
DynamoDB
DynamoDB는 완전 관리형 NoSQL 데이터베이스로, 분산 데이터베이스를 운영하며 크기 조정에 따른 개발자의 관리 부담을 줄여 준다. 또한, 하드웨어 프로비저닝, 설정 및 구성, 복제, 소프트웨어 패치, 클러스터 크기 조정 등에 대해 걱정할 필요가 없다.
아래에 그밖에 또다른 특징 및 장점들을 나열해 보았다.
- DynamoDB는 암호화를 제공해 중요한 데이터를 보호할 수 있게 해준다.
- 다운타임 또는 성능 저하 없이 테이블의 처리 능력을 확장 또는 축소할 수 있다.
- 온디맨드 백업 기능을 제공하기 때문에 장기간 유지 및 보관이 가능하다.
- 특정 시점으로 복구를 활성화 할 수 있다. → 단, 특정 시점으로부터 최근 35일 증 원하는 시점으로 복구가 가능하다.
- TTL(Time To Live) 설정이 가능하기 때문에 만료된 항목을 테이블에서 자동으로 삭제할 수 있다.
- 가용성이 높다.
- 테이블의 데이터 및 트래픽을 자동 분산해 스토리지 요구 사항을 처리하며 빠른 성능을 유지한다.
- 모든 데이터는 SSD에 저장되고 리전의 여러 가용 영역에 자동 복제되어 고가용성 및 내구성을 제공한다.
- 전역 테이블 사용이 가능하기 때문에 aws 리전 간에 테이블을 동기화 할 수 있다.
구성요소
테이블, 항목, 속성으로 구성된다.
테이블
- RDB에서와 같은 테이블을 의미한다.
항목
- 고유하게 식별할 수 있는 속성들의 집합이다.
- Cars 테이블에서는 차량 한 대가 항목이 된다.
- 다른 DB 시스템의 행과 유사하다.
- 테이블에 저장할 수 있는 항목 수에 제한이 없다.
속성
- 각 항목은 하나 이상의 속성으로 구성된다.
- 기본적인 데이터 요소로, 더 이상 나뉠 필요가 없다.
- People 테이블을 예시로 보면 PersonID, LastName, FirstName 등이 그 속성이 된다.
아래의 예시를 보자.
예시
People table

- People 테이블에는 각 항목을 다른 항목들과 구별하기 위한 고유 식별자인
기본 키가 있다. → 이는 RDB에서의 pk와 유사하다. → 여기서는 PersonID가 기본 키다.
- People 테이블에는 스키마가 없다. → 즉, 속성 및 데이터 형식을 미리 정의할 필요가 없다.
- 속성은 스칼라로, 하나의 값만 가질 수 있다.
Address의 경우 중첩되어 있는데, DynamoDB는 최대 32개 깊이까지 중첩된 속성을 지원한다.
Music table

- 기본 키가
Artist,SongTitle두 개이다. → 각 item들이 이 두 속성을 가지고 있어야 한다. → 이는 item을 다른 item들과 구별해 준다.
- 기본 키 외에는 스키마가 없다.
기본 키
테이블의 각 항목을 나타내는 고유 식별자로, 각 두 item이 동일한 키를 가질 수 없다.
두 가지의 기본 키가 있으며 각 기본 키의 속성은 스칼라(단일 값)여야 한다.
- 파티션 키: 하나의 속성으로 구분되는 단순 기본 키 ⇒
해시 속성이라고도 한다.
- 파티션 키 + 정렬 키: 복합 기본 키로, 두 개의 속성으로 구성된다.
-
이 경우, 파티션 키 값이 동일한 항목들은 정렬 키 값을 기준으로 정렬되어 저장 된다.
-
파티션 키 값이 같을 수 있다. 하지만 정렬 키 값은 달라야 한다.
→ 위의 Music 테이블 예시는 복합 기본 키를 사용하는 예시이다.⇒
범위 속성이라고도 한다.
-
보조 인덱스
보조 인덱스를 통해 기본 키에 대한 쿼리 뿐만 아니라 대체키를 사용해 테이블의 데이터를 쿼리할 수 있다.
DynamoDB는 인덱스가 필요하지 않지만, 데이터 쿼리에는 보조 인덱스가 유용한 수단이다. 이를 통해 테이블에서 데이터를 읽는 것과 같은 방식으로 인덱스에서 데이터를 읽을 수 있다. 2가지 보조 인덱스가 있다.
