Amazon Aurora
- 고성능 상용 데이터베이스의 성능과 가용성 + 오픈소스 데이터베이스의 간편성과 비용효율성
- 클라우드를 위해 구축된 MySQL 및 PostgreSQL 호환 관계형 데이터베이스
- 표준 MySQL데이터베이스 보다 최대 5배 빠르고 표준 PostgreSQL 데이터베이스 보다 최대 3배 빠름
- 또한 10분의 1 비용으로 상용 데이터베이스의 보안, 가용성 및 안정성을 제공
- 하드웨어 프로비저닝, 데이터베이스 설정, 패치 및 백업과 같은 시간 소모적인 관리작업을 자동화하는 Amazon Relational Database Service(RDS)에서 Amazon Aurora의 모든 것을 관리 한다.
- MySQL과 PostgreSQL 기반으로 새롭게 설계한 관계형 데이터베이스 서비스
기존 RDS의 아키텍쳐
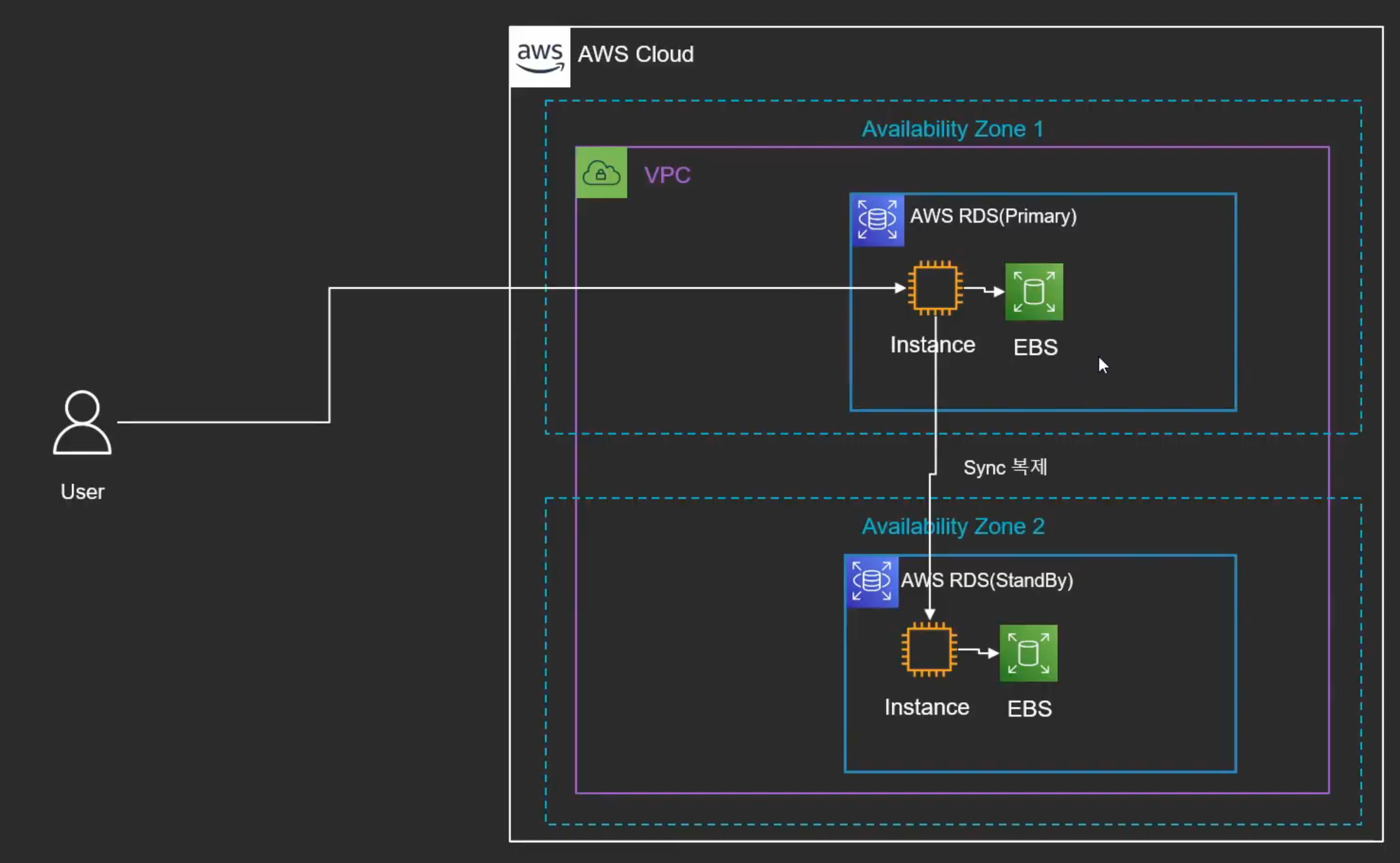
- Multi-AZ
- 두개의 가용영역 안에 각각의 RDS가 있음
