Aurora Serverless
- 자동화된 데이터베이스 인스턴스화와 실제 사용에 근거한 auto-scaling 기능을 제공한다.
- 불연속적이며 간헐적인, 그리고 예측 불가능한 작업량을 가질 때 사용하기 좋다.
- 초 단위로 금액을 지불하기 때문에 비용 측면에서 훨씬 효율적이다.
동작 방식
- 클라이언트가 Proxy Fleet(Aurora가 관리함)과 소통하게 되고, 많은 Aurora 인스턴스가 워크로드에 기초해 servlerless 형태로 생성된다.
- 따라서, 용량을 사전에 프로비저닝 할 필요가 없다.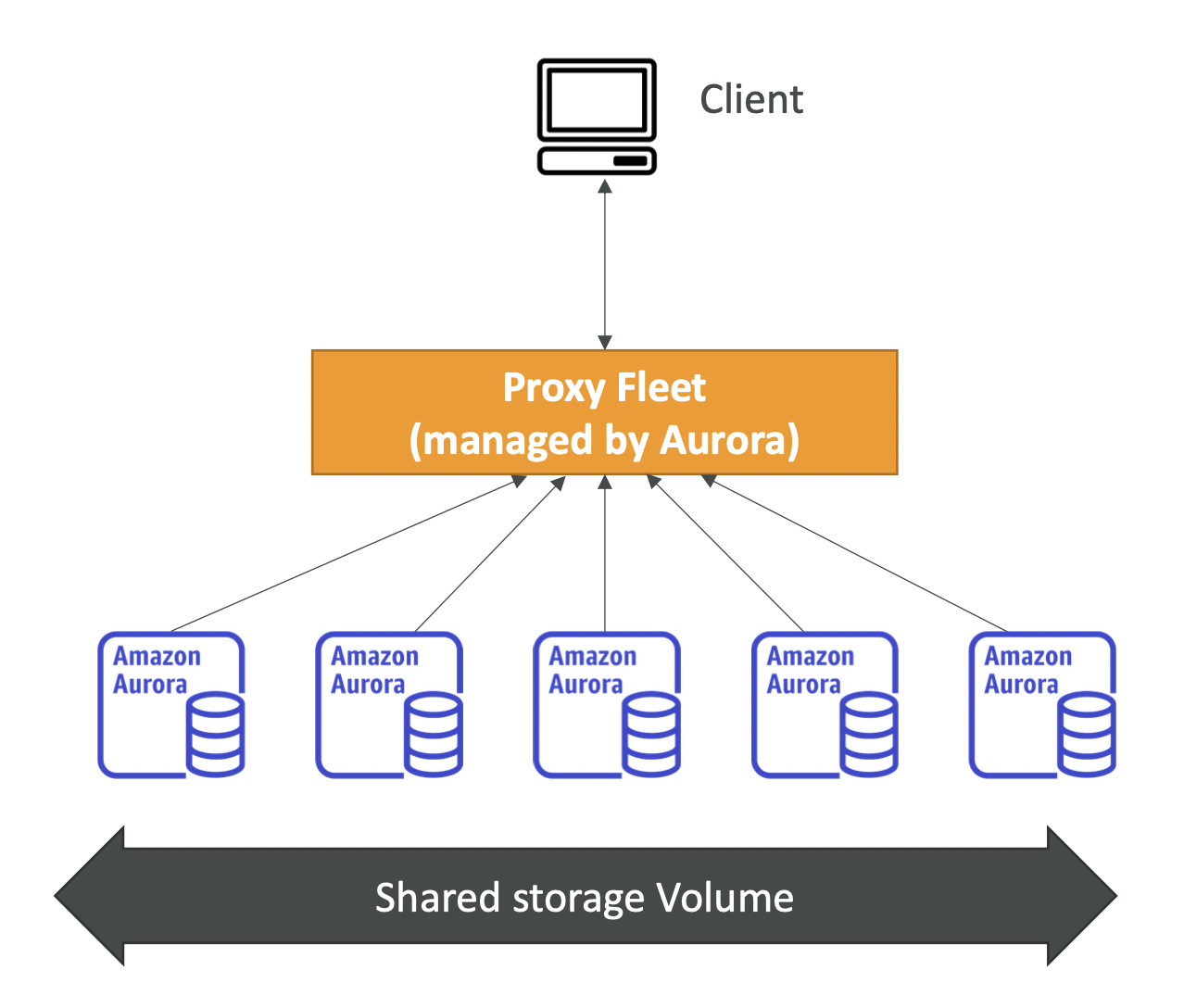
Aurora Multi-Master
- 라이터 노드에 대한 즉각적인 장애 대응을 하기 위해 고 가용성이 요구될 때 사용하기 좋다.