- 글로벌 보조 인덱스(GSI): 파티션 키와 정렬 키가 테이블과 다를 수 있는 인덱스
- 로컬 보조 인덱스(LSI): 기본 테이블과 파티션 키는 동일하지만 정렬 키가 다른 인덱스
→ GSI는 총 20개 & LSI는 총 5개의 할당량이 있다.
예시
위의 Music 테이블에는 이미 기본키로 “파티션 키 + 정렬 키”가 있다.
그런데 만약 Genre와 AlbumTitle에 대해 인덱스 생성 후 쿼리를 하고 싶다면 어떻게 해야 할까?
이 때는 Genre 및 AlbumTitle에 대한 인덱스를 만들고 쿼리하면 된다. 즉, GenreAlbumTItle이라는 새로운 인덱스 테이블이 생성된다고 보면 된다. 이 인덱스 테이블에서 Genre가 파티션 키, AlbumTitle이 정렬 키가 된다.

- Music은 GenreAlbumTitle 인덱스의
기본 테이블이라 부른다. - DynamoDB는 인덱스를 자동으로 유지 관리하기 때문에 기본 테이블의 항목이 추가 또는 삭제 되면 해당 테이블에 속하는 모든 인덱스에서 해당 항목이 추가 또는 삭제 된다. → 완전 관리의 속성이 여기에 있다.
DynamoDB Streams
DynamoDB Streams는 스트림 레코드를 기록한다.
만약 테이블의 데이터 수정 이벤트가 발생하면 이를 캡쳐하는 것이다. 이벤트가 발생한 순서대로 거의 실시간으로 스트림에 표시되며 이는 선택적 기능이다. 스트림 레코드의 수명은 24시간이기 때문에 이후에는 스트림에서 자동으로 제거 된다.
aws에서 제시하는 스트림 레코드를 기록하는 이벤트는 다음과 같다.
테이블에 새로운 항목이 추가되면 스트림이 해당 속성을 모두 포함하여 전체 항목의 이미지를 캡처합니다.
항목이 업데이트되면 스트림이 항목에서 수정된 속성의 "사전" 및 "사후" 이미지를 캡처합니다.
테이블에서 항목이 삭제되면 스트림이 항목이 삭제되기 전에 전체 항목의 이미지를 캡처합니다.
이 기능은 다음과 같은 상황에서 사용이 가능하다.
가령, Customers 테이블이 있을 때 새로운 고객이 추가될 때 고객에게 환영 알림을 보내고 싶다고 하자. 그러면 스트림을 활성화 한 다음 해당 스트림을 lambda 함수와 연결할 수 있다. lambda 함수는 새 고객이 추가될 때마다 실행되며 고객의 전화번호에 맞게 문자를 전송할 수 있다.
비용
아래 사진은 효과적인 NoSQL 디자인 및 활용 방안 강의에서 제시된 자료이다.
우리는 욕설 데이터를 DynamoDB 테이블에 담을 것이다. 이를 유념해 비용을 책정하는 과정을 적어 보았다.
