. 하루 1억 건의 URL을 단축하는 시스템에서는 단순한 기능 구현보다 부하를 견디는 아키텍처 설계와 병목 추적이 훨씬 중요했다.
이 글은 URL 단축기를 직접 구축하고, 성능의 발목을 잡는 병목 지점들을 하나씩 제거해 최종적으로 목표 처리량(RPS)에 도달하기까지의 과정을 정리한 기록이다.
목표 스펙은 다음과 같이 잡았다.
- 쓰기 연산: 매일 1억 개의 단축 URL 생성
- 초당 쓰기 연산: 1억 / 24시간 / 3600초 ≒ 1,160 RPS
- 읽기 연산: 쓰기 대비 10배 비중으로 가정 = 11,600 RPS
- 목표 RPS: 약 11,000
- (DB 총 용량 계산은 이번 실습 범위에서 제외)
시스템 아키텍처
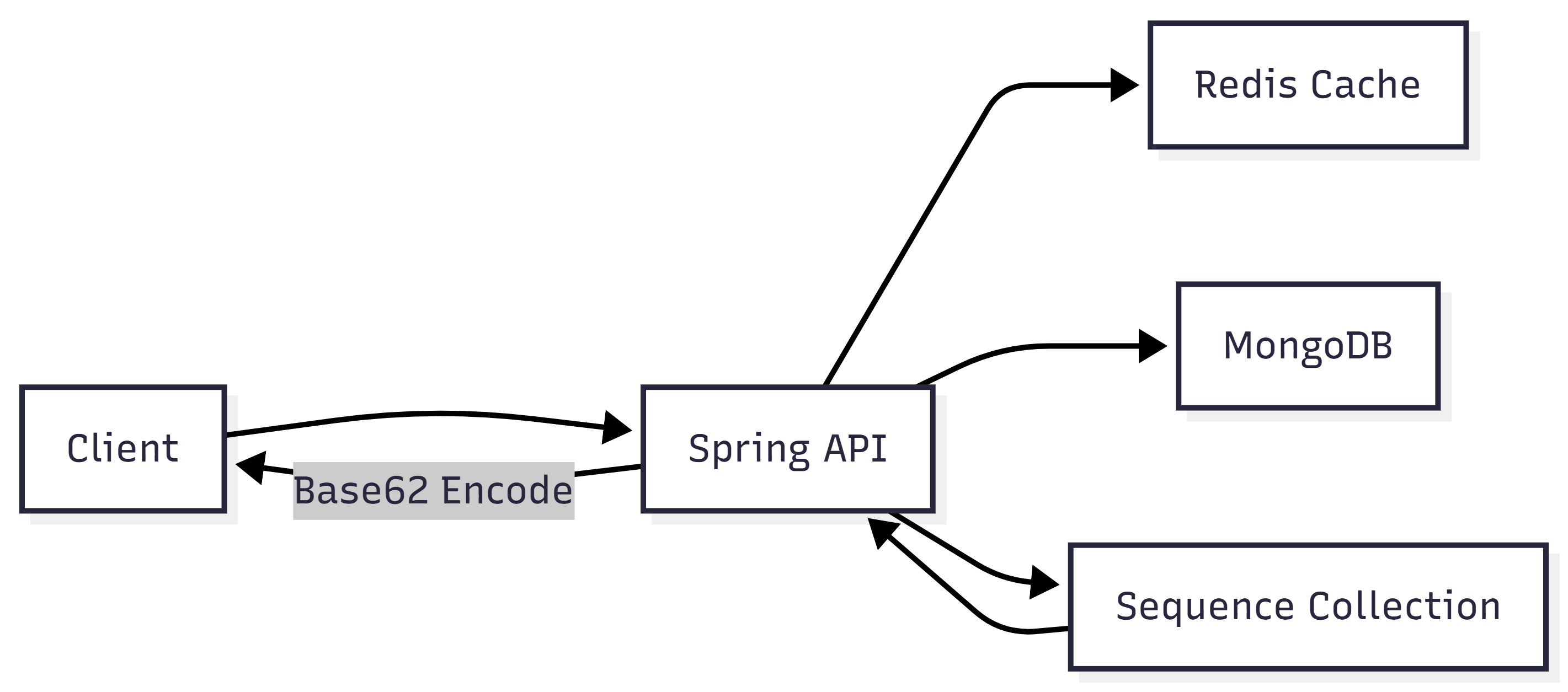
시스템의 뼈대는 Spring Boot + Redis + MongoDB로 구성했다. 압도적으로 많은 읽기 요청은 Redis를 통해 최대한 흡수하고, URL 데이터의 영구 저장 및 정합성 유지는 MongoDB에 위임하는 구조다.