- 고가용성을 유지하기 위해서 Primary에서 standBy로 복제
- 하나의 RDS는 하나의 인스턴스와 EBS로 구성
- Aurora는 이런 구조에서 나오는 문제점을 해결하기 위해 아예 아키텍쳐 단위부터 바꿔버림
Aurora의 아키텍쳐
1. Single-Master
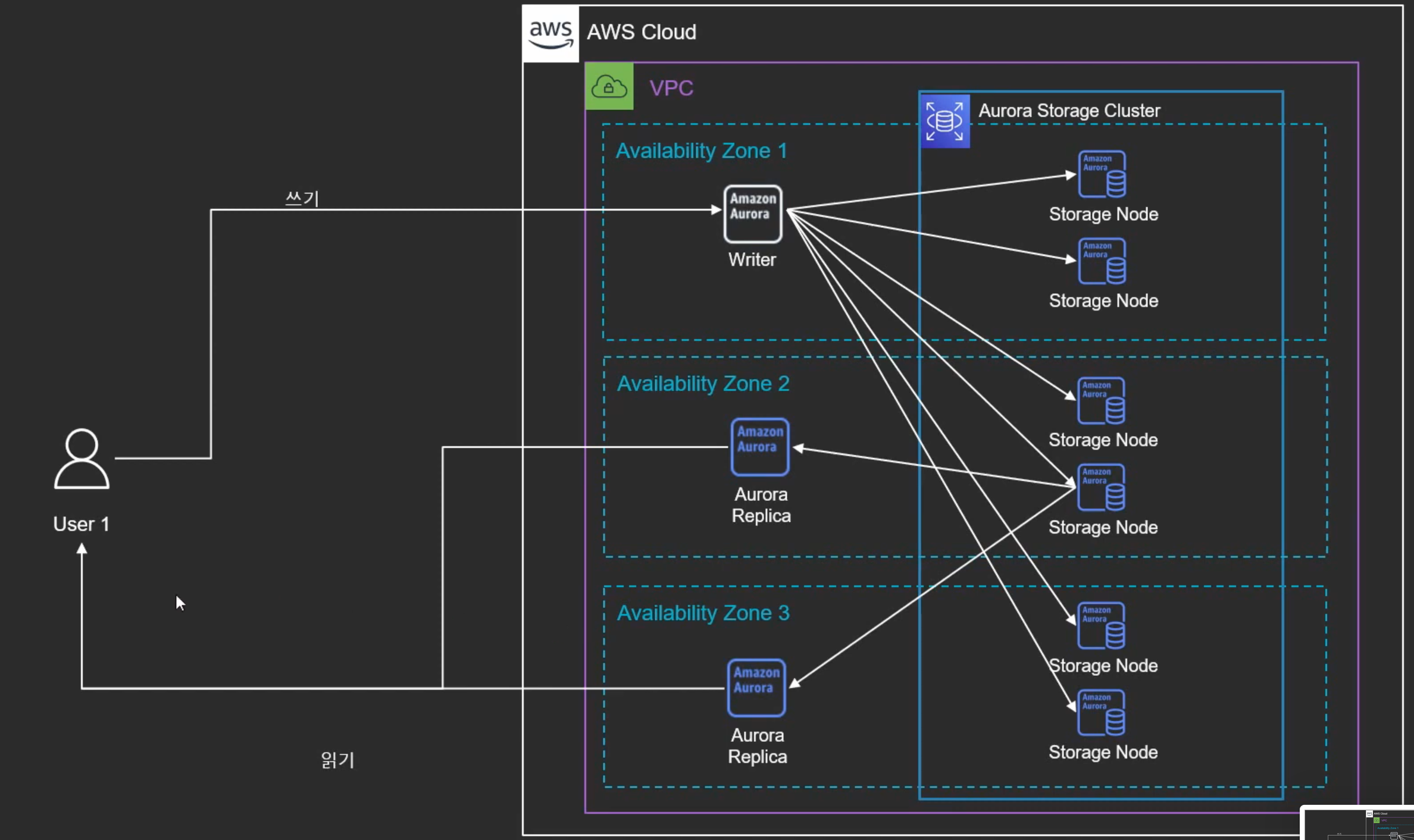
- 읽기/쓰기와 저장을 분리
- 한대의 Write 인스턴스와 다수의 읽기 전용 인스턴스(Aurora Replica)로 구성
- 쓰기전용 노드가 받아서 6개의 저장 노드에 모두 write를 함
- 읽기전용 노드들이 저장 노드와 통신을 해서 데이터를 불러와서 유저에게 전달
- 총 15개의 Replica 생성 가능
- Async 복제
- 하나의 리전 안에 생성 가능
- Writer가 죽을 경우 자동으로 Replica 중 하나가 Writer로 Failover
: 데이터 손실 없이 Failover 시 메인으로 승격 가능 - 고가용성 확보
2. Multi-Master