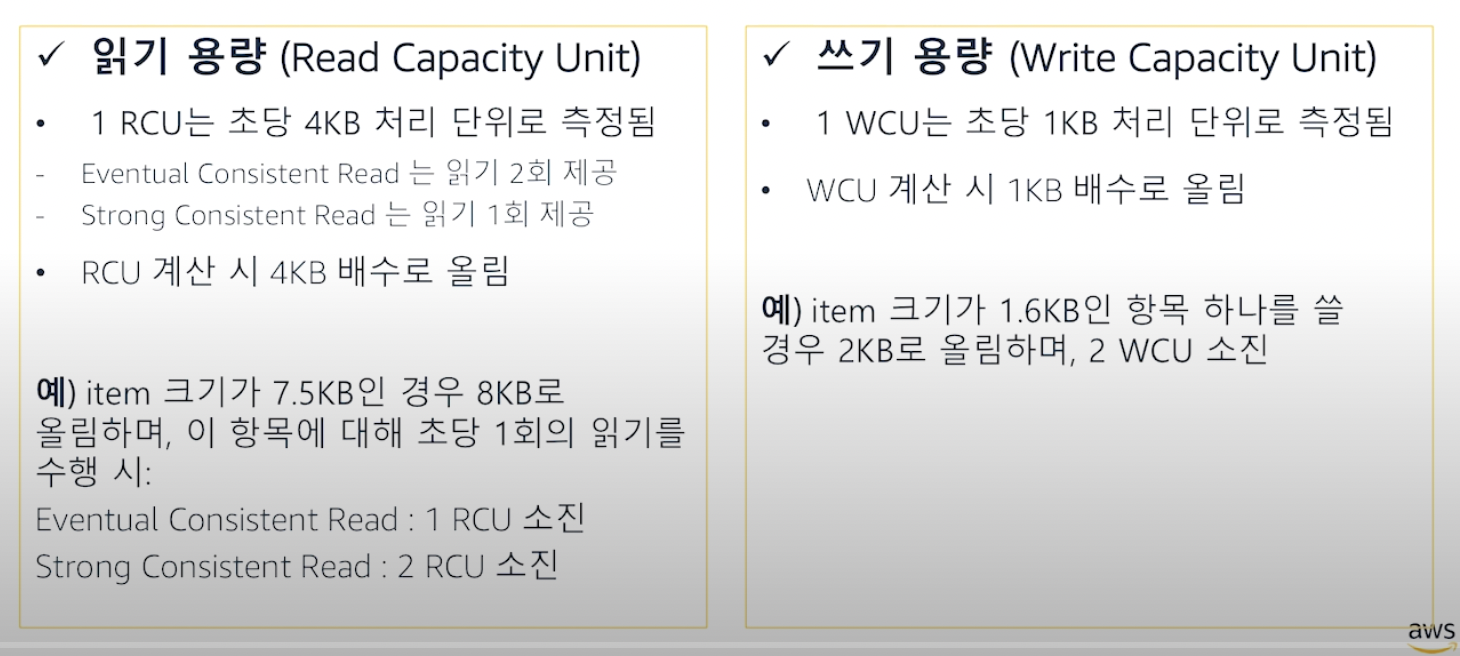
- 한글 한 글자 당 2byte 이고 욕설 하나 당 평균 세 글자이므로 6byte 정도& 영어 한 글자 당 1byte → 단어 1000개 정도 예상되므로 총 6000byte(6kb) 정도의 용량을 소모할 예정 → 여기에 pk를 추가하면 pk를 name 또는 word로 할 경우 4byte이고 item 1000개에 1000번 들어가니까 4000byte(4kb) 소모할 예정 ⇒ 총 10kb 용량이 될 것임(만약 pk를 2글자까지 줄이면 8kb에 들어올 수는 있을듯)
- 읽기
- 1RCU는 4kb/초 이고 eventual consistent read 선택시 읽기 2회를 제공하기 때문에 초 당 1회의 읽기 수행하면 2RCU를 초 당 행하게 되므로 8kb까지 읽을 수 있다. → item의 크기가 10byte이므로 읽기 용량 1RCU를 해도 되겠다.
- 1RCU는 4kb/초 이고 eventual consistent read 선택시 읽기 2회를 제공하기 때문에 초 당 1회의 읽기 수행하면 2RCU를 초 당 행하게 되므로 8kb까지 읽을 수 있다. → item의 크기가 10byte이므로 읽기 용량 1RCU를 해도 되겠다.
- 쓰기
- 1WCU는 1kb/초 이고 욕설 item은 10byte 정도이므로 1WCU 소모 예정
- 읽기
따라서 아래와 같은 용량 계산을 하면 될 것 같다.
