
Serverless 인프라 이용해 블로그 만들기
이제부터 블로그를 하나 만든다고 가정해 보자. 블로그는 대부분 쓰기 요청보다 읽기 요청이 더 많다는 점을 기억하자.
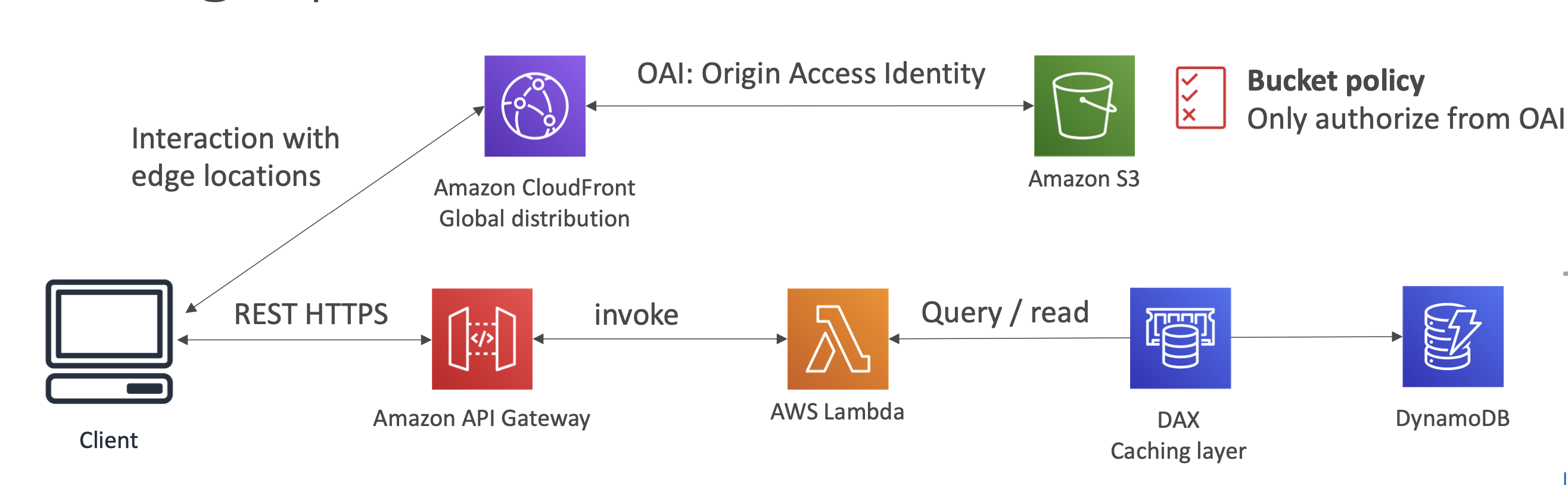
정적 컨텐츠를 글로벌 하게 클라이언트에 제공하기
S3로부터 사진 데이터를 받아온다고 가정하자.
그 다음, 클라이언트와 S3 버킷 사이에 CloudFront를 놓아 전 세계적으로 엣지 로케이션이 분포하게 하여 각국의 사용자들이 CloudFront와 상호작용 할 수 있도록 만든다. 그럼 이는 S3로부터 받은 데이터를 캐싱해 둘 수 있다.
그럼 이제 OAI(Origin Access Identity)를 이용해 CloudFront가 S3로 액세스 요청을 할 것이고, S3에 추가된 버킷 정책은 OAI에만 읽기 권한을 부여하였으니 인증된 사용자만 읽기 요청이 가능하다.
여기서 확인할 수 있는 점은 클라이언트는 CloudFront를 한 번 거쳐야 하기 때문에 인프라를 안전하게 보호할 수 있다는 것이다.