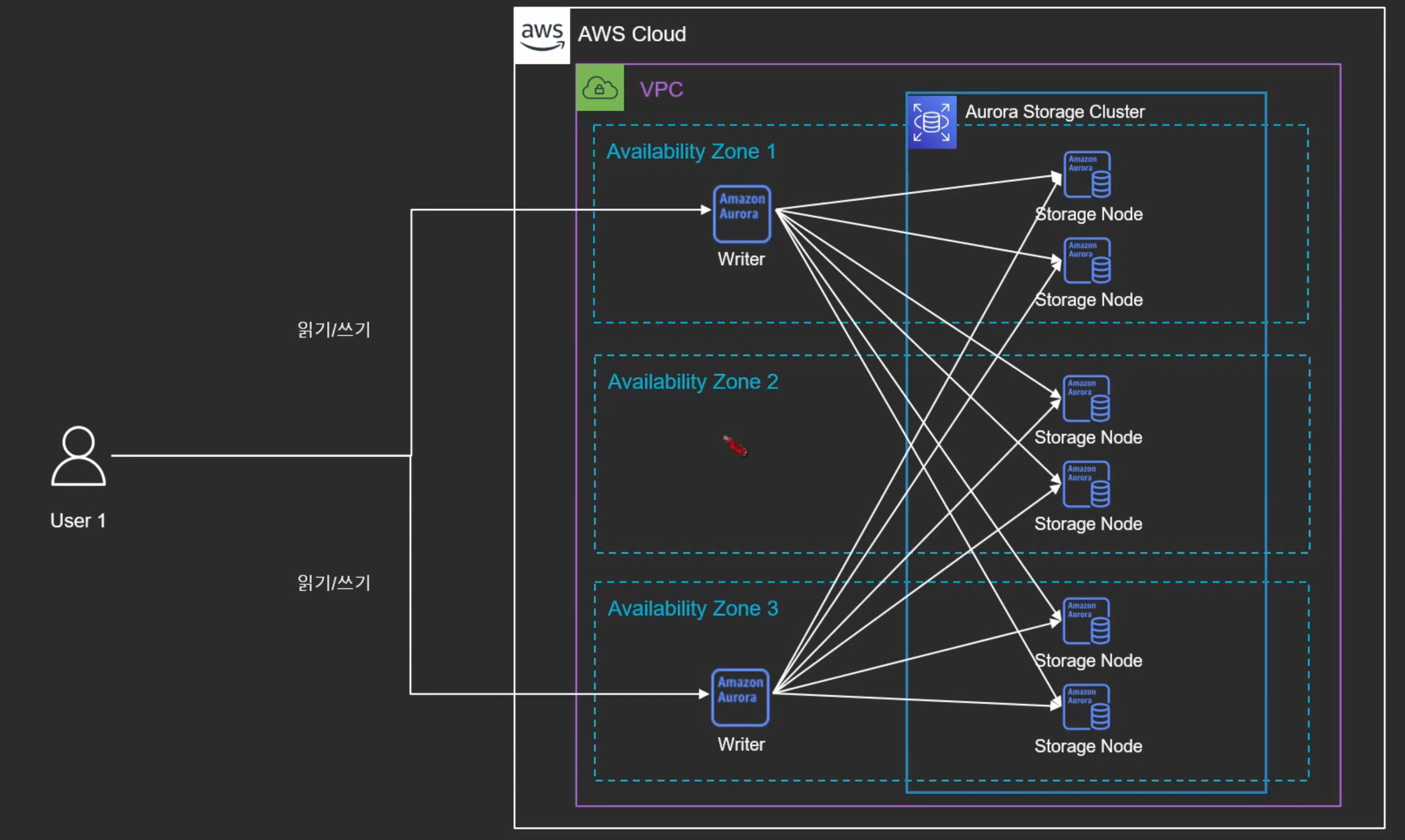
- 읽기/쓰기를 담당하는 노드가 여러개임( 최대4개 )
- 각 노드는 독립적: 정지/재부팅/삭제 등에 서로 영향X
- 지속적인 가용성 제공
- 주로 Multitenant 또는 Sharding이 적용된 애플리케이션에 좋은 성능
- 스토리지 간에 동시에 read/write 할 때 싱크를 어떻게 맞추느냐는 나중에 심화수업때 !
Aurora의 특징
(1) MySQL과 PostgreSQL 지원
(2) 두가지 모드
1) 다수의 노드로 읽기 쓰기가 가능한 Multi-Master
2) 한개의 쓰기 전용 노드와 다수의 읽기 전용 노드 구성의 Single-Master
- 대부분의 경우 Single-Master모드를 사용 함. 왜냐면 Multi-Master를 쓸 경우 사용하지 못하는 Aurora의 기능들이 있다.
==> 따라서 시나리오에 따라 적절하게 선택해야 함
(3). 용량의 자동 증감: 10GB부터 시작하여 10GB 단위로 증가( 최대 128TB )
- 읽기 쓰기 노드와 저장 노드를 분리 시켰기 때문에 가능
cf) RDS는 EBS 기반이기 때문에 미리 용량을 확정하여 EBS를 생성해야 함
(4). 연산 능력: 96vCPU와 768GB까지 증가 가능
(5). 데이터의 분산 저장
- 각 AZ마다 2개의 데이터 복제본 저장 * 최소 3개 이상의 AZ
==> 최소 6개의 복사본 - 3개 이상을 잃어버리기 전엔 쓰기 능력이 유지
- 4개 이상을 잃어버리기 전엔 읽기 능력이 유지
- 손실 된 복제본은 자가치유 - 지속적으로 손실된 부분을 검사 후 복구
- Quorum 모델 사용 (투표시스템..6개 복제본이 존재할 때 6개에 대한 상태를 어떻게 유지할 것에 대한 방법을 투표로 정한다는 것..write가 발생 했을 때 6개 중 4개 이상의 노드에 쓰여질 경우 완전무결한 write로 인정하겠다...6개 중 3개 이상의 노드를 확보하여 read 했을 때 올바른 read라고 인정...)