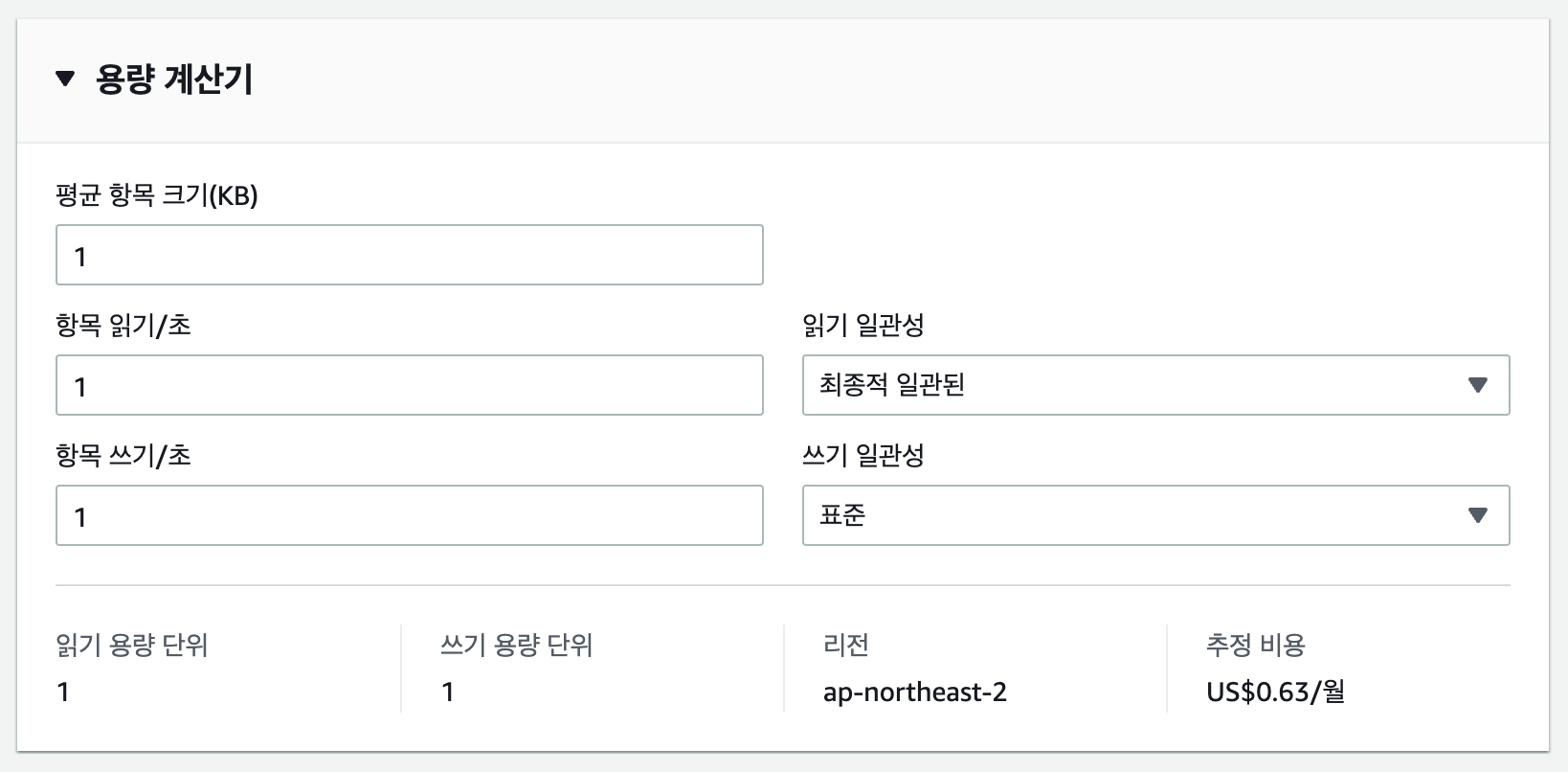
프로비저닝 용량 단위

- 테이블 당 40000 RCU와 40000 WCU를 할당 받음
- 아래와 같이 설정해서 테이블 생성하면 될 것 같다.