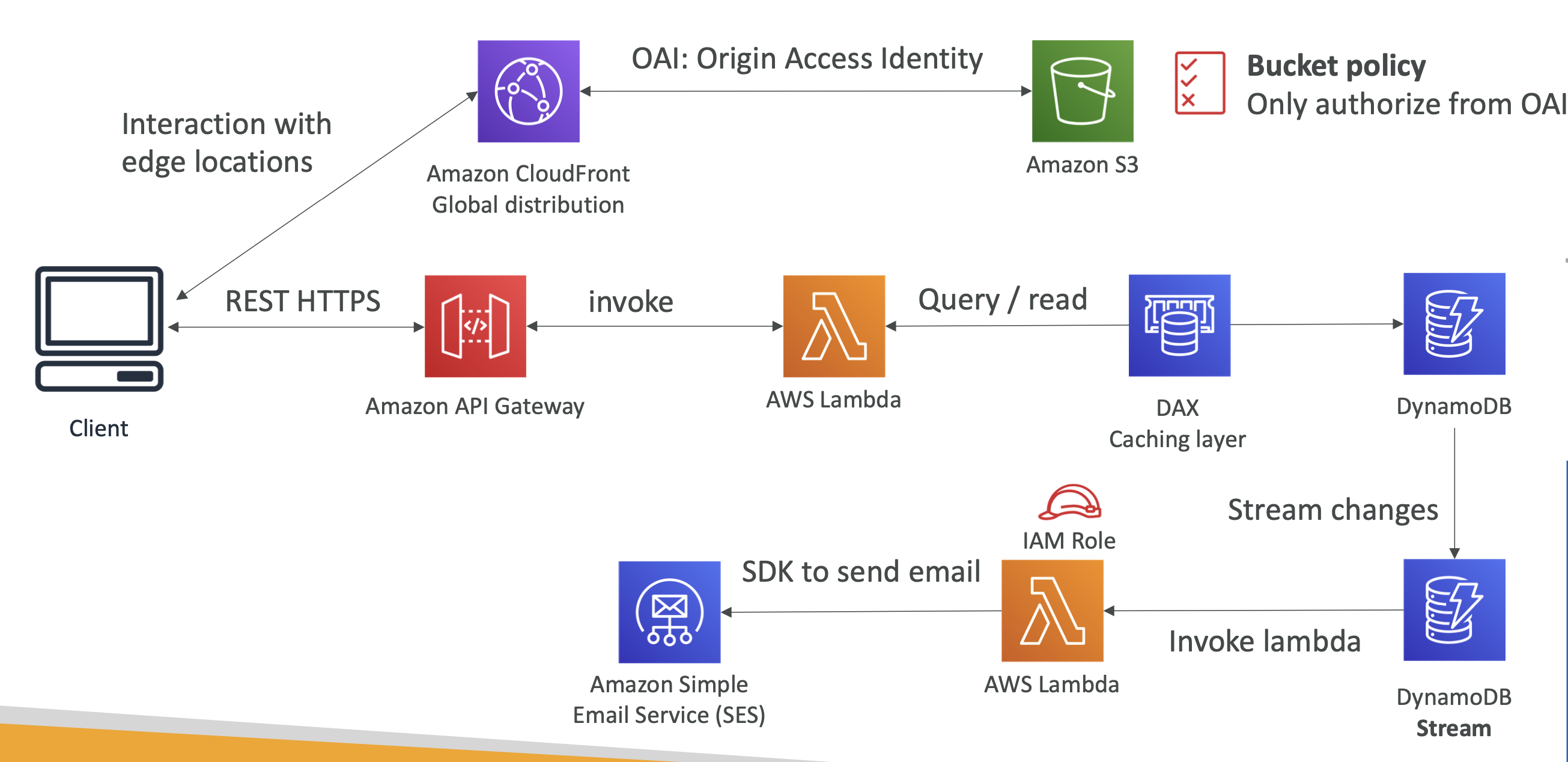
사용자가 구독하면 환영 이메일 보내기
위의 아키텍쳐에 DynamoDB Stream을 추가하면 된다.
DynamoDB Streams는 람다를 호출하고 람다는 SES를 이용할 수 있는 IAM Role을 갖고 있어 AWS SES를 이용해 메일을 보내게 될 것이다.