- 이 경우, Aurora 클러스터에 있는 모든 인스턴스가 읽기와 쓰기 기능을 하며 장애 발생시 리더 인스턴스를 master로 승격한다.
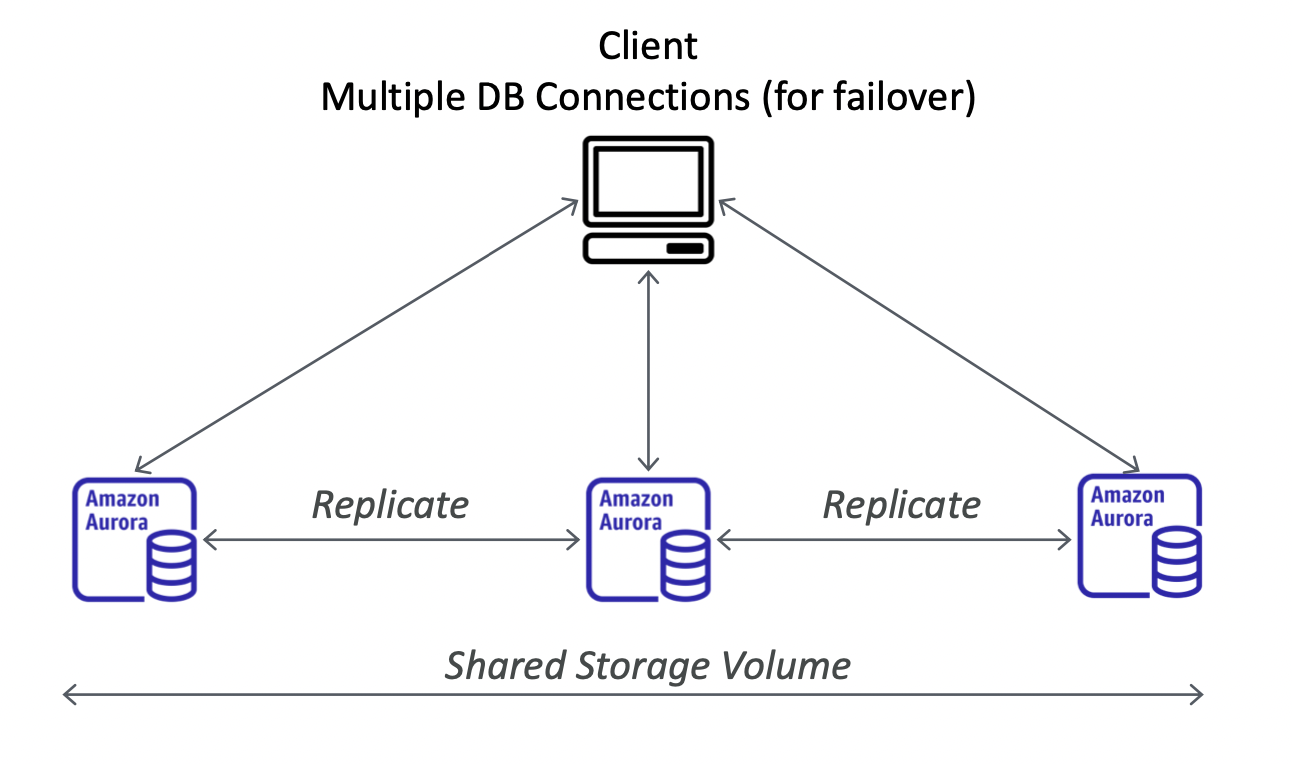
Global Aurora
만약 교차 리전에 읽기 복제본을 가지고 있는 경우 이는 장애 복구를 위해 사용하기 좋다. 그러나, 이 방법 말고도 Aurora Global Database를 사용하는 방법도 있으며 이 방법이 더 추천되는 방법이다.
Aurora Global Database
- 이 경우 1개의 primary region을 갖게 된다.
- 최대 5개의 read 전용 secondary region을 셋업할 수 있다.