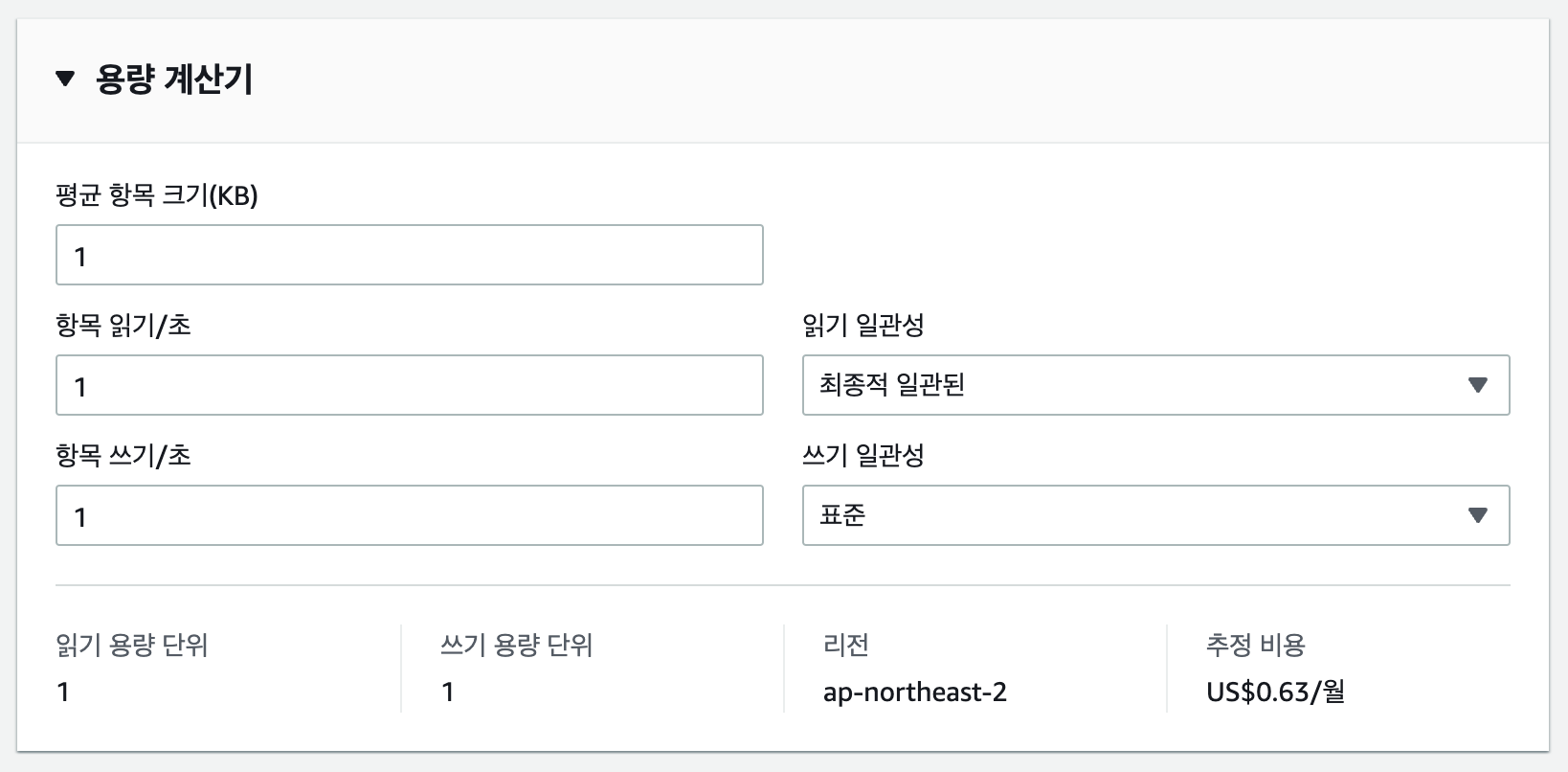
Items 크기
항목 크기
DynamoDB에서 최대 항목 크기가 400KB를 초과할 수 없다.
→ 여기에는 속성 이름 이진 길이(UTF-8 길이)와 속성 값 길이(이진 길이)가 모두 포함되며 속성 이름은 크기 제한에 포함되기 때문에 변수명을 지을 때도 잘 생각해야 한다.
목록, 맵 또는 집합 내 값 수
목록, 맵 또는 집합 내 값의 수에는 제한이 없다. 단, 값을 포함하는 항목이 400KB 항목 크기 제한을 초과하지 않아야 한다. 따라서, 욕설 데이터를 집합으로 담는다고 해도 400KB만 넘지 않으면 되기 때문에 아마도 모든 욕설을 다 담을 수 있지 않을까 싶다.
Boto3로 파이썬에서 DynamoDB 사용하기
boto3 공식 문서에 DynamoDB를 boto3로 사용하는 예시가 잘 설명 되어 있다.
table은 aws console로 생성했다고 가정하고 알아본다.
DynamoDB 사용 설정하기
import boto3
# Get the service resource.
dynamodb = boto3.resource('dynamodb')
# Instantiate a table resource object without actually
# creating a DynamoDB table.
table = dynamodb.Table('users')새로운 item 추가하기
아이템을 추가하는 방법은 item에 들어갈 값들을 직접 명시해 주는 방법도 있고, 만약 String set이나 list가 들어갈 경우 그 형식을 지정해서 추가하는 방법도 있다.
table.put_item(
Item={
'pk': 1,
'username': 'janedoe',
'first_name': 'Jane',
'last_name': 'Doe',
}
)만약 여러 사람을 동시에 추가하고 싶다면 다음과 같이 한다.
people = [person1, person2]
table.put_item(
Item={
"pk": 1,
"people": {"SS": set(people)}}
) 여기서 “SS”는 String Set을 의미한다. 가령 “L”의 경우 List를 의미한다. 이에 대해서는 여기에 잘 설명되어 있다.