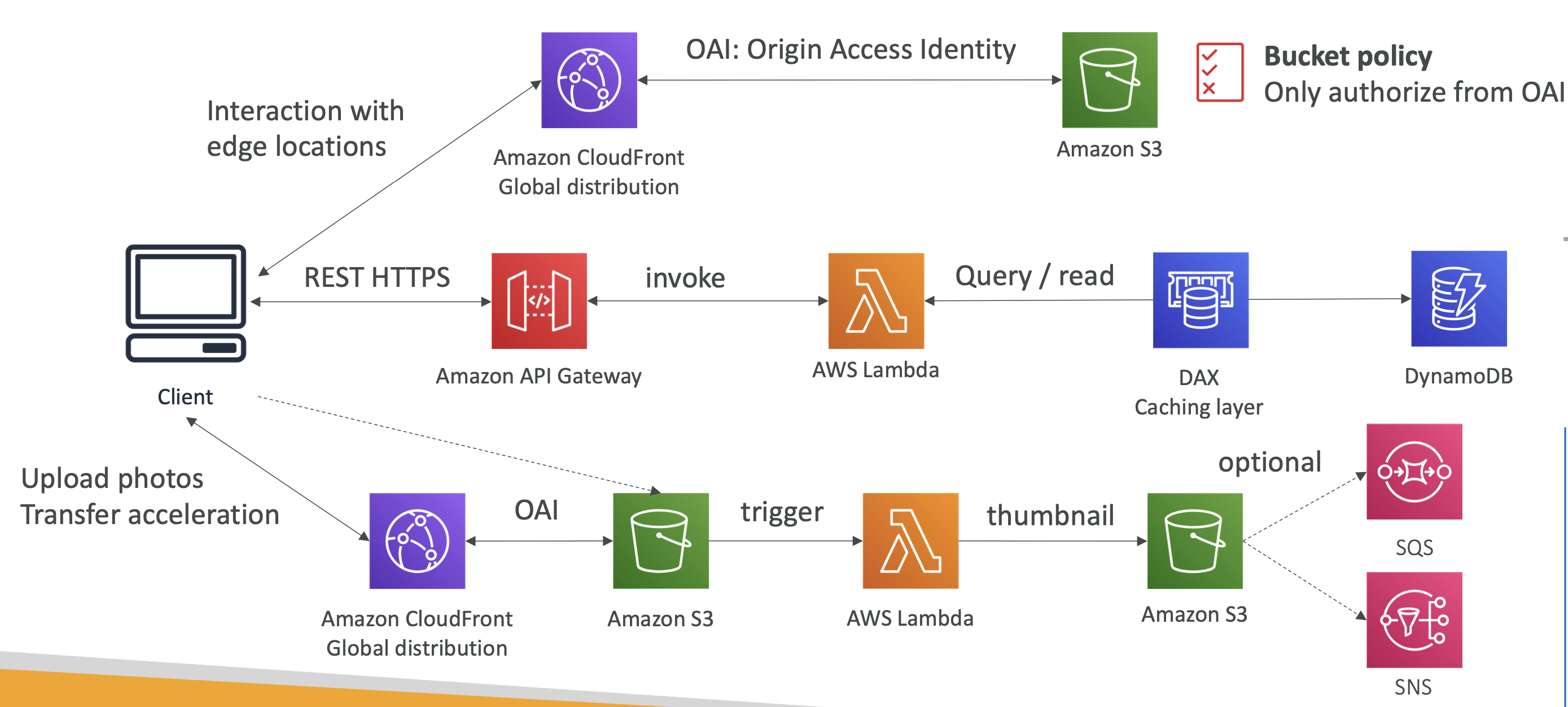
사용자가 업로드한 사진으로 썸네일 만들기
유저가 사진을 업로드 하면 바로 CloudFront로 보내지고 OAI를 이용해 CloudFront가 S3 버킷과 상호작용 한다. 이렇게 S3에 직접 보내지 않고 CloudFront를 한 번 거치는 것을 S3 Transfer Acceleration이라 한다.
그리고 파일이 S3에 추가될 때마다 S3는 람다 함수를 호출할 것이다. 그러면 람다는 썸네일을 생성하고 이를 S3 버킷에 저장하는데 여기서는 기존 S3 버킷이 아니라 썸네일용 버킷을 사용한다고 가정해 보자. 그 다음 추가적으로 SQS나 SNS를 붙여서 알림을 보낼 수도 있다.
Micro Service Architecture
각 MSA는 원하는 방식 대로 구현해도 상관 없다.
단, 아래 도식에서는 service2는 service1과, service3는 service2와 상호작용 한다고 가정해 본다.