- 이 경우 지연 시간은 1초가 채 안된다.
- secondary region에는 최대 16개의 읽기 복제본을 가질 수 있다. - 만약 한 리전의 데이터베이스에 장애가 발생하면 다른 리전을 primary로 승격시키며 이 때 RTO(Recovery Time Objective)는 1분 미만이다.
- 즉, 다른 리전으로 장애 복구를 하는 데 1분 미만의 시간이 소요되는 것이다. - Primary region은 read/write 모두를 수행할 수 있지만 secondary region은 read only이다.
- 만약 장애가 발생해 secondary를 primary로 승격하게 될 경우 해당 복제본은 read/write aurora cluster가 된다.
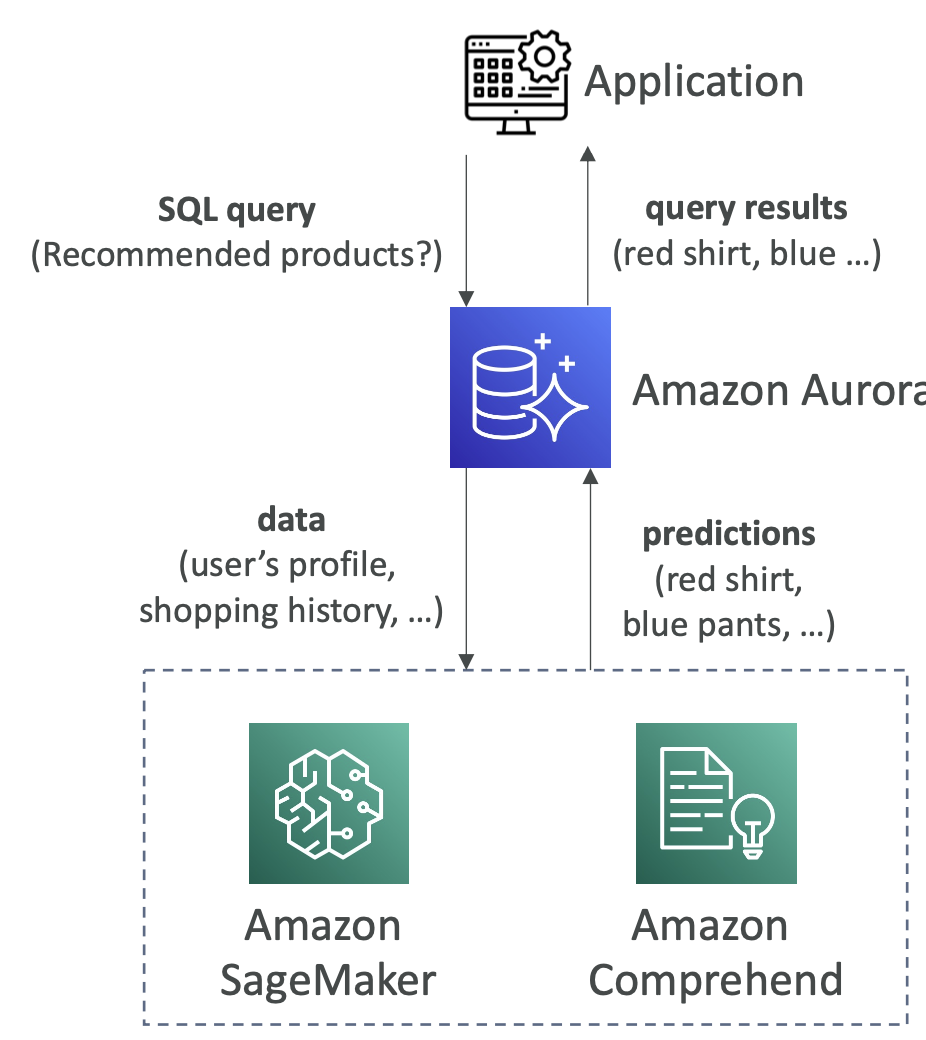
Aurora Machine Learning
- SQL을 이용해 머신러닝에 기초한 예측을 애플리케이션에 추가할 수 있다.
- 이는 간단하며 최적화되고 또한 안전한 Aurora - AWS ML service 사이의 통합이다.
- 지원되는 서비스
- Amazon SageMaker
- Amazon Comprehend - 사용 사례: 이상 거래 탐지, ads targeting, 감정 분석, 상품 추천 서비스 등