기본 기능 흐름
API는 아래 두 개로 단순화했다.
1. POST /api/v1/data/shorten
- 입력:
{ longUrl: longURIstring } - 출력: 단축 URL
GET /api/v1/{shortUrl}
- 출력: 원본 URL로 HTTP 리다이렉트(
301/302)
핵심 동작 흐름은 다음과 같다.
1. shorten: ID 생성 -> Base62 인코딩 -> Mongo 저장 -> Redis 캐시 반영
2. redirect: Redis 조회 -> miss 시 Mongo 조회 -> Redis 갱신 -> 리다이렉트 반환
초기 스택과 한계
초기 아키텍처는 보편적인 Spring MVC + PostgreSQL 조합으로 시작했다. 하지만 테스트를 진행할수록 쓰기/조회 경로가 길어지고, 부하가 쌓일수록 응답 지연(Latency)이 빠르게 튀는 현상이 발생했다.
URL 단축 서비스는 복잡한 조인(Join)보다는 단순한 Key-Value 형태의 조회와 저장 비중이 절대적이다. 따라서 Document 기반으로 Upsert 경로가 더 가볍고 유연한 MongoDB가 이 시스템에 훨씬 적합하다고 판단하여 전환을 결정했다.
전환 결과는 아래와 같다.
| 단계 | req/s | avg | p95 | 비고 |
|---|---|---|---|---|
| Spring MVC 초기 | 897.63 | 1.04s | 2.17s | 기준점 |
| PostgreSQL -> MongoDB | 1962.70 | 478.59ms | 1.02s | DB 경로 단순화 효과 |
핵심 문제 해결 과정 (Troubleshooting)
이슈 1. 단축키 충돌과 DB 부하 (ID 생성 전략의 진화)
초기에는 임의의 해시(Hash) 값을 기반으로 단축키를 생성했다. 하지만 이 방식은 필연적으로 '충돌 확인 -> 재시도 로직을 동반했고, 이는 쓰기 경로를 무겁게 만드는 주범이었다.
- 1차 개선 (Mongo Sequence + Base62): 충돌 검증 로직을 아예 제거하기 위해 MongoDB의 시퀀스를 활용한 고유 ID를 발급받고, 이를 Base62로 인코딩했다. 쓰기 경로는 단순해졌지만, ID 발급을 위해 DB를 2번 왕복해야 하는 2-way 경로(findAndModify -> update) 병목이 새롭게 발생했다.
- 최종 개선 (Snowflake ID): 데이터베이스에 의존하지 않고 애플리케이션 내부에서 고유 ID를 생성하는 Snowflake ID 방식을 도입하여 DB 왕복 오버헤드를 완전히 제거했다.
| 단계 | req/s | p95 | fail | 해석 |
|---|---|---|---|---|
| 재검증 시작점 | 4647.56 | 381.65ms | 0.00% | 2-way ID 병목 확인 |
| Snowflake 튜닝 반영 | 5003.31 | 361.30ms | 0.00% | ID 경로 단순화 효과 확인 |
이슈 2. 조회 성능 극대화
조회 트래픽 방어를 위해 Look-aside (Cache Aside) 패턴을 적용했다. Redis에 데이터가 있으면 즉시 반환(Hit)하고, 없으면 DB를 조회한 뒤 Redis를 갱신(Miss)한다.
단축 URL은 '생성 직후에 즉시 공유'되는 서비스 특성을 가진다. 이러한 특성 덕분에 생성 시점에 캐시를 미리 밀어 넣는 웜업(Warm-up) 혹은 빠른 캐시 갱신 전략이 적중률을 높이고 데이터베이스 부하를 극적으로 낮추는 데 큰 역할을 했다.
이슈 3. 병목 지점 파악과 리소스 튜닝
Grafana 모니터링을 통해 시스템 지표를 살펴보던 중, 애플리케이션의 메모리 Young 영역이 빠르게 포화되며 Minor GC 지연이 높은 값을 유지하는 패턴을 발견했다.
-
현상: Young 영역 포화 STW(Stop-The-World) 빈도 증가 GC 누적 처리량 하락 및 Tail Latency(P95) 악화
-
조치:
- CPU 코어 확장:
2 -> 4
RAM 증설:4GB -> 12GB (Xms, Xmx 옵션 통일)
- 결과: Minor GC 소요 시간이
200ms -> 50ms로 단축되었고, CPU 활용률이 안정화되며 처리량이 눈에 띄게 상승했다.