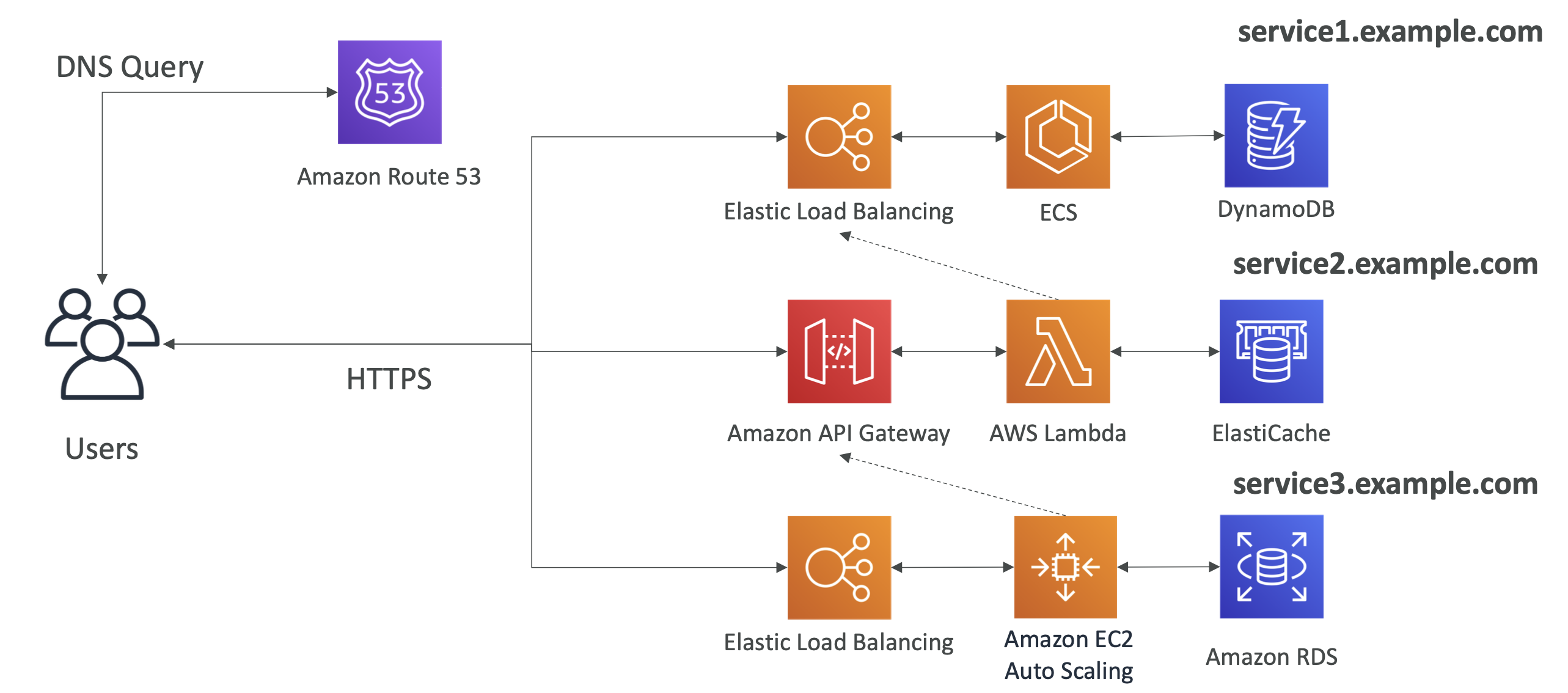
크게 두 가지 패턴을 이용해서 MSA를 구현할 수 있다.
동기적 구현
- 클라에서 들어온 요청을 다른 Micro Service에 전달한다.
- API Gateway와 Load Balancer가 HTTPS 요청을 다른 마이크로 서비스로 전달하는 역할을 한다.
비동기적 구현
- SQS, Kinesis, SNS, Lambda triggers(S3)
- SQS를 예로 들면, SQS에 메시지를 전달하지만 응답이 언제 오는지는 신경 쓰지 않고 다른 이벤트가 일어나게 된다.
그러나 MSA의 단점으로는 아래와 같은 사항들이 있다.
- MSA를 구축하기까지 간접적인 처리 시간 · 메모리가 소요된다.
- 구축한 여러 종류의 서버를 얼마나 잘 사용할 수 있을 지에 대한 이슈가 있다.
- 그러나 이는 서버리스를 활용하면 해결할 수 있다.- 즉, API Gateway나 Lambda를 이용하면 자동으로 확장하고 사용한 만큼 돈을 지불하기 때문에 사용률에 관한 고민을 하지 않아도 된다.
- API를 재활용하거나 환경을 복제하는 것도 손쉽게 할 수 있다.
- 여러 MSA를 동시에 사용하면서 생기는 복잡성 문제가 있다.