아이템 가져오기
아래와 같이 get_item 메소드를 이용한다. Key를 사용하기 때문에 이를 import 해야 한다.
from boto3.dynamodb.conditions import Key
response = table.get_item(
Key={
'username': 'janedoe',
'last_name': 'Doe'
}
)
item = response['Item']
print(item)만약 String Set으로 추가했다면 아래와 같이 가져올 수 있다.
response = table.get_item(Key={"pk": 1})
print(response["Item"]["people"]["SS"])
>>> [person1, person2]Boto3 resource vs client
stackoverflow를 참고했다.
boto 사용시 resource와 client를 모두 사용할 수 있는데 두 가지 모두 사용할 수 있지만 약간의 차이점이 있다.
client
client는 원래 boto3 API 추상화로, low-level의 AWS service access를 제공한다.
모든 AWS service 운영은 client에 의해 지원된다. client는 개발자에게 botocore client를 노출하며 보통 AWS service와 API를 1:1로 매핑한다. 또한, snake-cased 메소드명을 제공한다(e.g. ListBuckets API => list_buckets method).
예시
S3를 사용하는 예시이다.
import boto3
client = boto3.client('s3')
response = client.list_objects_v2(Bucket='mybucket')
for content in response['Contents']:
obj_dict = client.get_object(Bucket='mybucket', Key=content['Key'])
print(content['Key'], obj_dict['LastModified'])→ 이 경우 client-level의 코드는 최대 1000개의 객체만 리스팅 하는 것이 가능하기 때문에 그 이상의 수의 객체를 불러오려면 paginator를 이용해야 한다.
resource
이는 client보다 조금 더 최신의 boto3 API 추상화로, high-level의 객체 지향 API를 제공한다. 그러나 resource는 AWS 서비스의 100% API 적용 범위를 제공하지 않기 때문에 주의해야 한다. 이는 identifiers와 attributes를 이용하고 특정한 actions를 지니며 하위 리소스들과 AWS resources의 컬렉션을 개발자에게 노출한다.
예시
S3를 사용하는 예시이다.
import boto3
s3 = boto3.resource('s3')
bucket = s3.Bucket('mybucket')
for obj in bucket.objects.all():
print(obj.key, obj.last_modified)→ 이 경우 client의 경우와 달리 객체를 가져오기 위해 2차 API 호출을 하지 않아도 된다. API 호출을 한 번만 해도 bucket 컬렉션이 전부 제공된다. 그러나, 이러한 하위 리소스들은 지연 로드 된다는 단점이 있다. 또한, 한 눈에 보기에도 그러하듯 resource가 client의 경우보다 소스 코드가 더 짧다.
⇒ 정리하면 client와 resource 둘 다 비슷하지만 client는 API호출을 2번 해야 하는 반면 resource는 한 번에 전부 가져올 수 있지만 하위 리소스들은 지연 로드 된다는 특징이 있다. 또한 client는 코드가 resource를 사용하는 경우보다 조금 더 복잡하다.
관계형 vs NoSQL
여기를 참고했다.
aws에 따르면 DynamoDB는 대량의 데이터와 매우 많은 수의 사용자를 처리할 수 있도록 크기를 원활하게 조정한다. 따라서, 데이터베이스가 초당 수만 혹은 수십만 건의 읽기 및 쓰기를 처리해야 한다면 DynamoDB를 쓰는 것이 좋을 수 있다.
관계형 데이터베이스는 파일 숫자와 크기에 최대치가 있기 때문에 이 최대치가 확장성의 상한선이 된다. 반면 DynamoDB는 분산된 하드웨어 클러스터를 사용해 확장하도록 설계되어 있어 지연 시간의 증가가 없는 처리 능력 증대가 가능하다. 따라서, 고객이 처리량 요구 사항을 지정하면 DynamoDB는 충분한 리소스를 할당하게 된다.(하지만 돈은 나갈 것이다....)
참고