부하 테스트 및 최종 검증 (k6)
테스트 시나리오 소개
목표 RPS 11,000을 검증하기 위해 k6를 활용해 쓰기 1 : 읽기 10 비율로 시나리오를 구성했다.
export const options = {
scenarios: {
load_test: {
executor: "constant-arrival-rate",
duration: "30s",
preAllocatedVUs: 1000,
rate: 1000,
timeUnit: "1s",
},
},
};로컬 환경에서의 한계
처음에는 로컬 환경(Windows 10, i7-7700HQ)에서 테스트를 진행했다. 하지만 자원 튜닝을 거쳐도 일정 수준(약 6,000 RPS) 이상 올라가지 않았다. 원인은 애플리케이션의 한계가 아니라, 부하를 생성하는 k6 툴과 서버가 같은 머신 내에서 CPU를 두고 경합(Contention)하고 있었기 때문이다.
| 단계 | req/s | avg | p95 | 비고 |
|---|---|---|---|---|
| CPU 4코어 확장 | 5555.85 | 169.74ms | 350.82ms | 자원 병목 완화 |
| Sequence + Base62 최종 | 5982.34 | 155.94ms | 330.83ms | 로컬 기준 최종 |
EC2 환경 분리 후 최종 결과
정확한 측정을 위해 부하 생성기와 서비스 실행 환경을 물리적으로 분리(Ubuntu 22, EC2 t3.xlarge)한 뒤 10분간 장기 테스트를 수행했다.
| 환경 | req/s | p95 | fail | 결과 |
|---|---|---|---|---|
| 로컬 재검증 시작점 | 4647.56 | 381.65ms | 0.00% | 병목 분석 단계 |
| Snowflake 튜닝 반영 | 5003.31 | 361.30ms | 0.00% | ID 경로 개선 |
EC2(t3.xlarge) 최종 10분 | 10902.61 | 65.43ms | 0.00% | 목표 11,000 RPS 달성 |
마무리 (회고)
이번 대규모 시스템 설계와 부하 테스트를 진행하며 얻은 가장 큰 교훈은 "알고리즘 최적화만으로는 한계가 있으며, 시스템 전반에서 병목이 발생하는 계층을 정확히 짚어내야 한다"는 점이다.
-
시야의 확장: 코드 레벨을 넘어 시스템 전체로
이전까지는 기능 구현에 주로 집중했기 때문에, 성능 이슈가 발생해도 그 원인을 항상 '코드 레벨'에서만 찾으려 했다. 하지만 트래픽 규모가 커지자 해시 충돌, 2-way ID 생성으로 인한 DB 부하, 그리고 JVM 메모리(GC) 포화 등 전혀 다른 계층의 원인들이 겹치며 단계마다 성능 상한선을 만들고 있었다. -
모니터링과 데이터 기반의 문제 해결
비록 초기에는 원인을 찾기 위해 헤매는 시간도 있었지만, 이 과정은 오히려 성장할 수 있었다. Grafana를 구축해 시스템 지표를 직접 모니터링하면서, 감이 아닌 '데이터'를 기반으로 병목 지점을 추적하고 튜닝하는 일련의 노하우를 얻었다. 각 계층의 한계를 하나씩 돌파하며 11,000 RPS라는 목표를 달성해 낸 과정은 무척 뜻깊은 경험이었다. -
향후 개선 과제 (Next Step)
이제는 단일 서버에서의 성능 최적화를 넘어, 더 견고한 아키텍처에 대한 고민으로 시야를 넓혀야 한다.
Top-down 최적화: 이번 경험은 문제가 발생한 지점부터 해결해 나가는 Bottom-up 방식으로 접근해나갔다. 다음 설계에서는 3-tier 아키텍처를 순서대로 검증해나가면서, 전체 시스템 관점에서 어디에 부하가 집중되는지 먼저 식별하는 구조적이고 하향식인 접근법을 연습해보고자 한다.
SPOF(단일 장애점) 극복: 현재 아키텍처는 특정 노드에 장애가 발생하면 전체 시스템에 영향을 미칠 수 있다. 이를 Scale-out 이나 다른 방식들을 생각해볼 수 있을것 같다.
고가용성 확보: 이를 해결하기 위해 서버 다중화나 리전 분리 등 고가용성을 보장하는 아키텍처로의 확장을 고민해 볼 계획이다.
비용 효율성: 더불어 무작정 인프라를 늘리는(Scale-out) 것이 아니라, EC2의 비용 효율성을 철저히 따져가며 성능과 유지 유지비용 사이의 '최적의 타협점'을 찾는 것도 훌륭한 다음 과제가 될 것이다.