- 분리된 서비스를 통합해 사용하기 위해 클라이언트에 많은 시간이 소요될 수 있다.
유료 컨텐츠 배포를 위한 아키텍쳐
글로벌한, 서버리스의 넷플릭스와 같은 서비스를 만들려면 어떻게 해야 할까?
CloudFront는 Signed URL(이는 IP 주소 제한을 포함한 보안을 갖는다)을 사용할 수 있다. 이를 이용하면 유료 고객들에게만 URL을 제공할 수 있다. 그러려면 Signed URL을 생성할 수 있는 애플리케이션이 있어야 한다.
이를 위해서 기존과는 달리 API Gateway를 추가로 하나 더 두어야 한다. 그러면 클라이언트가 Cognito를 이용해 사용자 인증 정보를 API Gateway에 전달하면 API gateway는 람다함수를 호출해 Signed URL을 클라이언트에 제공하게 된다.
즉, 호출된 람다 함수는 DB에 접근해 API를 호출한 사용자가 프리미엄 유저인지 확인하고 만약 호출한 유저가 프리미엄 유저면 람다함수는 AWS SDK를 통해 CloudFront API를 이용하게 될 것이다. 이제 CloudFront는 Signed URL을 생성할 것이고 이는 생성한지 5분이 지나면 만료된다(이는 설정 가능하다).
생성된 Signed URL은 람다로부터 API Gateway로 전달되고 API Gateway는 이를 클라이언트에 전달한다. 그러면 클라이언트는 CloudFront에 Signed URL을 이용해 접근할 수 있다.
위에서 설명한 아키텍처는 아래와 같다.
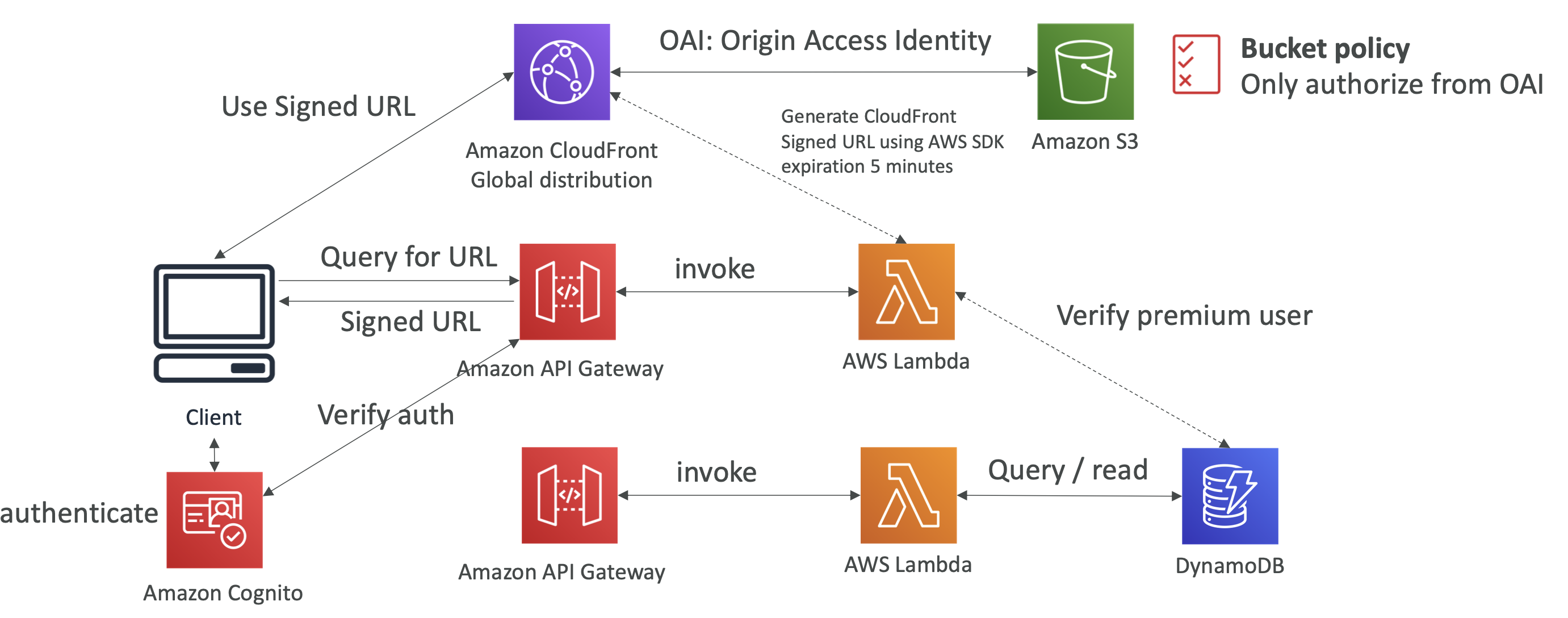
- 이 경우, 유저 registration을 위한 람다 함수와 signed URL을 생성하기 위한 람다 함수 총 두 종류의 람다 함수가 호출되었다.