Aurora Global Database
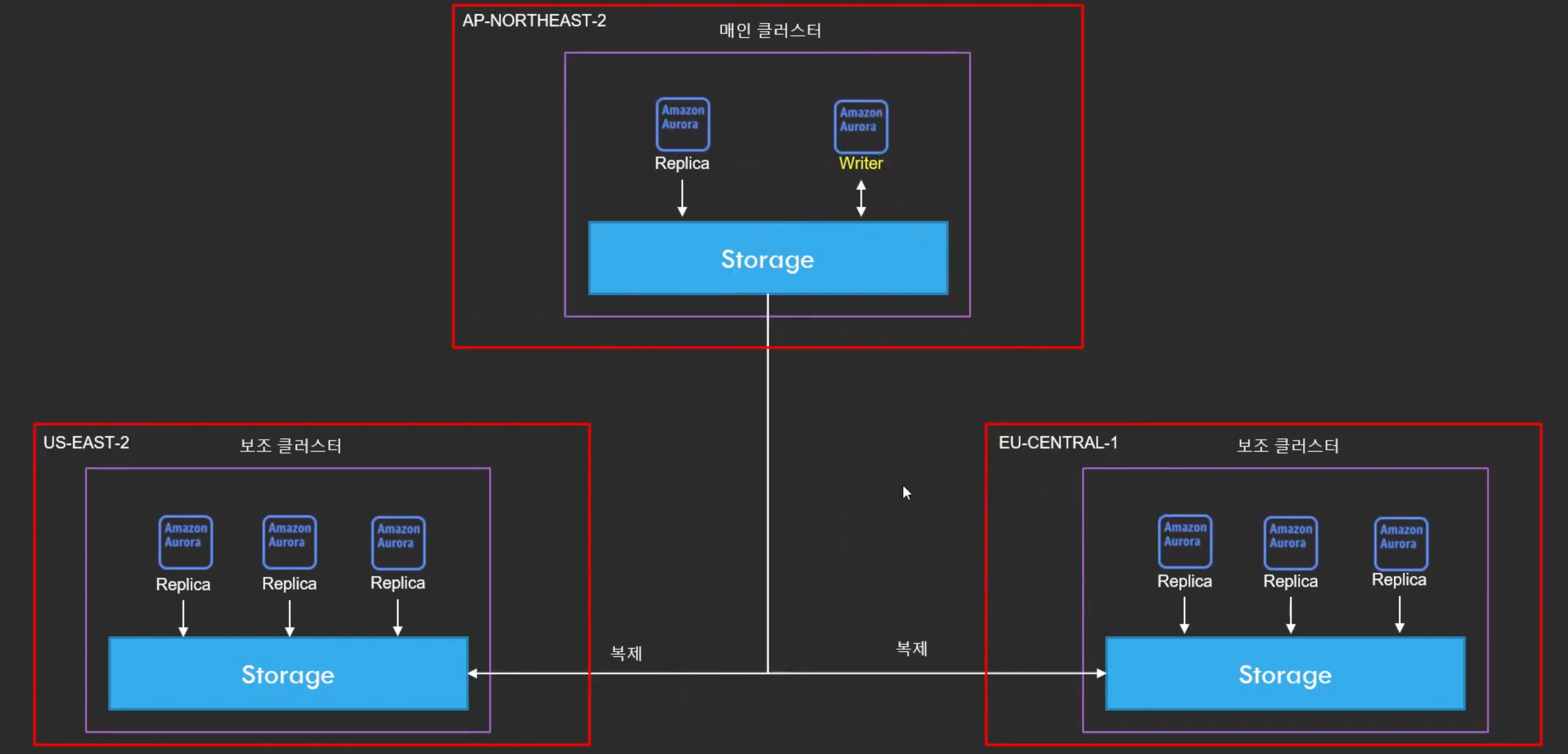
-
전세계 모든 리전에서 1초 내의 지연시간으로 데이터 엑세스 가능한 서비스
-
다른 리전에 자동으로 복제하는 서비스
-
재해복구 용도로 활용 가능
1) 유사시 보조 리전 중 하나를 승격하여 메인으로 활용
2) 1초의 PRO (복구 목표 지점)
3) 1분 미만의 RTO (복구 목표 시간) -
보조 리전 중에는 총 16개의 Read 전용 노드 생성 가능 (원래는 15개)
-
만약 위 그림처럼 서울리전에 메인클러스터가 있고 그 안에 쓰기노드와 읽기노드가 있다. 그리고 다른리전에 보조클러스터로 스토리지를 계속 복제하게 된다. 서울리전 AP-NORTHEST-2가 터지면 US-EAST-2 또는 EU-CENTRAL-1
둘 중 하나의 보조클러스터가 메인클러스터 역할을 수행한다. 데이터가 계속 복제되고 있기 때문에 약 1초 이상의 데이터는 손실X
병렬 쿼리
-
읽기 노드가 여러개이기 때문에 쿼리 자체를 병렬로 처리
-
다수의 읽기 노드를 통해 쿼리를 병렬로 처리하는 모드
(1) 빠름
(2) 부하 분산 (CPU, memory) -