만약 CloudFront를 이용하지 않고 S3만 이용한다면?
- CloudFront Signed URL을 얻는 대신 S3 Signed URL을 얻을 수 있다.
- 그러나, 이 경우 글로벌하게 배포할 수는 없다. - 또한, OAI의 경우 CloudFront만 S3에 접근할 수 있도록 하기 때문에 S3 pre-signed URL은 작동하지 않게 될 것이다.
소프트웨어 업데이트 배포를 위한 아키텍쳐
우리가 서비스 중인 애플리케이션을 업데이트 하고 싶을 때가 있을 것이다.
가령 아래와 같이 EC2가 여러 AZ에서 작동 중이고 업데이트를 위한 정적 파일은 Amazon Elastic Filesystem(AEF)에 있다고 하자.
그러면 보통은 클라이언트 - ELB - 여러 EC2들 - AEF의 구조를 생각하는데, 이 때 더 좋은 방법은 ELB앞에 CloudFront를 붙이는 것이다.
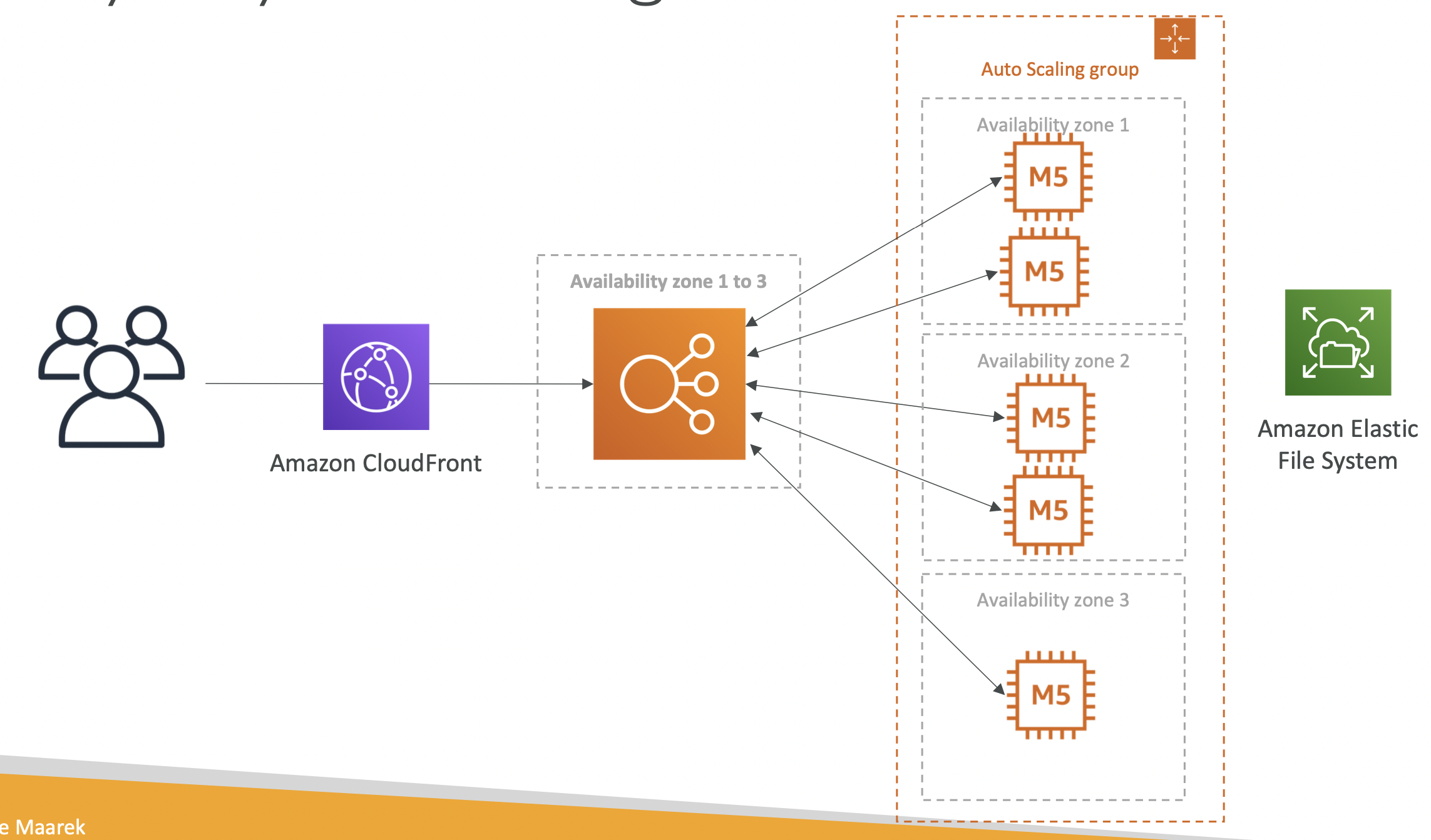
CloudFront는,
- 업데이트를 캐시할 것이다.
- 업데이트 파일은 정적 파일일 것이다. - EC2는 서버리스가 아니지만 CloudFront는 서버리스이고 확장성이 있기 때문에 EC2를 이용해 확장하는 데 따른 비용을 절약할 수 있다.
- 가용성이 높으며 네트워크 bandwith(대역폭)가 넓다.
즉, 정적 컨텐츠라면 CloudFront를 이용해 캐싱하는 것이 더 확장성이 높고 저렴한 선택이다.
빅데이터 수집 파이프라인
빅데이터를 수집 하는 상황은 아래와 같을 것이다.
- 완전 관리형의 서버리스 환경이 필요하다.
- 실시간 데이터 수집이 필요하다.
- 데이터 transform 해야 한다.
- transform 된 데이터를 SQL을 이용해 쿼리할 필요가 있다.
- 쿼리를 이용해 만들어진 reports는 S3에 저장되어야 한다.
- 이렇게 만들어진 데이터를 warehouse에 로드하고 대시보드를 생성하고 싶다.
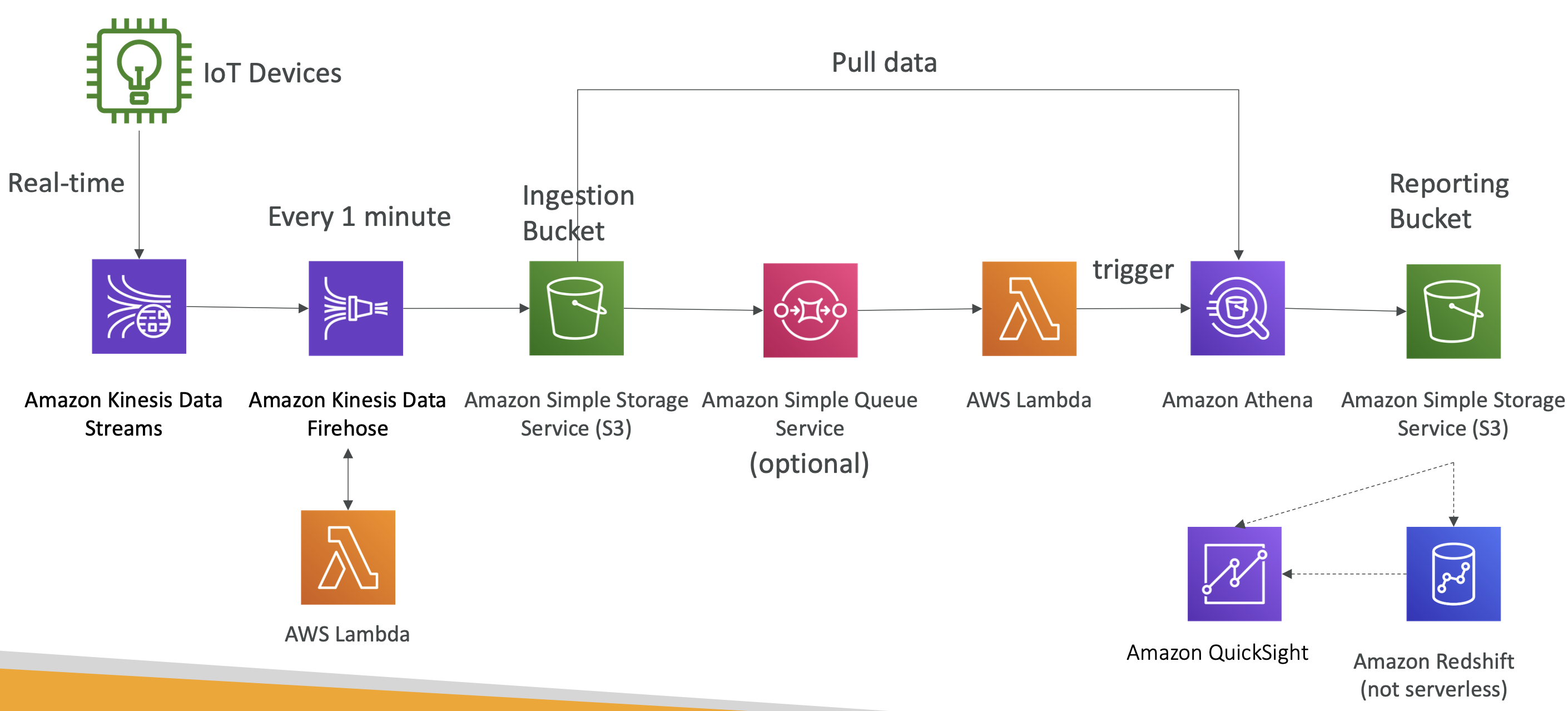
- 람다 함수를 이용해 Data Firehose에 도달한 데이터를 변형할 수 있다.
- 그리고 버킷 다음에는 SQS가 붙어서 람다 함수를 호출할 수 있다(SQS는 선택적으로 사용하면 되며 버킷과 람다 함수가 직접적으로 상호작용 해도 된다).
- 아테나가 S3 ingestion bucket으로부터 데이터를 가져온다.
- 그러면 서버리스 SQL 쿼리를 할 것이다. - 그러면 정제된 데이터를 다른 S3 버킷에 담으면 되고, 이를 Quicksight(S3에서 바로 시각화 할 수 있는 도구)를 이용해 직접 시각화 할 수 있다.
- 또는 분석에 적절한 data warehouse인 Redshift(서버리스가 아니다)로 데이터를 로드할 수도 있다(Reshift도 Quicksight를 이용할 수 있다).