MySQL 5.6/5.7에서만 지원
-
몇몇 낮은 인스턴스( db.t2, db.t3 등 )에서는 지원X
Aurora의 백업
(1) 읽기 복제본(Read replica) 지원 (Aurora replica와 다른 개념)
- MySQL DB의 Binaary log 복제(Binlog)
- 단 다른 리전에만 생성 가능
(2) RDS와 마찬가지로 자동/수동 백업 가능
- 자동백업의 경우 1~35일 동안 보관 (S3에 보관)
- 수동백업(스냅샷) 가능
- 백업 데이터를 복원할 경우 다른 데이터베이스를 생성
Aurora의 데이터베이스 클로닝
-
기존의 데이터베이스에서 새로운 데이터베이스를 복제
: 스냅샷을 통해 새로운 데이터베이스를 생성하는 것보다 빠르고 저렴 -
Copy-On-Write 프로토콜 사용
1) 리소스가 복제되었지만 수정되지 않은 경우에 새 리소스를 만들 필요 없이 복사본과 원본이 리소스를 공유하고, 복사본이 수정되었을 때만 새 리소스를 만드는 리소스 관리 기법
2) 기존 클러스터를 삭제해도 제대로 동작
Backtrack
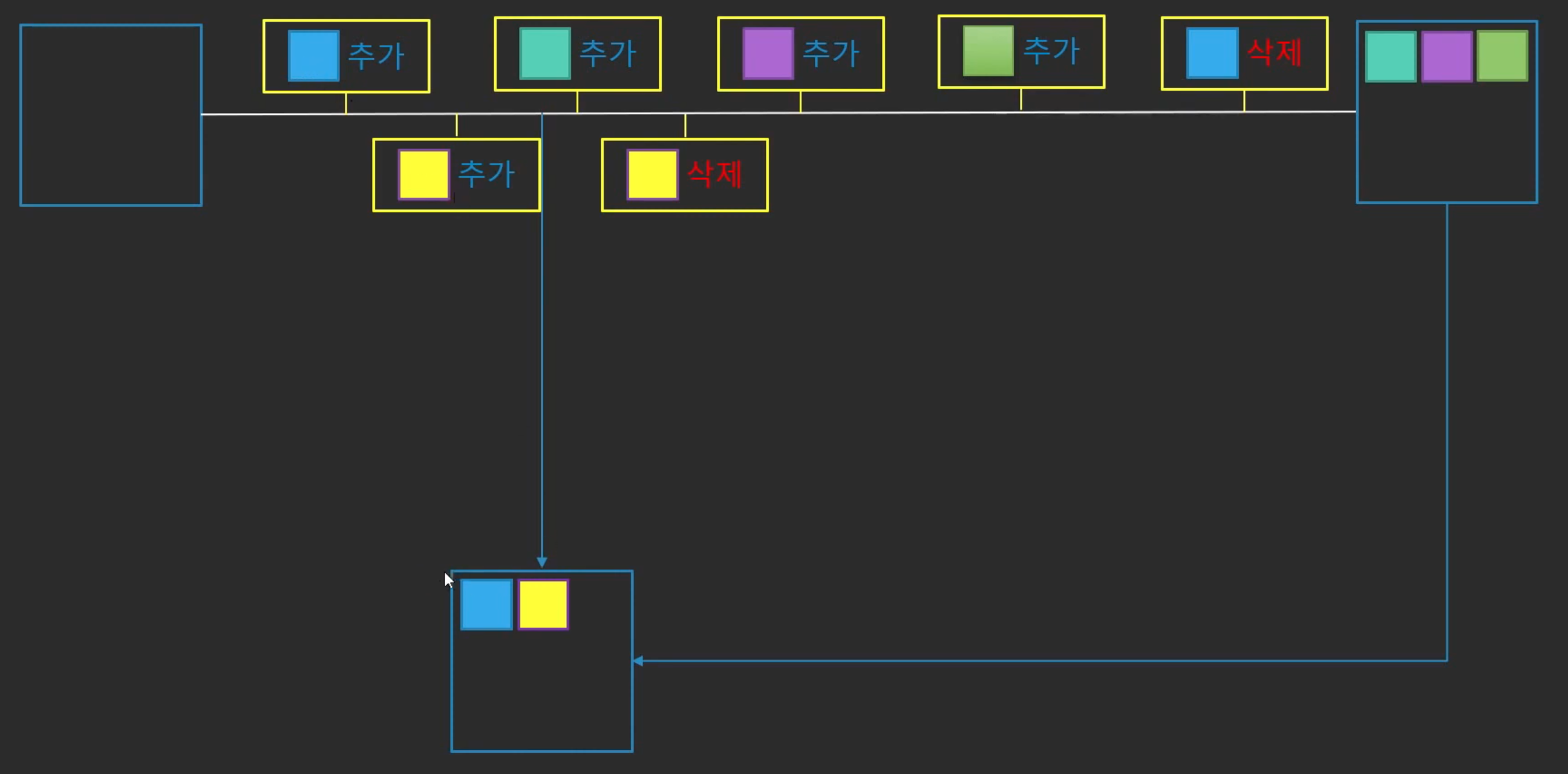
-
기존 DB를 특정시점으로 되돌리는 것 (새로운 DB가 아닌 기존DB)
-
DB관리의 실수를 쉽게 만회 가능
ex) Where없는 Delete.. -
새로운 DB를 생성하는 것보다 훨씬 빠름 (변경부분만 반영하면 되기 때문)
-
앞뒤로 시점을 이동할 수 있기 때문에 원하는 시점을 빠르게 찾을수O
Backtrack Window
(1) Target Backtrack Window
- 어느 시점 만큼 DB를 되돌리기 위한 데이터를 저장할 것인지
- 지정시점 이전으로는 Backtrack 불가능
(2) Actual Backtrack Window
- 실제로 시간을 얼만큼 되돌릴지
- Target Backtrack Window보다 작아야함
-
Backtrack 활성화 시 시간당 DB의 변화를 저장
--> 저장된 용량만큼 비용 지불
--> DB변화가 많을수록 많은 로그 = 많은 비용
--> DB로그가 너무 많아 Actual Backtrack Window가 Target Backtrack Window(설정값)보다 작을 경우, 알림 -
MySQL만 가능
-
Aurora 생성시 Backtrack을 설정한 DB만 Backtrack 가능
-
Multi-Master 상태에서는 Backtrack 불가능
참고