정리하면,
- IoT core를 이용해 많은 IoT 디바이스로부터 데이터를 가져올 수 있다.
- kinesis는 실시간 데이터 수집에 용이하다.
- Firehose는 거의 실시간으로 S3로 데이터를 전송할 수 있도록 도와준다.
- 람다 함수는 Firehose를 도와 데이터 변환을 실행한다.
- S3는 SQS, SNS 또는 람다를 이용해 알림을 트리거 한다.
- 아테나는 서버리스 SQL 서비스이며 그 결과 데이터는 S3에 저장된다.
- reporting 버킷은 분석한 데이터를 저장하기 위한 공간이며 QuickSight나 Redshift와 함께 이용하는 것이 좋다.
오답노트

- 이 경우, 비동기식이라 SQS인 것은 맞지만 람다는 안된다. 왜냐하면 처리에 25분 이상 소요되기 때문이다. 람다는 최대 호출 시간이 15분이다.
Q1. 만약 당신이 이미지를 공유하는 전세계적인 사이트를 운영하고 있을 때 컨텐츠는Elastic File System(EFS) 파일 시스템에서 호스팅되고 애플리케이션 로드 밸런서 (ALB)와 EC2 인스턴스 세트에 의해 배포되고 있다고 해보자. 매월 EC2 인스턴스에 대한 부하를 증가시키고 네트워크 비용을 증가시키는 매우 높은 트래픽을 경험하고 있다면 어떤 해결 방법이 있을까?
A1: CloudFront를 ALB의 앞 단에 붙인다.
-> CloudFront는 짧은 지연 시간과 높은 전송 속도로 전 세계 고객에게 데이터, 비디오, 애플리케이션 및 API를 안전하게 제공하는 빠른 CDN(콘텐츠 전송 네트워크) 서비스이다. Amazon CloudFront는 애플리케이션 로드 밸런서 (ALB) 앞에서 사용할 수 있다. CloudFront를 통해 파일을 캐싱하는 것이 좋다.
